 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Teacher Knowledge Distillation with Domain Alignment for Face Anti-spoofing
Jan 02, 2024



Face recognition systems have raised concerns due to their vulnerability to different presentation attacks, and system security has become an increasingly critical concern. Although many face anti-spoofing (FAS) methods perform well in intra-dataset scenarios, their generalization remains a challenge. To address this issue, some methods adopt domain adversarial training (DAT) to extract domain-invariant features. However, the competition between the encoder and the domain discriminator can cause the network to be difficult to train and converge. In this paper, we propose a domain adversarial attack (DAA) method to mitigate the training instability problem by adding perturbations to the input images, which makes them indistinguishable across domains and enables domain alignment. Moreover, since models trained on limited data and types of attacks cannot generalize well to unknown attacks, we propose a dual perceptual and generative knowledge distillation framework for face anti-spoofing that utilizes pre-trained face-related models containing rich face priors. Specifically, we adopt two different face-related models as teachers to transfer knowledge to the target student model. The pre-trained teacher models are not from the task of face anti-spoofing but from perceptual and generative tasks, respectively, which implicitly augment the data. By combining both DAA and dual-teacher knowledge distillation, we develop a dual teacher knowledge distillation with domain alignment framework (DTDA) for face anti-spoofing. The advantage of our proposed method has been verified through extensive ablation studies and comparison with state-of-the-art methods on public datasets across multiple protocols.
ASLseg: Adapting SAM in the Loop for Semi-supervised Liver Tumor Segmentation
Dec 13, 2023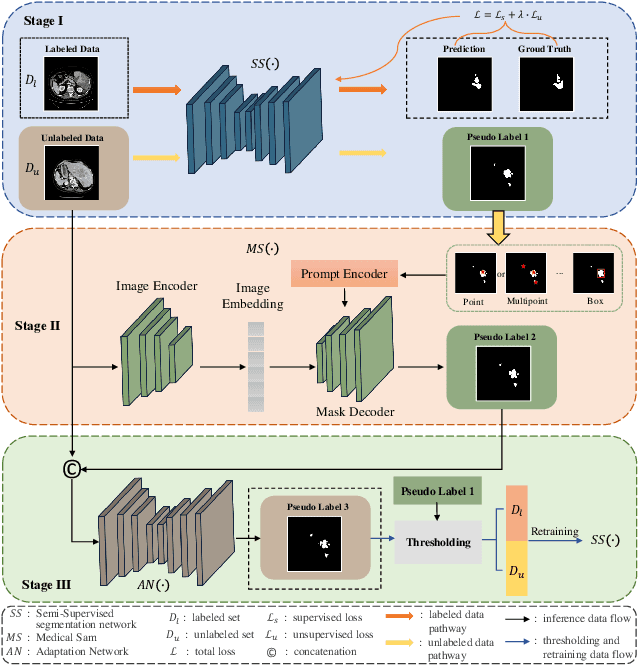
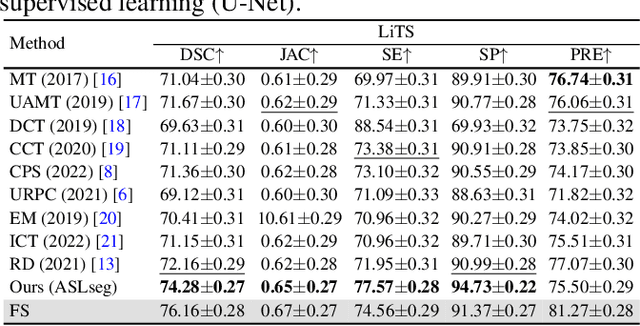
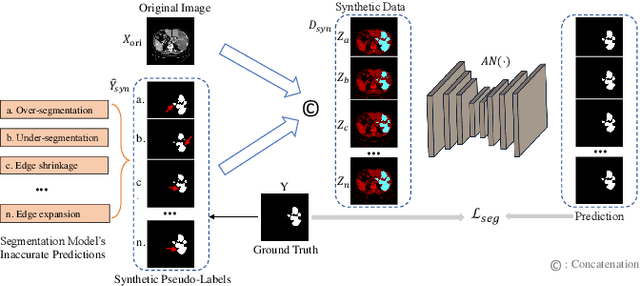
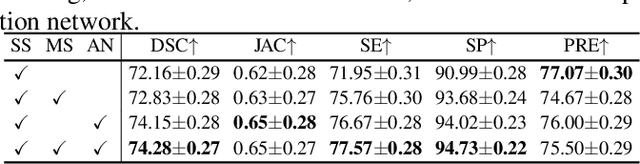
Liver tumor segmentation is essential for computer-aided diagnosis, surgical planning, and prognosis evaluation. However, obtaining and maintaining a large-scale dataset with dense annotations is challenging. Semi-Supervised Learning (SSL) is a common technique to address these challenges. Recently, Segment Anything Model (SAM) has shown promising performance in some medical image segmentation tasks, but it performs poorly for liver tumor segmentation. In this paper, we propose a novel semi-supervised framework, named ASLseg, which can effectively adapt the SAM to the SSL setting and combine both domain-specific and general knowledge of liver tumors. Specifically, the segmentation model trained with a specific SSL paradigm provides the generated pseudo-labels as prompts to the fine-tuned SAM. An adaptation network is then used to refine the SAM-predictions and generate higher-quality pseudo-labels. Finally, the reliable pseudo-labels are selected to expand the labeled set for iterative training. Extensive experiments on the LiTS dataset demonstrate overwhelming performance of our ASLseg.
Simultaneous Alignment and Surface Regression Using Hybrid 2D-3D Networks for 3D Coherent Layer Segmentation of Retinal OCT Images with Full and Sparse Annotations
Dec 04, 2023



Layer segmentation is important to quantitative analysis of retinal optical coherence tomography (OCT). Recently, deep learning based methods have been developed to automate this task and yield remarkable performance. However, due to the large spatial gap and potential mismatch between the B-scans of an OCT volume, all of them were based on 2D segmentation of individual B-scans, which may lose the continuity and diagnostic information of the retinal layers in 3D space. Besides, most of these methods required dense annotation of the OCT volumes, which is labor-intensive and expertise-demanding. This work presents a novel framework based on hybrid 2D-3D convolutional neural networks (CNNs) to obtain continuous 3D retinal layer surfaces from OCT volumes, which works well with both full and sparse annotations. The 2D features of individual B-scans are extracted by an encoder consisting of 2D convolutions. These 2D features are then used to produce the alignment displacement vectors and layer segmentation by two 3D decoders coupled via a spatial transformer module. Two losses are proposed to utilize the retinal layers' natural property of being smooth for B-scan alignment and layer segmentation, respectively, and are the key to the semi-supervised learning with sparse annotation. The entire framework is trained end-to-end. To the best of our knowledge, this is the first work that attempts 3D retinal layer segmentation in volumetric OCT images based on CNNs. Experiments on a synthetic dataset and three public clinical datasets show that our framework can effectively align the B-scans for potential motion correction, and achieves superior performance to state-of-the-art 2D deep learning methods in terms of both layer segmentation accuracy and cross-B-scan 3D continuity in both fully and semi-supervised settings, thus offering more clinical values than previous works.
FedRec+: Enhancing Privacy and Addressing Heterogeneity in Federated Recommendation Systems
Oct 31, 2023Preserving privacy and reducing communication costs for edge users pose significant challenges in recommendation systems. Although federated learning has proven effective in protecting privacy by avoiding data exchange between clients and servers, it has been shown that the server can infer user ratings based on updated non-zero gradients obtained from two consecutive rounds of user-uploaded gradients. Moreover, federated recommendation systems (FRS) face the challenge of heterogeneity, leading to decreased recommendation performance. In this paper, we propose FedRec+, an ensemble framework for FRS that enhances privacy while addressing the heterogeneity challenge. FedRec+ employs optimal subset selection based on feature similarity to generate near-optimal virtual ratings for pseudo items, utilizing only the user's local information. This approach reduces noise without incurring additional communication costs. Furthermore, we utilize the Wasserstein distance to estimate the heterogeneity and contribution of each client, and derive optimal aggregation weights by solving a defined optimization problem. Experimental results demonstrate the state-of-the-art performance of FedRec+ across various reference datasets.
Find Your Optimal Assignments On-the-fly: A Holistic Framework for Clustered Federated Learning
Oct 09, 2023Federated Learning (FL) is an emerging distributed machine learning approach that preserves client privacy by storing data on edge devices. However, data heterogeneity among clients presents challenges in training models that perform well on all local distributions. Recent studies have proposed clustering as a solution to tackle client heterogeneity in FL by grouping clients with distribution shifts into different clusters. However, the diverse learning frameworks used in current clustered FL methods make it challenging to integrate various clustered FL methods, gather their benefits, and make further improvements. To this end, this paper presents a comprehensive investigation into current clustered FL methods and proposes a four-tier framework, namely HCFL, to encompass and extend existing approaches. Based on the HCFL, we identify the remaining challenges associated with current clustering methods in each tier and propose an enhanced clustering method called HCFL+ to address these challenges. Through extensive numerical evaluations, we showcase the effectiveness of our clustering framework and the improved components. Our code will be publicly available.
Exploring Federated Optimization by Reducing Variance of Adaptive Unbiased Client Sampling
Oct 04, 2023Federated Learning (FL) systems usually sample a fraction of clients to conduct a training process. Notably, the variance of global estimates for updating the global model built on information from sampled clients is highly related to federated optimization quality. This paper explores a line of "free" adaptive client sampling techniques in federated optimization, where the server builds promising sampling probability and reliable global estimates without requiring additional local communication and computation. We capture a minor variant in the sampling procedure and improve the global estimation accordingly. Based on that, we propose a novel sampler called K-Vib, which solves an online convex optimization respecting client sampling in federated optimization. It achieves improved a linear speed up on regret bound $\tilde{\mathcal{O}}\big(N^{\frac{1}{3}}T^{\frac{2}{3}}/K^{\frac{4}{3}}\big)$ with communication budget $K$. As a result, it significantly improves the performance of federated optimization. Theoretical improvements and intensive experiments on classic federated tasks demonstrate our findings.
Tackling Hybrid Heterogeneity on Federated Optimization via Gradient Diversity Maximization
Oct 04, 2023Federated learning refers to a distributed machine learning paradigm in which data samples are decentralized and distributed among multiple clients. These samples may exhibit statistical heterogeneity, which refers to data distributions are not independent and identical across clients. Additionally, system heterogeneity, or variations in the computational power of the clients, introduces biases into federated learning. The combined effects of statistical and system heterogeneity can significantly reduce the efficiency of federated optimization. However, the impact of hybrid heterogeneity is not rigorously discussed. This paper explores how hybrid heterogeneity affects federated optimization by investigating server-side optimization. The theoretical results indicate that adaptively maximizing gradient diversity in server update direction can help mitigate the potential negative consequences of hybrid heterogeneity. To this end, we introduce a novel server-side gradient-based optimizer \textsc{FedAWARE} with theoretical guarantees provided. Intensive experiments in heterogeneous federated settings demonstrate that our proposed optimizer can significantly enhance the performance of federated learning across varying degrees of hybrid heterogeneity.
PRIOR: Prototype Representation Joint Learning from Medical Images and Reports
Jul 24, 2023



Contrastive learning based vision-language joint pre-training has emerged as a successful representation learning strategy. In this paper, we present a prototype representation learning framework incorporating both global and local alignment between medical images and reports. In contrast to standard global multi-modality alignment methods, we employ a local alignment module for fine-grained representation. Furthermore, a cross-modality conditional reconstruction module is designed to interchange information across modalities in the training phase by reconstructing masked images and reports. For reconstructing long reports, a sentence-wise prototype memory bank is constructed, enabling the network to focus on low-level localized visual and high-level clinical linguistic features. Additionally, a non-auto-regressive generation paradigm is proposed for reconstructing non-sequential reports. Experimental results on five downstream tasks, including supervised classification, zero-shot classification, image-to-text retrieval, semantic segmentation, and object detection, show the proposed method outperforms other state-of-the-art methods across multiple datasets and under different dataset size settings. The code is available at https://github.com/QtacierP/PRIOR.
TriFormer: A Multi-modal Transformer Framework For Mild Cognitive Impairment Conversion Prediction
Jul 14, 2023The prediction of mild cognitive impairment (MCI) conversion to Alzheimer's disease (AD) is important for early treatment to prevent or slow the progression of AD. To accurately predict the MCI conversion to stable MCI or progressive MCI, we propose Triformer, a novel transformer-based framework with three specialized transformers to incorporate multi-model data. Triformer uses I) an image transformer to extract multi-view image features from medical scans, II) a clinical transformer to embed and correlate multi-modal clinical data, and III) a modality fusion transformer that produces an accurate prediction based on fusing the outputs from the image and clinical transformers. Triformer is evaluated on the Alzheimer's Disease Neuroimaging Initiative (ANDI)1 and ADNI2 datasets and outperforms previous state-of-the-art single and multi-modal methods.
JOINEDTrans: Prior Guided Multi-task Transformer for Joint Optic Disc/Cup Segmentation and Fovea Detection
May 19, 2023



Deep learning-based image segmentation and detection models have largely improved the efficiency of analyzing retinal landmarks such as optic disc (OD), optic cup (OC), and fovea. However, factors including ophthalmic disease-related lesions and low image quality issues may severely complicate automatic OD/OC segmentation and fovea detection. Most existing works treat the identification of each landmark as a single task, and take into account no prior information. To address these issues, we propose a prior guided multi-task transformer framework for joint OD/OC segmentation and fovea detection, named JOINEDTrans. JOINEDTrans effectively combines various spatial features of the fundus images, relieving the structural distortions induced by lesions and other imaging issues. It contains a segmentation branch and a detection branch. To be noted, we employ an encoder pretrained in a vessel segmentation task to effectively exploit the positional relationship among vessel, OD/OC, and fovea, successfully incorporating spatial prior into the proposed JOINEDTrans framework. There are a coarse stage and a fine stage in JOINEDTrans. In the coarse stage, OD/OC coarse segmentation and fovea heatmap localization are obtained through a joint segmentation and detection module. In the fine stage, we crop regions of interest for subsequent refinement and use predictions obtained in the coarse stage to provide additional information for better performance and faster convergence. Experimental results demonstrate that JOINEDTrans outperforms existing state-of-the-art methods on the publicly available GAMMA, REFUGE, and PALM fundus image datasets. We make our code available at https://github.com/HuaqingHe/JOINEDTrans