 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlexRL: Cluster-Level Orchestration of Serviceized LLM Execution for RLVR
May 20, 2026Reinforcement learning with verifiable rewards (RLVR) has recently unlocked strong reasoning capabilities in large language models (LLMs), triggering rapid exploration of new algorithms and data. However, RLVR training is notoriously inefficient: long-tailed rollouts, tool-induced stalls, and asymmetric resource requirements between rollout and training introduce substantial idle time that cannot be eliminated by job-local optimizations such as synchronous pipelining, asynchronous rollout, or colocated execution. We argue that this inefficiency is structural. While idle gaps are unavoidable within individual RLVR jobs, they are largely anti-correlated across jobs and therefore exploitable at the cluster level. Leveraging this observation, we present PlexRL, a cluster-level runtime for multiplexing unified LLM services across RLVR jobs. By centrally managing model placement, state transitions, and function-level scheduling under strict affinity constraints, PlexRL time-slices LLM execution across jobs to fill otherwise idle periods without expensive model migration. Our implementation and evaluations demonstrate that PlexRL significantly improves effective cluster capacity and reduces user GPU hour cost by maximum 37.58% while preserving algorithmic flexibility and introducing minimal per-job overhead.
SortedRL: Accelerating RL Training for LLMs through Online Length-Aware Scheduling
Mar 24, 2026Scaling reinforcement learning (RL) has shown strong promise for enhancing the reasoning abilities of large language models (LLMs), particularly in tasks requiring long chain-of-thought generation. However, RL training efficiency is often bottlenecked by the rollout phase, which can account for up to 70% of total training time when generating long trajectories (e.g., 16k tokens), due to slow autoregressive generation and synchronization overhead between rollout and policy updates. We propose SortedRL, an online length-aware scheduling strategy designed to address this bottleneck by improving rollout efficiency and maintaining training stability. SortedRL reorders rollout samples based on output lengths, prioritizing short samples forming groups for early updates. This enables large rollout batches, flexible update batches, and near on-policy micro-curriculum construction simultaneously. To further accelerate the pipeline, SortedRL incorporates a mechanism to control the degree of off-policy training through a cache-based mechanism, and is supported by a dedicated RL infrastructure that manages rollout and update via a stateful controller and rollout buffer. Experiments using LLaMA-3.1-8B and Qwen-2.5-32B on diverse tasks, including logical puzzles, and math challenges like AIME 24, Math 500, and Minerval, show that SortedRL reduces RL training bubble ratios by over 50%, while attaining 3.9% to 18.4% superior performance over baseline given same amount of data.
AADG: Automatic Augmentation for Domain Generalization on Retinal Image Segmentation
Jul 27, 2022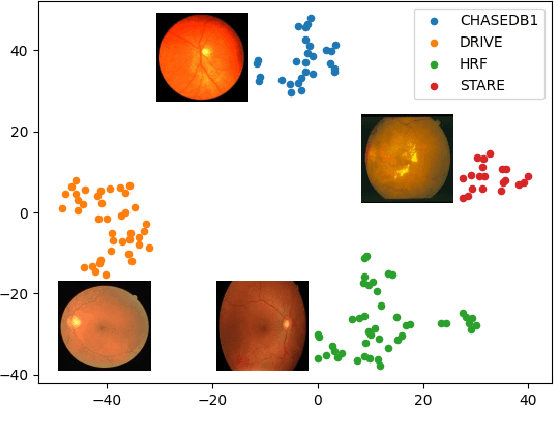
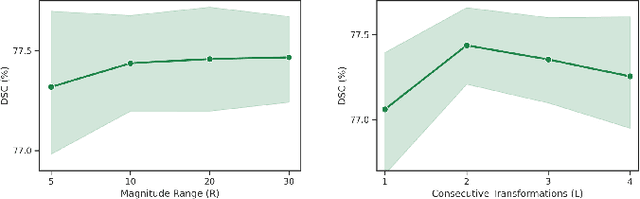
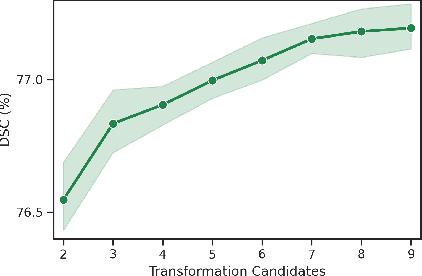
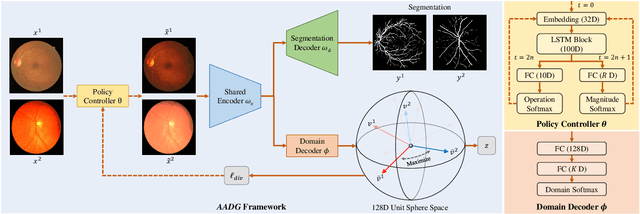
Convolutional neural networks have been widely applied to medical image segmentation and have achieved considerable performance. However, the performance may be significantly affected by the domain gap between training data (source domain) and testing data (target domain). To address this issue, we propose a data manipulation based domain generalization method, called Automated Augmentation for Domain Generalization (AADG). Our AADG framework can effectively sample data augmentation policies that generate novel domains and diversify the training set from an appropriate search space. Specifically, we introduce a novel proxy task maximizing the diversity among multiple augmented novel domains as measured by the Sinkhorn distance in a unit sphere space, making automated augmentation tractable. Adversarial training and deep reinforcement learning are employed to efficiently search the objectives. Quantitative and qualitative experiments on 11 publicly-accessible fundus image datasets (four for retinal vessel segmentation, four for optic disc and cup (OD/OC) segmentation and three for retinal lesion segmentation) are comprehensively performed. Two OCTA datasets for retinal vasculature segmentation are further involved to validate cross-modality generalization. Our proposed AADG exhibits state-of-the-art generalization performance and outperforms existing approaches by considerable margins on retinal vessel, OD/OC and lesion segmentation tasks. The learned policies are empirically validated to be model-agnostic and can transfer well to other models. The source code is available at https://github.com/CRazorback/AADG.