 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDDSA: Dual-Domain Strategic Attack for Spatial-Temporal Efficiency in Adversarial Robustness Testing
Jan 18, 2026Image transmission and processing systems in resource-critical applications face significant challenges from adversarial perturbations that compromise mission-specific object classification. Current robustness testing methods require excessive computational resources through exhaustive frame-by-frame processing and full-image perturbations, proving impractical for large-scale deployments where massive image streams demand immediate processing. This paper presents DDSA (Dual-Domain Strategic Attack), a resource-efficient adversarial robustness testing framework that optimizes testing through temporal selectivity and spatial precision. We introduce a scenario-aware trigger function that identifies critical frames requiring robustness evaluation based on class priority and model uncertainty, and employ explainable AI techniques to locate influential pixel regions for targeted perturbation. Our dual-domain approach achieves substantial temporal-spatial resource conservation while maintaining attack effectiveness. The framework enables practical deployment of comprehensive adversarial robustness testing in resource-constrained real-time applications where computational efficiency directly impacts mission success.
Towards A Unified PAC-Bayesian Framework for Norm-based Generalization Bounds
Jan 13, 2026Understanding the generalization behavior of deep neural networks remains a fundamental challenge in modern statistical learning theory. Among existing approaches, PAC-Bayesian norm-based bounds have demonstrated particular promise due to their data-dependent nature and their ability to capture algorithmic and geometric properties of learned models. However, most existing results rely on isotropic Gaussian posteriors, heavy use of spectral-norm concentration for weight perturbations, and largely architecture-agnostic analyses, which together limit both the tightness and practical relevance of the resulting bounds. To address these limitations, in this work, we propose a unified framework for PAC-Bayesian norm-based generalization by reformulating the derivation of generalization bounds as a stochastic optimization problem over anisotropic Gaussian posteriors. The key to our approach is a sensitivity matrix that quantifies the network outputs with respect to structured weight perturbations, enabling the explicit incorporation of heterogeneous parameter sensitivities and architectural structures. By imposing different structural assumptions on this sensitivity matrix, we derive a family of generalization bounds that recover several existing PAC-Bayesian results as special cases, while yielding bounds that are comparable to or tighter than state-of-the-art approaches. Such a unified framework provides a principled and flexible way for geometry-/structure-aware and interpretable generalization analysis in deep learning.
Lying with Truths: Open-Channel Multi-Agent Collusion for Belief Manipulation via Generative Montage
Jan 04, 2026As large language models (LLMs) transition to autonomous agents synthesizing real-time information, their reasoning capabilities introduce an unexpected attack surface. This paper introduces a novel threat where colluding agents steer victim beliefs using only truthful evidence fragments distributed through public channels, without relying on covert communications, backdoors, or falsified documents. By exploiting LLMs' overthinking tendency, we formalize the first cognitive collusion attack and propose Generative Montage: a Writer-Editor-Director framework that constructs deceptive narratives through adversarial debate and coordinated posting of evidence fragments, causing victims to internalize and propagate fabricated conclusions. To study this risk, we develop CoPHEME, a dataset derived from real-world rumor events, and simulate attacks across diverse LLM families. Our results show pervasive vulnerability across 14 LLM families: attack success rates reach 74.4% for proprietary models and 70.6% for open-weights models. Counterintuitively, stronger reasoning capabilities increase susceptibility, with reasoning-specialized models showing higher attack success than base models or prompts. Furthermore, these false beliefs then cascade to downstream judges, achieving over 60% deception rates, highlighting a socio-technical vulnerability in how LLM-based agents interact with dynamic information environments. Our implementation and data are available at: https://github.com/CharlesJW222/Lying_with_Truth/tree/main.
Rethinking Multi-Agent Intelligence Through the Lens of Small-World Networks
Dec 19, 2025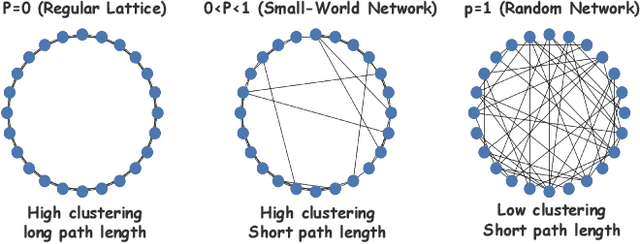



Large language models (LLMs) have enabled multi-agent systems (MAS) in which multiple agents argue, critique, and coordinate to solve complex tasks, making communication topology a first-class design choice. Yet most existing LLM-based MAS either adopt fully connected graphs, simple sparse rings, or ad-hoc dynamic selection, with little structural guidance. In this work, we revisit classic theory on small-world (SW) networks and ask: what changes if we treat SW connectivity as a design prior for MAS? We first bridge insights from neuroscience and complex networks to MAS, highlighting how SW structures balance local clustering and long-range integration. Using multi-agent debate (MAD) as a controlled testbed, experiment results show that SW connectivity yields nearly the same accuracy and token cost, while substantially stabilizing consensus trajectories. Building on this, we introduce an uncertainty-guided rewiring scheme for scaling MAS, where long-range shortcuts are added between epistemically divergent agents using LLM-oriented uncertainty signals (e.g., semantic entropy). This yields controllable SW structures that adapt to task difficulty and agent heterogeneity. Finally, we discuss broader implications of SW priors for MAS design, framing them as stabilizers of reasoning, enhancers of robustness, scalable coordinators, and inductive biases for emergent cognitive roles.
SynthSeg-Agents: Multi-Agent Synthetic Data Generation for Zero-Shot Weakly Supervised Semantic Segmentation
Dec 17, 2025
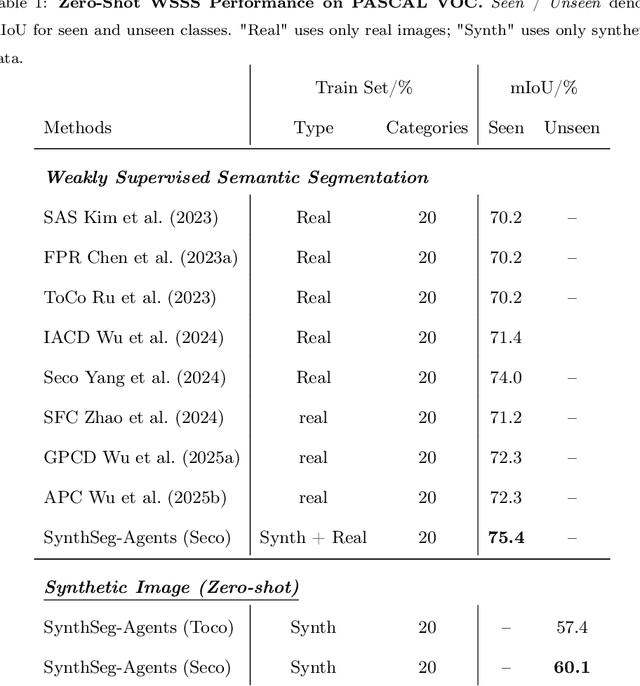
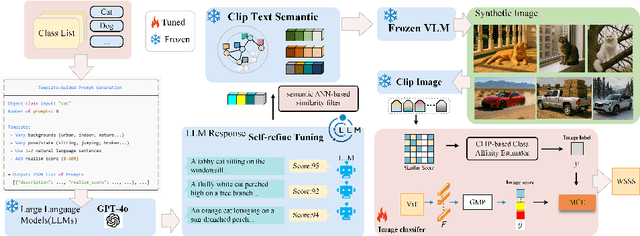

Weakly Supervised Semantic Segmentation (WSSS) with image level labels aims to produce pixel level predictions without requiring dense annotations. While recent approaches have leveraged generative models to augment existing data, they remain dependent on real world training samples. In this paper, we introduce a novel direction, Zero Shot Weakly Supervised Semantic Segmentation (ZSWSSS), and propose SynthSeg Agents, a multi agent framework driven by Large Language Models (LLMs) to generate synthetic training data entirely without real images. SynthSeg Agents comprises two key modules, a Self Refine Prompt Agent and an Image Generation Agent. The Self Refine Prompt Agent autonomously crafts diverse and semantically rich image prompts via iterative refinement, memory mechanisms, and prompt space exploration, guided by CLIP based similarity and nearest neighbor diversity filtering. These prompts are then passed to the Image Generation Agent, which leverages Vision Language Models (VLMs) to synthesize candidate images. A frozen CLIP scoring model is employed to select high quality samples, and a ViT based classifier is further trained to relabel the entire synthetic dataset with improved semantic precision. Our framework produces high quality training data without any real image supervision. Experiments on PASCAL VOC 2012 and COCO 2014 show that SynthSeg Agents achieves competitive performance without using real training images. This highlights the potential of LLM driven agents in enabling cost efficient and scalable semantic segmentation.
RecGPT-V2 Technical Report
Dec 16, 2025



Large language models (LLMs) have demonstrated remarkable potential in transforming recommender systems from implicit behavioral pattern matching to explicit intent reasoning. While RecGPT-V1 successfully pioneered this paradigm by integrating LLM-based reasoning into user interest mining and item tag prediction, it suffers from four fundamental limitations: (1) computational inefficiency and cognitive redundancy across multiple reasoning routes; (2) insufficient explanation diversity in fixed-template generation; (3) limited generalization under supervised learning paradigms; and (4) simplistic outcome-focused evaluation that fails to match human standards. To address these challenges, we present RecGPT-V2 with four key innovations. First, a Hierarchical Multi-Agent System restructures intent reasoning through coordinated collaboration, eliminating cognitive duplication while enabling diverse intent coverage. Combined with Hybrid Representation Inference that compresses user-behavior contexts, our framework reduces GPU consumption by 60% and improves exclusive recall from 9.39% to 10.99%. Second, a Meta-Prompting framework dynamically generates contextually adaptive prompts, improving explanation diversity by +7.3%. Third, constrained reinforcement learning mitigates multi-reward conflicts, achieving +24.1% improvement in tag prediction and +13.0% in explanation acceptance. Fourth, an Agent-as-a-Judge framework decomposes assessment into multi-step reasoning, improving human preference alignment. Online A/B tests on Taobao demonstrate significant improvements: +2.98% CTR, +3.71% IPV, +2.19% TV, and +11.46% NER. RecGPT-V2 establishes both the technical feasibility and commercial viability of deploying LLM-powered intent reasoning at scale, bridging the gap between cognitive exploration and industrial utility.
Fragile by Design: On the Limits of Adversarial Defenses in Personalized Generation
Nov 13, 2025Personalized AI applications such as DreamBooth enable the generation of customized content from user images, but also raise significant privacy concerns, particularly the risk of facial identity leakage. Recent defense mechanisms like Anti-DreamBooth attempt to mitigate this risk by injecting adversarial perturbations into user photos to prevent successful personalization. However, we identify two critical yet overlooked limitations of these methods. First, the adversarial examples often exhibit perceptible artifacts such as conspicuous patterns or stripes, making them easily detectable as manipulated content. Second, the perturbations are highly fragile, as even a simple, non-learned filter can effectively remove them, thereby restoring the model's ability to memorize and reproduce user identity. To investigate this vulnerability, we propose a novel evaluation framework, AntiDB_Purify, to systematically evaluate existing defenses under realistic purification threats, including both traditional image filters and adversarial purification. Results reveal that none of the current methods maintains their protective effectiveness under such threats. These findings highlight that current defenses offer a false sense of security and underscore the urgent need for more imperceptible and robust protections to safeguard user identity in personalized generation.
Chasing Consistency: Quantifying and Optimizing Human-Model Alignment in Chain-of-Thought Reasoning
Nov 09, 2025This paper presents a framework for evaluating and optimizing reasoning consistency in Large Language Models (LLMs) via a new metric, the Alignment Score, which quantifies the semantic alignment between model-generated reasoning chains and human-written reference chains in Chain-of-Thought (CoT) reasoning. Empirically, we find that 2-hop reasoning chains achieve the highest Alignment Score. To explain this phenomenon, we define four key error types: logical disconnection, thematic shift, redundant reasoning, and causal reversal, and show how each contributes to the degradation of the Alignment Score. Building on this analysis, we further propose Semantic Consistency Optimization Sampling (SCOS), a method that samples and favors chains with minimal alignment errors, significantly improving Alignment Scores by an average of 29.84% with longer reasoning chains, such as in 3-hop tasks.
Can MLLMs Absorb Math Reasoning Abilities from LLMs as Free Lunch?
Oct 16, 2025Math reasoning has been one crucial ability of large language models (LLMs), where significant advancements have been achieved in recent years. However, most efforts focus on LLMs by curating high-quality annotation data and intricate training (or inference) paradigms, while the math reasoning performance of multi-modal LLMs (MLLMs) remains lagging behind. Since the MLLM typically consists of an LLM and a vision block, we wonder: Can MLLMs directly absorb math reasoning abilities from off-the-shelf math LLMs without tuning? Recent model-merging approaches may offer insights into this question. However, they overlook the alignment between the MLLM and LLM, where we find that there is a large gap between their parameter spaces, resulting in lower performance. Our empirical evidence reveals two key factors behind this issue: the identification of crucial reasoning-associated layers in the model and the mitigation of the gaps in parameter space. Based on the empirical insights, we propose IP-Merging that first identifies the reasoning-associated parameters in both MLLM and Math LLM, then projects them into the subspace of MLLM, aiming to maintain the alignment, and finally merges parameters in this subspace. IP-Merging is a tuning-free approach since parameters are directly adjusted. Extensive experiments demonstrate that our IP-Merging method can enhance the math reasoning ability of MLLMs directly from Math LLMs without compromising their other capabilities.
Distributed Nash Equilibrium Seeking Algorithm in Aggregative Games for Heterogeneous Multi-Robot Systems
Sep 19, 2025This paper develops a distributed Nash Equilibrium seeking algorithm for heterogeneous multi-robot systems. The algorithm utilises distributed optimisation and output control to achieve the Nash equilibrium by leveraging information shared among neighbouring robots. Specifically, we propose a distributed optimisation algorithm that calculates the Nash equilibrium as a tailored reference for each robot and designs output control laws for heterogeneous multi-robot systems to track it in an aggregative game. We prove that our algorithm is guaranteed to converge and result in efficient outcomes. The effectiveness of our approach is demonstrated through numerical simulations and empirical testing with physical robots.