 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Dataset and a Deep Learning Method for Mitosis Nuclei Segmentation and Classification
Dec 27, 2022



Mitosis nuclei count is one of the important indicators for the pathological diagnosis of breast cancer. The manual annotation needs experienced pathologists, which is very time-consuming and inefficient. With the development of deep learning methods, some models with good performance have emerged, but the generalization ability should be further strengthened. In this paper, we propose a two-stage mitosis segmentation and classification method, named SCMitosis. Firstly, the segmentation performance with a high recall rate is achieved by the proposed depthwise separable convolution residual block and channel-spatial attention gate. Then, a classification network is cascaded to further improve the detection performance of mitosis nuclei. The proposed model is verified on the ICPR 2012 dataset, and the highest F-score value of 0.8687 is obtained compared with the current state-of-the-art algorithms. In addition, the model also achieves good performance on GZMH dataset, which is prepared by our group and will be firstly released with the publication of this paper. The code will be available at: https://github.com/antifen/mitosis-nuclei-segmentation.
Binary Representation via Jointly Personalized Sparse Hashing
Aug 31, 2022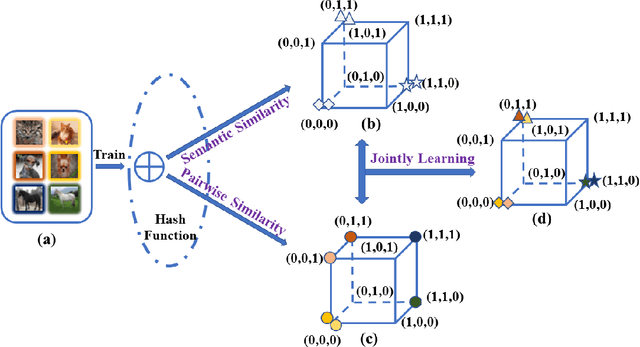
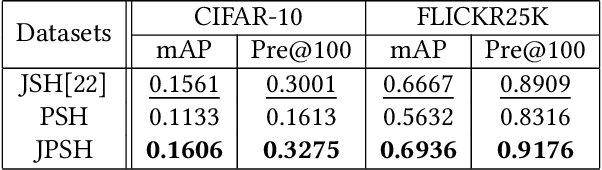
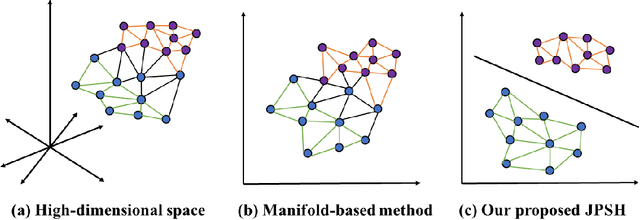
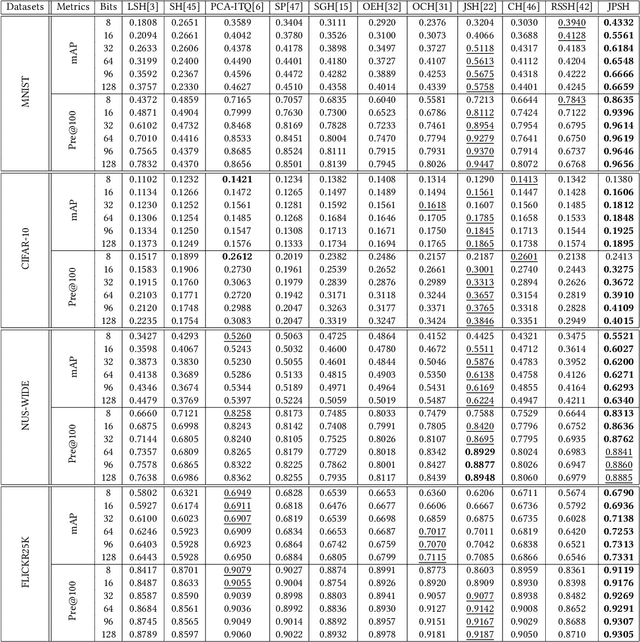
Unsupervised hashing has attracted much attention for binary representation learning due to the requirement of economical storage and efficiency of binary codes. It aims to encode high-dimensional features in the Hamming space with similarity preservation between instances. However, most existing methods learn hash functions in manifold-based approaches. Those methods capture the local geometric structures (i.e., pairwise relationships) of data, and lack satisfactory performance in dealing with real-world scenarios that produce similar features (e.g. color and shape) with different semantic information. To address this challenge, in this work, we propose an effective unsupervised method, namely Jointly Personalized Sparse Hashing (JPSH), for binary representation learning. To be specific, firstly, we propose a novel personalized hashing module, i.e., Personalized Sparse Hashing (PSH). Different personalized subspaces are constructed to reflect category-specific attributes for different clusters, adaptively mapping instances within the same cluster to the same Hamming space. In addition, we deploy sparse constraints for different personalized subspaces to select important features. We also collect the strengths of the other clusters to build the PSH module with avoiding over-fitting. Then, to simultaneously preserve semantic and pairwise similarities in our JPSH, we incorporate the PSH and manifold-based hash learning into the seamless formulation. As such, JPSH not only distinguishes the instances from different clusters, but also preserves local neighborhood structures within the cluster. Finally, an alternating optimization algorithm is adopted to iteratively capture analytical solutions of the JPSH model. Extensive experiments on four benchmark datasets verify that the JPSH outperforms several hashing algorithms on the similarity search task.
Neural Points: Point Cloud Representation with Neural Fields
Dec 13, 2021
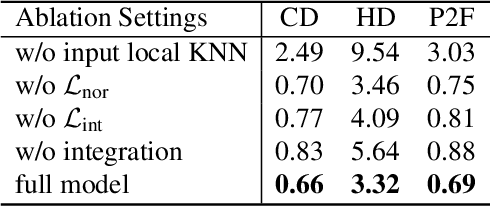
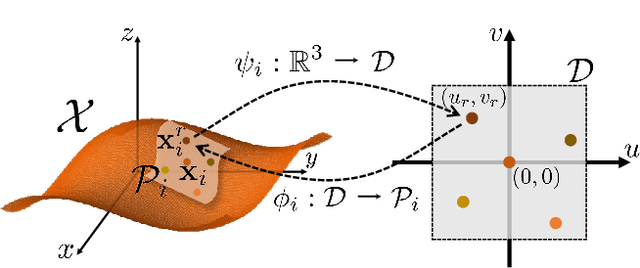
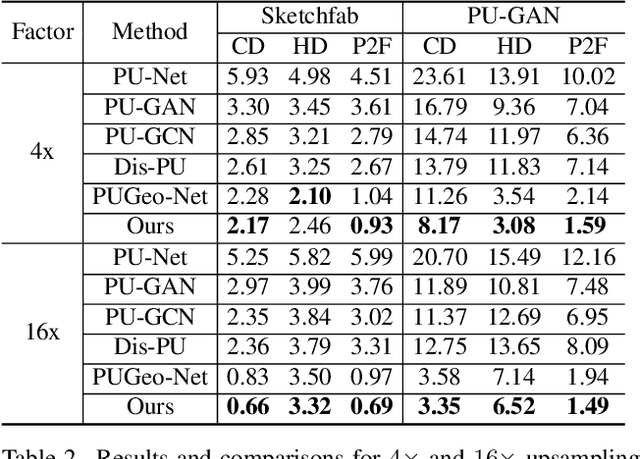
In this paper, we propose \emph{Neural Points}, a novel point cloud representation. Unlike traditional point cloud representation where each point only represents a position or a local plane in the 3D space, each point in Neural Points represents a local continuous geometric shape via neural fields. Therefore, Neural Points can express much more complex details and thus have a stronger representation ability. Neural Points is trained with high-resolution surface containing rich geometric details, such that the trained model has enough expression ability for various shapes. Specifically, we extract deep local features on the points and construct neural fields through the local isomorphism between the 2D parametric domain and the 3D local patch. In the final, local neural fields are integrated together to form the global surface. Experimental results show that Neural Points has powerful representation ability and demonstrate excellent robustness and generalization ability. With Neural Points, we can resample point cloud with arbitrary resolutions, and it outperforms state-of-the-art point cloud upsampling methods by a large margin.
GAN for Vision, KG for Relation: a Two-stage Deep Network for Zero-shot Action Recognition
May 25, 2021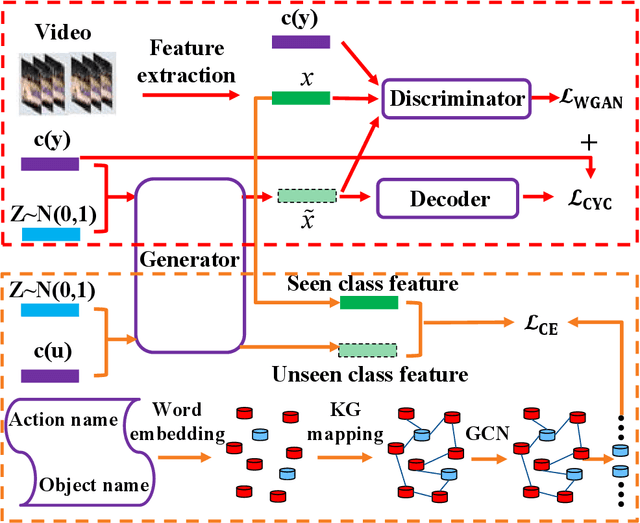
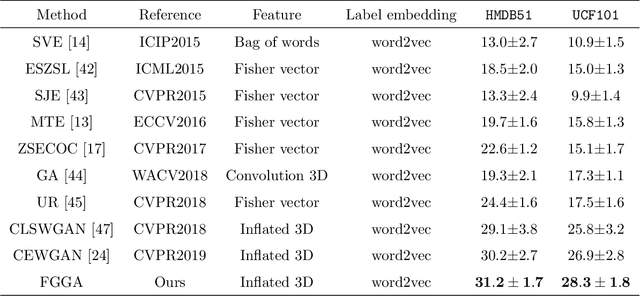

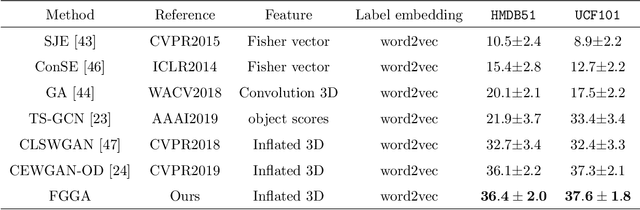
Zero-shot action recognition can recognize samples of unseen classes that are unavailable in training by exploring common latent semantic representation in samples. However, most methods neglected the connotative relation and extensional relation between the action classes, which leads to the poor generalization ability of the zero-shot learning. Furthermore, the learned classifier incline to predict the samples of seen class, which leads to poor classification performance. To solve the above problems, we propose a two-stage deep neural network for zero-shot action recognition, which consists of a feature generation sub-network serving as the sampling stage and a graph attention sub-network serving as the classification stage. In the sampling stage, we utilize a generative adversarial networks (GAN) trained by action features and word vectors of seen classes to synthesize the action features of unseen classes, which can balance the training sample data of seen classes and unseen classes. In the classification stage, we construct a knowledge graph (KG) based on the relationship between word vectors of action classes and related objects, and propose a graph convolution network (GCN) based on attention mechanism, which dynamically updates the relationship between action classes and objects, and enhances the generalization ability of zero-shot learning. In both stages, we all use word vectors as bridges for feature generation and classifier generalization from seen classes to unseen classes. We compare our method with state-of-the-art methods on UCF101 and HMDB51 datasets. Experimental results show that our proposed method improves the classification performance of the trained classifier and achieves higher accuracy.
Neural Task Planning with And-Or Graph Representations
Aug 25, 2018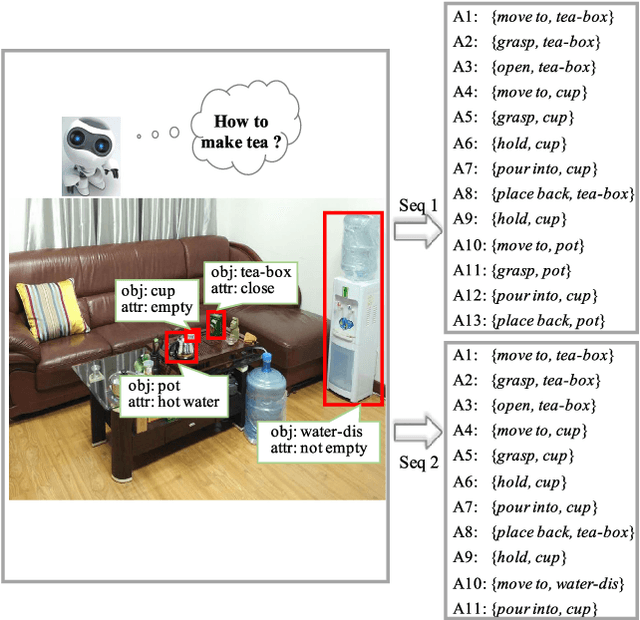
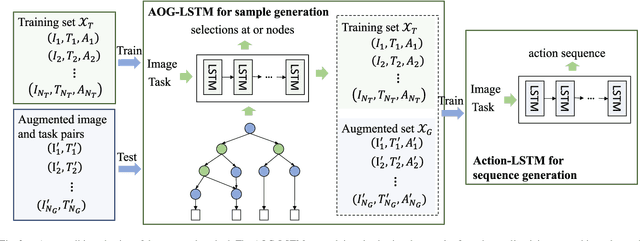
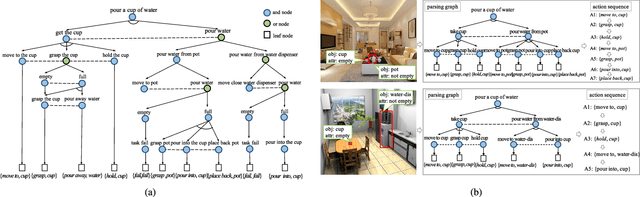
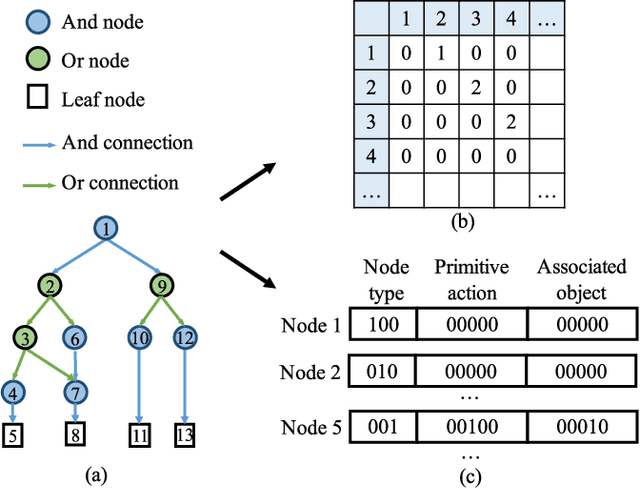
This paper focuses on semantic task planning, i.e., predicting a sequence of actions toward accomplishing a specific task under a certain scene, which is a new problem in computer vision research. The primary challenges are how to model task-specific knowledge and how to integrate this knowledge into the learning procedure. In this work, we propose training a recurrent long short-term memory (LSTM) network to address this problem, i.e., taking a scene image (including pre-located objects) and the specified task as input and recurrently predicting action sequences. However, training such a network generally requires large numbers of annotated samples to cover the semantic space (e.g., diverse action decomposition and ordering). To overcome this issue, we introduce a knowledge and-or graph (AOG) for task description, which hierarchically represents a task as atomic actions. With this AOG representation, we can produce many valid samples (i.e., action sequences according to common sense) by training another auxiliary LSTM network with a small set of annotated samples. Furthermore, these generated samples (i.e., task-oriented action sequences) effectively facilitate training of the model for semantic task planning. In our experiments, we create a new dataset that contains diverse daily tasks and extensively evaluate the effectiveness of our approach.
Fine-Grained Representation Learning and Recognition by Exploiting Hierarchical Semantic Embedding
Aug 14, 2018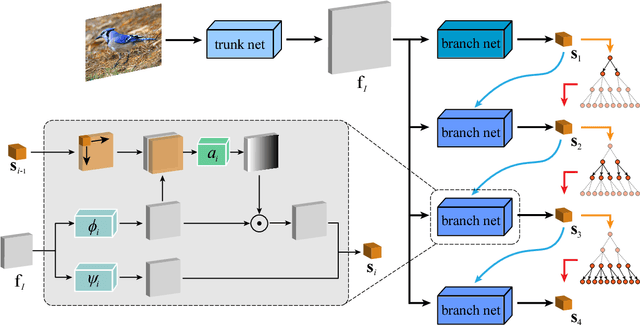
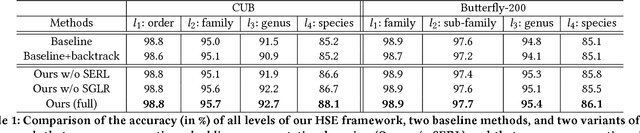

Object categories inherently form a hierarchy with different levels of concept abstraction, especially for fine-grained categories. For example, birds (Aves) can be categorized according to a four-level hierarchy of order, family, genus, and species. This hierarchy encodes rich correlations among various categories across different levels, which can effectively regularize the semantic space and thus make prediction less ambiguous. However, previous studies of fine-grained image recognition primarily focus on categories of one certain level and usually overlook this correlation information. In this work, we investigate simultaneously predicting categories of different levels in the hierarchy and integrating this structured correlation information into the deep neural network by developing a novel Hierarchical Semantic Embedding (HSE) framework. Specifically, the HSE framework sequentially predicts the category score vector of each level in the hierarchy, from highest to lowest. At each level, it incorporates the predicted score vector of the higher level as prior knowledge to learn finer-grained feature representation. During training, the predicted score vector of the higher level is also employed to regularize label prediction by using it as soft targets of corresponding sub-categories. To evaluate the proposed framework, we organize the 200 bird species of the Caltech-UCSD birds dataset with the four-level category hierarchy and construct a large-scale butterfly dataset that also covers four level categories. Extensive experiments on these two and the newly-released VegFru datasets demonstrate the superiority of our HSE framework over the baseline methods and existing competitors.
Learning to Segment Object Candidates via Recursive Neural Networks
Jul 29, 2018
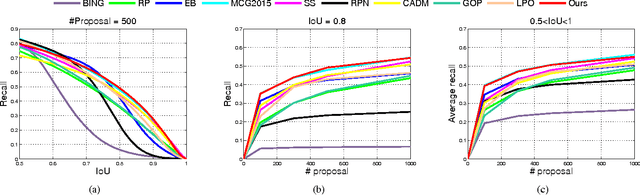
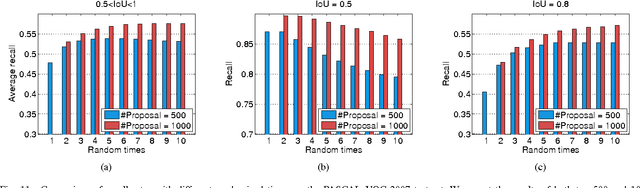
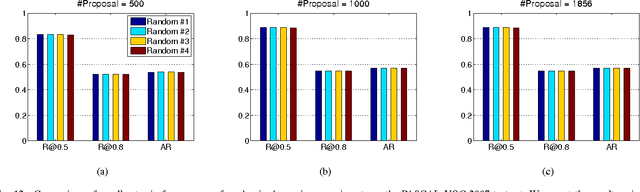
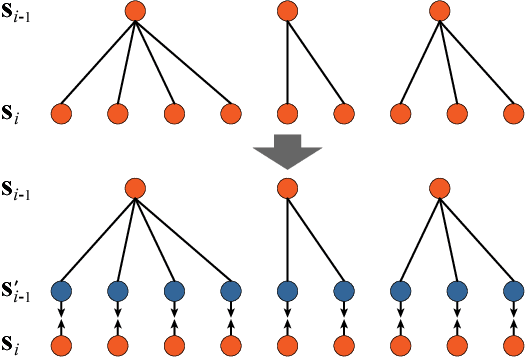
To avoid the exhaustive search over locations and scales, current state-of-the-art object detection systems usually involve a crucial component generating a batch of candidate object proposals from images. In this paper, we present a simple yet effective approach for segmenting object proposals via a deep architecture of recursive neural networks (ReNNs), which hierarchically groups regions for detecting object candidates over scales. Unlike traditional methods that mainly adopt fixed similarity measures for merging regions or finding object proposals, our approach adaptively learns the region merging similarity and the objectness measure during the process of hierarchical region grouping. Specifically, guided by a structured loss, the ReNN model jointly optimizes the cross-region similarity metric with the region merging process as well as the objectness prediction. During inference of the object proposal generation, we introduce randomness into the greedy search to cope with the ambiguity of grouping regions. Extensive experiments on standard benchmarks, e.g., PASCAL VOC and ImageNet, suggest that our approach is capable of producing object proposals with high recall while well preserving the object boundaries and outperforms other existing methods in both accuracy and efficiency.
Knowledge-Embedded Representation Learning for Fine-Grained Image Recognition
Jul 02, 2018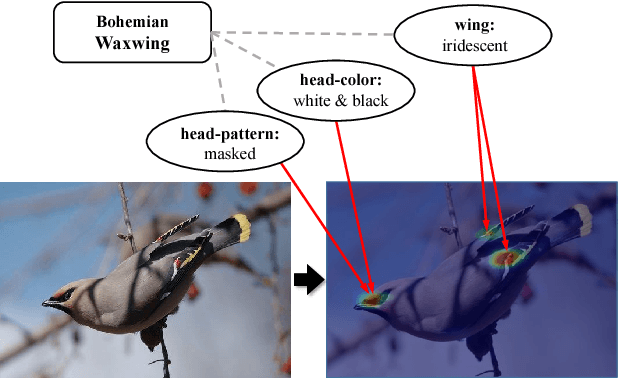
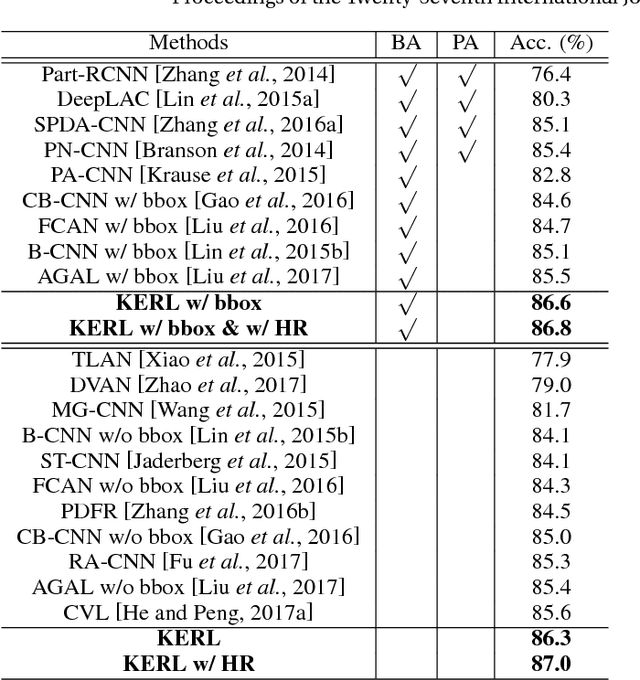
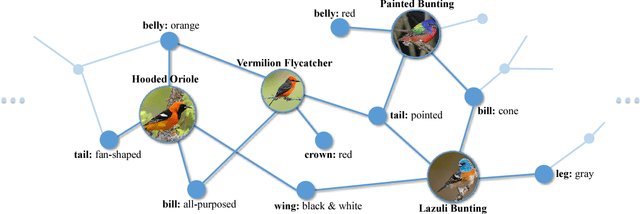
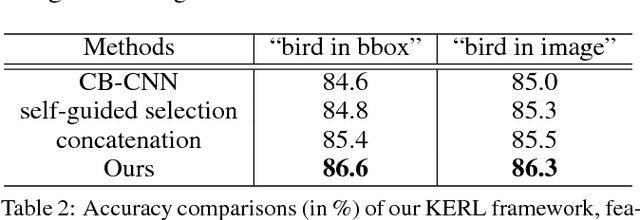
Humans can naturally understand an image in depth with the aid of rich knowledge accumulated from daily lives or professions. For example, to achieve fine-grained image recognition (e.g., categorizing hundreds of subordinate categories of birds) usually requires a comprehensive visual concept organization including category labels and part-level attributes. In this work, we investigate how to unify rich professional knowledge with deep neural network architectures and propose a Knowledge-Embedded Representation Learning (KERL) framework for handling the problem of fine-grained image recognition. Specifically, we organize the rich visual concepts in the form of knowledge graph and employ a Gated Graph Neural Network to propagate node message through the graph for generating the knowledge representation. By introducing a novel gated mechanism, our KERL framework incorporates this knowledge representation into the discriminative image feature learning, i.e., implicitly associating the specific attributes with the feature maps. Compared with existing methods of fine-grained image classification, our KERL framework has several appealing properties: i) The embedded high-level knowledge enhances the feature representation, thus facilitating distinguishing the subtle differences among subordinate categories. ii) Our framework can learn feature maps with a meaningful configuration that the highlighted regions finely accord with the nodes (specific attributes) of the knowledge graph. Extensive experiments on the widely used Caltech-UCSD bird dataset demonstrate the superiority of our KERL framework over existing state-of-the-art methods.
Structured Inhomogeneous Density Map Learning for Crowd Counting
Jan 20, 2018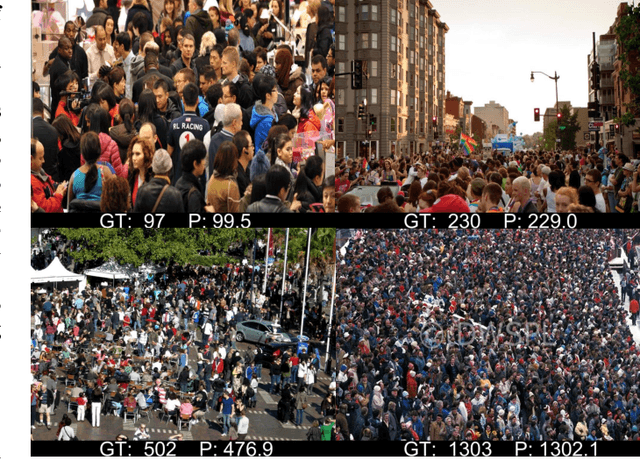
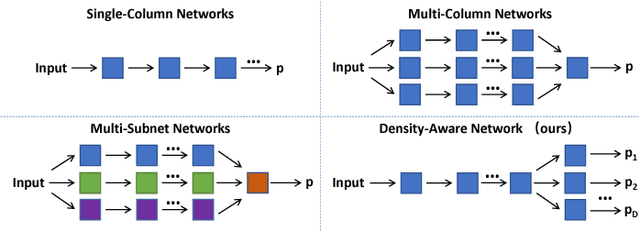
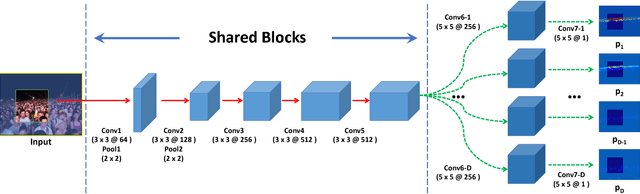

In this paper, we aim at tackling the problem of crowd counting in extremely high-density scenes, which contain hundreds, or even thousands of people. We begin by a comprehensive analysis of the most widely used density map-based methods, and demonstrate how easily existing methods are affected by the inhomogeneous density distribution problem, e.g., causing them to be sensitive to outliers, or be hard to optimized. We then present an extremely simple solution to the inhomogeneous density distribution problem, which can be intuitively summarized as extending the density map from 2D to 3D, with the extra dimension implicitly indicating the density level. Such solution can be implemented by a single Density-Aware Network, which is not only easy to train, but also can achieve the state-of-art performance on various challenging datasets.
Learning Deep Similarity Models with Focus Ranking for Fabric Image Retrieval
Dec 29, 2017

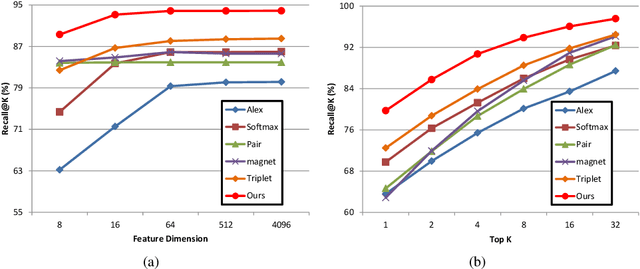
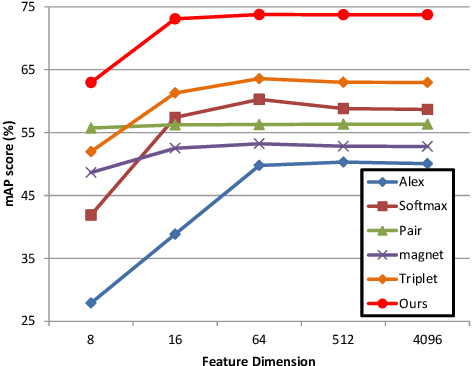
Fabric image retrieval is beneficial to many applications including clothing searching, online shopping and cloth modeling. Learning pairwise image similarity is of great importance to an image retrieval task. With the resurgence of Convolutional Neural Networks (CNNs), recent works have achieved significant progresses via deep representation learning with metric embedding, which drives similar examples close to each other in a feature space, and dissimilar ones apart from each other. In this paper, we propose a novel embedding method termed focus ranking that can be easily unified into a CNN for jointly learning image representations and metrics in the context of fine-grained fabric image retrieval. Focus ranking aims to rank similar examples higher than all dissimilar ones by penalizing ranking disorders via the minimization of the overall cost attributed to similar samples being ranked below dissimilar ones. At the training stage, training samples are organized into focus ranking units for efficient optimization. We build a large-scale fabric image retrieval dataset (FIRD) with about 25,000 images of 4,300 fabrics, and test the proposed model on the FIRD dataset. Experimental results show the superiority of the proposed model over existing metric embedding models.