 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynchronous Bidirectional Learning for Multilingual Lip Reading
May 12, 2020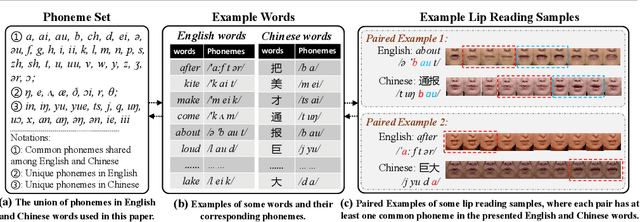
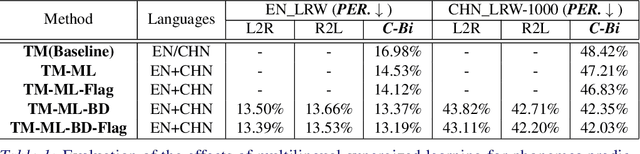
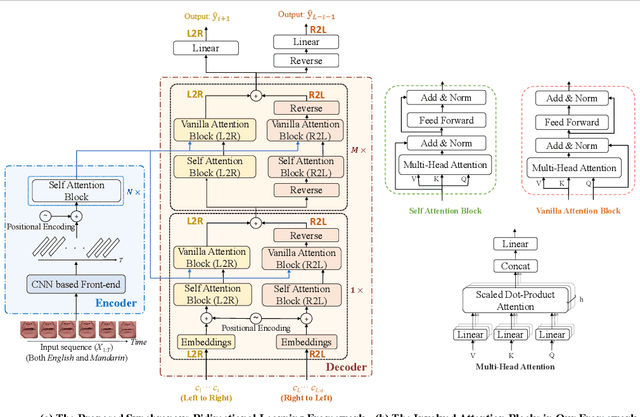
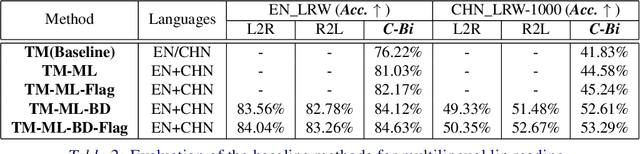
Lip reading has received increasing attention in recent years. This paper focuses on the synergy of multilingual lip reading. There are more than 7,000 languages in the world, which implies that it is impractical to train separate lip reading models by collecting large-scale data per language. Although each language has its own linguistic and pronunciation features, the lip movements of all languages share similar patterns. Based on this idea, in this paper, we try to explore the synergized learning of multilingual lip reading, and further propose a synchronous bidirectional learning(SBL) framework for effective synergy of multilingual lip reading. Firstly, we introduce the phonemes as our modeling units for the multilingual setting. Similar phoneme always leads to similar visual patterns. The multilingual setting would increase both the quantity and the diversity of each phoneme shared among different languages. So the learning for the multilingual target should bring improvement to the prediction of phonemes. Then, a SBL block is proposed to infer the target unit when given its previous and later context. The rules for each specific language which the model itself judges to be is learned in this fill-in-the-blank manner. To make the learning process more targeted at each particular language, we introduce an extra task of predicting the language identity in the learning process. Finally, we perform a thorough comparison on LRW (English) and LRW-1000(Mandarin). The results outperform the existing state of the art by a large margin, and show the promising benefits from the synergized learning of different languages.
Single-Side Domain Generalization for Face Anti-Spoofing
Apr 29, 2020



Existing domain generalization methods for face anti-spoofing endeavor to extract common differentiation features to improve the generalization. However, due to large distribution discrepancies among fake faces of different domains, it is difficult to seek a compact and generalized feature space for the fake faces. In this work, we propose an end-to-end single-side domain generalization framework (SSDG) to improve the generalization ability of face anti-spoofing. The main idea is to learn a generalized feature space, where the feature distribution of the real faces is compact while that of the fake ones is dispersed among domains but compact within each domain. Specifically, a feature generator is trained to make only the real faces from different domains undistinguishable, but not for the fake ones, thus forming a single-side adversarial learning. Moreover, an asymmetric triplet loss is designed to constrain the fake faces of different domains separated while the real ones aggregated. The above two points are integrated into a unified framework in an end-to-end training manner, resulting in a more generalized class boundary, especially good for samples from novel domains. Feature and weight normalization is incorporated to further improve the generalization ability. Extensive experiments show that our proposed approach is effective and outperforms the state-of-the-art methods on four public databases.
Dynamic R-CNN: Towards High Quality Object Detection via Dynamic Training
Apr 13, 2020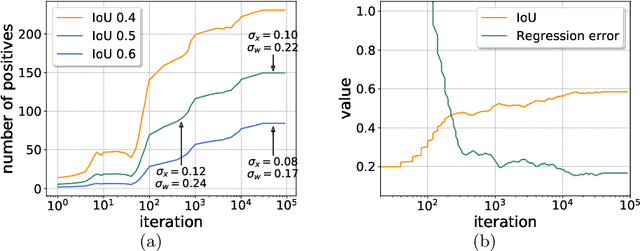
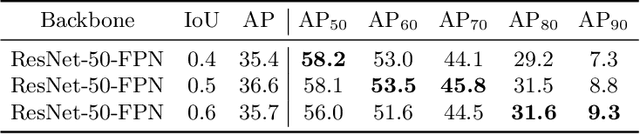
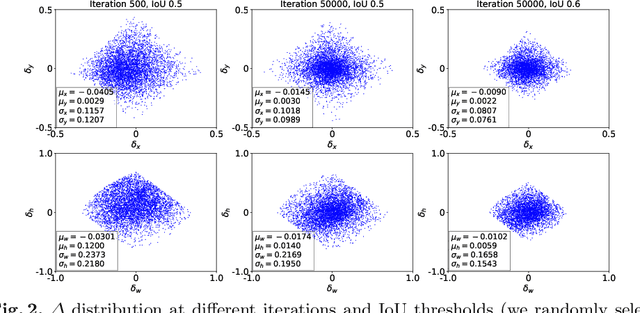
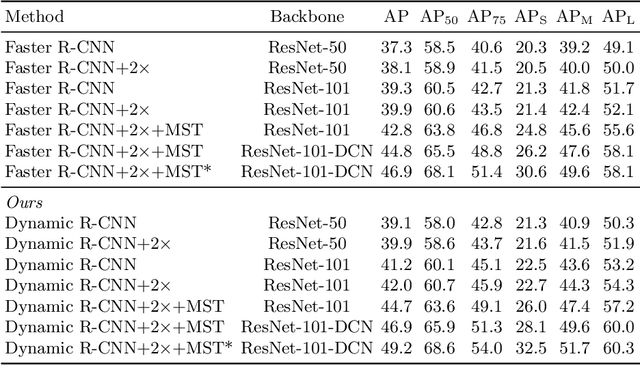
Although two-stage object detectors have continuously advanced the state-of-the-art performance in recent years, the training process itself is far from crystal. In this work, we first point out the inconsistency problem between the fixed network settings and the dynamic training procedure, which greatly affects the performance. For example, the fixed label assignment strategy and regression loss function cannot fit the distribution change of proposals and thus are harmful to training high quality detectors. Consequently, we propose Dynamic R-CNN to adjust the label assignment criteria (IoU threshold) and the shape of regression loss function (parameters of SmoothL1 Loss) automatically based on the statistics of proposals during training. This dynamic design makes better use of the training samples and pushes the detector to fit more high quality samples. Specifically, our method improves upon ResNet-50-FPN baseline with 1.9% AP and 5.5% AP$_{90}$ on the MS COCO dataset with no extra overhead. Codes and models are available at https://github.com/hkzhang95/DynamicRCNN.
Self-supervised Equivariant Attention Mechanism for Weakly Supervised Semantic Segmentation
Apr 09, 2020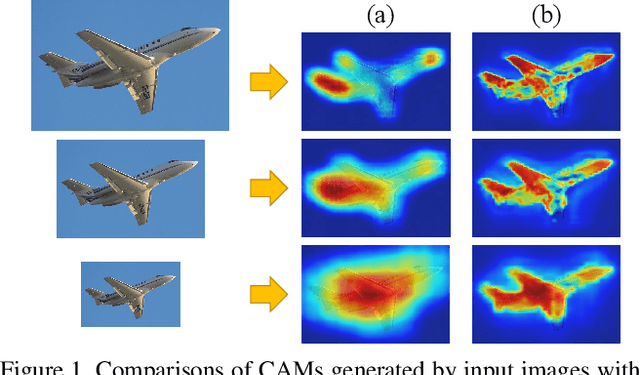
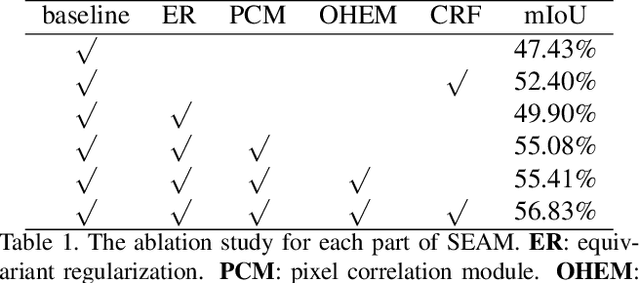
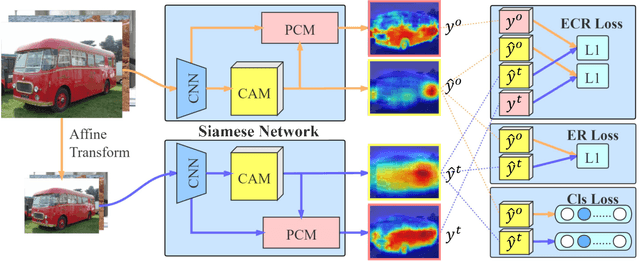

Image-level weakly supervised semantic segmentation is a challenging problem that has been deeply studied in recent years. Most of advanced solutions exploit class activation map (CAM). However, CAMs can hardly serve as the object mask due to the gap between full and weak supervisions. In this paper, we propose a self-supervised equivariant attention mechanism (SEAM) to discover additional supervision and narrow the gap. Our method is based on the observation that equivariance is an implicit constraint in fully supervised semantic segmentation, whose pixel-level labels take the same spatial transformation as the input images during data augmentation. However, this constraint is lost on the CAMs trained by image-level supervision. Therefore, we propose consistency regularization on predicted CAMs from various transformed images to provide self-supervision for network learning. Moreover, we propose a pixel correlation module (PCM), which exploits context appearance information and refines the prediction of current pixel by its similar neighbors, leading to further improvement on CAMs consistency. Extensive experiments on PASCAL VOC 2012 dataset demonstrate our method outperforms state-of-the-art methods using the same level of supervision. The code is released online.
Cross-domain Face Presentation Attack Detection via Multi-domain Disentangled Representation Learning
Apr 04, 2020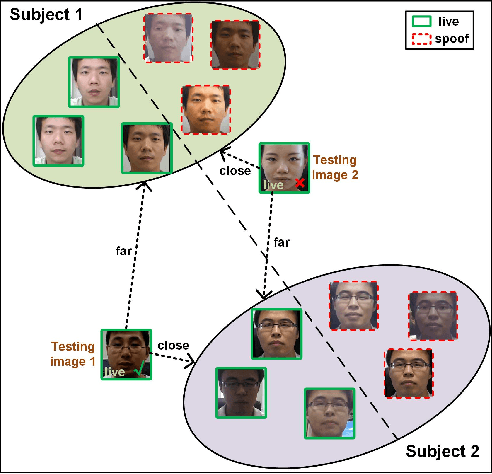
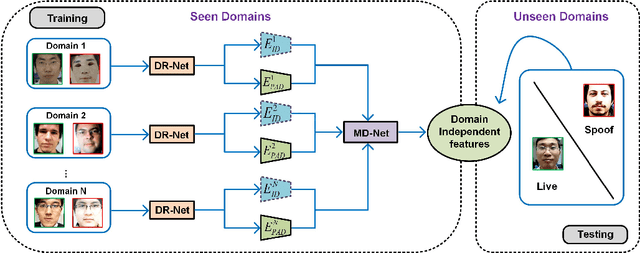
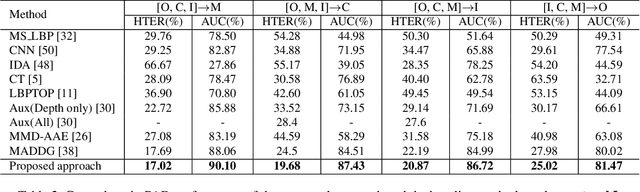
Face presentation attack detection (PAD) has been an urgent problem to be solved in the face recognition systems. Conventional approaches usually assume the testing and training are within the same domain; as a result, they may not generalize well into unseen scenarios because the representations learned for PAD may overfit to the subjects in the training set. In light of this, we propose an efficient disentangled representation learning for cross-domain face PAD. Our approach consists of disentangled representation learning (DR-Net) and multi-domain learning (MD-Net). DR-Net learns a pair of encoders via generative models that can disentangle PAD informative features from subject discriminative features. The disentangled features from different domains are fed to MD-Net which learns domain-independent features for the final cross-domain face PAD task. Extensive experiments on several public datasets validate the effectiveness of the proposed approach for cross-domain PAD.
Multi-Modal Graph Neural Network for Joint Reasoning on Vision and Scene Text
Mar 31, 2020
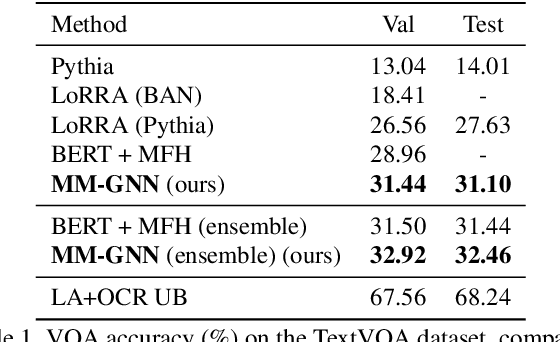

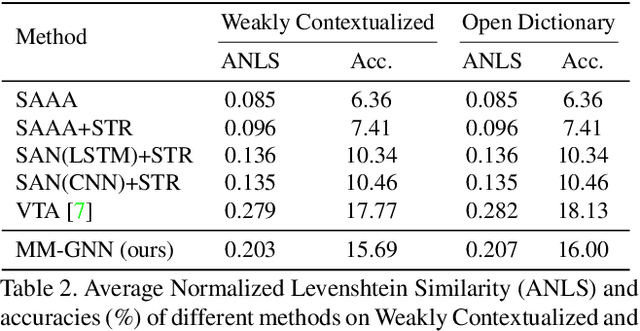
Answering questions that require reading texts in an image is challenging for current models. One key difficulty of this task is that rare, polysemous, and ambiguous words frequently appear in images, e.g., names of places, products, and sports teams. To overcome this difficulty, only resorting to pre-trained word embedding models is far from enough. A desired model should utilize the rich information in multiple modalities of the image to help understand the meaning of scene texts, e.g., the prominent text on a bottle is most likely to be the brand. Following this idea, we propose a novel VQA approach, Multi-Modal Graph Neural Network (MM-GNN). It first represents an image as a graph consisting of three sub-graphs, depicting visual, semantic, and numeric modalities respectively. Then, we introduce three aggregators which guide the message passing from one graph to another to utilize the contexts in various modalities, so as to refine the features of nodes. The updated nodes have better features for the downstream question answering module. Experimental evaluations show that our MM-GNN represents the scene texts better and obviously facilitates the performances on two VQA tasks that require reading scene texts.
Mutual Information Maximization for Effective Lip Reading
Mar 13, 2020

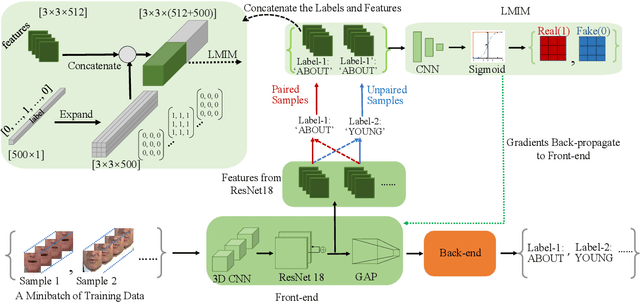
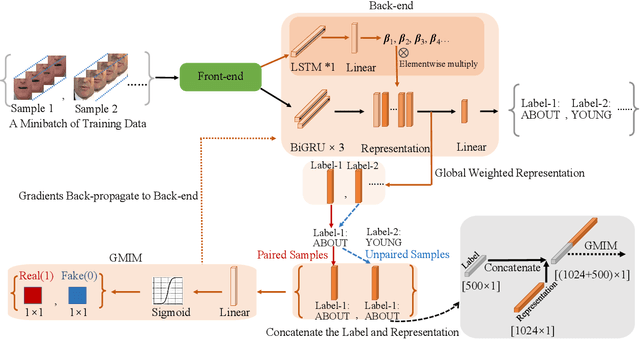
Lip reading has received an increasing research interest in recent years due to the rapid development of deep learning and its widespread potential applications. One key point to obtain good performance for the lip reading task depends heavily on how effective the representation can be to capture the lip movement information and meanwhile to resist the noises resulted from the change of pose, lighting conditions, speaker's appearance and so on. Towards this target, we propose to introduce the mutual information constraints on both the local feature's level and the global sequence's level to enhance the relations of the features with the speech content. On the one hand, we constraint the features generated at each time step to enable them carry a strong relation with the speech content by imposing the local mutual information maximization constraint (LMIM), leading to improvements over the model's ability to discover fine-grained lip movements and the fine-grained differences among words with similar pronunciation, such as ``spend'' and ``spending''. On the other hand, we introduce the mutual information maximization constraint on the global sequence's level (GMIM), to make the model be able to pay more attention to discriminate key frames related with the speech content, and less to various noises appeared in the speaking process. By combining these two advantages together, the proposed method is expected to be both discriminative and robust for effective lip reading. To verify this method, we evaluate on two large-scale benchmark. We perform a detailed analysis and comparison on several aspects, including the comparison of the LMIM and GMIM with the baseline, the visualization of the learned representation and so on. The results not only prove the effectiveness of the proposed method but also report new state-of-the-art performance on both the two benchmarks.
Deformation Flow Based Two-Stream Network for Lip Reading
Mar 13, 2020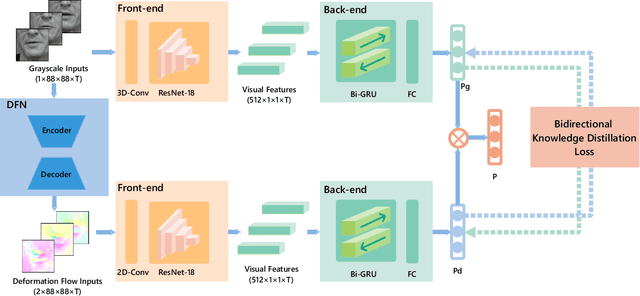
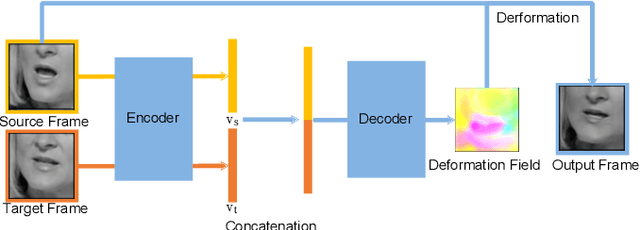

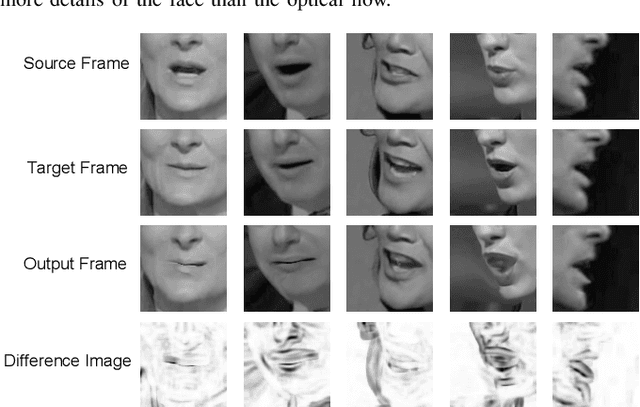
Lip reading is the task of recognizing the speech content by analyzing movements in the lip region when people are speaking. Observing on the continuity in adjacent frames in the speaking process, and the consistency of the motion patterns among different speakers when they pronounce the same phoneme, we model the lip movements in the speaking process as a sequence of apparent deformations in the lip region. Specifically, we introduce a Deformation Flow Network (DFN) to learn the deformation flow between adjacent frames, which directly captures the motion information within the lip region. The learned deformation flow is then combined with the original grayscale frames with a two-stream network to perform lip reading. Different from previous two-stream networks, we make the two streams learn from each other in the learning process by introducing a bidirectional knowledge distillation loss to train the two branches jointly. Owing to the complementary cues provided by different branches, the two-stream network shows a substantial improvement over using either single branch. A thorough experimental evaluation on two large-scale lip reading benchmarks is presented with detailed analysis. The results accord with our motivation, and show that our method achieves state-of-the-art or comparable performance on these two challenging datasets.
Pseudo-Convolutional Policy Gradient for Sequence-to-Sequence Lip-Reading
Mar 09, 2020
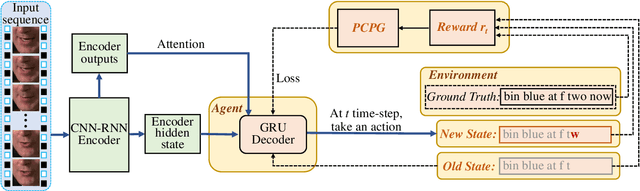
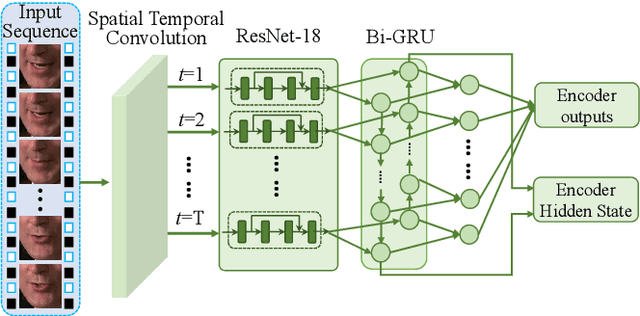
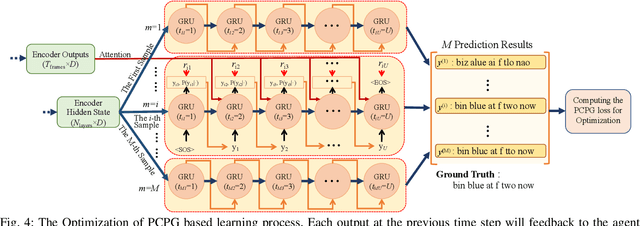
Lip-reading aims to infer the speech content from the lip movement sequence and can be seen as a typical sequence-to-sequence (seq2seq) problem which translates the input image sequence of lip movements to the text sequence of the speech content. However, the traditional learning process of seq2seq models always suffers from two problems: the exposure bias resulted from the strategy of "teacher-forcing", and the inconsistency between the discriminative optimization target (usually the cross-entropy loss) and the final evaluation metric (usually the character/word error rate). In this paper, we propose a novel pseudo-convolutional policy gradient (PCPG) based method to address these two problems. On the one hand, we introduce the evaluation metric (refers to the character error rate in this paper) as a form of reward to optimize the model together with the original discriminative target. On the other hand, inspired by the local perception property of convolutional operation, we perform a pseudo-convolutional operation on the reward and loss dimension, so as to take more context around each time step into account to generate a robust reward and loss for the whole optimization. Finally, we perform a thorough comparison and evaluation on both the word-level and sentence-level benchmarks. The results show a significant improvement over other related methods, and report either a new state-of-the-art performance or a competitive accuracy on all these challenging benchmarks, which clearly proves the advantages of our approach.
Can We Read Speech Beyond the Lips? Rethinking RoI Selection for Deep Visual Speech Recognition
Mar 09, 2020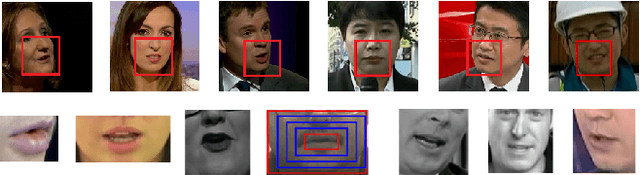

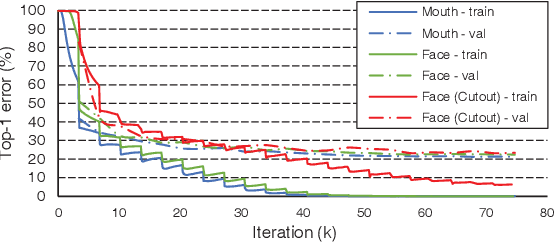
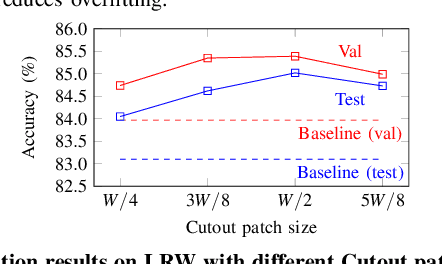
Recent advances in deep learning have heightened interest among researchers in the field of visual speech recognition (VSR). Currently, most existing methods equate VSR with automatic lip reading, which attempts to recognise speech by analysing lip motion. However, human experience and psychological studies suggest that we do not always fix our gaze at each other's lips during a face-to-face conversation, but rather scan the whole face repetitively. This inspires us to revisit a fundamental yet somehow overlooked problem: can VSR models benefit from reading extraoral facial regions, i.e. beyond the lips? In this paper, we perform a comprehensive study to evaluate the effects of different facial regions with state-of-the-art VSR models, including the mouth, the whole face, the upper face, and even the cheeks. Experiments are conducted on both word-level and sentence-level benchmarks with different characteristics. We find that despite the complex variations of the data, incorporating information from extraoral facial regions, even the upper face, consistently benefits VSR performance. Furthermore, we introduce a simple yet effective method based on Cutout to learn more discriminative features for face-based VSR, hoping to maximise the utility of information encoded in different facial regions. Our experiments show obvious improvements over existing state-of-the-art methods that use only the lip region as inputs, a result we believe would probably provide the VSR community with some new and exciting insights.