 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEpisodic Memory Temporal Consistency for Cooperative Multi-Agent Reinforcement Learning
Jun 03, 2026Cooperative Multi-Agent Reinforcement Learning (MARL) frequently suffers from severe reward sparsity and exploration bottlenecks. While episodic memory mechanisms mitigate these issues by reusing high-return trajectories, they often trap agents in local optima due to unconstrained incentive distribution and semantic representation collapse. To address this, we propose Episodic Memory Temporal Consistency (EMTC), a framework that robustly constructs and selectively leverages historical experiences. EMTC introduces two synergistic components: (1) a Temporally Consistent Semantic Embedder that integrates contrastive learning with time-conditioned state reconstruction, preventing representation collapse and enabling precise memory retrieval; and (2) a Temporal Consistency Gating Mechanism that dynamically modulates episodic incentives based on temporal consistency error. This adaptive gate filters misleading signals from pseudo-successful trajectories, effectively mitigating Q-value overestimation. We provide theoretical guarantees, establishing a strict error bound that directly links the observable temporal consistency error to the underlying trajectory optimality and representation quality. Extensive evaluations on the SMAC and GRF benchmarks demonstrate that EMTC consistently outperforms state-of-the-art baselines. Notably, compared to the strongest episodic baseline, EMTC achieves absolute win-rate improvements of up to 24% in super-hard SMAC scenarios and an average improvement of 28% across GRF tasks.
LoongFlow: Directed Evolutionary Search via a Cognitive Plan-Execute-Summarize Paradigm
Dec 30, 2025The transition from static Large Language Models (LLMs) to self-improving agents is hindered by the lack of structured reasoning in traditional evolutionary approaches. Existing methods often struggle with premature convergence and inefficient exploration in high-dimensional code spaces. To address these challenges, we introduce LoongFlow, a self-evolving agent framework that achieves state-of-the-art solution quality with significantly reduced computational costs. Unlike "blind" mutation operators, LoongFlow integrates LLMs into a cognitive "Plan-Execute-Summarize" (PES) paradigm, effectively mapping the evolutionary search to a reasoning-heavy process. To sustain long-term architectural coherence, we incorporate a hybrid evolutionary memory system. By synergizing Multi-Island models with MAP-Elites and adaptive Boltzmann selection, this system theoretically balances the exploration-exploitation trade-off, maintaining diverse behavioral niches to prevent optimization stagnation. We instantiate LoongFlow with a General Agent for algorithmic discovery and an ML Agent for pipeline optimization. Extensive evaluations on the AlphaEvolve benchmark and Kaggle competitions demonstrate that LoongFlow outperforms leading baselines (e.g., OpenEvolve, ShinkaEvolve) by up to 60% in evolutionary efficiency while discovering superior solutions. LoongFlow marks a substantial step forward in autonomous scientific discovery, enabling the generation of expert-level solutions with reduced computational overhead.
Concentrate Attention: Towards Domain-Generalizable Prompt Optimization for Language Models
Jun 15, 2024



Recent advances in prompt optimization have notably enhanced the performance of pre-trained language models (PLMs) on downstream tasks. However, the potential of optimized prompts on domain generalization has been under-explored. To explore the nature of prompt generalization on unknown domains, we conduct pilot experiments and find that (i) Prompts gaining more attention weight from PLMs' deep layers are more generalizable and (ii) Prompts with more stable attention distributions in PLMs' deep layers are more generalizable. Thus, we offer a fresh objective towards domain-generalizable prompts optimization named "Concentration", which represents the "lookback" attention from the current decoding token to the prompt tokens, to increase the attention strength on prompts and reduce the fluctuation of attention distribution. We adapt this new objective to popular soft prompt and hard prompt optimization methods, respectively. Extensive experiments demonstrate that our idea improves comparison prompt optimization methods by 1.42% for soft prompt generalization and 2.16% for hard prompt generalization in accuracy on the multi-source domain generalization setting, while maintaining satisfying in-domain performance. The promising results validate the effectiveness of our proposed prompt optimization objective and provide key insights into domain-generalizable prompts.
StablePT: Towards Stable Prompting for Few-shot Learning via Input Separation
Apr 30, 2024Large language models have shown their ability to become effective few-shot learners with prompting, revoluting the paradigm of learning with data scarcity. However, this approach largely depends on the quality of prompt initialization, and always exhibits large variability among different runs. Such property makes prompt tuning highly unreliable and vulnerable to poorly constructed prompts, which limits its extension to more real-world applications. To tackle this issue, we propose to treat the hard prompt and soft prompt as separate inputs to mitigate noise brought by the prompt initialization. Furthermore, we optimize soft prompts with contrastive learning for utilizing class-aware information in the training process to maintain model performance. Experimental results demonstrate that \sysname outperforms state-of-the-art methods by 7.20% in accuracy and reduces the standard deviation by 2.02 on average. Furthermore, extensive experiments underscore its robustness and stability across 7 datasets covering various tasks.
Does DetectGPT Fully Utilize Perturbation? Selective Perturbation on Model-Based Contrastive Learning Detector would be Better
Feb 04, 2024



The burgeoning capabilities of large language models (LLMs) have raised growing concerns about abuse. DetectGPT, a zero-shot metric-based unsupervised machine-generated text detector, first introduces perturbation and shows great performance improvement. However, DetectGPT's random perturbation strategy might introduce noise, limiting the distinguishability and further performance improvements. Moreover, its logit regression module relies on setting the threshold, which harms the generalizability and applicability of individual or small-batch inputs. Hence, we propose a novel detector, Pecola, which uses selective strategy perturbation to relieve the information loss caused by random masking, and multi-pair contrastive learning to capture the implicit pattern information during perturbation, facilitating few-shot performance. The experiments show that Pecola outperforms the SOTA method by 1.20% in accuracy on average on four public datasets. We further analyze the effectiveness, robustness, and generalization of our perturbation method.
Dialogue for Prompting: a Policy-Gradient-Based Discrete Prompt Optimization for Few-shot Learning
Aug 14, 2023



Prompt-based pre-trained language models (PLMs) paradigm have succeeded substantially in few-shot natural language processing (NLP) tasks. However, prior discrete prompt optimization methods require expert knowledge to design the base prompt set and identify high-quality prompts, which is costly, inefficient, and subjective. Meanwhile, existing continuous prompt optimization methods improve the performance by learning the ideal prompts through the gradient information of PLMs, whose high computational cost, and low readability and generalizability are often concerning. To address the research gap, we propose a Dialogue-comprised Policy-gradient-based Discrete Prompt Optimization ($DP_2O$) method. We first design a multi-round dialogue alignment strategy for readability prompt set generation based on GPT-4. Furthermore, we propose an efficient prompt screening metric to identify high-quality prompts with linear complexity. Finally, we construct a reinforcement learning (RL) framework based on policy gradients to match the prompts to inputs optimally. By training a policy network with only 0.67% of the PLM parameter size on the tasks in the few-shot setting, $DP_2O$ outperforms the state-of-the-art (SOTA) method by 1.52% in accuracy on average on four open-source datasets. Moreover, subsequent experiments also demonstrate that $DP_2O$ has good universality, robustness, and generalization ability.
CoCo: Coherence-Enhanced Machine-Generated Text Detection Under Data Limitation With Contrastive Learning
Dec 20, 2022



Machine-Generated Text (MGT) detection, a task that discriminates MGT from Human-Written Text (HWT), plays a crucial role in preventing misuse of text generative models, which excel in mimicking human writing style recently. Latest proposed detectors usually take coarse text sequence as input and output some good results by fine-tune pretrained models with standard cross-entropy loss. However, these methods fail to consider the linguistic aspect of text (e.g., coherence) and sentence-level structures. Moreover, they lack the ability to handle the low-resource problem which could often happen in practice considering the enormous amount of textual data online. In this paper, we present a coherence-based contrastive learning model named CoCo to detect the possible MGT under low-resource scenario. Inspired by the distinctiveness and permanence properties of linguistic feature, we represent text as a coherence graph to capture its entity consistency, which is further encoded by the pretrained model and graph neural network. To tackle the challenges of data limitations, we employ a contrastive learning framework and propose an improved contrastive loss for making full use of hard negative samples in training stage. The experiment results on two public datasets prove our approach outperforms the state-of-art methods significantly.
A Duet Recommendation Algorithm Based on Jointly Local and Global Representation Learning
Dec 03, 2020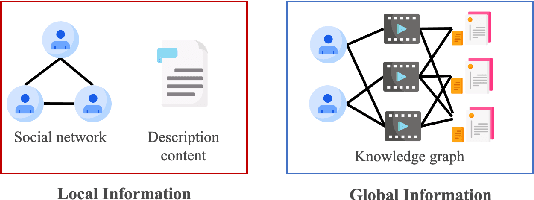
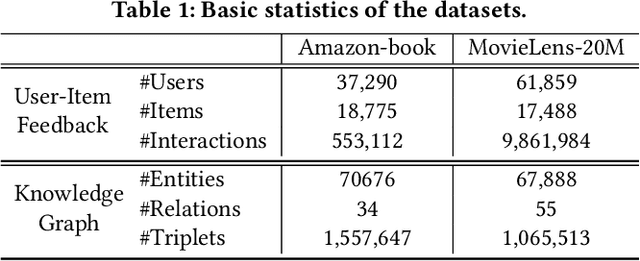
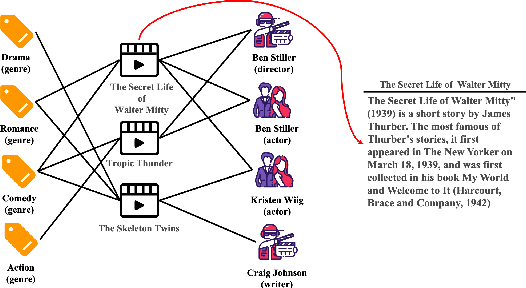
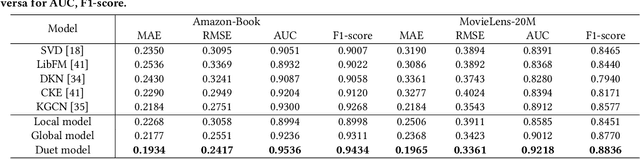
Knowledge graph (KG), as the side information, is widely utilized to learn the semantic representations of item/user for recommendation system. The traditional recommendation algorithms usually just depend on user-item interactions, but ignore the inherent web information describing the item/user, which could be formulated by the knowledge graph embedding (KGE) methods to significantly improve applications' performance. In this paper, we propose a knowledge-aware-based recommendation algorithm to capture the local and global representation learning from heterogeneous information. Specifically, the local model and global model can naturally depict the inner patterns in the content-based heterogeneous information and interactive behaviors among the users and items. Based on the method that local and global representations are learned jointly by graph convolutional networks with attention mechanism, the final recommendation probability is calculated by a fully-connected neural network. Extensive experiments are conducted on two real-world datasets to verify the proposed algorithm's validation. The evaluation results indicate that the proposed algorithm surpasses state-of-arts by $10.0\%$, $5.1\%$, $2.5\%$ and $1.8\%$ in metrics of MAE, RMSE, AUC and F1-score at least, respectively. The significant improvements reveal the capacity of our proposal to recommend user/item effectively.