 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTarget-aware Dual Adversarial Learning and a Multi-scenario Multi-Modality Benchmark to Fuse Infrared and Visible for Object Detection
Mar 30, 2022

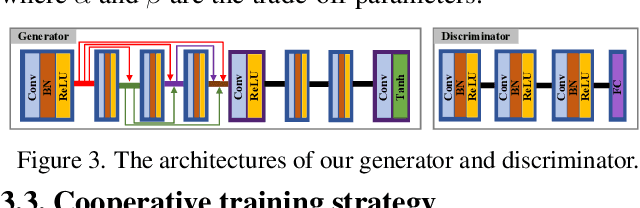

This study addresses the issue of fusing infrared and visible images that appear differently for object detection. Aiming at generating an image of high visual quality, previous approaches discover commons underlying the two modalities and fuse upon the common space either by iterative optimization or deep networks. These approaches neglect that modality differences implying the complementary information are extremely important for both fusion and subsequent detection task. This paper proposes a bilevel optimization formulation for the joint problem of fusion and detection, and then unrolls to a target-aware Dual Adversarial Learning (TarDAL) network for fusion and a commonly used detection network. The fusion network with one generator and dual discriminators seeks commons while learning from differences, which preserves structural information of targets from the infrared and textural details from the visible. Furthermore, we build a synchronized imaging system with calibrated infrared and optical sensors, and collect currently the most comprehensive benchmark covering a wide range of scenarios. Extensive experiments on several public datasets and our benchmark demonstrate that our method outputs not only visually appealing fusion but also higher detection mAP than the state-of-the-art approaches.
Automated Learning for Deformable Medical Image Registration by Jointly Optimizing Network Architectures and Objective Functions
Mar 14, 2022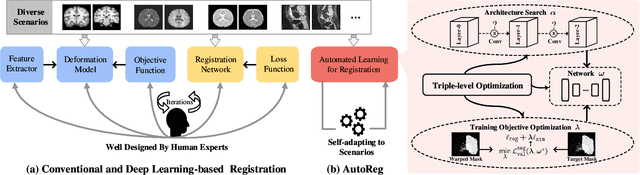
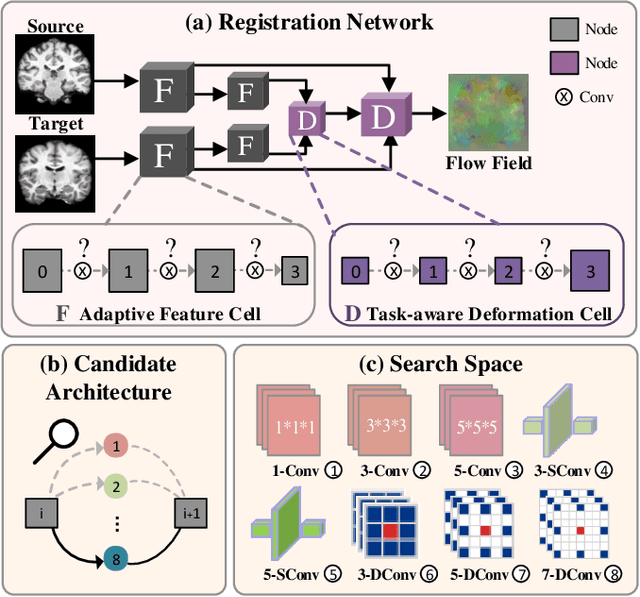
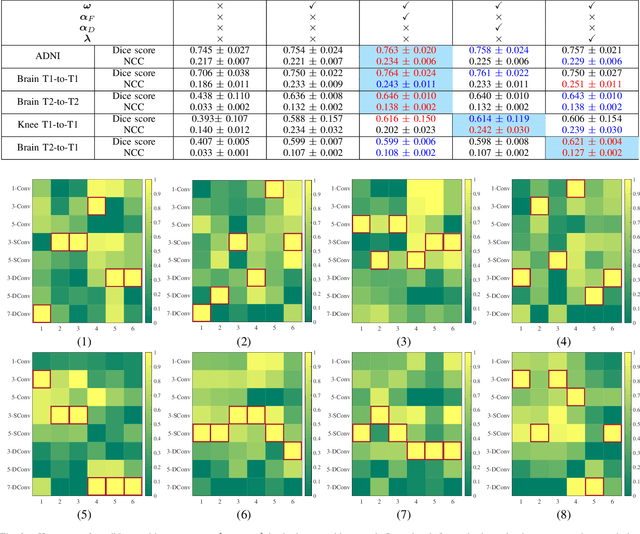
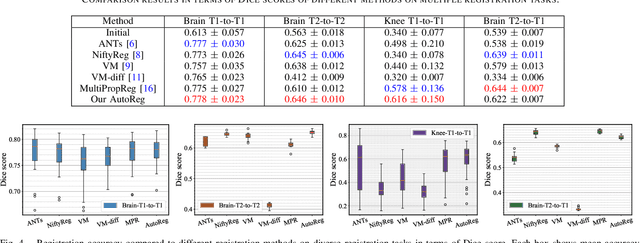
Deformable image registration plays a critical role in various tasks of medical image analysis. A successful registration algorithm, either derived from conventional energy optimization or deep networks requires tremendous efforts from computer experts to well design registration energy or to carefully tune network architectures for the specific type of medical data. To tackle the aforementioned problems, this paper proposes an automated learning registration algorithm (AutoReg) that cooperatively optimizes both architectures and their corresponding training objectives, enabling non-computer experts, e.g., medical/clinical users, to conveniently find off-the-shelf registration algorithms for diverse scenarios. Specifically, we establish a triple-level framework to deduce registration network architectures and objectives with an auto-searching mechanism and cooperating optimization. We conduct image registration experiments on multi-site volume datasets and various registration tasks. Extensive results demonstrate that our AutoReg may automatically learn an optimal deep registration network for given volumes and achieve state-of-the-art performance, also significantly improving computation efficiency than the mainstream UNet architectures (from 0.558 to 0.270 seconds for a 3D image pair on the same configuration).
Cross-SRN: Structure-Preserving Super-Resolution Network with Cross Convolution
Jan 07, 2022



It is challenging to restore low-resolution (LR) images to super-resolution (SR) images with correct and clear details. Existing deep learning works almost neglect the inherent structural information of images, which acts as an important role for visual perception of SR results. In this paper, we design a hierarchical feature exploitation network to probe and preserve structural information in a multi-scale feature fusion manner. First, we propose a cross convolution upon traditional edge detectors to localize and represent edge features. Then, cross convolution blocks (CCBs) are designed with feature normalization and channel attention to consider the inherent correlations of features. Finally, we leverage multi-scale feature fusion group (MFFG) to embed the cross convolution blocks and develop the relations of structural features in different scales hierarchically, invoking a lightweight structure-preserving network named as Cross-SRN. Experimental results demonstrate the Cross-SRN achieves competitive or superior restoration performances against the state-of-the-art methods with accurate and clear structural details. Moreover, we set a criterion to select images with rich structural textures. The proposed Cross-SRN outperforms the state-of-the-art methods on the selected benchmark, which demonstrates that our network has a significant advantage in preserving edges.
Learning Deep Context-Sensitive Decomposition for Low-Light Image Enhancement
Dec 09, 2021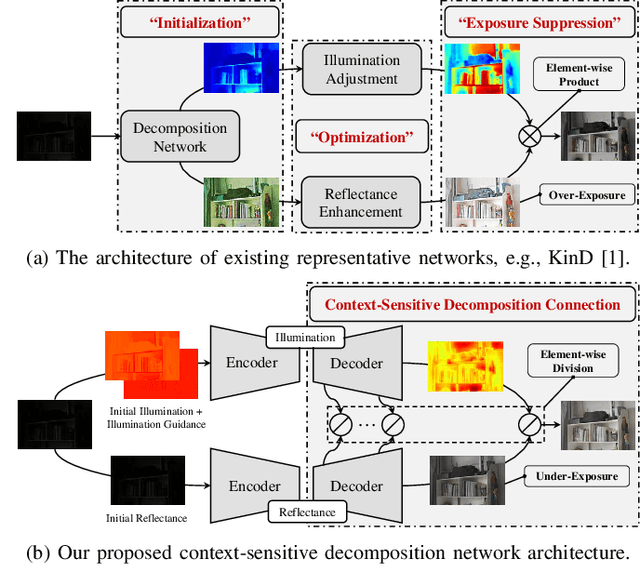
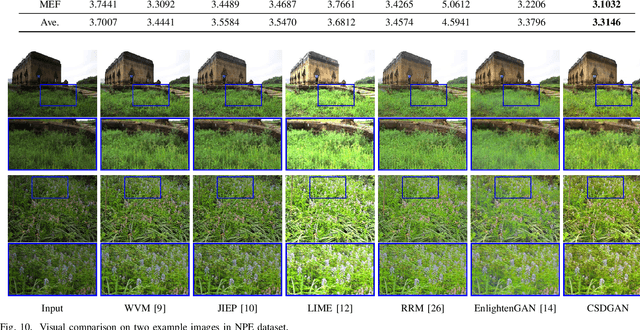

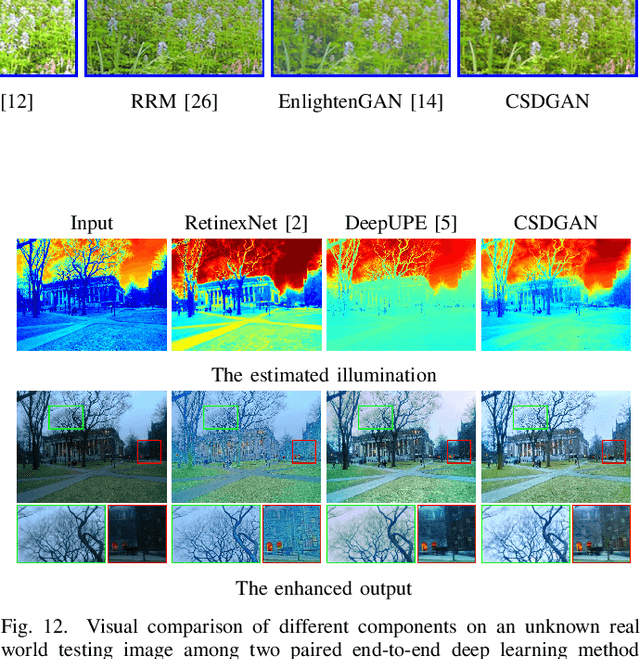
Enhancing the quality of low-light images plays a very important role in many image processing and multimedia applications. In recent years, a variety of deep learning techniques have been developed to address this challenging task. A typical framework is to simultaneously estimate the illumination and reflectance, but they disregard the scene-level contextual information encapsulated in feature spaces, causing many unfavorable outcomes, e.g., details loss, color unsaturation, artifacts, and so on. To address these issues, we develop a new context-sensitive decomposition network architecture to exploit the scene-level contextual dependencies on spatial scales. More concretely, we build a two-stream estimation mechanism including reflectance and illumination estimation network. We design a novel context-sensitive decomposition connection to bridge the two-stream mechanism by incorporating the physical principle. The spatially-varying illumination guidance is further constructed for achieving the edge-aware smoothness property of the illumination component. According to different training patterns, we construct CSDNet (paired supervision) and CSDGAN (unpaired supervision) to fully evaluate our designed architecture. We test our method on seven testing benchmarks to conduct plenty of analytical and evaluated experiments. Thanks to our designed context-sensitive decomposition connection, we successfully realized excellent enhanced results, which fully indicates our superiority against existing state-of-the-art approaches. Finally, considering the practical needs for high-efficiency, we develop a lightweight CSDNet (named LiteCSDNet) by reducing the number of channels. Further, by sharing an encoder for these two components, we obtain a more lightweight version (SLiteCSDNet for short). SLiteCSDNet just contains 0.0301M parameters but achieves the almost same performance as CSDNet.
Learning with Nested Scene Modeling and Cooperative Architecture Search for Low-Light Vision
Dec 09, 2021
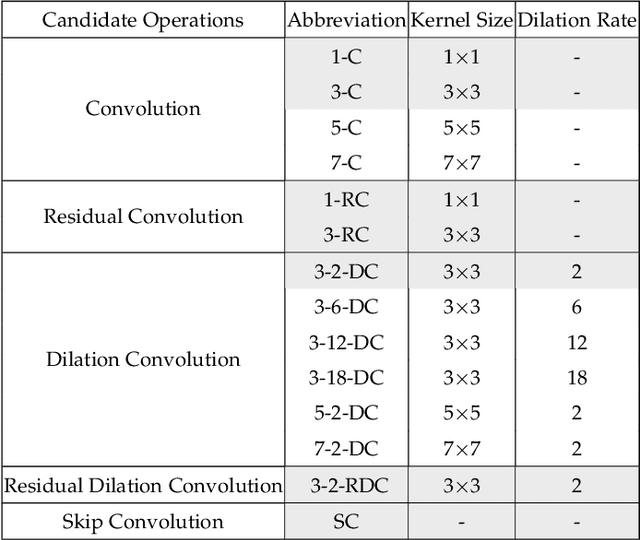
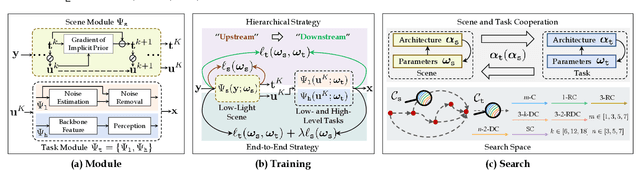
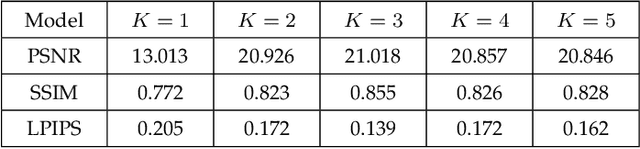
Images captured from low-light scenes often suffer from severe degradations, including low visibility, color cast and intensive noises, etc. These factors not only affect image qualities, but also degrade the performance of downstream Low-Light Vision (LLV) applications. A variety of deep learning methods have been proposed to enhance the visual quality of low-light images. However, these approaches mostly rely on significant architecture engineering to obtain proper low-light models and often suffer from high computational burden. Furthermore, it is still challenging to extend these enhancement techniques to handle other LLVs. To partially address above issues, we establish Retinex-inspired Unrolling with Architecture Search (RUAS), a general learning framework, which not only can address low-light enhancement task, but also has the flexibility to handle other more challenging downstream vision applications. Specifically, we first establish a nested optimization formulation, together with an unrolling strategy, to explore underlying principles of a series of LLV tasks. Furthermore, we construct a differentiable strategy to cooperatively search specific scene and task architectures for RUAS. Last but not least, we demonstrate how to apply RUAS for both low- and high-level LLV applications (e.g., enhancement, detection and segmentation). Extensive experiments verify the flexibility, effectiveness, and efficiency of RUAS.
Triple-level Model Inferred Collaborative Network Architecture for Video Deraining
Nov 08, 2021
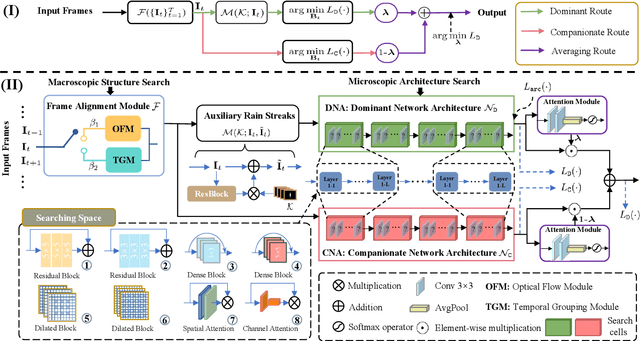
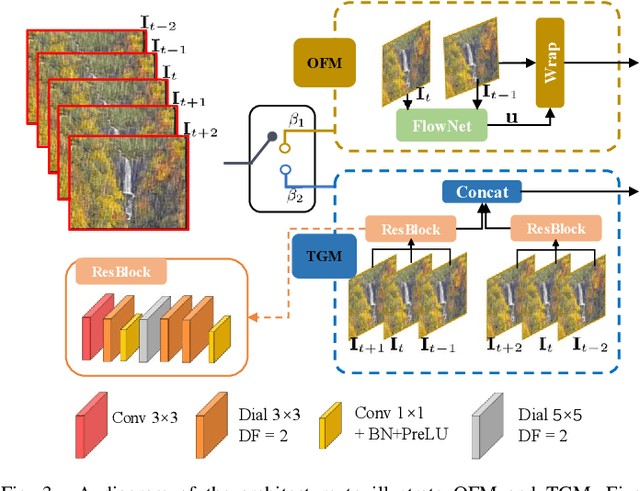
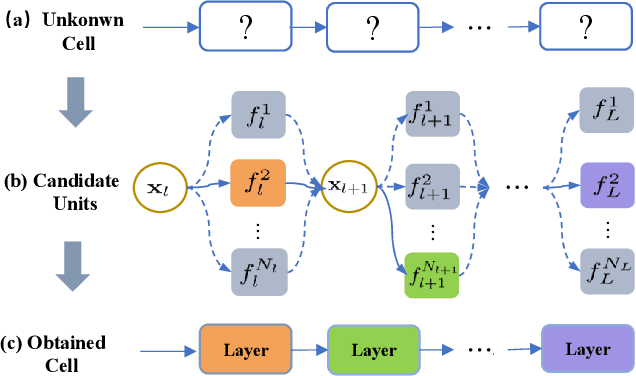
Video deraining is an important issue for outdoor vision systems and has been investigated extensively. However, designing optimal architectures by the aggregating model formation and data distribution is a challenging task for video deraining. In this paper, we develop a model-guided triple-level optimization framework to deduce network architecture with cooperating optimization and auto-searching mechanism, named Triple-level Model Inferred Cooperating Searching (TMICS), for dealing with various video rain circumstances. In particular, to mitigate the problem that existing methods cannot cover various rain streaks distribution, we first design a hyper-parameter optimization model about task variable and hyper-parameter. Based on the proposed optimization model, we design a collaborative structure for video deraining. This structure includes Dominant Network Architecture (DNA) and Companionate Network Architecture (CNA) that is cooperated by introducing an Attention-based Averaging Scheme (AAS). To better explore inter-frame information from videos, we introduce a macroscopic structure searching scheme that searches from Optical Flow Module (OFM) and Temporal Grouping Module (TGM) to help restore latent frame. In addition, we apply the differentiable neural architecture searching from a compact candidate set of task-specific operations to discover desirable rain streaks removal architectures automatically. Extensive experiments on various datasets demonstrate that our model shows significant improvements in fidelity and temporal consistency over the state-of-the-art works. Source code is available at https://github.com/vis-opt-group/TMICS.
BEV-SGD: Best Effort Voting SGD for Analog Aggregation Based Federated Learning against Byzantine Attackers
Oct 18, 2021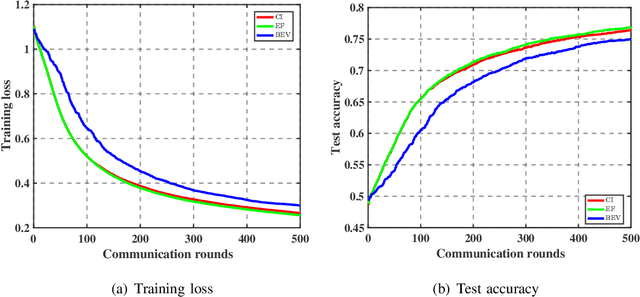
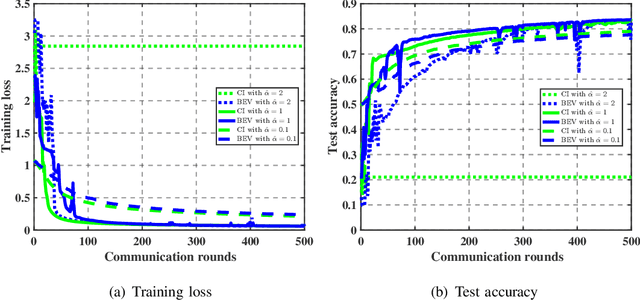
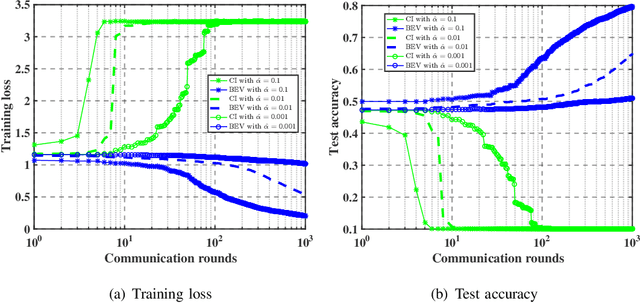
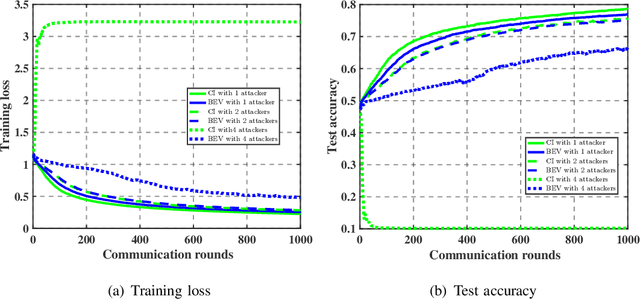
As a promising distributed learning technology, analog aggregation based federated learning over the air (FLOA) provides high communication efficiency and privacy provisioning in edge computing paradigm. When all edge devices (workers) simultaneously upload their local updates to the parameter server (PS) through the commonly shared time-frequency resources, the PS can only obtain the averaged update rather than the individual local ones. As a result, such a concurrent transmission and aggregation scheme reduces the latency and costs of communication but makes FLOA vulnerable to Byzantine attacks which then degrade FLOA performance. For the design of Byzantine-resilient FLOA, this paper starts from analyzing the channel inversion (CI) power control mechanism that is widely used in existing FLOA literature. Our theoretical analysis indicates that although CI can achieve good learning performance in the non-attacking scenarios, it fails to work well with limited defensive capability to Byzantine attacks. Then, we propose a novel defending scheme called best effort voting (BEV) power control policy integrated with stochastic gradient descent (SGD). Our BEV-SGD improves the robustness of FLOA to Byzantine attacks, by allowing all the workers to send their local updates at their maximum transmit power. Under the strongest-attacking circumstance, we derive the expected convergence rates of FLOA with CI and BEV power control policies, respectively. The rate comparison reveals that our BEV-SGD outperforms its counterpart with CI in terms of better convergence behavior, which is verified by experimental simulations.
An Underwater Image Semantic Segmentation Method Focusing on Boundaries and a Real Underwater Scene Semantic Segmentation Dataset
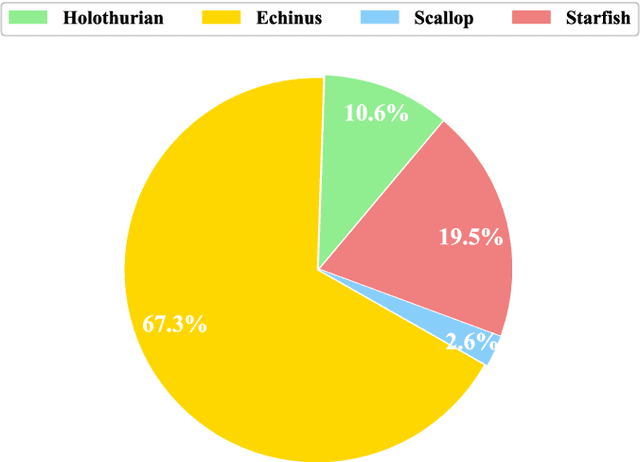
Aug 26, 2021With the development of underwater object grabbing technology, underwater object recognition and segmentation of high accuracy has become a challenge. The existing underwater object detection technology can only give the general position of an object, unable to give more detailed information such as the outline of the object, which seriously affects the grabbing efficiency. To address this problem, we label and establish the first underwater semantic segmentation dataset of real scene(DUT-USEG:DUT Underwater Segmentation Dataset). The DUT- USEG dataset includes 6617 images, 1487 of which have semantic segmentation and instance segmentation annotations, and the remaining 5130 images have object detection box annotations. Based on this dataset, we propose a semi-supervised underwater semantic segmentation network focusing on the boundaries(US-Net: Underwater Segmentation Network). By designing a pseudo label generator and a boundary detection subnetwork, this network realizes the fine learning of boundaries between underwater objects and background, and improves the segmentation effect of boundary areas. Experiments show that the proposed method improves by 6.7% in three categories of holothurian, echinus, starfish in DUT-USEG dataset, and achieves state-of-the-art results. The DUT- USEG dataset will be released at https://github.com/baxiyi/DUT-USEG.
A Dataset And Benchmark Of Underwater Object Detection For Robot Picking
Jun 10, 2021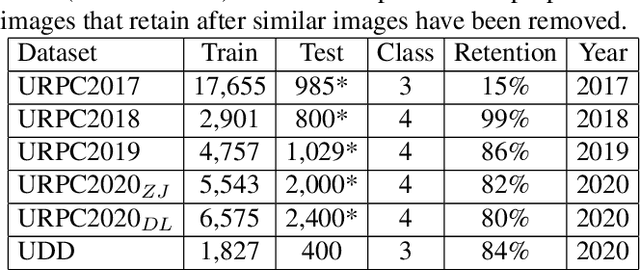

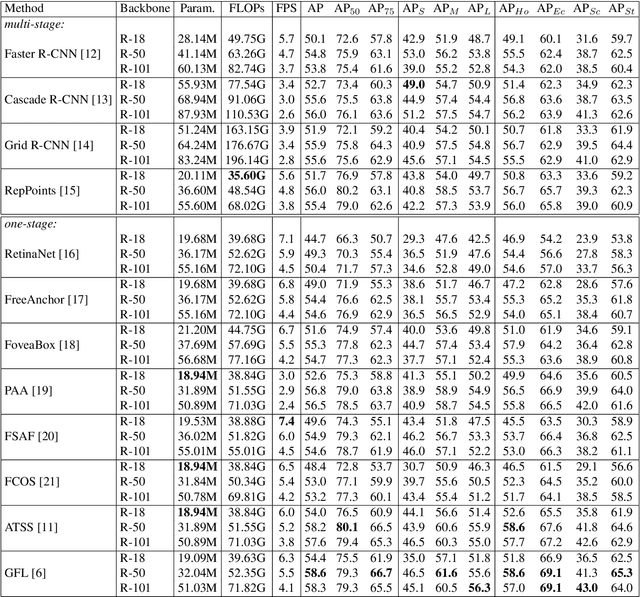
Underwater object detection for robot picking has attracted a lot of interest. However, it is still an unsolved problem due to several challenges. We take steps towards making it more realistic by addressing the following challenges. Firstly, the currently available datasets basically lack the test set annotations, causing researchers must compare their method with other SOTAs on a self-divided test set (from the training set). Training other methods lead to an increase in workload and different researchers divide different datasets, resulting there is no unified benchmark to compare the performance of different algorithms. Secondly, these datasets also have other shortcomings, e.g., too many similar images or incomplete labels. Towards these challenges we introduce a dataset, Detecting Underwater Objects (DUO), and a corresponding benchmark, based on the collection and re-annotation of all relevant datasets. DUO contains a collection of diverse underwater images with more rational annotations. The corresponding benchmark provides indicators of both efficiency and accuracy of SOTAs (under the MMDtection framework) for academic research and industrial applications, where JETSON AGX XAVIER is used to assess detector speed to simulate the robot-embedded environment.
Joint Optimization of Communications and Federated Learning Over the Air
Apr 08, 2021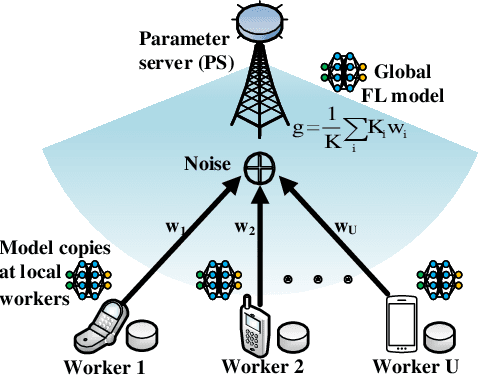
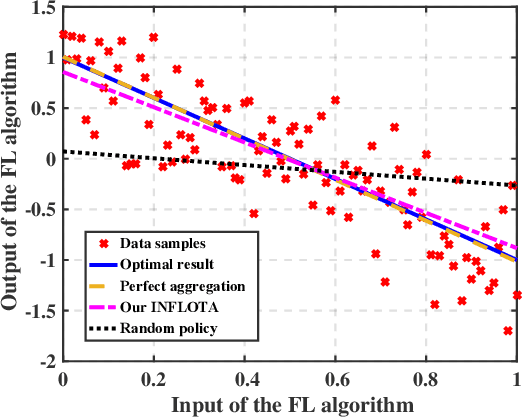
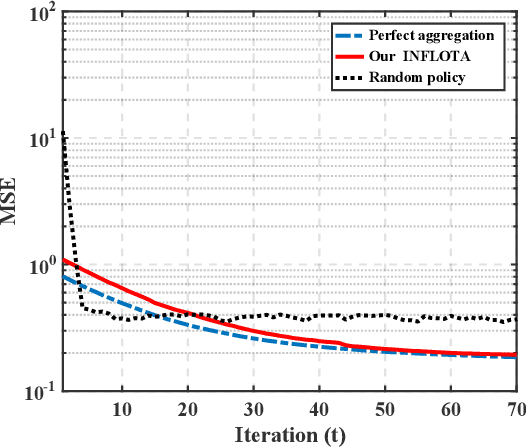
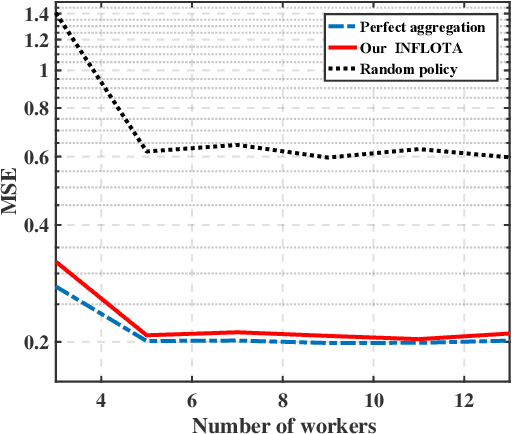
Federated learning (FL) is an attractive paradigm for making use of rich distributed data while protecting data privacy. Nonetheless, nonideal communication links and limited transmission resources have become the bottleneck of the implementation of fast and accurate FL. In this paper, we study joint optimization of communications and FL based on analog aggregation transmission in realistic wireless networks. We first derive a closed-form expression for the expected convergence rate of FL over the air, which theoretically quantifies the impact of analog aggregation on FL. Based on the analytical result, we develop a joint optimization model for accurate FL implementation, which allows a parameter server to select a subset of workers and determine an appropriate power scaling factor. Since the practical setting of FL over the air encounters unobservable parameters, we reformulate the joint optimization of worker selection and power allocation using controlled approximation. Finally, we efficiently solve the resulting mixed-integer programming problem via a simple yet optimal finite-set search method by reducing the search space. Simulation results show that the proposed solutions developed for realistic wireless analog channels outperform a benchmark method, and achieve comparable performance of the ideal case where FL is implemented over noise-free wireless channels.