 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained Scene Image Classification with Modality-Agnostic Adapter
Jul 03, 2024



When dealing with the task of fine-grained scene image classification, most previous works lay much emphasis on global visual features when doing multi-modal feature fusion. In other words, models are deliberately designed based on prior intuitions about the importance of different modalities. In this paper, we present a new multi-modal feature fusion approach named MAA (Modality-Agnostic Adapter), trying to make the model learn the importance of different modalities in different cases adaptively, without giving a prior setting in the model architecture. More specifically, we eliminate the modal differences in distribution and then use a modality-agnostic Transformer encoder for a semantic-level feature fusion. Our experiments demonstrate that MAA achieves state-of-the-art results on benchmarks by applying the same modalities with previous methods. Besides, it is worth mentioning that new modalities can be easily added when using MAA and further boost the performance. Code is available at https://github.com/quniLcs/MAA.
FairMonitor: A Dual-framework for Detecting Stereotypes and Biases in Large Language Models
May 06, 2024



Detecting stereotypes and biases in Large Language Models (LLMs) is crucial for enhancing fairness and reducing adverse impacts on individuals or groups when these models are applied. Traditional methods, which rely on embedding spaces or are based on probability metrics, fall short in revealing the nuanced and implicit biases present in various contexts. To address this challenge, we propose the FairMonitor framework and adopt a static-dynamic detection method for a comprehensive evaluation of stereotypes and biases in LLMs. The static component consists of a direct inquiry test, an implicit association test, and an unknown situation test, including 10,262 open-ended questions with 9 sensitive factors and 26 educational scenarios. And it is effective for evaluating both explicit and implicit biases. Moreover, we utilize the multi-agent system to construst the dynamic scenarios for detecting subtle biases in more complex and realistic setting. This component detects the biases based on the interaction behaviors of LLMs across 600 varied educational scenarios. The experimental results show that the cooperation of static and dynamic methods can detect more stereotypes and biased in LLMs.
UMAAF: Unveiling Aesthetics via Multifarious Attributes of Images
Nov 21, 2023



With the increasing prevalence of smartphones and websites, Image Aesthetic Assessment (IAA) has become increasingly crucial. While the significance of attributes in IAA is widely recognized, many attribute-based methods lack consideration for the selection and utilization of aesthetic attributes. Our initial step involves the acquisition of aesthetic attributes from both intra- and inter-perspectives. Within the intra-perspective, we extract the direct visual attributes of images, constituting the absolute attribute. In the inter-perspective, our focus lies in modeling the relative score relationships between images within the same sequence, forming the relative attribute. Then, to better utilize image attributes in aesthetic assessment, we propose the Unified Multi-attribute Aesthetic Assessment Framework (UMAAF) to model both absolute and relative attributes of images. For absolute attributes, we leverage multiple absolute-attribute perception modules and an absolute-attribute interacting network. The absolute-attribute perception modules are first pre-trained on several absolute-attribute learning tasks and then used to extract corresponding absolute attribute features. The absolute-attribute interacting network adaptively learns the weight of diverse absolute-attribute features, effectively integrating them with generic aesthetic features from various absolute-attribute perspectives and generating the aesthetic prediction. To model the relative attribute of images, we consider the relative ranking and relative distance relationships between images in a Relative-Relation Loss function, which boosts the robustness of the UMAAF. Furthermore, UMAAF achieves state-of-the-art performance on TAD66K and AVA datasets, and multiple experiments demonstrate the effectiveness of each module and the model's alignment with human preference.
DCQA: Document-Level Chart Question Answering towards Complex Reasoning and Common-Sense Understanding
Oct 29, 2023



Visually-situated languages such as charts and plots are omnipresent in real-world documents. These graphical depictions are human-readable and are often analyzed in visually-rich documents to address a variety of questions that necessitate complex reasoning and common-sense responses. Despite the growing number of datasets that aim to answer questions over charts, most only address this task in isolation, without considering the broader context of document-level question answering. Moreover, such datasets lack adequate common-sense reasoning information in their questions. In this work, we introduce a novel task named document-level chart question answering (DCQA). The goal of this task is to conduct document-level question answering, extracting charts or plots in the document via document layout analysis (DLA) first and subsequently performing chart question answering (CQA). The newly developed benchmark dataset comprises 50,010 synthetic documents integrating charts in a wide range of styles (6 styles in contrast to 3 for PlotQA and ChartQA) and includes 699,051 questions that demand a high degree of reasoning ability and common-sense understanding. Besides, we present the development of a potent question-answer generation engine that employs table data, a rich color set, and basic question templates to produce a vast array of reasoning question-answer pairs automatically. Based on DCQA, we devise an OCR-free transformer for document-level chart-oriented understanding, capable of DLA and answering complex reasoning and common-sense questions over charts in an OCR-free manner. Our DCQA dataset is expected to foster research on understanding visualizations in documents, especially for scenarios that require complex reasoning for charts in the visually-rich document. We implement and evaluate a set of baselines, and our proposed method achieves comparable results.
Progressive Evidence Refinement for Open-domain Multimodal Retrieval Question Answering
Oct 15, 2023



Pre-trained multimodal models have achieved significant success in retrieval-based question answering. However, current multimodal retrieval question-answering models face two main challenges. Firstly, utilizing compressed evidence features as input to the model results in the loss of fine-grained information within the evidence. Secondly, a gap exists between the feature extraction of evidence and the question, which hinders the model from effectively extracting critical features from the evidence based on the given question. We propose a two-stage framework for evidence retrieval and question-answering to alleviate these issues. First and foremost, we propose a progressive evidence refinement strategy for selecting crucial evidence. This strategy employs an iterative evidence retrieval approach to uncover the logical sequence among the evidence pieces. It incorporates two rounds of filtering to optimize the solution space, thus further ensuring temporal efficiency. Subsequently, we introduce a semi-supervised contrastive learning training strategy based on negative samples to expand the scope of the question domain, allowing for a more thorough exploration of latent knowledge within known samples. Finally, in order to mitigate the loss of fine-grained information, we devise a multi-turn retrieval and question-answering strategy to handle multimodal inputs. This strategy involves incorporating multimodal evidence directly into the model as part of the historical dialogue and question. Meanwhile, we leverage a cross-modal attention mechanism to capture the underlying connections between the evidence and the question, and the answer is generated through a decoding generation approach. We validate the model's effectiveness through extensive experiments, achieving outstanding performance on WebQA and MultimodelQA benchmark tests.
FairBench: A Four-Stage Automatic Framework for Detecting Stereotypes and Biases in Large Language Models
Aug 21, 2023Detecting stereotypes and biases in Large Language Models (LLMs) can enhance fairness and reduce adverse impacts on individuals or groups when these LLMs are applied. However, the majority of existing methods focus on measuring the model's preference towards sentences containing biases and stereotypes within datasets, which lacks interpretability and cannot detect implicit biases and stereotypes in the real world. To address this gap, this paper introduces a four-stage framework to directly evaluate stereotypes and biases in the generated content of LLMs, including direct inquiry testing, serial or adapted story testing, implicit association testing, and unknown situation testing. Additionally, the paper proposes multi-dimensional evaluation metrics and explainable zero-shot prompts for automated evaluation. Using the education sector as a case study, we constructed the Edu-FairBench based on the four-stage framework, which encompasses 12,632 open-ended questions covering nine sensitive factors and 26 educational scenarios. Experimental results reveal varying degrees of stereotypes and biases in five LLMs evaluated on Edu-FairBench. Moreover, the results of our proposed automated evaluation method have shown a high correlation with human annotations.
DDT: Dual-branch Deformable Transformer for Image Denoising
Apr 13, 2023



Transformer is beneficial for image denoising tasks since it can model long-range dependencies to overcome the limitations presented by inductive convolutional biases. However, directly applying the transformer structure to remove noise is challenging because its complexity grows quadratically with the spatial resolution. In this paper, we propose an efficient Dual-branch Deformable Transformer (DDT) denoising network which captures both local and global interactions in parallel. We divide features with a fixed patch size and a fixed number of patches in local and global branches, respectively. In addition, we apply deformable attention operation in both branches, which helps the network focus on more important regions and further reduces computational complexity. We conduct extensive experiments on real-world and synthetic denoising tasks, and the proposed DDT achieves state-of-the-art performance with significantly fewer computational costs.
LoGoNet: Towards Accurate 3D Object Detection with Local-to-Global Cross-Modal Fusion
Mar 14, 2023LiDAR-camera fusion methods have shown impressive performance in 3D object detection. Recent advanced multi-modal methods mainly perform global fusion, where image features and point cloud features are fused across the whole scene. Such practice lacks fine-grained region-level information, yielding suboptimal fusion performance. In this paper, we present the novel Local-to-Global fusion network (LoGoNet), which performs LiDAR-camera fusion at both local and global levels. Concretely, the Global Fusion (GoF) of LoGoNet is built upon previous literature, while we exclusively use point centroids to more precisely represent the position of voxel features, thus achieving better cross-modal alignment. As to the Local Fusion (LoF), we first divide each proposal into uniform grids and then project these grid centers to the images. The image features around the projected grid points are sampled to be fused with position-decorated point cloud features, maximally utilizing the rich contextual information around the proposals. The Feature Dynamic Aggregation (FDA) module is further proposed to achieve information interaction between these locally and globally fused features, thus producing more informative multi-modal features. Extensive experiments on both Waymo Open Dataset (WOD) and KITTI datasets show that LoGoNet outperforms all state-of-the-art 3D detection methods. Notably, LoGoNet ranks 1st on Waymo 3D object detection leaderboard and obtains 81.02 mAPH (L2) detection performance. It is noteworthy that, for the first time, the detection performance on three classes surpasses 80 APH (L2) simultaneously. Code will be available at \url{https://github.com/sankin97/LoGoNet}.
Homogeneous Multi-modal Feature Fusion and Interaction for 3D Object Detection
Oct 18, 2022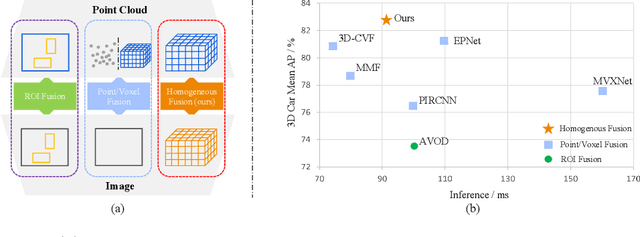
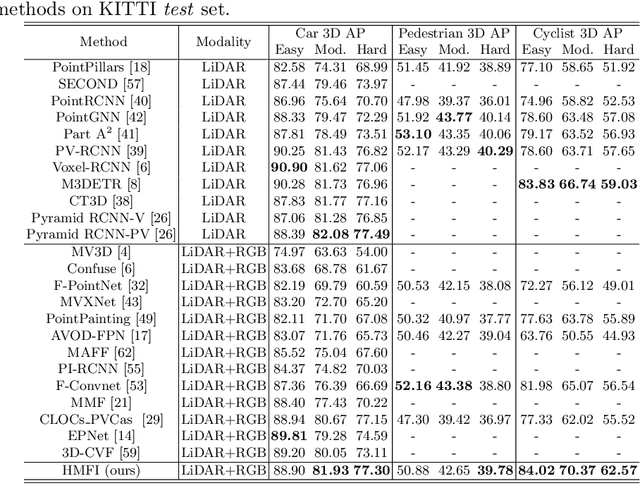
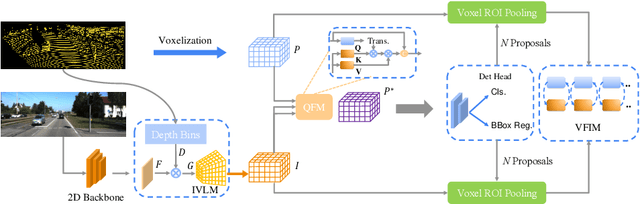
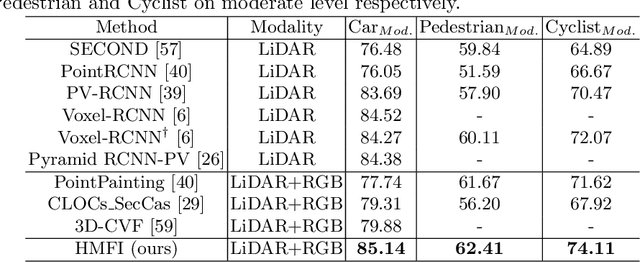
Multi-modal 3D object detection has been an active research topic in autonomous driving. Nevertheless, it is non-trivial to explore the cross-modal feature fusion between sparse 3D points and dense 2D pixels. Recent approaches either fuse the image features with the point cloud features that are projected onto the 2D image plane or combine the sparse point cloud with dense image pixels. These fusion approaches often suffer from severe information loss, thus causing sub-optimal performance. To address these problems, we construct the homogeneous structure between the point cloud and images to avoid projective information loss by transforming the camera features into the LiDAR 3D space. In this paper, we propose a homogeneous multi-modal feature fusion and interaction method (HMFI) for 3D object detection. Specifically, we first design an image voxel lifter module (IVLM) to lift 2D image features into the 3D space and generate homogeneous image voxel features. Then, we fuse the voxelized point cloud features with the image features from different regions by introducing the self-attention based query fusion mechanism (QFM). Next, we propose a voxel feature interaction module (VFIM) to enforce the consistency of semantic information from identical objects in the homogeneous point cloud and image voxel representations, which can provide object-level alignment guidance for cross-modal feature fusion and strengthen the discriminative ability in complex backgrounds. We conduct extensive experiments on the KITTI and Waymo Open Dataset, and the proposed HMFI achieves better performance compared with the state-of-the-art multi-modal methods. Particularly, for the 3D detection of cyclist on the KITTI benchmark, HMFI surpasses all the published algorithms by a large margin.
Progressive Scene Text Erasing with Self-Supervision
Jul 23, 2022


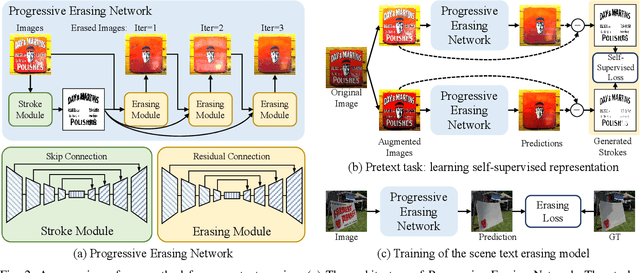
Scene text erasing seeks to erase text contents from scene images and current state-of-the-art text erasing models are trained on large-scale synthetic data. Although data synthetic engines can provide vast amounts of annotated training samples, there are differences between synthetic and real-world data. In this paper, we employ self-supervision for feature representation on unlabeled real-world scene text images. A novel pretext task is designed to keep consistent among text stroke masks of image variants. We design the Progressive Erasing Network in order to remove residual texts. The scene text is erased progressively by leveraging the intermediate generated results which provide the foundation for subsequent higher quality results. Experiments show that our method significantly improves the generalization of the text erasing task and achieves state-of-the-art performance on public benchmarks.