 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDilated Recurrent Neural Networks
Nov 02, 2017
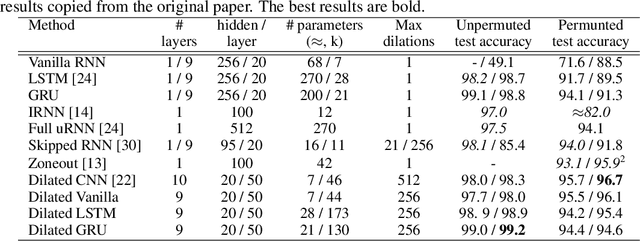
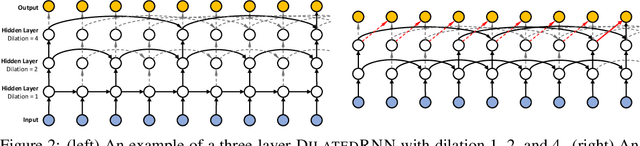
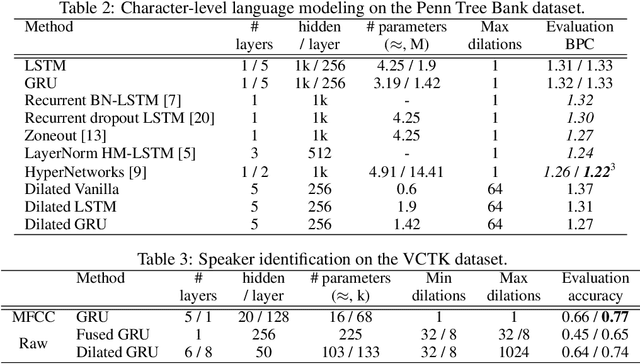
Learning with recurrent neural networks (RNNs) on long sequences is a notoriously difficult task. There are three major challenges: 1) complex dependencies, 2) vanishing and exploding gradients, and 3) efficient parallelization. In this paper, we introduce a simple yet effective RNN connection structure, the DilatedRNN, which simultaneously tackles all of these challenges. The proposed architecture is characterized by multi-resolution dilated recurrent skip connections and can be combined flexibly with diverse RNN cells. Moreover, the DilatedRNN reduces the number of parameters needed and enhances training efficiency significantly, while matching state-of-the-art performance (even with standard RNN cells) in tasks involving very long-term dependencies. To provide a theory-based quantification of the architecture's advantages, we introduce a memory capacity measure, the mean recurrent length, which is more suitable for RNNs with long skip connections than existing measures. We rigorously prove the advantages of the DilatedRNN over other recurrent neural architectures. The code for our method is publicly available at https://github.com/code-terminator/DilatedRNN
Deep Memory Networks for Attitude Identification
Jan 16, 2017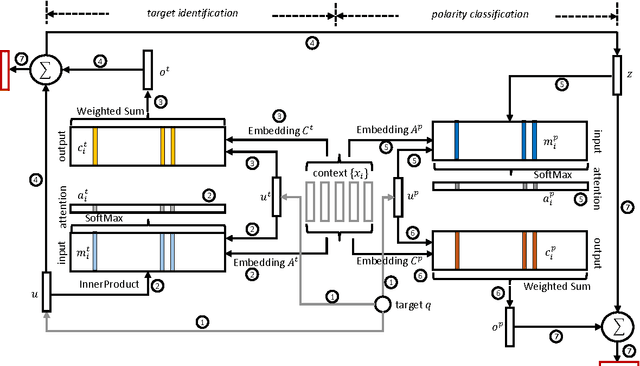
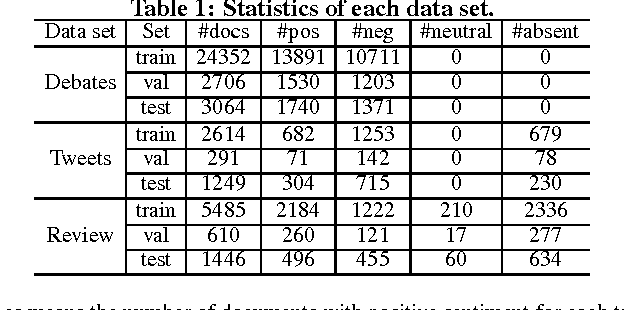
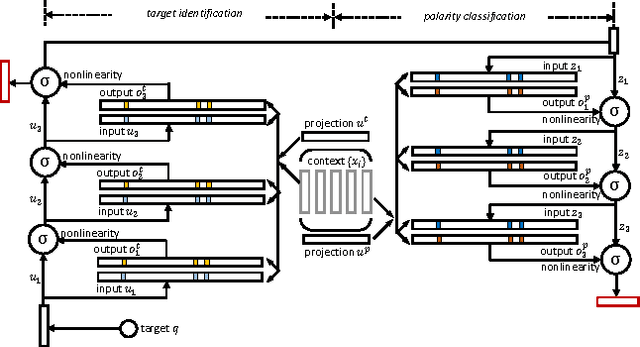
We consider the task of identifying attitudes towards a given set of entities from text. Conventionally, this task is decomposed into two separate subtasks: target detection that identifies whether each entity is mentioned in the text, either explicitly or implicitly, and polarity classification that classifies the exact sentiment towards an identified entity (the target) into positive, negative, or neutral. Instead, we show that attitude identification can be solved with an end-to-end machine learning architecture, in which the two subtasks are interleaved by a deep memory network. In this way, signals produced in target detection provide clues for polarity classification, and reversely, the predicted polarity provides feedback to the identification of targets. Moreover, the treatments for the set of targets also influence each other -- the learned representations may share the same semantics for some targets but vary for others. The proposed deep memory network, the AttNet, outperforms methods that do not consider the interactions between the subtasks or those among the targets, including conventional machine learning methods and the state-of-the-art deep learning models.
DeepCas: an End-to-end Predictor of Information Cascades
Nov 16, 2016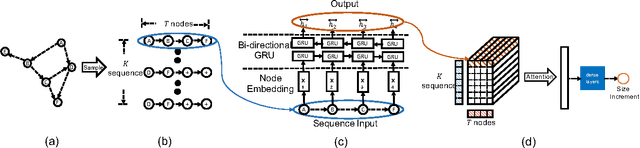
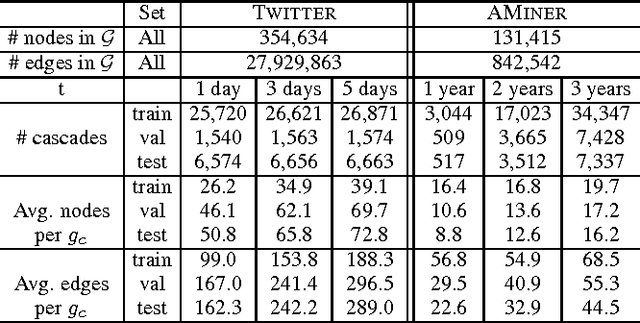
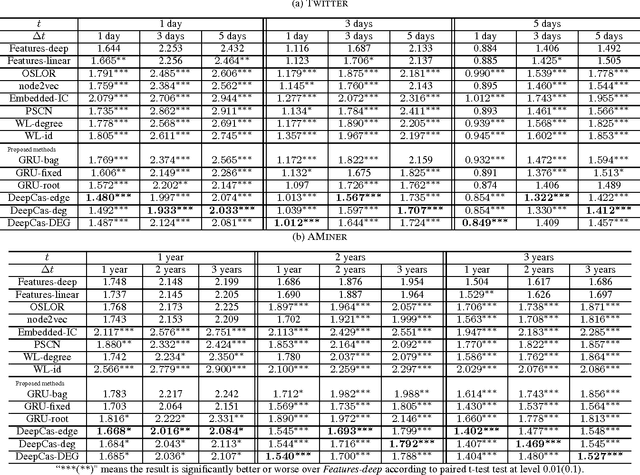
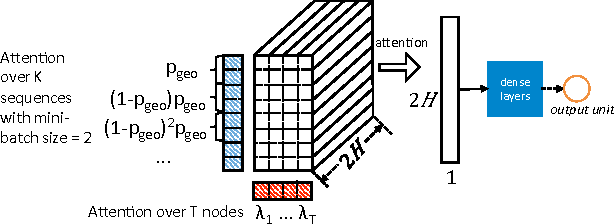
Information cascades, effectively facilitated by most social network platforms, are recognized as a major factor in almost every social success and disaster in these networks. Can cascades be predicted? While many believe that they are inherently unpredictable, recent work has shown that some key properties of information cascades, such as size, growth, and shape, can be predicted by a machine learning algorithm that combines many features. These predictors all depend on a bag of hand-crafting features to represent the cascade network and the global network structure. Such features, always carefully and sometimes mysteriously designed, are not easy to extend or to generalize to a different platform or domain. Inspired by the recent successes of deep learning in multiple data mining tasks, we investigate whether an end-to-end deep learning approach could effectively predict the future size of cascades. Such a method automatically learns the representation of individual cascade graphs in the context of the global network structure, without hand-crafted features and heuristics. We find that node embeddings fall short of predictive power, and it is critical to learn the representation of a cascade graph as a whole. We present algorithms that learn the representation of cascade graphs in an end-to-end manner, which significantly improve the performance of cascade prediction over strong baselines that include feature based methods, node embedding methods, and graph kernel methods. Our results also provide interesting implications for cascade prediction in general.
DeepGraph: Graph Structure Predicts Network Growth
Oct 20, 2016
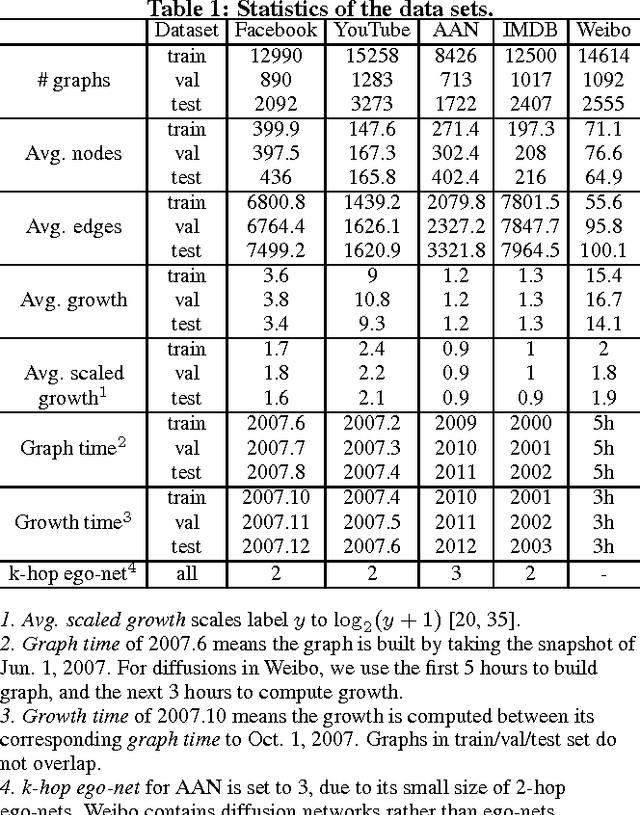
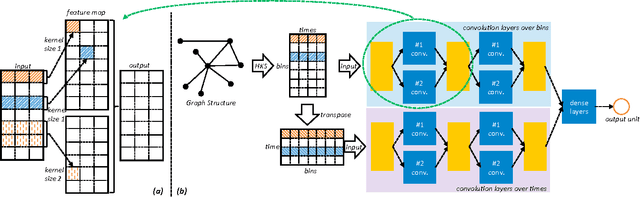

The topological (or graph) structures of real-world networks are known to be predictive of multiple dynamic properties of the networks. Conventionally, a graph structure is represented using an adjacency matrix or a set of hand-crafted structural features. These representations either fail to highlight local and global properties of the graph or suffer from a severe loss of structural information. There lacks an effective graph representation, which hinges the realization of the predictive power of network structures. In this study, we propose to learn the represention of a graph, or the topological structure of a network, through a deep learning model. This end-to-end prediction model, named DeepGraph, takes the input of the raw adjacency matrix of a real-world network and outputs a prediction of the growth of the network. The adjacency matrix is first represented using a graph descriptor based on the heat kernel signature, which is then passed through a multi-column, multi-resolution convolutional neural network. Extensive experiments on five large collections of real-world networks demonstrate that the proposed prediction model significantly improves the effectiveness of existing methods, including linear or nonlinear regressors that use hand-crafted features, graph kernels, and competing deep learning methods.
Deep Learning for Reward Design to Improve Monte Carlo Tree Search in ATARI Games
Apr 24, 2016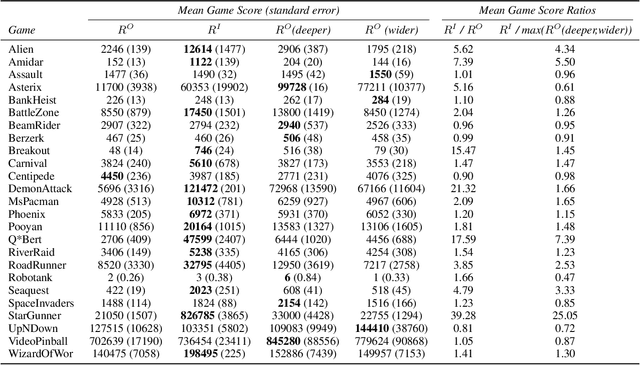
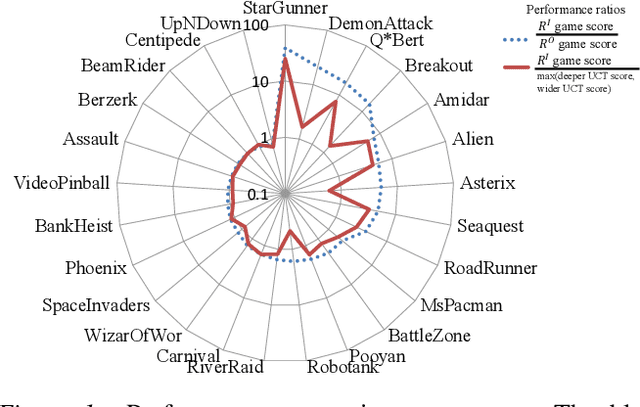
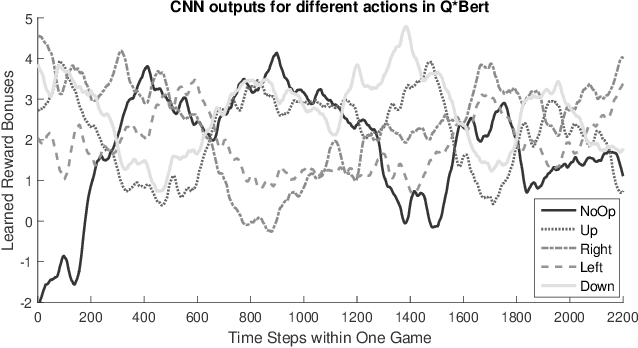
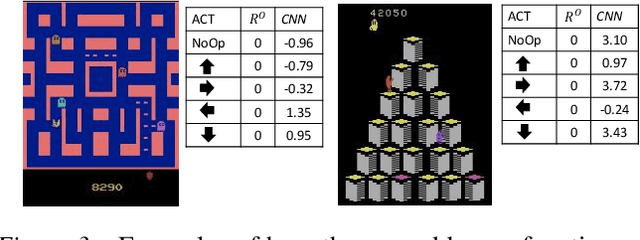
Monte Carlo Tree Search (MCTS) methods have proven powerful in planning for sequential decision-making problems such as Go and video games, but their performance can be poor when the planning depth and sampling trajectories are limited or when the rewards are sparse. We present an adaptation of PGRD (policy-gradient for reward-design) for learning a reward-bonus function to improve UCT (a MCTS algorithm). Unlike previous applications of PGRD in which the space of reward-bonus functions was limited to linear functions of hand-coded state-action-features, we use PGRD with a multi-layer convolutional neural network to automatically learn features from raw perception as well as to adapt the non-linear reward-bonus function parameters. We also adopt a variance-reducing gradient method to improve PGRD's performance. The new method improves UCT's performance on multiple ATARI games compared to UCT without the reward bonus. Combining PGRD and Deep Learning in this way should make adapting rewards for MCTS algorithms far more widely and practically applicable than before.
Action-Conditional Video Prediction using Deep Networks in Atari Games
Dec 22, 2015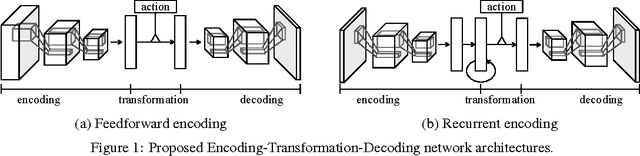
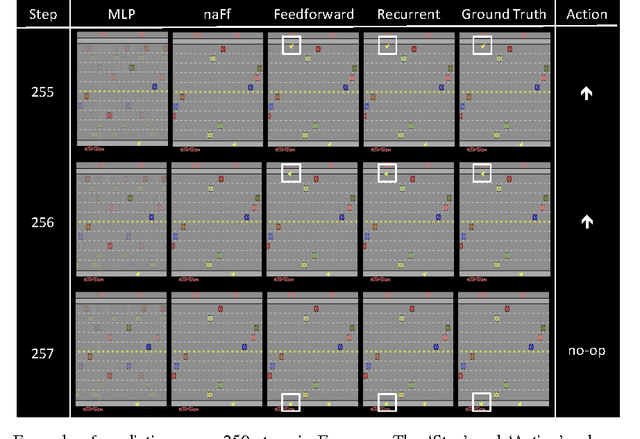
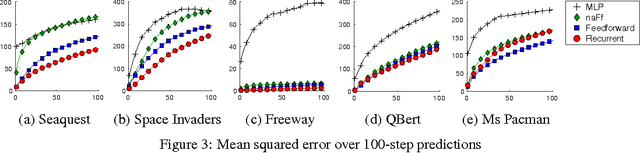
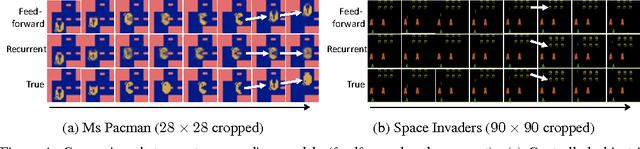
Motivated by vision-based reinforcement learning (RL) problems, in particular Atari games from the recent benchmark Aracade Learning Environment (ALE), we consider spatio-temporal prediction problems where future (image-)frames are dependent on control variables or actions as well as previous frames. While not composed of natural scenes, frames in Atari games are high-dimensional in size, can involve tens of objects with one or more objects being controlled by the actions directly and many other objects being influenced indirectly, can involve entry and departure of objects, and can involve deep partial observability. We propose and evaluate two deep neural network architectures that consist of encoding, action-conditional transformation, and decoding layers based on convolutional neural networks and recurrent neural networks. Experimental results show that the proposed architectures are able to generate visually-realistic frames that are also useful for control over approximately 100-step action-conditional futures in some games. To the best of our knowledge, this paper is the first to make and evaluate long-term predictions on high-dimensional video conditioned by control inputs.