 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConservative Bayesian Model-Based Value Expansion for Offline Policy Optimization
Oct 07, 2022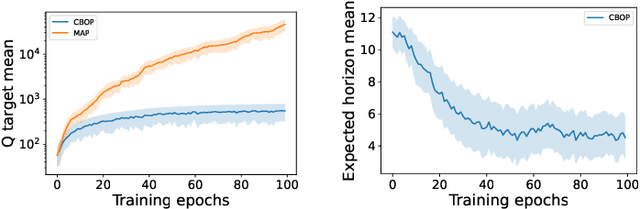
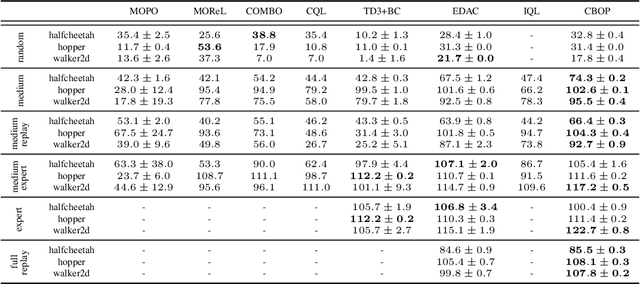
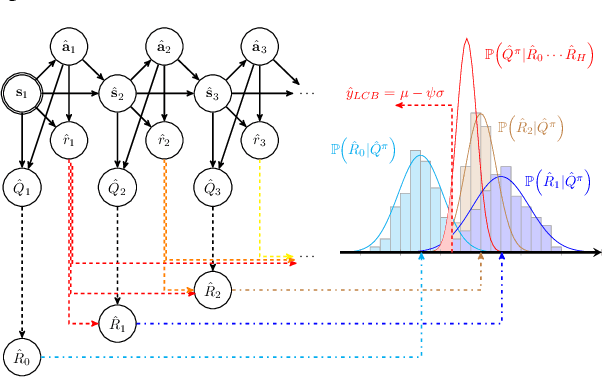
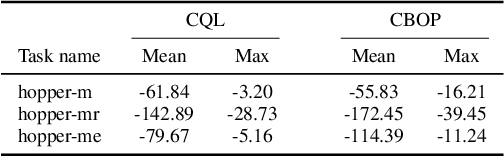
Offline reinforcement learning (RL) addresses the problem of learning a performant policy from a fixed batch of data collected by following some behavior policy. Model-based approaches are particularly appealing in the offline setting since they can extract more learning signals from the logged dataset by learning a model of the environment. However, the performance of existing model-based approaches falls short of model-free counterparts, due to the compounding of estimation errors in the learned model. Driven by this observation, we argue that it is critical for a model-based method to understand when to trust the model and when to rely on model-free estimates, and how to act conservatively w.r.t. both. To this end, we derive an elegant and simple methodology called conservative Bayesian model-based value expansion for offline policy optimization (CBOP), that trades off model-free and model-based estimates during the policy evaluation step according to their epistemic uncertainties, and facilitates conservatism by taking a lower bound on the Bayesian posterior value estimate. On the standard D4RL continuous control tasks, we find that our method significantly outperforms previous model-based approaches: e.g., MOPO by $116.4$%, MOReL by $23.2$% and COMBO by $23.7$%. Further, CBOP achieves state-of-the-art performance on $11$ out of $18$ benchmark datasets while doing on par on the remaining datasets.
Predictive Edge Caching through Deep Mining of Sequential Patterns in User Content Retrievals
Oct 06, 2022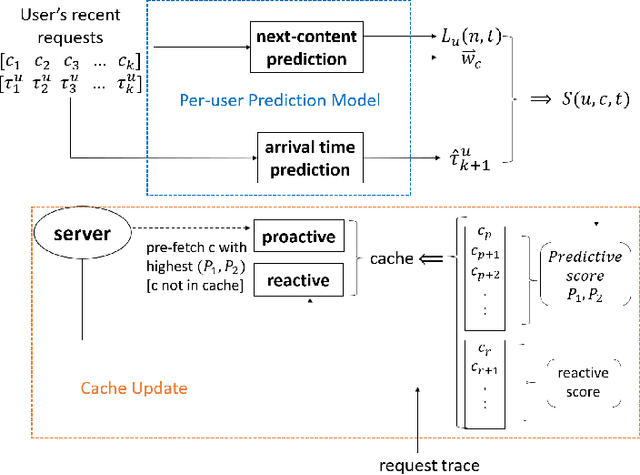
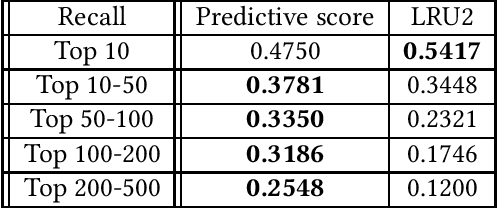
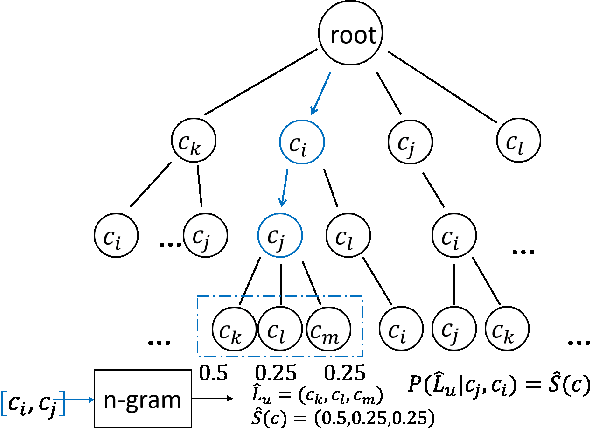
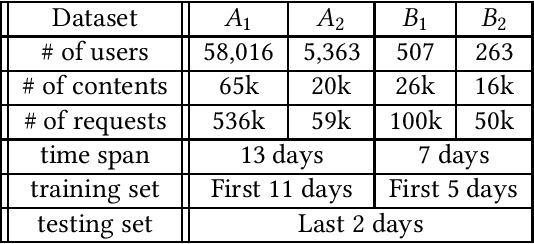
Edge caching plays an increasingly important role in boosting user content retrieval performance while reducing redundant network traffic. The effectiveness of caching ultimately hinges on the accuracy of predicting content popularity in the near future. However, at the network edge, content popularity can be extremely dynamic due to diverse user content retrieval behaviors and the low-degree of user multiplexing. It's challenging for the traditional reactive caching systems to keep up with the dynamic content popularity patterns. In this paper, we propose a novel Predictive Edge Caching (PEC) system that predicts the future content popularity using fine-grained learning models that mine sequential patterns in user content retrieval behaviors, and opportunistically prefetches contents predicted to be popular in the near future using idle network bandwidth. Through extensive experiments driven by real content retrieval traces, we demonstrate that PEC can adapt to highly dynamic content popularity, and significantly improve cache hit ratio and reduce user content retrieval latency over the state-of-art caching policies. More broadly, our study demonstrates that edge caching performance can be boosted by deep mining of user content retrieval behaviors.
Lifted Bregman Training of Neural Networks
Aug 18, 2022
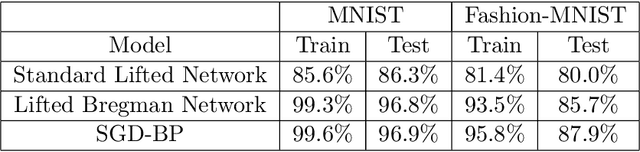
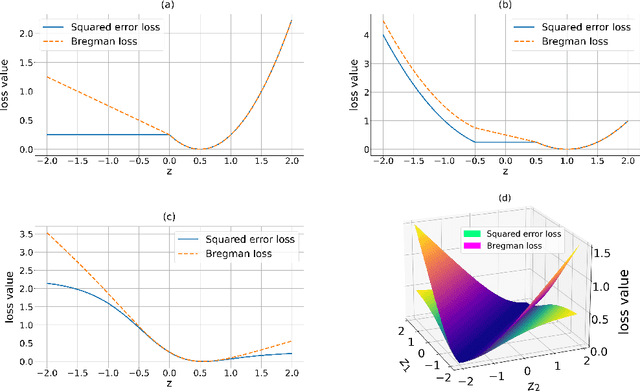

We introduce a novel mathematical formulation for the training of feed-forward neural networks with (potentially non-smooth) proximal maps as activation functions. This formulation is based on Bregman distances and a key advantage is that its partial derivatives with respect to the network's parameters do not require the computation of derivatives of the network's activation functions. Instead of estimating the parameters with a combination of first-order optimisation method and back-propagation (as is the state-of-the-art), we propose the use of non-smooth first-order optimisation methods that exploit the specific structure of the novel formulation. We present several numerical results that demonstrate that these training approaches can be equally well or even better suited for the training of neural network-based classifiers and (denoising) autoencoders with sparse coding compared to more conventional training frameworks.
ALBench: A Framework for Evaluating Active Learning in Object Detection
Aug 10, 2022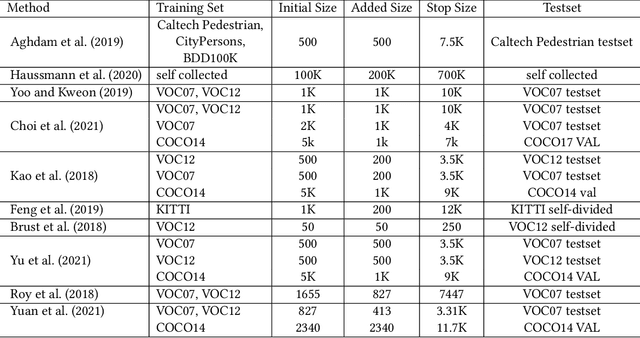
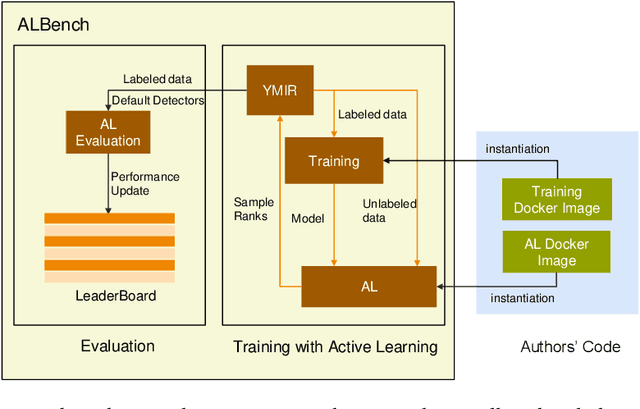
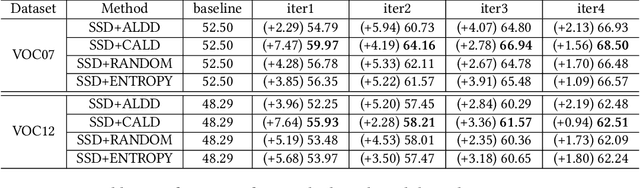
Active learning is an important technology for automated machine learning systems. In contrast to Neural Architecture Search (NAS) which aims at automating neural network architecture design, active learning aims at automating training data selection. It is especially critical for training a long-tailed task, in which positive samples are sparsely distributed. Active learning alleviates the expensive data annotation issue through incrementally training models powered with efficient data selection. Instead of annotating all unlabeled samples, it iteratively selects and annotates the most valuable samples. Active learning has been popular in image classification, but has not been fully explored in object detection. Most of current approaches on object detection are evaluated with different settings, making it difficult to fairly compare their performance. To facilitate the research in this field, this paper contributes an active learning benchmark framework named as ALBench for evaluating active learning in object detection. Developed on an automatic deep model training system, this ALBench framework is easy-to-use, compatible with different active learning algorithms, and ensures the same training and testing protocols. We hope this automated benchmark system help researchers to easily reproduce literature's performance and have objective comparisons with prior arts. The code will be release through Github.
Improving Adversarial Robustness via Mutual Information Estimation
Jul 25, 2022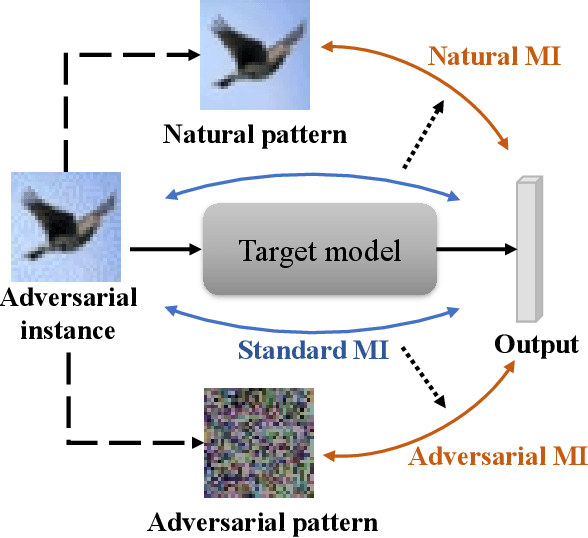
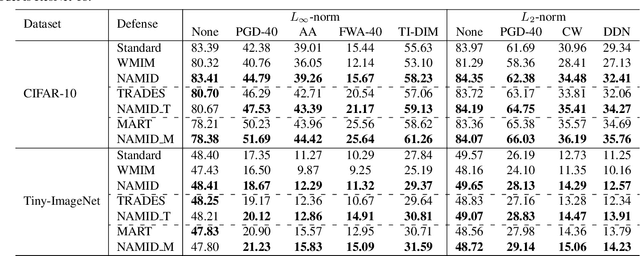
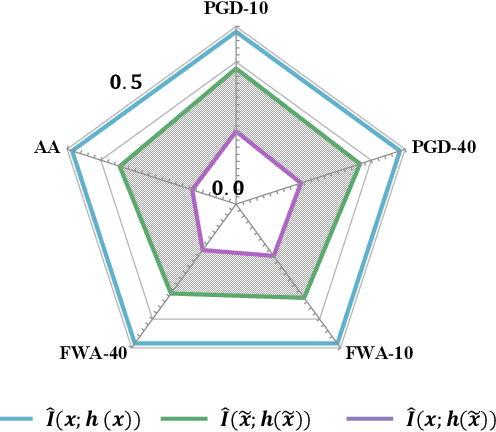

Deep neural networks (DNNs) are found to be vulnerable to adversarial noise. They are typically misled by adversarial samples to make wrong predictions. To alleviate this negative effect, in this paper, we investigate the dependence between outputs of the target model and input adversarial samples from the perspective of information theory, and propose an adversarial defense method. Specifically, we first measure the dependence by estimating the mutual information (MI) between outputs and the natural patterns of inputs (called natural MI) and MI between outputs and the adversarial patterns of inputs (called adversarial MI), respectively. We find that adversarial samples usually have larger adversarial MI and smaller natural MI compared with those w.r.t. natural samples. Motivated by this observation, we propose to enhance the adversarial robustness by maximizing the natural MI and minimizing the adversarial MI during the training process. In this way, the target model is expected to pay more attention to the natural pattern that contains objective semantics. Empirical evaluations demonstrate that our method could effectively improve the adversarial accuracy against multiple attacks.
Multi-Modal Multi-Correlation Learning for Audio-Visual Speech Separation
Jul 04, 2022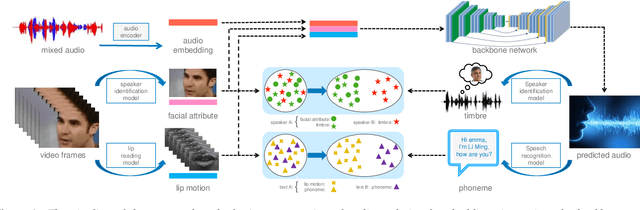
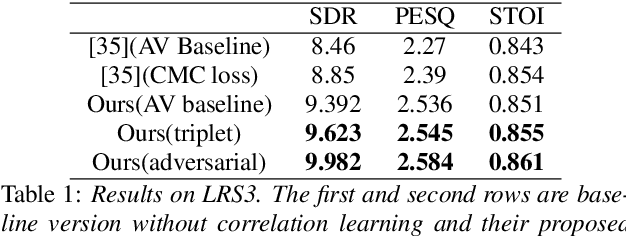
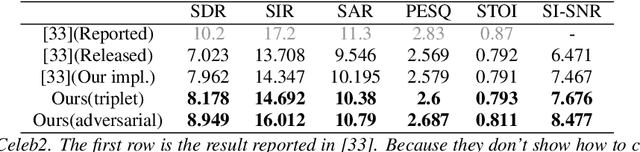
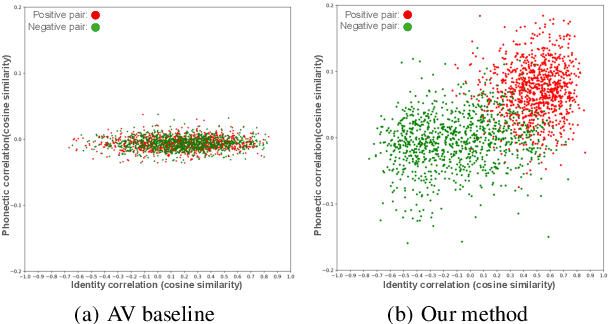
In this paper we propose a multi-modal multi-correlation learning framework targeting at the task of audio-visual speech separation. Although previous efforts have been extensively put on combining audio and visual modalities, most of them solely adopt a straightforward concatenation of audio and visual features. To exploit the real useful information behind these two modalities, we define two key correlations which are: (1) identity correlation (between timbre and facial attributes); (2) phonetic correlation (between phoneme and lip motion). These two correlations together comprise the complete information, which shows a certain superiority in separating target speaker's voice especially in some hard cases, such as the same gender or similar content. For implementation, contrastive learning or adversarial training approach is applied to maximize these two correlations. Both of them work well, while adversarial training shows its advantage by avoiding some limitations of contrastive learning. Compared with previous research, our solution demonstrates clear improvement on experimental metrics without additional complexity. Further analysis reveals the validity of the proposed architecture and its good potential for future extension.
Commonsense Knowledge Salience Evaluation with a Benchmark Dataset in E-commerce
May 22, 2022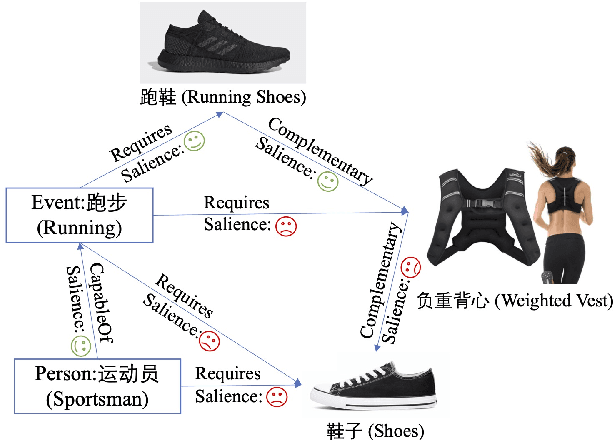


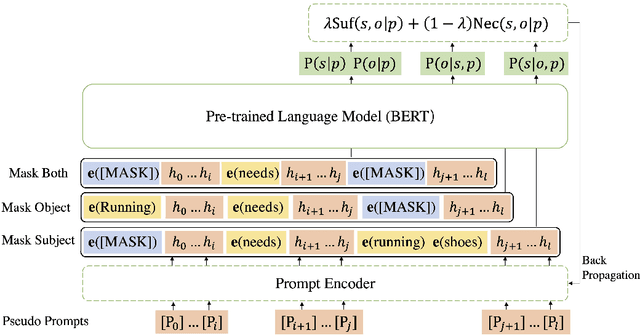
In e-commerce, the salience of commonsense knowledge (CSK) is beneficial for widespread applications such as product search and recommendation. For example, when users search for "running" in e-commerce, they would like to find items highly related to running, such as "running shoes" rather than "shoes". However, many existing CSK collections rank statements solely by confidence scores, and there is no information about which ones are salient from a human perspective. In this work, we define the task of supervised salience evaluation, where given a CSK triple, the model is required to learn whether the triple is salient or not. In addition to formulating the new task, we also release a new Benchmark dataset of Salience Evaluation in E-commerce (BSEE) and hope to promote related research on commonsense knowledge salience evaluation. We conduct experiments in the dataset with several representative baseline models. The experimental results show that salience evaluation is a hard task where models perform poorly on our evaluation set. We further propose a simple but effective approach, PMI-tuning, which shows promise for solving this novel problem.
Implementation of an Automated Learning System for Non-experts
Mar 26, 2022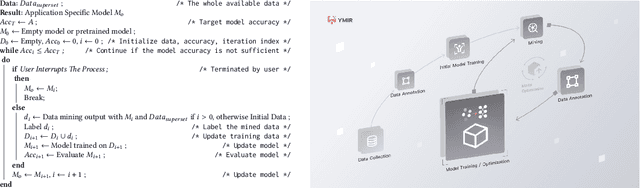

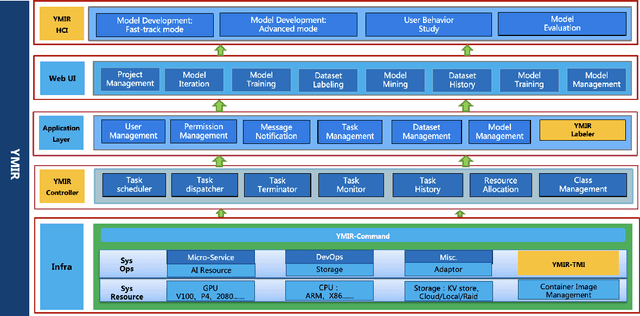
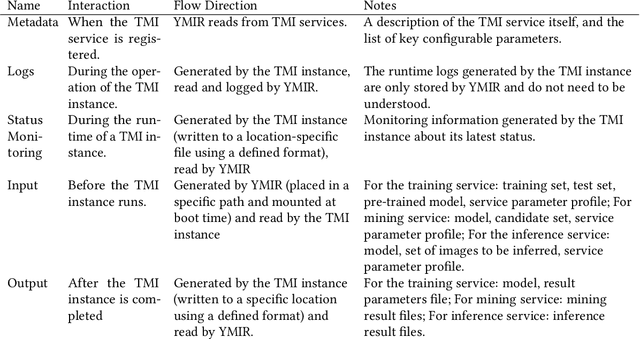
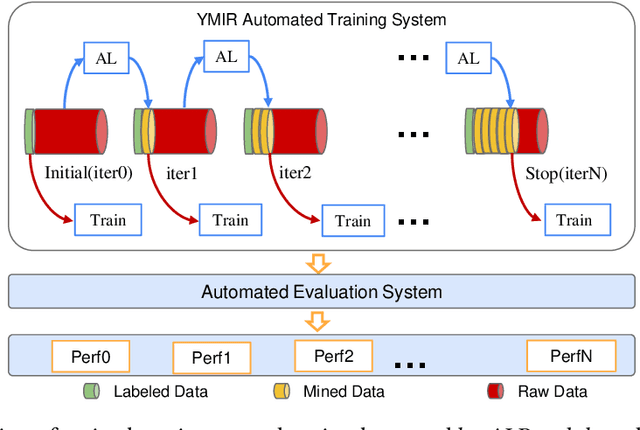
Automated machine learning systems for non-experts could be critical for industries to adopt artificial intelligence to their own applications. This paper detailed the engineering system implementation of an automated machine learning system called YMIR, which completely relies on graphical interface to interact with users. After importing training/validation data into the system, a user without AI knowledge can label the data, train models, perform data mining and evaluation by simply clicking buttons. The paper described: 1) Open implementation of model training and inference through docker containers. 2) Implementation of task and resource management. 3) Integration of Labeling software. 4) Implementation of HCI (Human Computer Interaction) with a rebuilt collaborative development paradigm. We also provide subsequent case study on training models with the system. We hope this paper can facilitate the prosperity of our automated machine learning community from industry application perspective. The code of the system has already been released to GitHub (https://github.com/industryessentials/ymir).
Towards Semi-Supervised Deep Facial Expression Recognition with An Adaptive Confidence Margin
Mar 24, 2022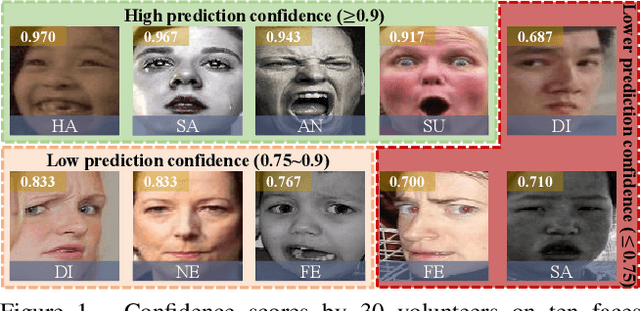
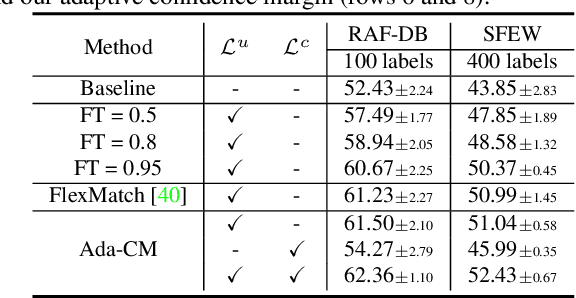
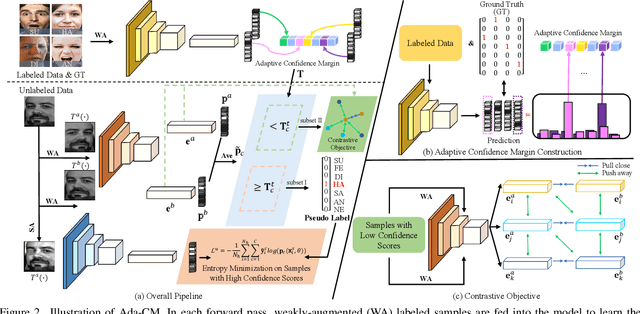
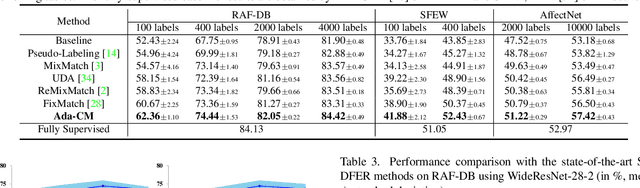
Only parts of unlabeled data are selected to train models for most semi-supervised learning methods, whose confidence scores are usually higher than the pre-defined threshold (i.e., the confidence margin). We argue that the recognition performance should be further improved by making full use of all unlabeled data. In this paper, we learn an Adaptive Confidence Margin (Ada-CM) to fully leverage all unlabeled data for semi-supervised deep facial expression recognition. All unlabeled samples are partitioned into two subsets by comparing their confidence scores with the adaptively learned confidence margin at each training epoch: (1) subset I including samples whose confidence scores are no lower than the margin; (2) subset II including samples whose confidence scores are lower than the margin. For samples in subset I, we constrain their predictions to match pseudo labels. Meanwhile, samples in subset II participate in the feature-level contrastive objective to learn effective facial expression features. We extensively evaluate Ada-CM on four challenging datasets, showing that our method achieves state-of-the-art performance, especially surpassing fully-supervised baselines in a semi-supervised manner. Ablation study further proves the effectiveness of our method. The source code is available at https://github.com/hangyu94/Ada-CM.
FaceMap: Towards Unsupervised Face Clustering via Map Equation
Mar 21, 2022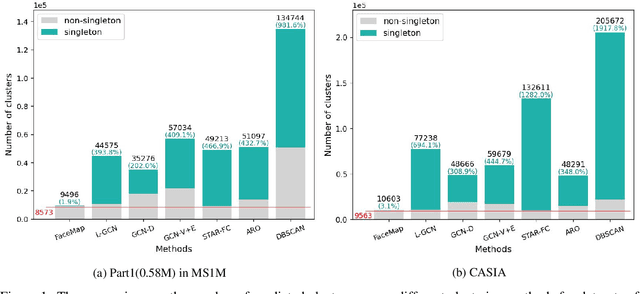
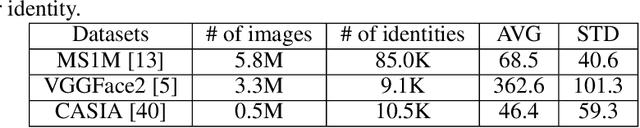
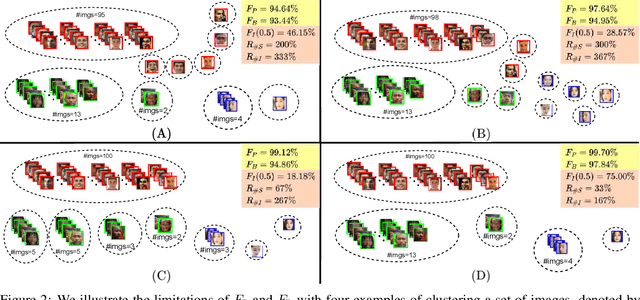

Face clustering is an essential task in computer vision due to the explosion of related applications such as augmented reality or photo album management. The main challenge of this task lies in the imperfectness of similarities among image feature representations. Given an existing feature extraction model, it is still an unresolved problem that how can the inherent characteristics of similarities of unlabelled images be leveraged to improve the clustering performance. Motivated by answering the question, we develop an effective unsupervised method, named as FaceMap, by formulating face clustering as a process of non-overlapping community detection, and minimizing the entropy of information flows on a network of images. The entropy is denoted by the map equation and its minimum represents the least description of paths among images in expectation. Inspired by observations on the ranked transition probabilities in the affinity graph constructed from facial images, we develop an outlier detection strategy to adaptively adjust transition probabilities among images. Experiments with ablation studies demonstrate that FaceMap significantly outperforms existing methods and achieves new state-of-the-arts on three popular large-scale datasets for face clustering, e.g., an absolute improvement of more than $10\%$ and $4\%$ comparing with prior unsupervised and supervised methods respectively in terms of average of Pairwise F-score. Our code is publicly available on github.