 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D-aware Image Generation using 2D Diffusion Models
Mar 31, 2023In this paper, we introduce a novel 3D-aware image generation method that leverages 2D diffusion models. We formulate the 3D-aware image generation task as multiview 2D image set generation, and further to a sequential unconditional-conditional multiview image generation process. This allows us to utilize 2D diffusion models to boost the generative modeling power of the method. Additionally, we incorporate depth information from monocular depth estimators to construct the training data for the conditional diffusion model using only still images. We train our method on a large-scale dataset, i.e., ImageNet, which is not addressed by previous methods. It produces high-quality images that significantly outperform prior methods. Furthermore, our approach showcases its capability to generate instances with large view angles, even though the training images are diverse and unaligned, gathered from "in-the-wild" real-world environments.
ReBotNet: Fast Real-time Video Enhancement
Mar 23, 2023Most video restoration networks are slow, have high computational load, and can't be used for real-time video enhancement. In this work, we design an efficient and fast framework to perform real-time video enhancement for practical use-cases like live video calls and video streams. Our proposed method, called Recurrent Bottleneck Mixer Network (ReBotNet), employs a dual-branch framework. The first branch learns spatio-temporal features by tokenizing the input frames along the spatial and temporal dimensions using a ConvNext-based encoder and processing these abstract tokens using a bottleneck mixer. To further improve temporal consistency, the second branch employs a mixer directly on tokens extracted from individual frames. A common decoder then merges the features form the two branches to predict the enhanced frame. In addition, we propose a recurrent training approach where the last frame's prediction is leveraged to efficiently enhance the current frame while improving temporal consistency. To evaluate our method, we curate two new datasets that emulate real-world video call and streaming scenarios, and show extensive results on multiple datasets where ReBotNet outperforms existing approaches with lower computations, reduced memory requirements, and faster inference time.
RemoteTouch: Enhancing Immersive 3D Video Communication with Hand Touch
Feb 28, 2023



Recent research advance has significantly improved the visual realism of immersive 3D video communication. In this work we present a method to further enhance this immersive experience by adding the hand touch capability ("remote hand clapping"). In our system, each meeting participant sits in front of a large screen with haptic feedback. The local participant can reach his hand out to the screen and perform hand clapping with the remote participant as if the two participants were only separated by a virtual glass. A key challenge in emulating the remote hand touch is the realistic rendering of the participant's hand and arm as the hand touches the screen. When the hand is very close to the screen, the RGBD data required for realistic rendering is no longer available. To tackle this challenge, we present a dual representation of the user's hand. Our dual representation not only preserves the high-quality rendering usually found in recent image-based rendering systems but also allows the hand to reach the screen. This is possible because the dual representation includes both an image-based model and a 3D geometry-based model, with the latter driven by a hand skeleton tracked by a side view camera. In addition, the dual representation provides a distance-based fusion of the image-based and 3D geometry-based models as the hand moves closer to the screen. The result is that the image-based and 3D geometry-based models mutually enhance each other, leading to realistic and seamless rendering. Our experiments demonstrate that our method provides consistent hand contact experience between remote users and improves the immersive experience of 3D video communication.
NeRFInvertor: High Fidelity NeRF-GAN Inversion for Single-shot Real Image Animation
Nov 30, 2022



Nerf-based Generative models have shown impressive capacity in generating high-quality images with consistent 3D geometry. Despite successful synthesis of fake identity images randomly sampled from latent space, adopting these models for generating face images of real subjects is still a challenging task due to its so-called inversion issue. In this paper, we propose a universal method to surgically fine-tune these NeRF-GAN models in order to achieve high-fidelity animation of real subjects only by a single image. Given the optimized latent code for an out-of-domain real image, we employ 2D loss functions on the rendered image to reduce the identity gap. Furthermore, our method leverages explicit and implicit 3D regularizations using the in-domain neighborhood samples around the optimized latent code to remove geometrical and visual artifacts. Our experiments confirm the effectiveness of our method in realistic, high-fidelity, and 3D consistent animation of real faces on multiple NeRF-GAN models across different datasets.
AniFaceGAN: Animatable 3D-Aware Face Image Generation for Video Avatars
Oct 12, 2022

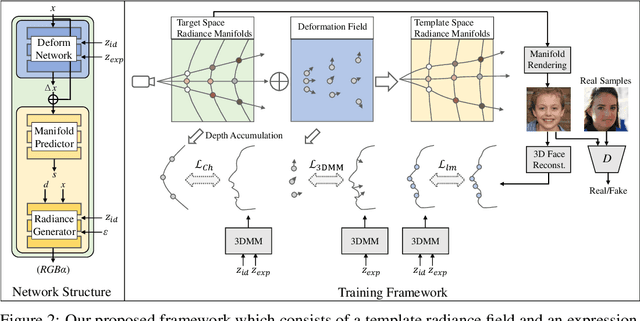
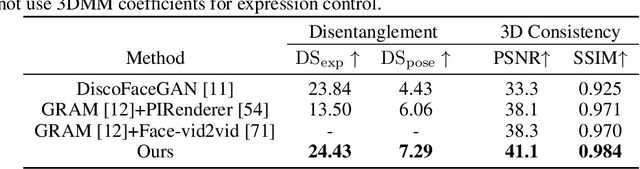
Although 2D generative models have made great progress in face image generation and animation, they often suffer from undesirable artifacts such as 3D inconsistency when rendering images from different camera viewpoints. This prevents them from synthesizing video animations indistinguishable from real ones. Recently, 3D-aware GANs extend 2D GANs for explicit disentanglement of camera pose by leveraging 3D scene representations. These methods can well preserve the 3D consistency of the generated images across different views, yet they cannot achieve fine-grained control over other attributes, among which facial expression control is arguably the most useful and desirable for face animation. In this paper, we propose an animatable 3D-aware GAN for multiview consistent face animation generation. The key idea is to decompose the 3D representation of the 3D-aware GAN into a template field and a deformation field, where the former represents different identities with a canonical expression, and the latter characterizes expression variations of each identity. To achieve meaningful control over facial expressions via deformation, we propose a 3D-level imitative learning scheme between the generator and a parametric 3D face model during adversarial training of the 3D-aware GAN. This helps our method achieve high-quality animatable face image generation with strong visual 3D consistency, even though trained with only unstructured 2D images. Extensive experiments demonstrate our superior performance over prior works. Project page: https://yuewuhkust.github.io/AniFaceGAN
Hierarchical Neyman-Pearson Classification for Prioritizing Severe Disease Categories in COVID-19 Patient Data
Oct 01, 2022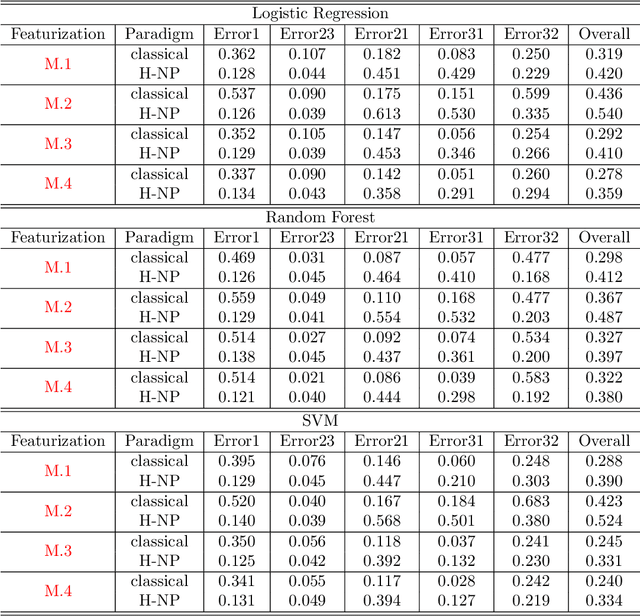
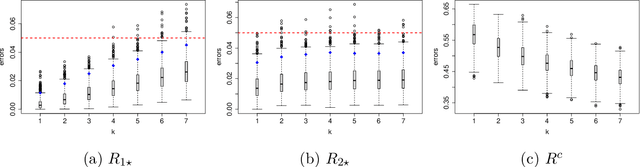
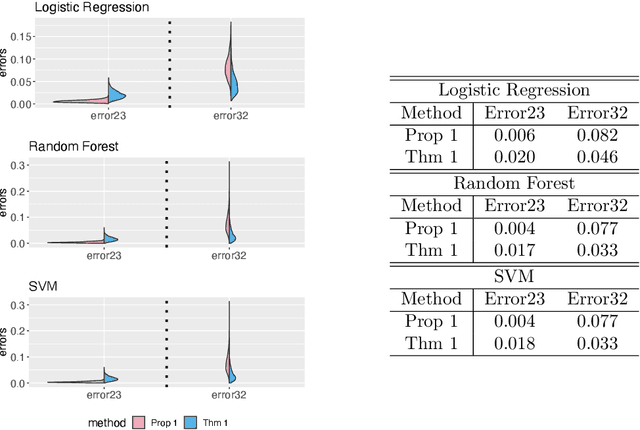
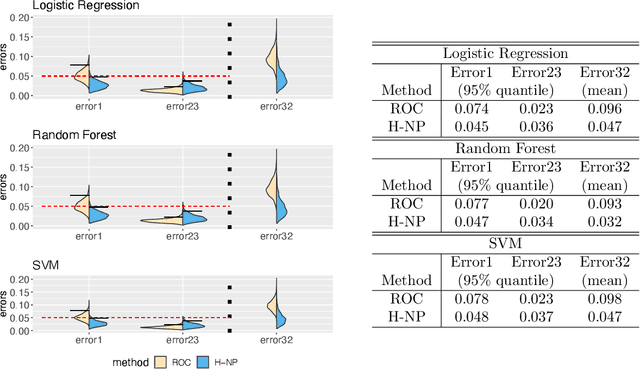
COVID-19 has a spectrum of disease severity, ranging from asymptomatic to requiring hospitalization. Providing appropriate medical care to severe patients is crucial to reduce mortality risks. Hence, in classifying patients into severity categories, the more important classification errors are "under-diagnosis", in which patients are misclassified into less severe categories and thus receive insufficient medical care. The Neyman-Pearson (NP) classification paradigm has been developed to prioritize the designated type of error. However, current NP procedures are either for binary classification or do not provide high probability controls on the prioritized errors in multi-class classification. Here, we propose a hierarchical NP (H-NP) framework and an umbrella algorithm that generally adapts to popular classification methods and controls the under-diagnosis errors with high probability. On an integrated collection of single-cell RNA-seq (scRNA-seq) datasets for 740 patients, we explore ways of featurization and demonstrate the efficacy of the H-NP algorithm in controlling the under-diagnosis errors regardless of featurization. Beyond COVID-19 severity classification, the H-NP algorithm generally applies to multi-class classification problems, where classes have a priority order.
Generative Deformable Radiance Fields for Disentangled Image Synthesis of Topology-Varying Objects
Sep 09, 2022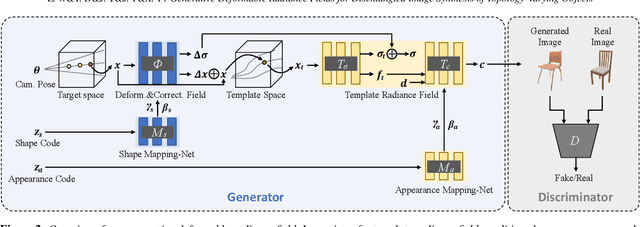
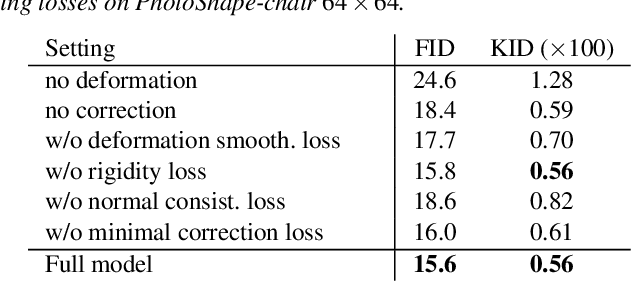
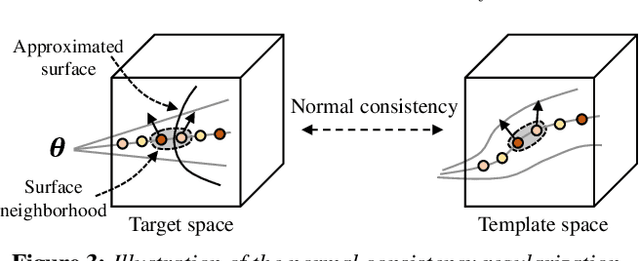
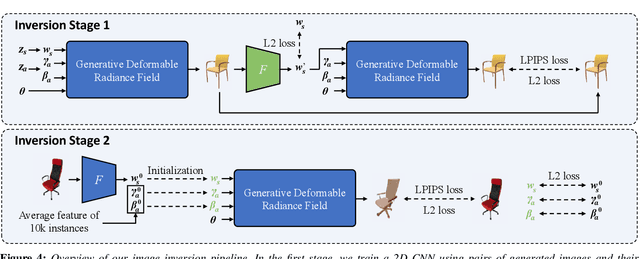
3D-aware generative models have demonstrated their superb performance to generate 3D neural radiance fields (NeRF) from a collection of monocular 2D images even for topology-varying object categories. However, these methods still lack the capability to separately control the shape and appearance of the objects in the generated radiance fields. In this paper, we propose a generative model for synthesizing radiance fields of topology-varying objects with disentangled shape and appearance variations. Our method generates deformable radiance fields, which builds the dense correspondence between the density fields of the objects and encodes their appearances in a shared template field. Our disentanglement is achieved in an unsupervised manner without introducing extra labels to previous 3D-aware GAN training. We also develop an effective image inversion scheme for reconstructing the radiance field of an object in a real monocular image and manipulating its shape and appearance. Experiments show that our method can successfully learn the generative model from unstructured monocular images and well disentangle the shape and appearance for objects (e.g., chairs) with large topological variance. The model trained on synthetic data can faithfully reconstruct the real object in a given single image and achieve high-quality texture and shape editing results.
Semantic Segmentation-Assisted Instance Feature Fusion for Multi-Level 3D Part Instance Segmentation
Aug 09, 2022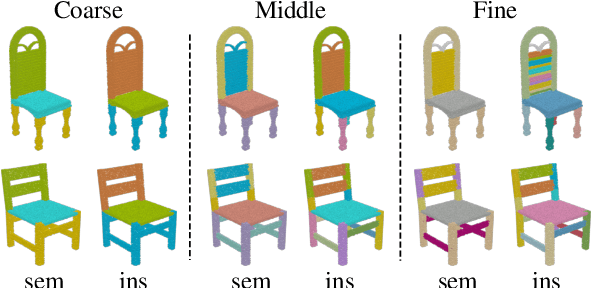
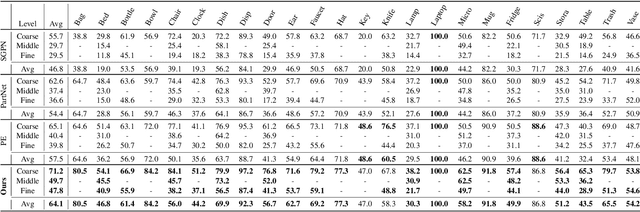
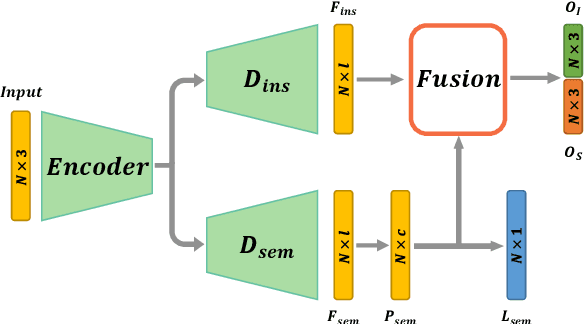

Recognizing 3D part instances from a 3D point cloud is crucial for 3D structure and scene understanding. Several learning-based approaches use semantic segmentation and instance center prediction as training tasks and fail to further exploit the inherent relationship between shape semantics and part instances. In this paper, we present a new method for 3D part instance segmentation. Our method exploits semantic segmentation to fuse nonlocal instance features, such as center prediction, and further enhances the fusion scheme in a multi- and cross-level way. We also propose a semantic region center prediction task to train and leverage the prediction results to improve the clustering of instance points. Our method outperforms existing methods with a large-margin improvement in the PartNet benchmark. We also demonstrate that our feature fusion scheme can be applied to other existing methods to improve their performance in indoor scene instance segmentation tasks.
Deep Deformable 3D Caricatures with Learned Shape Control
Jul 29, 2022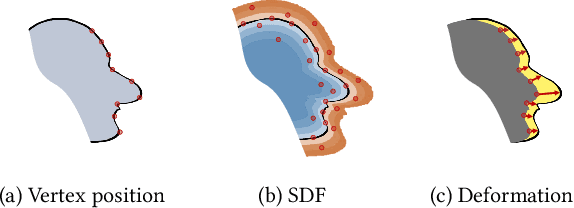
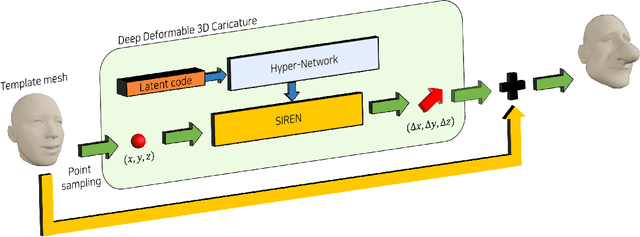


A 3D caricature is an exaggerated 3D depiction of a human face. The goal of this paper is to model the variations of 3D caricatures in a compact parameter space so that we can provide a useful data-driven toolkit for handling 3D caricature deformations. To achieve the goal, we propose an MLP-based framework for building a deformable surface model, which takes a latent code and produces a 3D surface. In the framework, a SIREN MLP models a function that takes a 3D position on a fixed template surface and returns a 3D displacement vector for the input position. We create variations of 3D surfaces by learning a hypernetwork that takes a latent code and produces the parameters of the MLP. Once learned, our deformable model provides a nice editing space for 3D caricatures, supporting label-based semantic editing and point-handle-based deformation, both of which produce highly exaggerated and natural 3D caricature shapes. We also demonstrate other applications of our deformable model, such as automatic 3D caricature creation.
Sparse Ellipsometry: Portable Acquisition of Polarimetric SVBRDF and Shape with Unstructured Flash Photography
Jul 09, 2022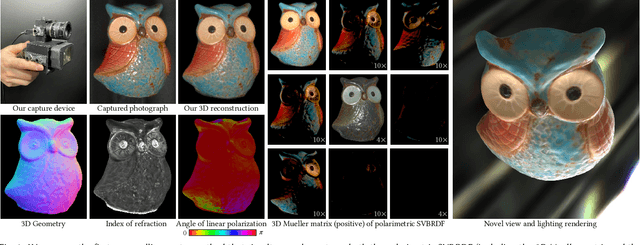
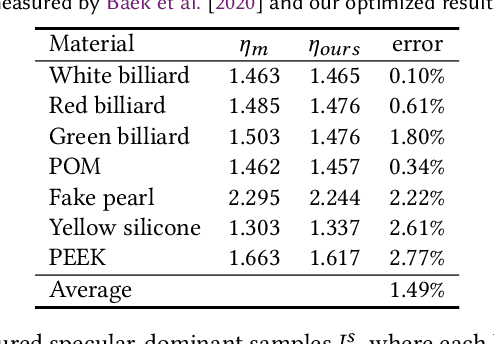
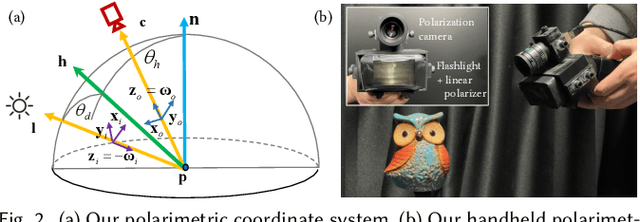
Ellipsometry techniques allow to measure polarization information of materials, requiring precise rotations of optical components with different configurations of lights and sensors. This results in cumbersome capture devices, carefully calibrated in lab conditions, and in very long acquisition times, usually in the order of a few days per object. Recent techniques allow to capture polarimetric spatially-varying reflectance information, but limited to a single view, or to cover all view directions, but limited to spherical objects made of a single homogeneous material. We present sparse ellipsometry, a portable polarimetric acquisition method that captures both polarimetric SVBRDF and 3D shape simultaneously. Our handheld device consists of off-the-shelf, fixed optical components. Instead of days, the total acquisition time varies between twenty and thirty minutes per object. We develop a complete polarimetric SVBRDF model that includes diffuse and specular components, as well as single scattering, and devise a novel polarimetric inverse rendering algorithm with data augmentation of specular reflection samples via generative modeling. Our results show a strong agreement with a recent ground-truth dataset of captured polarimetric BRDFs of real-world objects.