 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongCat-AudioDiT: High-Fidelity Diffusion Text-to-Speech in the Waveform Latent Space
Mar 31, 2026We present LongCat-AudioDiT, a novel, non-autoregressive diffusion-based text-to-speech (TTS) model that achieves state-of-the-art (SOTA) performance. Unlike previous methods that rely on intermediate acoustic representations such as mel-spectrograms, the core innovation of LongCat-AudioDiT lies in operating directly within the waveform latent space. This approach effectively mitigates compounding errors and drastically simplifies the TTS pipeline, requiring only a waveform variational autoencoder (Wav-VAE) and a diffusion backbone. Furthermore, we introduce two critical improvements to the inference process: first, we identify and rectify a long-standing training-inference mismatch; second, we replace traditional classifier-free guidance with adaptive projection guidance to elevate generation quality. Experimental results demonstrate that, despite the absence of complex multi-stage training pipelines or high-quality human-annotated datasets, LongCat-AudioDiT achieves SOTA zero-shot voice cloning performance on the Seed benchmark while maintaining competitive intelligibility. Specifically, our largest variant, LongCat-AudioDiT-3.5B, outperforms the previous SOTA model (Seed-TTS), improving the speaker similarity (SIM) scores from 0.809 to 0.818 on Seed-ZH, and from 0.776 to 0.797 on Seed-Hard. Finally, through comprehensive ablation studies and systematic analysis, we validate the effectiveness of our proposed modules. Notably, we investigate the interplay between the Wav-VAE and the TTS backbone, revealing the counterintuitive finding that superior reconstruction fidelity in the Wav-VAE does not necessarily lead to better overall TTS performance. Code and model weights are released to foster further research within the speech community.
AS-Speech: Adaptive Style For Speech Synthesis
Sep 09, 2024



In recent years, there has been significant progress in Text-to-Speech (TTS) synthesis technology, enabling the high-quality synthesis of voices in common scenarios. In unseen situations, adaptive TTS requires a strong generalization capability to speaker style characteristics. However, the existing adaptive methods can only extract and integrate coarse-grained timbre or mixed rhythm attributes separately. In this paper, we propose AS-Speech, an adaptive style methodology that integrates the speaker timbre characteristics and rhythmic attributes into a unified framework for text-to-speech synthesis. Specifically, AS-Speech can accurately simulate style characteristics through fine-grained text-based timbre features and global rhythm information, and achieve high-fidelity speech synthesis through the diffusion model. Experiments show that the proposed model produces voices with higher naturalness and similarity in terms of timbre and rhythm compared to a series of adaptive TTS models.
Multi-speaker Multi-style Text-to-speech Synthesis With Single-speaker Single-style Training Data Scenarios
Dec 23, 2021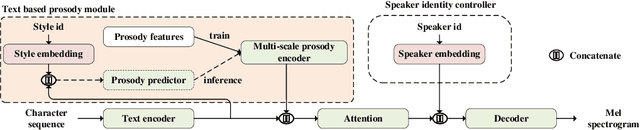
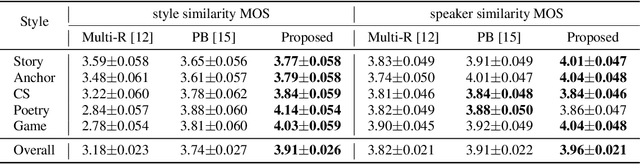
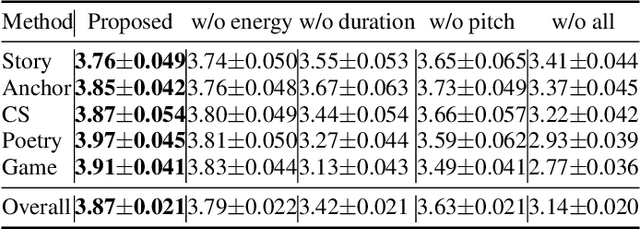
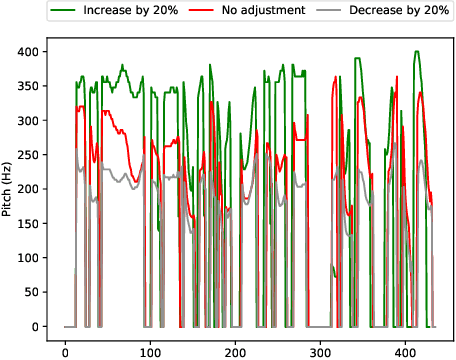
In the existing cross-speaker style transfer task, a source speaker with multi-style recordings is necessary to provide the style for a target speaker. However, it is hard for one speaker to express all expected styles. In this paper, a more general task, which is to produce expressive speech by combining any styles and timbres from a multi-speaker corpus in which each speaker has a unique style, is proposed. To realize this task, a novel method is proposed. This method is a Tacotron2-based framework but with a fine-grained text-based prosody predicting module and a speaker identity controller. Experiments demonstrate that the proposed method can successfully express a style of one speaker with the timber of another speaker bypassing the dependency on a single speaker's multi-style corpus. Moreover, the explicit prosody features used in the prosody predicting module can increase the diversity of synthetic speech by adjusting the value of prosody features.