 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Domain Generalization for Face Anti-spoofing: Separability and Alignment
Mar 23, 2023This work studies the generalization issue of face anti-spoofing (FAS) models on domain gaps, such as image resolution, blurriness and sensor variations. Most prior works regard domain-specific signals as a negative impact, and apply metric learning or adversarial losses to remove them from feature representation. Though learning a domain-invariant feature space is viable for the training data, we show that the feature shift still exists in an unseen test domain, which backfires on the generalizability of the classifier. In this work, instead of constructing a domain-invariant feature space, we encourage domain separability while aligning the live-to-spoof transition (i.e., the trajectory from live to spoof) to be the same for all domains. We formulate this FAS strategy of separability and alignment (SA-FAS) as a problem of invariant risk minimization (IRM), and learn domain-variant feature representation but domain-invariant classifier. We demonstrate the effectiveness of SA-FAS on challenging cross-domain FAS datasets and establish state-of-the-art performance.
Can Adversarial Examples Be Parsed to Reveal Victim Model Information?
Mar 15, 2023Numerous adversarial attack methods have been developed to generate imperceptible image perturbations that can cause erroneous predictions of state-of-the-art machine learning (ML) models, in particular, deep neural networks (DNNs). Despite intense research on adversarial attacks, little effort was made to uncover 'arcana' carried in adversarial attacks. In this work, we ask whether it is possible to infer data-agnostic victim model (VM) information (i.e., characteristics of the ML model or DNN used to generate adversarial attacks) from data-specific adversarial instances. We call this 'model parsing of adversarial attacks' - a task to uncover 'arcana' in terms of the concealed VM information in attacks. We approach model parsing via supervised learning, which correctly assigns classes of VM's model attributes (in terms of architecture type, kernel size, activation function, and weight sparsity) to an attack instance generated from this VM. We collect a dataset of adversarial attacks across 7 attack types generated from 135 victim models (configured by 5 architecture types, 3 kernel size setups, 3 activation function types, and 3 weight sparsity ratios). We show that a simple, supervised model parsing network (MPN) is able to infer VM attributes from unseen adversarial attacks if their attack settings are consistent with the training setting (i.e., in-distribution generalization assessment). We also provide extensive experiments to justify the feasibility of VM parsing from adversarial attacks, and the influence of training and evaluation factors in the parsing performance (e.g., generalization challenge raised in out-of-distribution evaluation). We further demonstrate how the proposed MPN can be used to uncover the source VM attributes from transfer attacks, and shed light on a potential connection between model parsing and attack transferability.
Learning Implicit Functions for Dense 3D Shape Correspondence of Generic Objects
Dec 29, 2022The objective of this paper is to learn dense 3D shape correspondence for topology-varying generic objects in an unsupervised manner. Conventional implicit functions estimate the occupancy of a 3D point given a shape latent code. Instead, our novel implicit function produces a probabilistic embedding to represent each 3D point in a part embedding space. Assuming the corresponding points are similar in the embedding space, we implement dense correspondence through an inverse function mapping from the part embedding vector to a corresponded 3D point. Both functions are jointly learned with several effective and uncertainty-aware loss functions to realize our assumption, together with the encoder generating the shape latent code. During inference, if a user selects an arbitrary point on the source shape, our algorithm can automatically generate a confidence score indicating whether there is a correspondence on the target shape, as well as the corresponding semantic point if there is one. Such a mechanism inherently benefits man-made objects with different part constitutions. The effectiveness of our approach is demonstrated through unsupervised 3D semantic correspondence and shape segmentation.
CoCo: Coherence-Enhanced Machine-Generated Text Detection Under Data Limitation With Contrastive Learning
Dec 20, 2022



Machine-Generated Text (MGT) detection, a task that discriminates MGT from Human-Written Text (HWT), plays a crucial role in preventing misuse of text generative models, which excel in mimicking human writing style recently. Latest proposed detectors usually take coarse text sequence as input and output some good results by fine-tune pretrained models with standard cross-entropy loss. However, these methods fail to consider the linguistic aspect of text (e.g., coherence) and sentence-level structures. Moreover, they lack the ability to handle the low-resource problem which could often happen in practice considering the enormous amount of textual data online. In this paper, we present a coherence-based contrastive learning model named CoCo to detect the possible MGT under low-resource scenario. Inspired by the distinctiveness and permanence properties of linguistic feature, we represent text as a coherence graph to capture its entity consistency, which is further encoded by the pretrained model and graph neural network. To tackle the challenges of data limitations, we employ a contrastive learning framework and propose an improved contrastive loss for making full use of hard negative samples in training stage. The experiment results on two public datasets prove our approach outperforms the state-of-art methods significantly.
Cluster and Aggregate: Face Recognition with Large Probe Set
Oct 19, 2022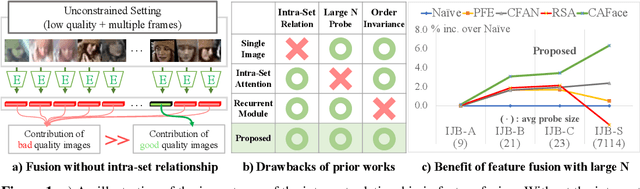
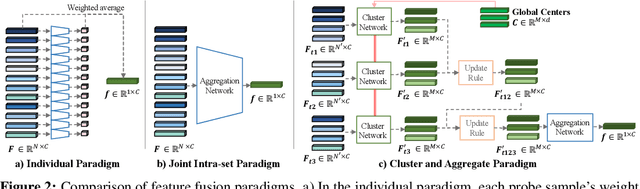
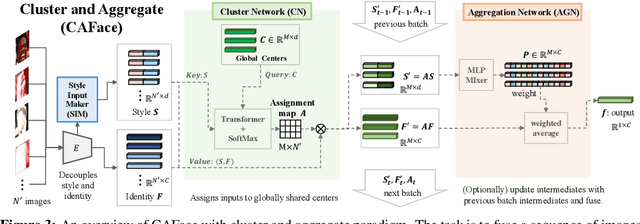

Feature fusion plays a crucial role in unconstrained face recognition where inputs (probes) comprise of a set of $N$ low quality images whose individual qualities vary. Advances in attention and recurrent modules have led to feature fusion that can model the relationship among the images in the input set. However, attention mechanisms cannot scale to large $N$ due to their quadratic complexity and recurrent modules suffer from input order sensitivity. We propose a two-stage feature fusion paradigm, Cluster and Aggregate, that can both scale to large $N$ and maintain the ability to perform sequential inference with order invariance. Specifically, Cluster stage is a linear assignment of $N$ inputs to $M$ global cluster centers, and Aggregation stage is a fusion over $M$ clustered features. The clustered features play an integral role when the inputs are sequential as they can serve as a summarization of past features. By leveraging the order-invariance of incremental averaging operation, we design an update rule that achieves batch-order invariance, which guarantees that the contributions of early image in the sequence do not diminish as time steps increase. Experiments on IJB-B and IJB-S benchmark datasets show the superiority of the proposed two-stage paradigm in unconstrained face recognition. Code and pretrained models are available in https://github.com/mk-minchul/caface
Multi-domain Learning for Updating Face Anti-spoofing Models
Aug 23, 2022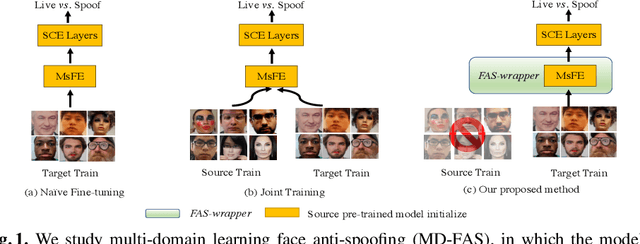
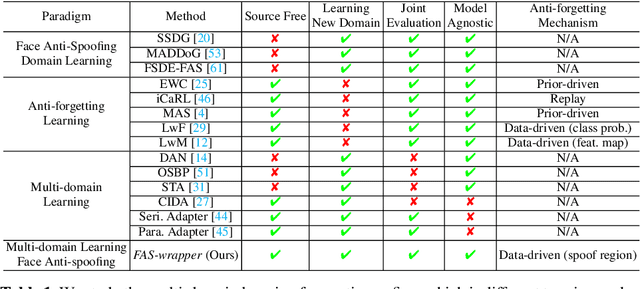
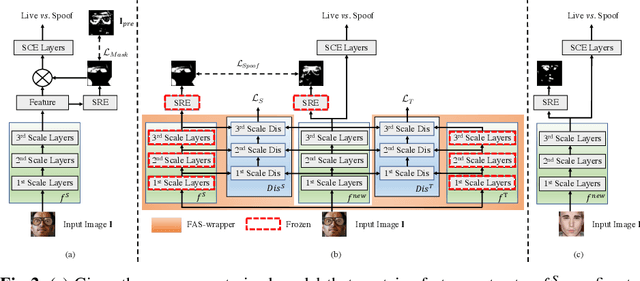
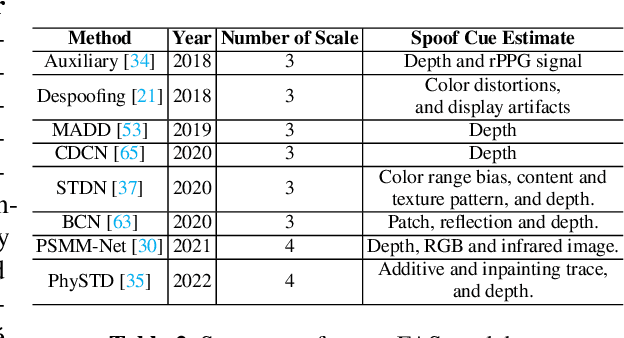
In this work, we study multi-domain learning for face anti-spoofing(MD-FAS), where a pre-trained FAS model needs to be updated to perform equally well on both source and target domains while only using target domain data for updating. We present a new model for MD-FAS, which addresses the forgetting issue when learning new domain data, while possessing a high level of adaptability. First, we devise a simple yet effective module, called spoof region estimator(SRE), to identify spoof traces in the spoof image. Such spoof traces reflect the source pre-trained model's responses that help upgraded models combat catastrophic forgetting during updating. Unlike prior works that estimate spoof traces which generate multiple outputs or a low-resolution binary mask, SRE produces one single, detailed pixel-wise estimate in an unsupervised manner. Secondly, we propose a novel framework, named FAS-wrapper, which transfers knowledge from the pre-trained models and seamlessly integrates with different FAS models. Lastly, to help the community further advance MD-FAS, we construct a new benchmark based on SIW, SIW-Mv2 and Oulu-NPU, and introduce four distinct protocols for evaluation, where source and target domains are different in terms of spoof type, age, ethnicity, and illumination. Our proposed method achieves superior performance on the MD-FAS benchmark than previous methods. Our code and newly curated SIW-Mv2 are publicly available.
DEVIANT: Depth EquiVarIAnt NeTwork for Monocular 3D Object Detection
Jul 21, 2022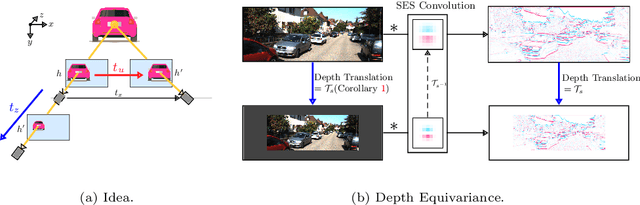
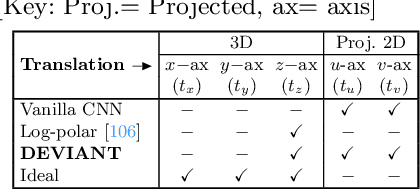
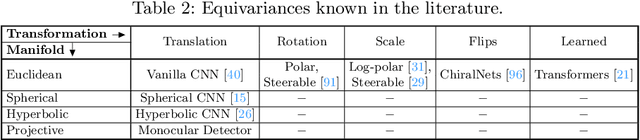
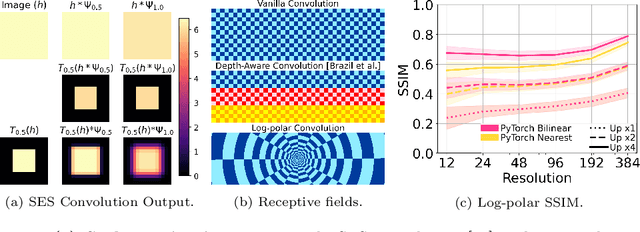
Modern neural networks use building blocks such as convolutions that are equivariant to arbitrary 2D translations. However, these vanilla blocks are not equivariant to arbitrary 3D translations in the projective manifold. Even then, all monocular 3D detectors use vanilla blocks to obtain the 3D coordinates, a task for which the vanilla blocks are not designed for. This paper takes the first step towards convolutions equivariant to arbitrary 3D translations in the projective manifold. Since the depth is the hardest to estimate for monocular detection, this paper proposes Depth EquiVarIAnt NeTwork (DEVIANT) built with existing scale equivariant steerable blocks. As a result, DEVIANT is equivariant to the depth translations in the projective manifold whereas vanilla networks are not. The additional depth equivariance forces the DEVIANT to learn consistent depth estimates, and therefore, DEVIANT achieves state-of-the-art monocular 3D detection results on KITTI and Waymo datasets in the image-only category and performs competitively to methods using extra information. Moreover, DEVIANT works better than vanilla networks in cross-dataset evaluation. Code and models at https://github.com/abhi1kumar/DEVIANT
2D GANs Meet Unsupervised Single-view 3D Reconstruction
Jul 20, 2022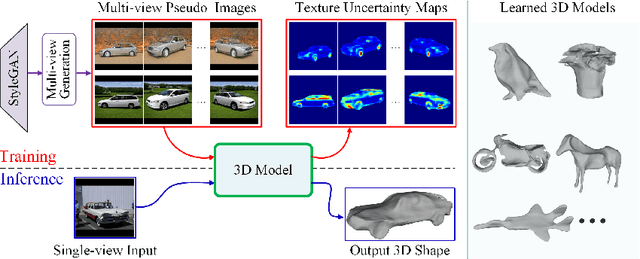
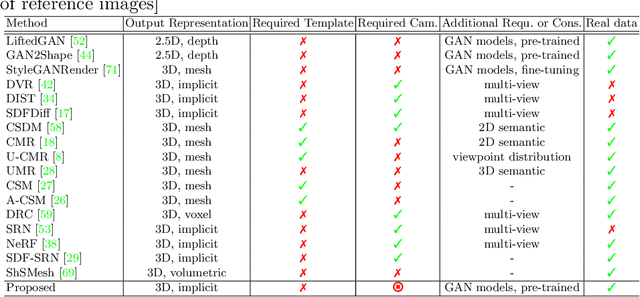
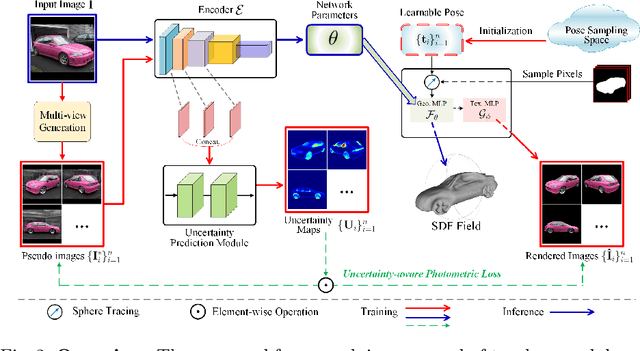
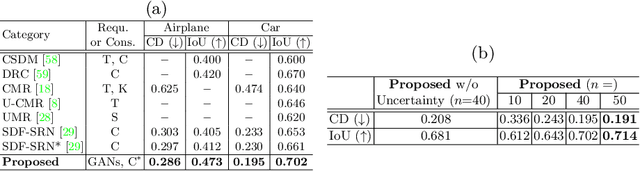
Recent research has shown that controllable image generation based on pre-trained GANs can benefit a wide range of computer vision tasks. However, less attention has been devoted to 3D vision tasks. In light of this, we propose a novel image-conditioned neural implicit field, which can leverage 2D supervisions from GAN-generated multi-view images and perform the single-view reconstruction of generic objects. Firstly, a novel offline StyleGAN-based generator is presented to generate plausible pseudo images with full control over the viewpoint. Then, we propose to utilize a neural implicit function, along with a differentiable renderer to learn 3D geometry from pseudo images with object masks and rough pose initializations. To further detect the unreliable supervisions, we introduce a novel uncertainty module to predict uncertainty maps, which remedy the negative effect of uncertain regions in pseudo images, leading to a better reconstruction performance. The effectiveness of our approach is demonstrated through superior single-view 3D reconstruction results of generic objects.
Controllable and Guided Face Synthesis for Unconstrained Face Recognition
Jul 20, 2022

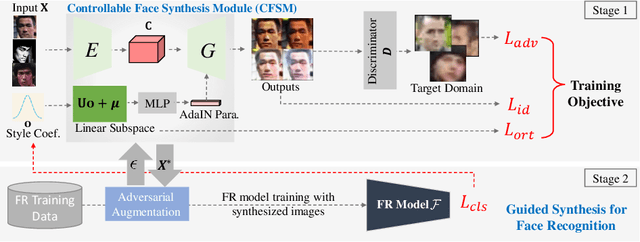
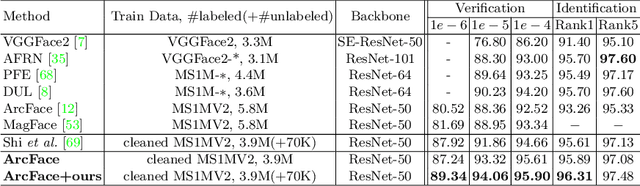
Although significant advances have been made in face recognition (FR), FR in unconstrained environments remains challenging due to the domain gap between the semi-constrained training datasets and unconstrained testing scenarios. To address this problem, we propose a controllable face synthesis model (CFSM) that can mimic the distribution of target datasets in a style latent space. CFSM learns a linear subspace with orthogonal bases in the style latent space with precise control over the diversity and degree of synthesis. Furthermore, the pre-trained synthesis model can be guided by the FR model, making the resulting images more beneficial for FR model training. Besides, target dataset distributions are characterized by the learned orthogonal bases, which can be utilized to measure the distributional similarity among face datasets. Our approach yields significant performance gains on unconstrained benchmarks, such as IJB-B, IJB-C, TinyFace and IJB-S (+5.76% Rank1).
AdaFace: Quality Adaptive Margin for Face Recognition
Apr 03, 2022
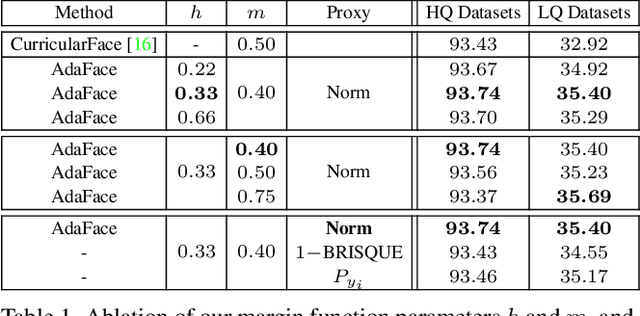


Recognition in low quality face datasets is challenging because facial attributes are obscured and degraded. Advances in margin-based loss functions have resulted in enhanced discriminability of faces in the embedding space. Further, previous studies have studied the effect of adaptive losses to assign more importance to misclassified (hard) examples. In this work, we introduce another aspect of adaptiveness in the loss function, namely the image quality. We argue that the strategy to emphasize misclassified samples should be adjusted according to their image quality. Specifically, the relative importance of easy or hard samples should be based on the sample's image quality. We propose a new loss function that emphasizes samples of different difficulties based on their image quality. Our method achieves this in the form of an adaptive margin function by approximating the image quality with feature norms. Extensive experiments show that our method, AdaFace, improves the face recognition performance over the state-of-the-art (SoTA) on four datasets (IJB-B, IJB-C, IJB-S and TinyFace). Code and models are released in https://github.com/mk-minchul/AdaFace.