 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFriendly Sharpness-Aware Minimization
Mar 19, 2024



Sharpness-Aware Minimization (SAM) has been instrumental in improving deep neural network training by minimizing both training loss and loss sharpness. Despite the practical success, the mechanisms behind SAM's generalization enhancements remain elusive, limiting its progress in deep learning optimization. In this work, we investigate SAM's core components for generalization improvement and introduce "Friendly-SAM" (F-SAM) to further enhance SAM's generalization. Our investigation reveals the key role of batch-specific stochastic gradient noise within the adversarial perturbation, i.e., the current minibatch gradient, which significantly influences SAM's generalization performance. By decomposing the adversarial perturbation in SAM into full gradient and stochastic gradient noise components, we discover that relying solely on the full gradient component degrades generalization while excluding it leads to improved performance. The possible reason lies in the full gradient component's increase in sharpness loss for the entire dataset, creating inconsistencies with the subsequent sharpness minimization step solely on the current minibatch data. Inspired by these insights, F-SAM aims to mitigate the negative effects of the full gradient component. It removes the full gradient estimated by an exponentially moving average (EMA) of historical stochastic gradients, and then leverages stochastic gradient noise for improved generalization. Moreover, we provide theoretical validation for the EMA approximation and prove the convergence of F-SAM on non-convex problems. Extensive experiments demonstrate the superior generalization performance and robustness of F-SAM over vanilla SAM. Code is available at https://github.com/nblt/F-SAM.
Inverse-Free Fast Natural Gradient Descent Method for Deep Learning
Mar 06, 2024



Second-order methods can converge much faster than first-order methods by incorporating second-order derivates or statistics, but they are far less prevalent in deep learning due to their computational inefficiency. To handle this, many of the existing solutions focus on reducing the size of the matrix to be inverted. However, it is still needed to perform the inverse operator in each iteration. In this paper, we present a fast natural gradient descent (FNGD) method, which only requires computing the inverse during the first epoch. Firstly, we reformulate the gradient preconditioning formula in the natural gradient descent (NGD) as a weighted sum of per-sample gradients using the Sherman-Morrison-Woodbury formula. Building upon this, to avoid the iterative inverse operation involved in computing coefficients, the weighted coefficients are shared across epochs without affecting the empirical performance. FNGD approximates the NGD as a fixed-coefficient weighted sum, akin to the average sum in first-order methods. Consequently, the computational complexity of FNGD can approach that of first-order methods. To demonstrate the efficiency of the proposed FNGD, we perform empirical evaluations on image classification and machine translation tasks. For training ResNet-18 on the CIFAR-100 dataset, FNGD can achieve a speedup of 2.05$\times$ compared with KFAC. For training Transformer on Multi30K, FNGD outperforms AdamW by 24 BLEU score while requiring almost the same training time.
Machine Unlearning by Suppressing Sample Contribution
Feb 23, 2024



Machine Unlearning (MU) is to forget data from a well-trained model, which is practically important due to the "right to be forgotten". In this paper, we start from the fundamental distinction between training data and unseen data on their contribution to the model: the training data contributes to the final model while the unseen data does not. We theoretically discover that the input sensitivity can approximately measure the contribution and practically design an algorithm, called MU-Mis (machine unlearning via minimizing input sensitivity), to suppress the contribution of the forgetting data. Experimental results demonstrate that MU-Mis outperforms state-of-the-art MU methods significantly. Additionally, MU-Mis aligns more closely with the application of MU as it does not require the use of remaining data.
Kernel PCA for Out-of-Distribution Detection
Feb 05, 2024



Out-of-Distribution (OoD) detection is vital for the reliability of Deep Neural Networks (DNNs). Existing works have shown the insufficiency of Principal Component Analysis (PCA) straightforwardly applied on the features of DNNs in detecting OoD data from In-Distribution (InD) data. The failure of PCA suggests that the network features residing in OoD and InD are not well separated by simply proceeding in a linear subspace, which instead can be resolved through proper nonlinear mappings. In this work, we leverage the framework of Kernel PCA (KPCA) for OoD detection, seeking subspaces where OoD and InD features are allocated with significantly different patterns. We devise two feature mappings that induce non-linear kernels in KPCA to advocate the separability between InD and OoD data in the subspace spanned by the principal components. Given any test sample, the reconstruction error in such subspace is then used to efficiently obtain the detection result with $\mathcal{O}(1)$ time complexity in inference. Extensive empirical results on multiple OoD data sets and network structures verify the superiority of our KPCA-based detector in efficiency and efficacy with state-of-the-art OoD detection performances.
Learn What You Need in Personalized Federated Learning
Jan 16, 2024



Personalized federated learning aims to address data heterogeneity across local clients in federated learning. However, current methods blindly incorporate either full model parameters or predefined partial parameters in personalized federated learning. They fail to customize the collaboration manner according to each local client's data characteristics, causing unpleasant aggregation results. To address this essential issue, we propose $\textit{Learn2pFed}$, a novel algorithm-unrolling-based personalized federated learning framework, enabling each client to adaptively select which part of its local model parameters should participate in collaborative training. The key novelty of the proposed $\textit{Learn2pFed}$ is to optimize each local model parameter's degree of participant in collaboration as learnable parameters via algorithm unrolling methods. This approach brings two benefits: 1) mathmatically determining the participation degree of local model parameters in the federated collaboration, and 2) obtaining more stable and improved solutions. Extensive experiments on various tasks, including regression, forecasting, and image classification, demonstrate that $\textit{Learn2pFed}$ significantly outperforms previous personalized federated learning methods.
Online Continual Learning via Logit Adjusted Softmax
Nov 11, 2023Online continual learning is a challenging problem where models must learn from a non-stationary data stream while avoiding catastrophic forgetting. Inter-class imbalance during training has been identified as a major cause of forgetting, leading to model prediction bias towards recently learned classes. In this paper, we theoretically analyze that inter-class imbalance is entirely attributed to imbalanced class-priors, and the function learned from intra-class intrinsic distributions is the Bayes-optimal classifier. To that end, we present that a simple adjustment of model logits during training can effectively resist prior class bias and pursue the corresponding Bayes-optimum. Our proposed method, Logit Adjusted Softmax, can mitigate the impact of inter-class imbalance not only in class-incremental but also in realistic general setups, with little additional computational cost. We evaluate our approach on various benchmarks and demonstrate significant performance improvements compared to prior arts. For example, our approach improves the best baseline by 4.6% on CIFAR10.
Self-similarity Prior Distillation for Unsupervised Remote Physiological Measurement
Nov 09, 2023Remote photoplethysmography (rPPG) is a noninvasive technique that aims to capture subtle variations in facial pixels caused by changes in blood volume resulting from cardiac activities. Most existing unsupervised methods for rPPG tasks focus on the contrastive learning between samples while neglecting the inherent self-similar prior in physiological signals. In this paper, we propose a Self-Similarity Prior Distillation (SSPD) framework for unsupervised rPPG estimation, which capitalizes on the intrinsic self-similarity of cardiac activities. Specifically, we first introduce a physical-prior embedded augmentation technique to mitigate the effect of various types of noise. Then, we tailor a self-similarity-aware network to extract more reliable self-similar physiological features. Finally, we develop a hierarchical self-distillation paradigm to assist the network in disentangling self-similar physiological patterns from facial videos. Comprehensive experiments demonstrate that the unsupervised SSPD framework achieves comparable or even superior performance compared to the state-of-the-art supervised methods. Meanwhile, SSPD maintains the lowest inference time and computation cost among end-to-end models. The source codes are available at https://github.com/LinXi1C/SSPD.
Low-Dimensional Gradient Helps Out-of-Distribution Detection
Oct 26, 2023



Detecting out-of-distribution (OOD) samples is essential for ensuring the reliability of deep neural networks (DNNs) in real-world scenarios. While previous research has predominantly investigated the disparity between in-distribution (ID) and OOD data through forward information analysis, the discrepancy in parameter gradients during the backward process of DNNs has received insufficient attention. Existing studies on gradient disparities mainly focus on the utilization of gradient norms, neglecting the wealth of information embedded in gradient directions. To bridge this gap, in this paper, we conduct a comprehensive investigation into leveraging the entirety of gradient information for OOD detection. The primary challenge arises from the high dimensionality of gradients due to the large number of network parameters. To solve this problem, we propose performing linear dimension reduction on the gradient using a designated subspace that comprises principal components. This innovative technique enables us to obtain a low-dimensional representation of the gradient with minimal information loss. Subsequently, by integrating the reduced gradient with various existing detection score functions, our approach demonstrates superior performance across a wide range of detection tasks. For instance, on the ImageNet benchmark, our method achieves an average reduction of 11.15% in the false positive rate at 95% recall (FPR95) compared to the current state-of-the-art approach. The code would be released.
Revisiting Deep Ensemble for Out-of-Distribution Detection: A Loss Landscape Perspective
Oct 22, 2023Existing Out-of-Distribution (OoD) detection methods address to detect OoD samples from In-Distribution data (InD) mainly by exploring differences in features, logits and gradients in Deep Neural Networks (DNNs). We in this work propose a new perspective upon loss landscape and mode ensemble to investigate OoD detection. In the optimization of DNNs, there exist many local optima in the parameter space, or namely modes. Interestingly, we observe that these independent modes, which all reach low-loss regions with InD data (training and test data), yet yield significantly different loss landscapes with OoD data. Such an observation provides a novel view to investigate the OoD detection from the loss landscape and further suggests significantly fluctuating OoD detection performance across these modes. For instance, FPR values of the RankFeat method can range from 46.58% to 84.70% among 5 modes, showing uncertain detection performance evaluations across independent modes. Motivated by such diversities on OoD loss landscape across modes, we revisit the deep ensemble method for OoD detection through mode ensemble, leading to improved performance and benefiting the OoD detector with reduced variances. Extensive experiments covering varied OoD detectors and network structures illustrate high variances across modes and also validate the superiority of mode ensemble in boosting OoD detection. We hope this work could attract attention in the view of independent modes in the OoD loss landscape and more reliable evaluations on OoD detectors.
Enhancing Kernel Flexibility via Learning Asymmetric Locally-Adaptive Kernels
Oct 08, 2023
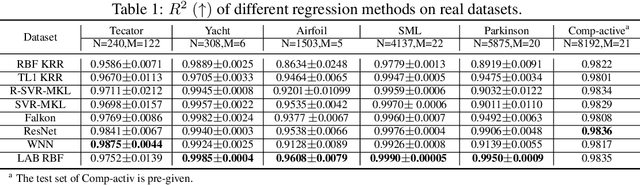

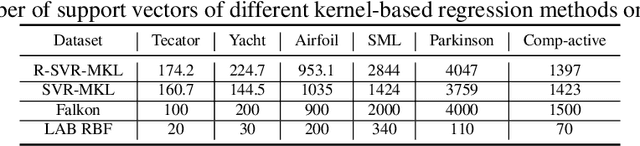
The lack of sufficient flexibility is the key bottleneck of kernel-based learning that relies on manually designed, pre-given, and non-trainable kernels. To enhance kernel flexibility, this paper introduces the concept of Locally-Adaptive-Bandwidths (LAB) as trainable parameters to enhance the Radial Basis Function (RBF) kernel, giving rise to the LAB RBF kernel. The parameters in LAB RBF kernels are data-dependent, and its number can increase with the dataset, allowing for better adaptation to diverse data patterns and enhancing the flexibility of the learned function. This newfound flexibility also brings challenges, particularly with regards to asymmetry and the need for an efficient learning algorithm. To address these challenges, this paper for the first time establishes an asymmetric kernel ridge regression framework and introduces an iterative kernel learning algorithm. This novel approach not only reduces the demand for extensive support data but also significantly improves generalization by training bandwidths on the available training data. Experimental results on real datasets underscore the remarkable performance of the proposed algorithm, showcasing its superior capability in handling large-scale datasets compared to Nystr\"om approximation-based algorithms. Moreover, it demonstrates a significant improvement in regression accuracy over existing kernel-based learning methods and even surpasses residual neural networks.