 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnother Vertical View: A Hierarchical Network for Heterogeneous Trajectory Prediction via Spectrums
Apr 11, 2023



With the fast development of AI-related techniques, the applications of trajectory prediction are no longer limited to easier scenes and trajectories. More and more heterogeneous trajectories with different representation forms, such as 2D or 3D coordinates, 2D or 3D bounding boxes, and even high-dimensional human skeletons, need to be analyzed and forecasted. Among these heterogeneous trajectories, interactions between different elements within a frame of trajectory, which we call the ``Dimension-Wise Interactions'', would be more complex and challenging. However, most previous approaches focus mainly on a specific form of trajectories, which means these methods could not be used to forecast heterogeneous trajectories, not to mention the dimension-wise interaction. Besides, previous methods mostly treat trajectory prediction as a normal time sequence generation task, indicating that these methods may require more work to directly analyze agents' behaviors and social interactions at different temporal scales. In this paper, we bring a new ``view'' for trajectory prediction to model and forecast trajectories hierarchically according to different frequency portions from the spectral domain to learn to forecast trajectories by considering their frequency responses. Moreover, we try to expand the current trajectory prediction task by introducing the dimension $M$ from ``another view'', thus extending its application scenarios to heterogeneous trajectories vertically. Finally, we adopt the bilinear structure to fuse two factors, including the frequency response and the dimension-wise interaction, to forecast heterogeneous trajectories via spectrums hierarchically in a generic way. Experiments show that the proposed model outperforms most state-of-the-art methods on ETH-UCY, Stanford Drone Dataset and nuScenes with heterogeneous trajectories, including 2D coordinates, 2D and 3D bounding boxes.
Self-supervised Guided Hypergraph Feature Propagation for Semi-supervised Classification with Missing Node Features
Feb 16, 2023Graph neural networks (GNNs) with missing node features have recently received increasing interest. Such missing node features seriously hurt the performance of the existing GNNs. Some recent methods have been proposed to reconstruct the missing node features by the information propagation among nodes with known and unknown attributes. Although these methods have achieved superior performance, how to exactly exploit the complex data correlations among nodes to reconstruct missing node features is still a great challenge. To solve the above problem, we propose a self-supervised guided hypergraph feature propagation (SGHFP). Specifically, the feature hypergraph is first generated according to the node features with missing information. And then, the reconstructed node features produced by the previous iteration are fed to a two-layer GNNs to construct a pseudo-label hypergraph. Before each iteration, the constructed feature hypergraph and pseudo-label hypergraph are fused effectively, which can better preserve the higher-order data correlations among nodes. After then, we apply the fused hypergraph to the feature propagation for reconstructing missing features. Finally, the reconstructed node features by multi-iteration optimization are applied to the downstream semi-supervised classification task. Extensive experiments demonstrate that the proposed SGHFP outperforms the existing semi-supervised classification with missing node feature methods.
Deep Manifold Hashing: A Divide-and-Conquer Approach for Semi-Paired Unsupervised Cross-Modal Retrieval
Sep 26, 2022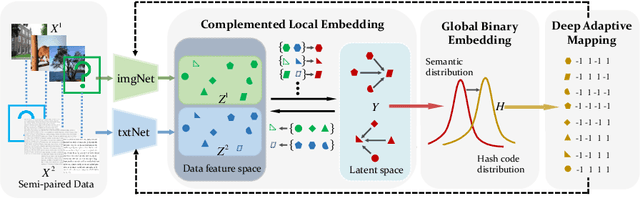
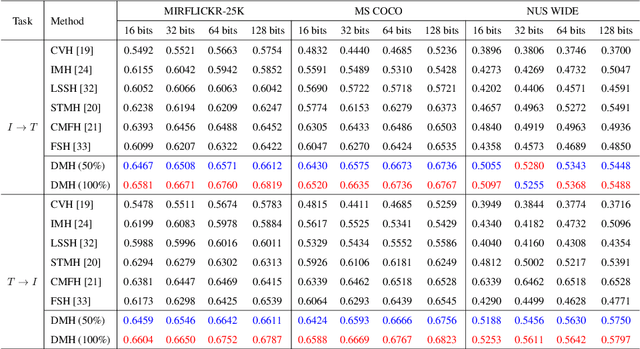
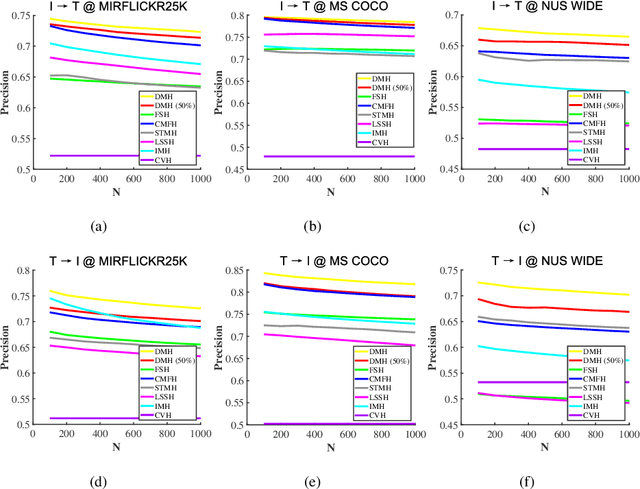
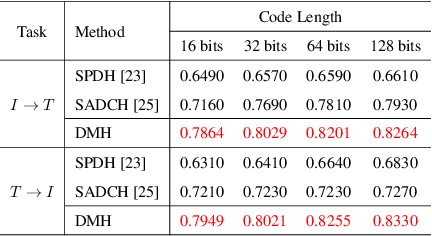
Hashing that projects data into binary codes has shown extraordinary talents in cross-modal retrieval due to its low storage usage and high query speed. Despite their empirical success on some scenarios, existing cross-modal hashing methods usually fail to cross modality gap when fully-paired data with plenty of labeled information is nonexistent. To circumvent this drawback, motivated by the Divide-and-Conquer strategy, we propose Deep Manifold Hashing (DMH), a novel method of dividing the problem of semi-paired unsupervised cross-modal retrieval into three sub-problems and building one simple yet efficiency model for each sub-problem. Specifically, the first model is constructed for obtaining modality-invariant features by complementing semi-paired data based on manifold learning, whereas the second model and the third model aim to learn hash codes and hash functions respectively. Extensive experiments on three benchmarks demonstrate the superiority of our DMH compared with the state-of-the-art fully-paired and semi-paired unsupervised cross-modal hashing methods.
Information-Theoretic Hashing for Zero-Shot Cross-Modal Retrieval
Sep 26, 2022Zero-shot cross-modal retrieval (ZS-CMR) deals with the retrieval problem among heterogenous data from unseen classes. Typically, to guarantee generalization, the pre-defined class embeddings from natural language processing (NLP) models are used to build a common space. In this paper, instead of using an extra NLP model to define a common space beforehand, we consider a totally different way to construct (or learn) a common hamming space from an information-theoretic perspective. We term our model the Information-Theoretic Hashing (ITH), which is composed of two cascading modules: an Adaptive Information Aggregation (AIA) module; and a Semantic Preserving Encoding (SPE) module. Specifically, our AIA module takes the inspiration from the Principle of Relevant Information (PRI) to construct a common space that adaptively aggregates the intrinsic semantics of different modalities of data and filters out redundant or irrelevant information. On the other hand, our SPE module further generates the hashing codes of different modalities by preserving the similarity of intrinsic semantics with the element-wise Kullback-Leibler (KL) divergence. A total correlation regularization term is also imposed to reduce the redundancy amongst different dimensions of hash codes. Sufficient experiments on three benchmark datasets demonstrate the superiority of the proposed ITH in ZS-CMR. Source code is available in the supplementary material.
Leachable Component Clustering
Aug 28, 2022

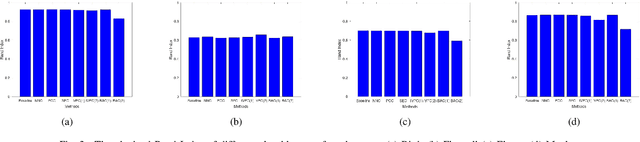
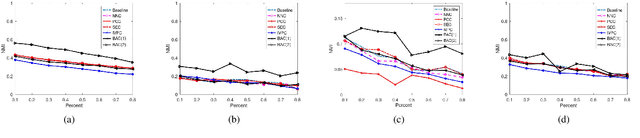
Clustering attempts to partition data instances into several distinctive groups, while the similarities among data belonging to the common partition can be principally reserved. Furthermore, incomplete data frequently occurs in many realworld applications, and brings perverse influence on pattern analysis. As a consequence, the specific solutions to data imputation and handling are developed to conduct the missing values of data, and independent stage of knowledge exploitation is absorbed for information understanding. In this work, a novel approach to clustering of incomplete data, termed leachable component clustering, is proposed. Rather than existing methods, the proposed method handles data imputation with Bayes alignment, and collects the lost patterns in theory. Due to the simple numeric computation of equations, the proposed method can learn optimized partitions while the calculation efficiency is held. Experiments on several artificial incomplete data sets demonstrate that, the proposed method is able to present superior performance compared with other state-of-the-art algorithms.
Deep Supervised Information Bottleneck Hashing for Cross-modal Retrieval based Computer-aided Diagnosis
May 06, 2022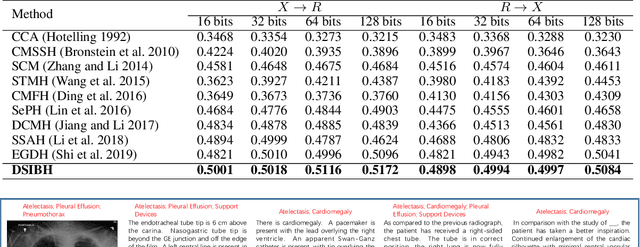
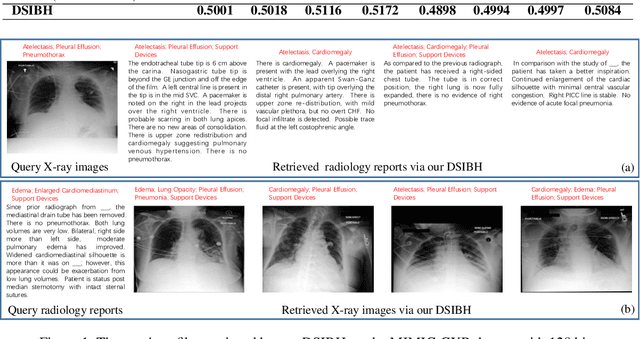
Mapping X-ray images, radiology reports, and other medical data as binary codes in the common space, which can assist clinicians to retrieve pathology-related data from heterogeneous modalities (i.e., hashing-based cross-modal medical data retrieval), provides a new view to promot computeraided diagnosis. Nevertheless, there remains a barrier to boost medical retrieval accuracy: how to reveal the ambiguous semantics of medical data without the distraction of superfluous information. To circumvent this drawback, we propose Deep Supervised Information Bottleneck Hashing (DSIBH), which effectively strengthens the discriminability of hash codes. Specifically, the Deep Deterministic Information Bottleneck (Yu, Yu, and Principe 2021) for single modality is extended to the cross-modal scenario. Benefiting from this, the superfluous information is reduced, which facilitates the discriminability of hash codes. Experimental results demonstrate the superior accuracy of the proposed DSIBH compared with state-of-the-arts in cross-modal medical data retrieval tasks.
* 7 pages, 1 figure
R2-Trans:Fine-Grained Visual Categorization with Redundancy Reduction
Apr 21, 2022
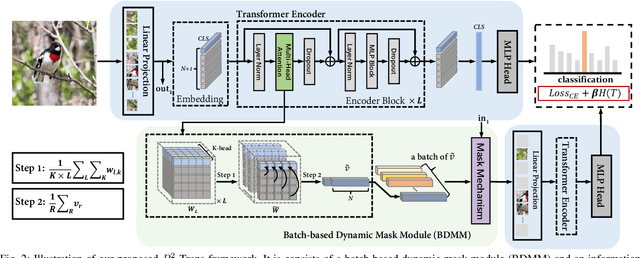

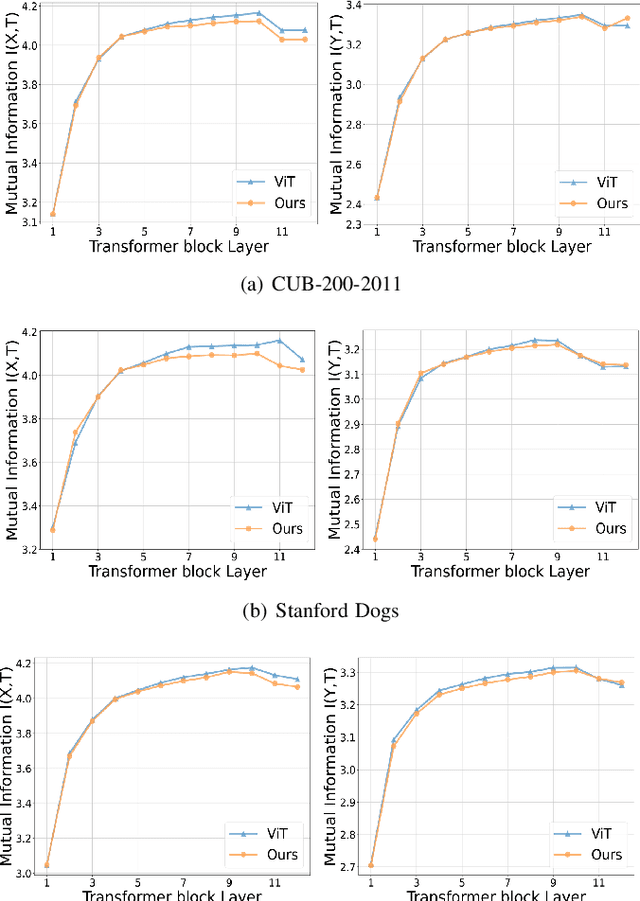
Fine-grained visual categorization (FGVC) aims to discriminate similar subcategories, whose main challenge is the large intraclass diversities and subtle inter-class differences. Existing FGVC methods usually select discriminant regions found by a trained model, which is prone to neglect other potential discriminant information. On the other hand, the massive interactions between the sequence of image patches in ViT make the resulting class-token contain lots of redundant information, which may also impacts FGVC performance. In this paper, we present a novel approach for FGVC, which can simultaneously make use of partial yet sufficient discriminative information in environmental cues and also compress the redundant information in class-token with respect to the target. Specifically, our model calculates the ratio of high-weight regions in a batch, adaptively adjusts the masking threshold and achieves moderate extraction of background information in the input space. Moreover, we also use the Information Bottleneck~(IB) approach to guide our network to learn a minimum sufficient representations in the feature space. Experimental results on three widely-used benchmark datasets verify that our approach can achieve outperforming performance than other state-of-the-art approaches and baseline models.
MSDN: Mutually Semantic Distillation Network for Zero-Shot Learning
Mar 07, 2022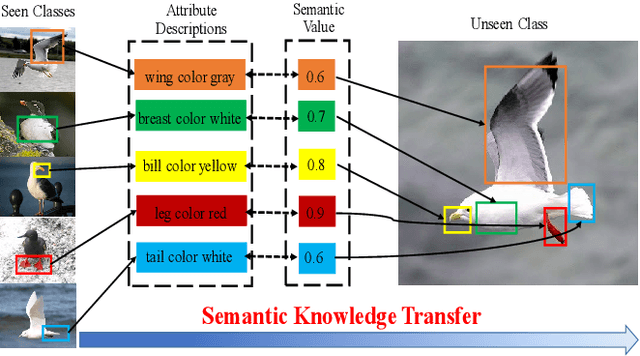
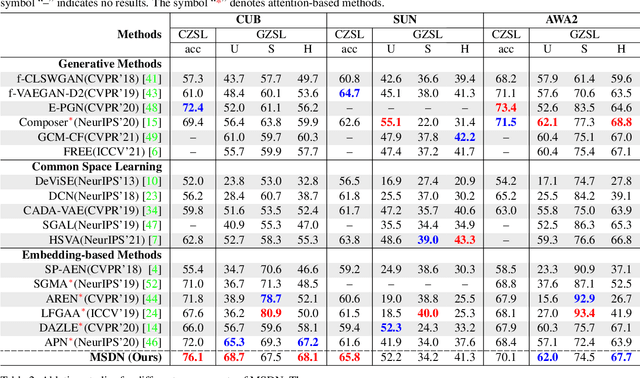

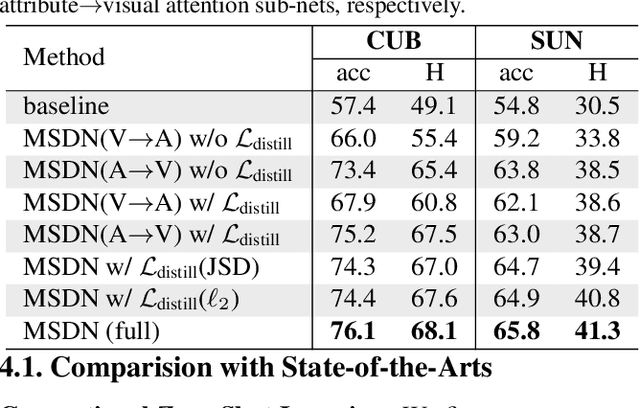
The key challenge of zero-shot learning (ZSL) is how to infer the latent semantic knowledge between visual and attribute features on seen classes, and thus achieving a desirable knowledge transfer to unseen classes. Prior works either simply align the global features of an image with its associated class semantic vector or utilize unidirectional attention to learn the limited latent semantic representations, which could not effectively discover the intrinsic semantic knowledge e.g., attribute semantics) between visual and attribute features. To solve the above dilemma, we propose a Mutually Semantic Distillation Network (MSDN), which progressively distills the intrinsic semantic representations between visual and attribute features for ZSL. MSDN incorporates an attribute$\rightarrow$visual attention sub-net that learns attribute-based visual features, and a visual$\rightarrow$attribute attention sub-net that learns visual-based attribute features. By further introducing a semantic distillation loss, the two mutual attention sub-nets are capable of learning collaboratively and teaching each other throughout the training process. The proposed MSDN yields significant improvements over the strong baselines, leading to new state-of-the-art performances on three popular challenging benchmarks, i.e., CUB, SUN, and AWA2. Our codes have been available at: \url{https://github.com/shiming-chen/MSDN}.
CSCNet: Contextual Semantic Consistency Network for Trajectory Prediction in Crowded Spaces
Feb 17, 2022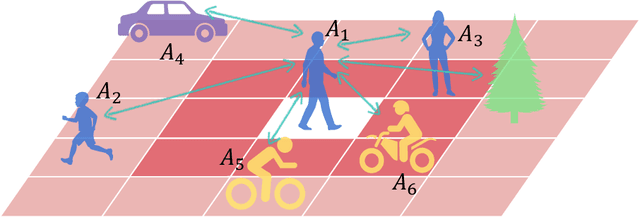
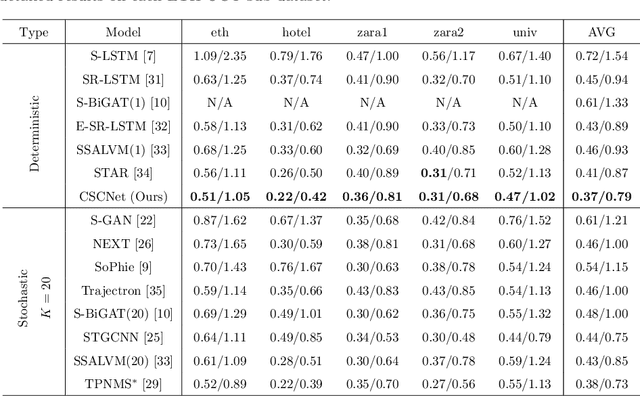
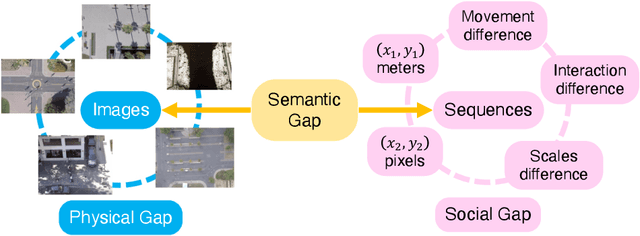
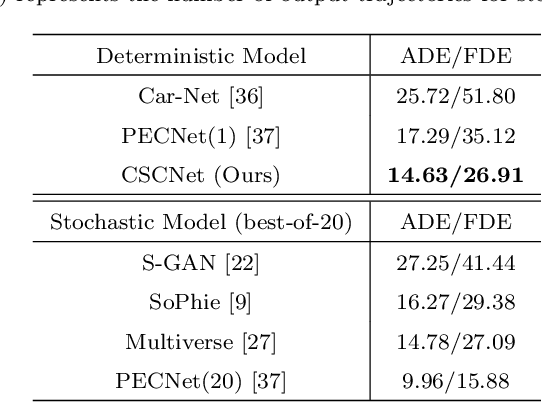
Trajectory prediction aims to predict the movement trend of the agents like pedestrians, bikers, vehicles. It is helpful to analyze and understand human activities in crowded spaces and widely applied in many areas such as surveillance video analysis and autonomous driving systems. Thanks to the success of deep learning, trajectory prediction has made significant progress. The current methods are dedicated to studying the agents' future trajectories under the social interaction and the sceneries' physical constraints. Moreover, how to deal with these factors still catches researchers' attention. However, they ignore the \textbf{Semantic Shift Phenomenon} when modeling these interactions in various prediction sceneries. There exist several kinds of semantic deviations inner or between social and physical interactions, which we call the "\textbf{Gap}". In this paper, we propose a \textbf{C}ontextual \textbf{S}emantic \textbf{C}onsistency \textbf{Net}work (\textbf{CSCNet}) to predict agents' future activities with powerful and efficient context constraints. We utilize a well-designed context-aware transfer to obtain the intermediate representations from the scene images and trajectories. Then we eliminate the differences between social and physical interactions by aligning activity semantics and scene semantics to cross the Gap. Experiments demonstrate that CSCNet performs better than most of the current methods quantitatively and qualitatively.
TransZero++: Cross Attribute-Guided Transformer for Zero-Shot Learning
Dec 21, 2021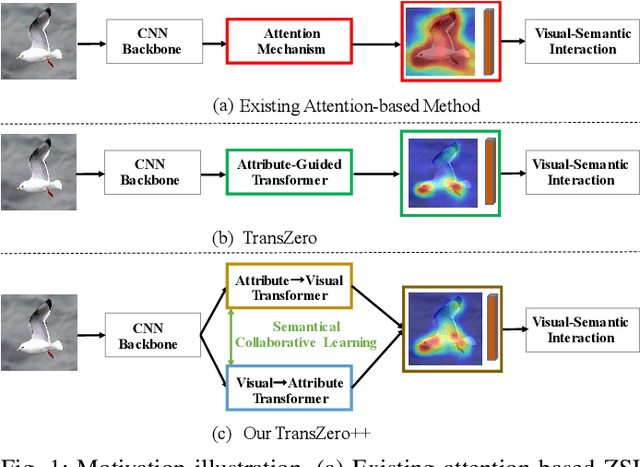
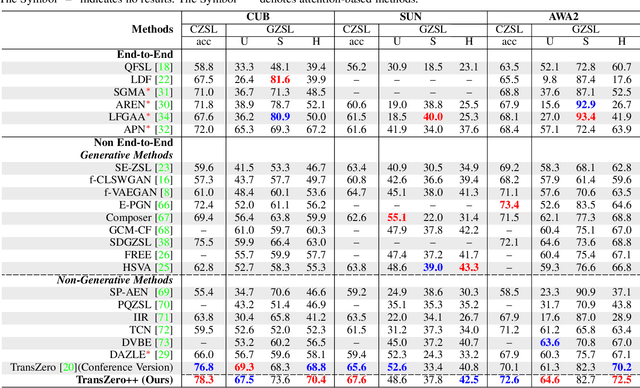
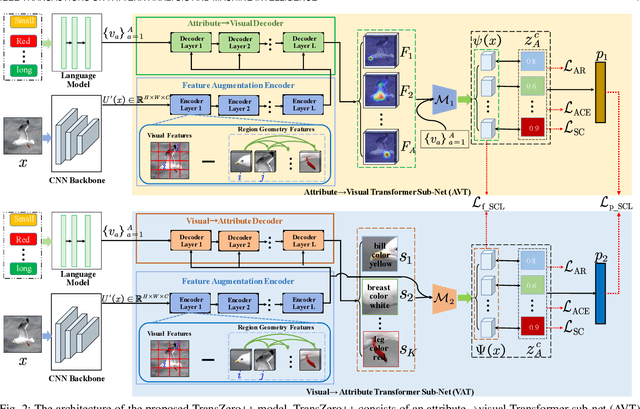
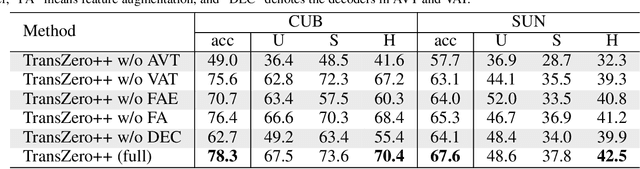
Zero-shot learning (ZSL) tackles the novel class recognition problem by transferring semantic knowledge from seen classes to unseen ones. Existing attention-based models have struggled to learn inferior region features in a single image by solely using unidirectional attention, which ignore the transferability and discriminative attribute localization of visual features. In this paper, we propose a cross attribute-guided Transformer network, termed TransZero++, to refine visual features and learn accurate attribute localization for semantic-augmented visual embedding representations in ZSL. TransZero++ consists of an attribute$\rightarrow$visual Transformer sub-net (AVT) and a visual$\rightarrow$attribute Transformer sub-net (VAT). Specifically, AVT first takes a feature augmentation encoder to alleviate the cross-dataset problem, and improves the transferability of visual features by reducing the entangled relative geometry relationships among region features. Then, an attribute$\rightarrow$visual decoder is employed to localize the image regions most relevant to each attribute in a given image for attribute-based visual feature representations. Analogously, VAT uses the similar feature augmentation encoder to refine the visual features, which are further applied in visual$\rightarrow$attribute decoder to learn visual-based attribute features. By further introducing semantical collaborative losses, the two attribute-guided transformers teach each other to learn semantic-augmented visual embeddings via semantical collaborative learning. Extensive experiments show that TransZero++ achieves the new state-of-the-art results on three challenging ZSL benchmarks. The codes are available at: \url{https://github.com/shiming-chen/TransZero_pp}.