 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain-Agnostic Batch Bayesian Optimization with Diverse Constraints via Bayesian Quadrature
Jun 09, 2023Real-world optimisation problems often feature complex combinations of (1) diverse constraints, (2) discrete and mixed spaces, and are (3) highly parallelisable. (4) There are also cases where the objective function cannot be queried if unknown constraints are not satisfied, e.g. in drug discovery, safety on animal experiments (unknown constraints) must be established before human clinical trials (querying objective function) may proceed. However, most existing works target each of the above three problems in isolation and do not consider (4) unknown constraints with query rejection. For problems with diverse constraints and/or unconventional input spaces, it is difficult to apply these techniques as they are often mutually incompatible. We propose cSOBER, a domain-agnostic prudent parallel active sampler for Bayesian optimisation, based on SOBER of Adachi et al. (2023). We consider infeasibility under unknown constraints as a type of integration error that we can estimate. We propose a theoretically-driven approach that propagates such error as a tolerance in the quadrature precision that automatically balances exploitation and exploration with the expected rejection rate. Moreover, our method flexibly accommodates diverse constraints and/or discrete and mixed spaces via adaptive tolerance, including conventional zero-risk cases. We show that cSOBER outperforms competitive baselines on diverse real-world blackbox-constrained problems, including safety-constrained drug discovery, and human-relationship-aware team optimisation over graph-structured space.
Bayesian Optimisation of Functions on Graphs
Jun 08, 2023The increasing availability of graph-structured data motivates the task of optimising over functions defined on the node set of graphs. Traditional graph search algorithms can be applied in this case, but they may be sample-inefficient and do not make use of information about the function values; on the other hand, Bayesian optimisation is a class of promising black-box solvers with superior sample efficiency, but it has been scarcely been applied to such novel setups. To fill this gap, we propose a novel Bayesian optimisation framework that optimises over functions defined on generic, large-scale and potentially unknown graphs. Through the learning of suitable kernels on graphs, our framework has the advantage of adapting to the behaviour of the target function. The local modelling approach further guarantees the efficiency of our method. Extensive experiments on both synthetic and real-world graphs demonstrate the effectiveness of the proposed optimisation framework.
Universal Self-adaptive Prompting
May 24, 2023



A hallmark of modern large language models (LLMs) is their impressive general zero-shot and few-shot abilities, often elicited through prompt-based and/or in-context learning. However, while highly coveted and being the most general, zero-shot performances in LLMs are still typically weaker due to the lack of guidance and the difficulty of applying existing automatic prompt design methods in general tasks when ground-truth labels are unavailable. In this study, we address this by presenting Universal Self-adaptive Prompting (USP), an automatic prompt design approach specifically tailored for zero-shot learning (while compatible with few-shot). Requiring only a small amount of unlabeled data & an inference-only LLM, USP is highly versatile: to achieve universal prompting, USP categorizes a possible NLP task into one of the three possible task types, and then uses a corresponding selector to select the most suitable queries & zero-shot model-generated responses as pseudo-demonstrations, thereby generalizing ICL to the zero-shot setup in a fully automated way. We evaluate zero-shot USP with two PaLM models, and demonstrate performances that are considerably stronger than standard zero-shot baselines and are comparable to or even superior than few-shot baselines across more than 20 natural language understanding (NLU) and natural language generation (NLG) tasks.
Better Zero-Shot Reasoning with Self-Adaptive Prompting
May 23, 2023



Modern large language models (LLMs) have demonstrated impressive capabilities at sophisticated tasks, often through step-by-step reasoning similar to humans. This is made possible by their strong few and zero-shot abilities -- they can effectively learn from a handful of handcrafted, completed responses ("in-context examples"), or are prompted to reason spontaneously through specially designed triggers. Nonetheless, some limitations have been observed. First, performance in the few-shot setting is sensitive to the choice of examples, whose design requires significant human effort. Moreover, given the diverse downstream tasks of LLMs, it may be difficult or laborious to handcraft per-task labels. Second, while the zero-shot setting does not require handcrafting, its performance is limited due to the lack of guidance to the LLMs. To address these limitations, we propose Consistency-based Self-adaptive Prompting (COSP), a novel prompt design method for LLMs. Requiring neither handcrafted responses nor ground-truth labels, COSP selects and builds the set of examples from the LLM zero-shot outputs via carefully designed criteria that combine consistency, diversity and repetition. In the zero-shot setting for three different LLMs, we show that using only LLM predictions, COSP improves performance up to 15% compared to zero-shot baselines and matches or exceeds few-shot baselines for a range of reasoning tasks.
SimSC: A Simple Framework for Semantic Correspondence with Temperature Learning
May 03, 2023We propose SimSC, a remarkably simple framework, to address the problem of semantic matching only based on the feature backbone. We discover that when fine-tuning ImageNet pre-trained backbone on the semantic matching task, L2 normalization of the feature map, a standard procedure in feature matching, produces an overly smooth matching distribution and significantly hinders the fine-tuning process. By setting an appropriate temperature to the softmax, this over-smoothness can be alleviated and the quality of features can be substantially improved. We employ a learning module to predict the optimal temperature for fine-tuning feature backbones. This module is trained together with the backbone and the temperature is updated online. We evaluate our method on three public datasets and demonstrate that we can achieve accuracy on par with state-of-the-art methods under the same backbone without using a learned matching head. Our method is versatile and works on various types of backbones. We show that the accuracy of our framework can be easily improved by coupling it with more powerful backbones.
Bayesian Quadrature for Neural Ensemble Search
Mar 17, 2023



Ensembling can improve the performance of Neural Networks, but existing approaches struggle when the architecture likelihood surface has dispersed, narrow peaks. Furthermore, existing methods construct equally weighted ensembles, and this is likely to be vulnerable to the failure modes of the weaker architectures. By viewing ensembling as approximately marginalising over architectures we construct ensembles using the tools of Bayesian Quadrature -- tools which are well suited to the exploration of likelihood surfaces with dispersed, narrow peaks. Additionally, the resulting ensembles consist of architectures weighted commensurate with their performance. We show empirically -- in terms of test likelihood, accuracy, and expected calibration error -- that our method outperforms state-of-the-art baselines, and verify via ablation studies that its components do so independently.
AutoPEFT: Automatic Configuration Search for Parameter-Efficient Fine-Tuning
Jan 28, 2023Large pretrained language models have been widely used in downstream NLP tasks via task-specific fine-tuning. Recently, an array of Parameter-Efficient Fine-Tuning (PEFT) methods have also achieved strong task performance while updating a much smaller number of parameters compared to full model tuning. However, it is non-trivial to make informed per-task design choices (i.e., to create PEFT configurations) concerning the selection of PEFT architectures and modules, the number of tunable parameters, and even the layers in which the PEFT modules are inserted. Consequently, it is highly likely that the current, manually set PEFT configurations might be suboptimal for many tasks from the perspective of the performance-to-efficiency trade-off. To address the core question of the PEFT configuration selection that aims to control and maximise the balance between performance and parameter efficiency, we first define a rich configuration search space spanning multiple representative PEFT modules along with finer-grained configuration decisions over the modules (e.g., parameter budget, insertion layer). We then propose AutoPEFT, a novel framework to traverse this configuration space: it automatically configures multiple PEFT modules via high-dimensional Bayesian optimisation. We show the resource scalability and task transferability of AutoPEFT-found configurations, outperforming existing PEFT methods on average on the standard GLUE benchmark while conducting the configuration search on a single task. The per-task AutoPEFT-based configuration search even outperforms full-model fine-tuning.
Bayesian Optimization over Discrete and Mixed Spaces via Probabilistic Reparameterization
Oct 18, 2022
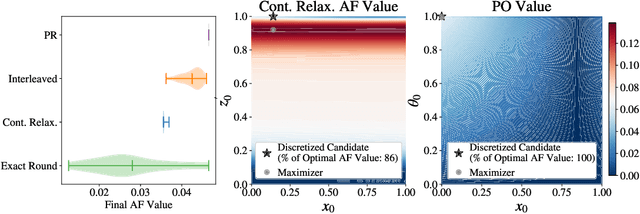

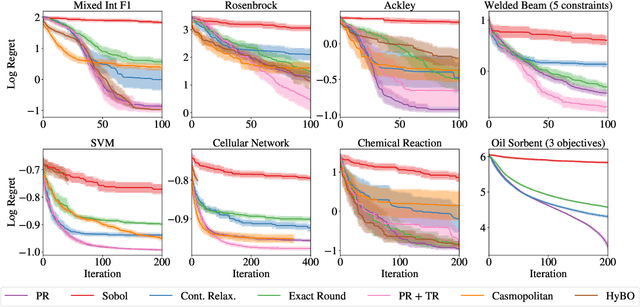
Optimizing expensive-to-evaluate black-box functions of discrete (and potentially continuous) design parameters is a ubiquitous problem in scientific and engineering applications. Bayesian optimization (BO) is a popular, sample-efficient method that leverages a probabilistic surrogate model and an acquisition function (AF) to select promising designs to evaluate. However, maximizing the AF over mixed or high-cardinality discrete search spaces is challenging standard gradient-based methods cannot be used directly or evaluating the AF at every point in the search space would be computationally prohibitive. To address this issue, we propose using probabilistic reparameterization (PR). Instead of directly optimizing the AF over the search space containing discrete parameters, we instead maximize the expectation of the AF over a probability distribution defined by continuous parameters. We prove that under suitable reparameterizations, the BO policy that maximizes the probabilistic objective is the same as that which maximizes the AF, and therefore, PR enjoys the same regret bounds as the original BO policy using the underlying AF. Moreover, our approach provably converges to a stationary point of the probabilistic objective under gradient ascent using scalable, unbiased estimators of both the probabilistic objective and its gradient. Therefore, as the number of starting points and gradient steps increase, our approach will recover of a maximizer of the AF (an often-neglected requisite for commonly used BO regret bounds). We validate our approach empirically and demonstrate state-of-the-art optimization performance on a wide range of real-world applications. PR is complementary to (and benefits) recent work and naturally generalizes to settings with multiple objectives and black-box constraints.
Bayesian Generational Population-Based Training
Jul 19, 2022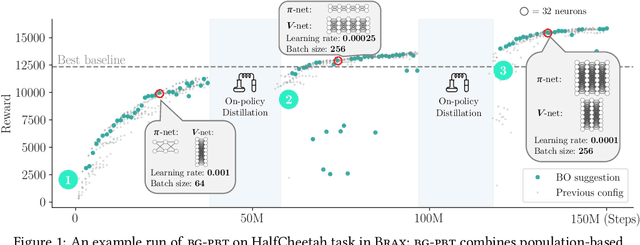
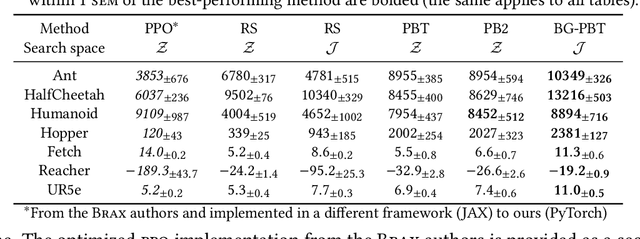
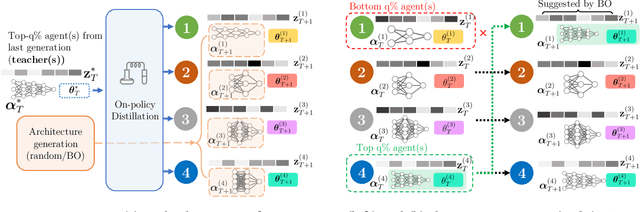
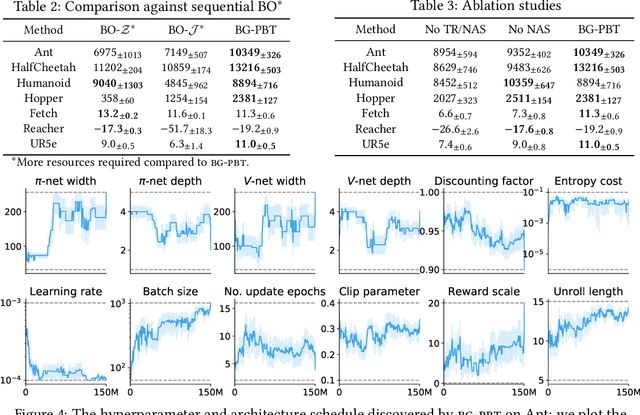
Reinforcement learning (RL) offers the potential for training generally capable agents that can interact autonomously in the real world. However, one key limitation is the brittleness of RL algorithms to core hyperparameters and network architecture choice. Furthermore, non-stationarities such as evolving training data and increased agent complexity mean that different hyperparameters and architectures may be optimal at different points of training. This motivates AutoRL, a class of methods seeking to automate these design choices. One prominent class of AutoRL methods is Population-Based Training (PBT), which have led to impressive performance in several large scale settings. In this paper, we introduce two new innovations in PBT-style methods. First, we employ trust-region based Bayesian Optimization, enabling full coverage of the high-dimensional mixed hyperparameter search space. Second, we show that using a generational approach, we can also learn both architectures and hyperparameters jointly on-the-fly in a single training run. Leveraging the new highly parallelizable Brax physics engine, we show that these innovations lead to large performance gains, significantly outperforming the tuned baseline while learning entire configurations on the fly. Code is available at https://github.com/xingchenwan/bgpbt.
On Redundancy and Diversity in Cell-based Neural Architecture Search
Mar 16, 2022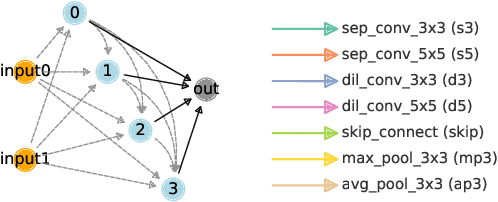
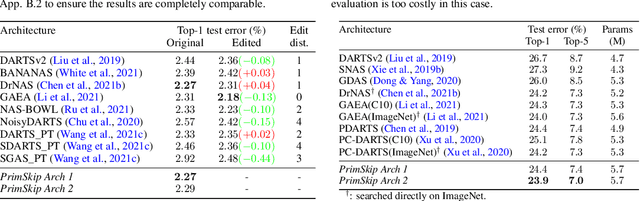
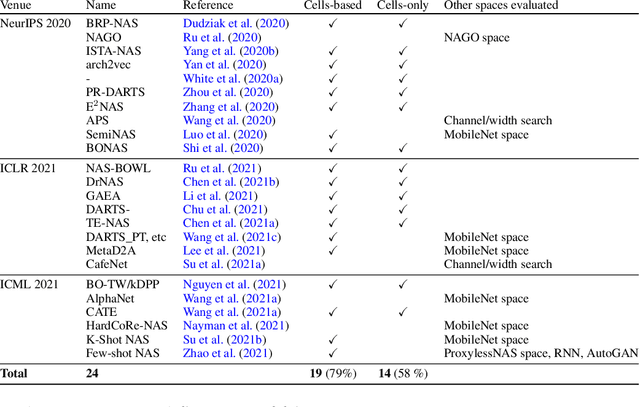
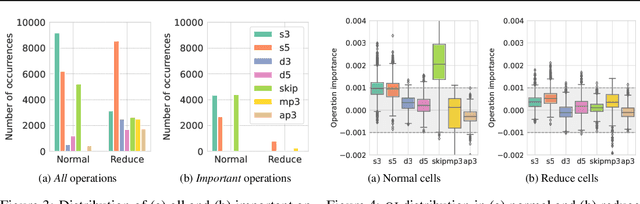
Searching for the architecture cells is a dominant paradigm in NAS. However, little attention has been devoted to the analysis of the cell-based search spaces even though it is highly important for the continual development of NAS. In this work, we conduct an empirical post-hoc analysis of architectures from the popular cell-based search spaces and find that the existing search spaces contain a high degree of redundancy: the architecture performance is minimally sensitive to changes at large parts of the cells, and universally adopted designs, like the explicit search for a reduction cell, significantly increase the complexities but have very limited impact on the performance. Across architectures found by a diverse set of search strategies, we consistently find that the parts of the cells that do matter for architecture performance often follow similar and simple patterns. By explicitly constraining cells to include these patterns, randomly sampled architectures can match or even outperform the state of the art. These findings cast doubts into our ability to discover truly novel architectures in the existing cell-based search spaces, and inspire our suggestions for improvement to guide future NAS research. Code is available at https://github.com/xingchenwan/cell-based-NAS-analysis.