 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbracing Uncertainty: Adaptive Vague Preference Policy Learning for Multi-round Conversational Recommendation
Jun 07, 2023



Conversational recommendation systems (CRS) effectively address information asymmetry by dynamically eliciting user preferences through multi-turn interactions. Existing CRS widely assumes that users have clear preferences. Under this assumption, the agent will completely trust the user feedback and treat the accepted or rejected signals as strong indicators to filter items and reduce the candidate space, which may lead to the problem of over-filtering. However, in reality, users' preferences are often vague and volatile, with uncertainty about their desires and changing decisions during interactions. To address this issue, we introduce a novel scenario called Vague Preference Multi-round Conversational Recommendation (VPMCR), which considers users' vague and volatile preferences in CRS.VPMCR employs a soft estimation mechanism to assign a non-zero confidence score for all candidate items to be displayed, naturally avoiding the over-filtering problem. In the VPMCR setting, we introduce an solution called Adaptive Vague Preference Policy Learning (AVPPL), which consists of two main components: Uncertainty-aware Soft Estimation (USE) and Uncertainty-aware Policy Learning (UPL). USE estimates the uncertainty of users' vague feedback and captures their dynamic preferences using a choice-based preferences extraction module and a time-aware decaying strategy. UPL leverages the preference distribution estimated by USE to guide the conversation and adapt to changes in users' preferences to make recommendations or ask for attributes. Our extensive experiments demonstrate the effectiveness of our method in the VPMCR scenario, highlighting its potential for practical applications and improving the overall performance and applicability of CRS in real-world settings, particularly for users with vague or dynamic preferences.
Automated Code generation for Information Technology Tasks in YAML through Large Language Models
May 05, 2023



The recent improvement in code generation capabilities due to the use of large language models has mainly benefited general purpose programming languages. Domain specific languages, such as the ones used for IT Automation, have received far less attention, despite involving many active developers and being an essential component of modern cloud platforms. This work focuses on the generation of Ansible-YAML, a widely used markup language for IT Automation. We present Ansible Wisdom, a natural-language to Ansible-YAML code generation tool, aimed at improving IT automation productivity. Ansible Wisdom is a transformer-based model, extended by training with a new dataset containing Ansible-YAML. We also develop two novel performance metrics for YAML and Ansible to capture the specific characteristics of this domain. Results show that Ansible Wisdom can accurately generate Ansible script from natural language prompts with performance comparable or better than existing state of the art code generation models.
Adaptive Texture Filtering for Single-Domain Generalized Segmentation
Mar 06, 2023



Domain generalization in semantic segmentation aims to alleviate the performance degradation on unseen domains through learning domain-invariant features. Existing methods diversify images in the source domain by adding complex or even abnormal textures to reduce the sensitivity to domain specific features. However, these approaches depend heavily on the richness of the texture bank, and training them can be time-consuming. In contrast to importing textures arbitrarily or augmenting styles randomly, we focus on the single source domain itself to achieve generalization. In this paper, we present a novel adaptive texture filtering mechanism to suppress the influence of texture without using augmentation, thus eliminating the interference of domain-specific features. Further, we design a hierarchical guidance generalization network equipped with structure-guided enhancement modules, which purpose is to learn the domain-invariant generalized knowledge. Extensive experiments together with ablation studies on widely-used datasets are conducted to verify the effectiveness of the proposed model, and reveal its superiority over other state-of-the-art alternatives.
Face Inverse Rendering via Hierarchical Decoupling
Jan 17, 2023



Previous face inverse rendering methods often require synthetic data with ground truth and/or professional equipment like a lighting stage. However, a model trained on synthetic data or using pre-defined lighting priors is typically unable to generalize well for real-world situations, due to the gap between synthetic data/lighting priors and real data. Furthermore, for common users, the professional equipment and skill make the task expensive and complex. In this paper, we propose a deep learning framework to disentangle face images in the wild into their corresponding albedo, normal, and lighting components. Specifically, a decomposition network is built with a hierarchical subdivision strategy, which takes image pairs captured from arbitrary viewpoints as input. In this way, our approach can greatly mitigate the pressure from data preparation, and significantly broaden the applicability of face inverse rendering. Extensive experiments are conducted to demonstrate the efficacy of our design, and show its superior performance in face relighting over other state-of-the-art alternatives. {Our code is available at \url{https://github.com/AutoHDR/HD-Net.git}}
Theoretical Characterization of How Neural Network Pruning Affects its Generalization
Jan 05, 2023



It has been observed in practice that applying pruning-at-initialization methods to neural networks and training the sparsified networks can not only retain the testing performance of the original dense models, but also sometimes even slightly boost the generalization performance. Theoretical understanding for such experimental observations are yet to be developed. This work makes the first attempt to study how different pruning fractions affect the model's gradient descent dynamics and generalization. Specifically, this work considers a classification task for overparameterized two-layer neural networks, where the network is randomly pruned according to different rates at the initialization. It is shown that as long as the pruning fraction is below a certain threshold, gradient descent can drive the training loss toward zero and the network exhibits good generalization performance. More surprisingly, the generalization bound gets better as the pruning fraction gets larger. To complement this positive result, this work further shows a negative result: there exists a large pruning fraction such that while gradient descent is still able to drive the training loss toward zero (by memorizing noise), the generalization performance is no better than random guessing. This further suggests that pruning can change the feature learning process, which leads to the performance drop of the pruned neural network.
Multi-objective Deep Data Generation with Correlated Property Control
Oct 06, 2022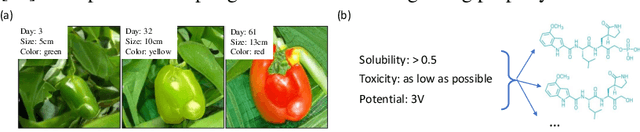
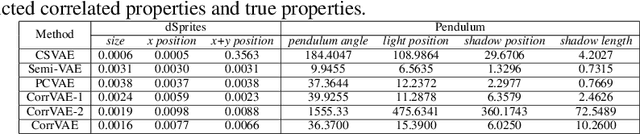
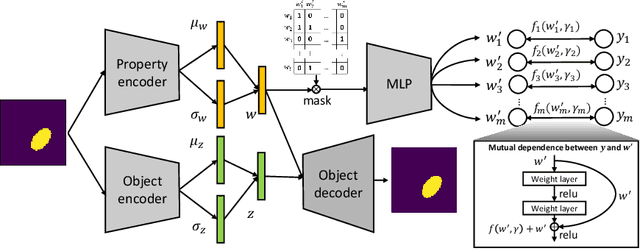
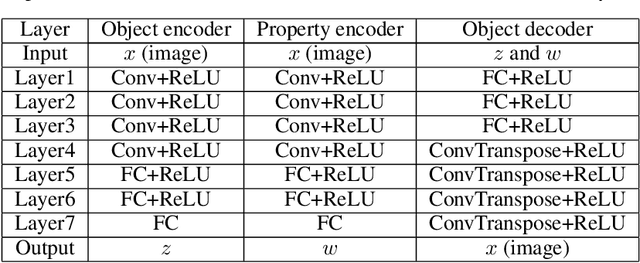
Developing deep generative models has been an emerging field due to the ability to model and generate complex data for various purposes, such as image synthesis and molecular design. However, the advancement of deep generative models is limited by challenges to generate objects that possess multiple desired properties: 1) the existence of complex correlation among real-world properties is common but hard to identify; 2) controlling individual property enforces an implicit partially control of its correlated properties, which is difficult to model; 3) controlling multiple properties under various manners simultaneously is hard and under-explored. We address these challenges by proposing a novel deep generative framework that recovers semantics and the correlation of properties through disentangled latent vectors. The correlation is handled via an explainable mask pooling layer, and properties are precisely retained by generated objects via the mutual dependence between latent vectors and properties. Our generative model preserves properties of interest while handling correlation and conflicts of properties under a multi-objective optimization framework. The experiments demonstrate our model's superior performance in generating data with desired properties.
Adaptive Perception Transformer for Temporal Action Localization
Aug 25, 2022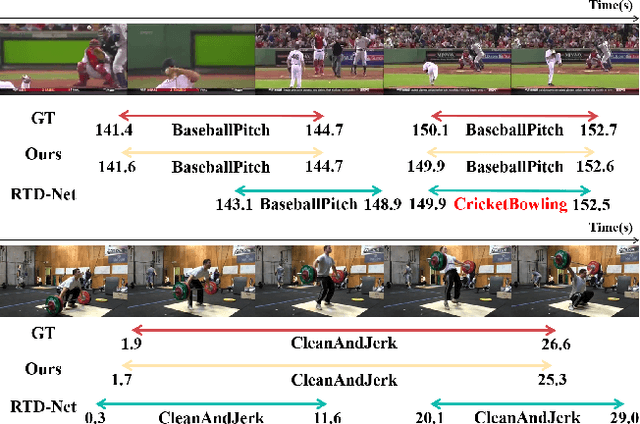
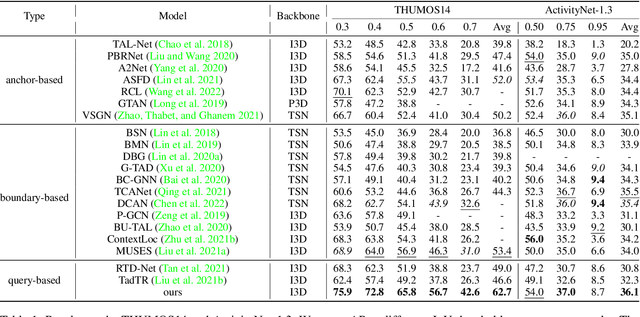
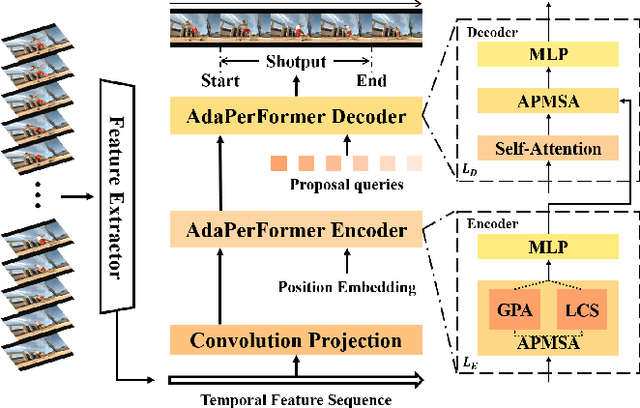
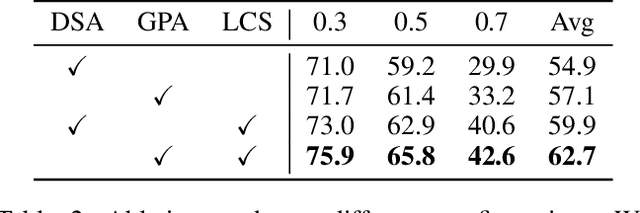
Temporal action localization aims to predict the boundary and category of each action instance in untrimmed long videos. Most of previous methods based on anchors or proposals neglect the global-local context interaction in entire video sequences. Besides, their multi-stage designs cannot generate action boundaries and categories straightforwardly. To address the above issues, this paper proposes a novel end-to-end model, called adaptive perception transformer (AdaPerFormer for short). Specifically, AdaPerFormer explores a dual-branch multi-head self-attention mechanism. One branch takes care of the global perception attention, which can model entire video sequences and aggregate global relevant contexts. While the other branch concentrates on the local convolutional shift to aggregate intra-frame and inter-frame information through our bidirectional shift operation. The end-to-end nature produces the boundaries and categories of video actions without extra steps. Extensive experiments together with ablation studies are provided to reveal the effectiveness of our design. Our method achieves a state-of-the-art accuracy on the THUMOS14 dataset (65.8\% in terms of mAP@0.5, 42.6\% mAP@0.7, and 62.7\% mAP@Avg), and obtains competitive performance on the ActivityNet-1.3 dataset with an average mAP of 36.1\%. The code and models are available at https://github.com/SouperO/AdaPerFormer.
YOLOV: Making Still Image Object Detectors Great at Video Object Detection
Aug 20, 2022
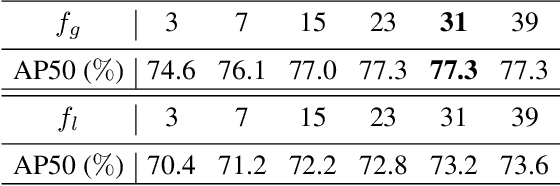
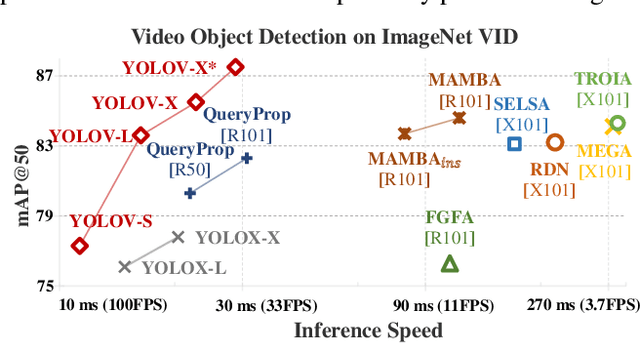

Video object detection (VID) is challenging because of the high variation of object appearance as well as the diverse deterioration in some frames. On the positive side, the detection in a certain frame of a video, compared with in a still image, can draw support from other frames. Hence, how to aggregate features across different frames is pivotal to the VID problem. Most of existing aggregation algorithms are customized for two-stage detectors. But, the detectors in this category are usually computationally expensive due to the two-stage nature. This work proposes a simple yet effective strategy to address the above concerns, which spends marginal overheads with significant gains in accuracy. Concretely, different from the traditional two-stage pipeline, we advocate putting the region-level selection after the one-stage detection to avoid processing massive low-quality candidates. Besides, a novel module is constructed to evaluate the relationship between a target frame and its reference ones, and guide the aggregation. Extensive experiments and ablation studies are conducted to verify the efficacy of our design, and reveal its superiority over other state-of-the-art VID approaches in both effectiveness and efficiency. Our YOLOX-based model can achieve promising performance (e.g., 87.5\% AP50 at over 30 FPS on the ImageNet VID dataset on a single 2080Ti GPU), making it attractive for large-scale or real-time applications. The implementation is simple, the demo code and models have been made available at https://github.com/YuHengsss/YOLOV .
Controllable Data Generation by Deep Learning: A Review
Jul 25, 2022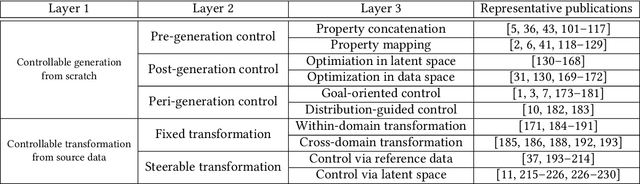
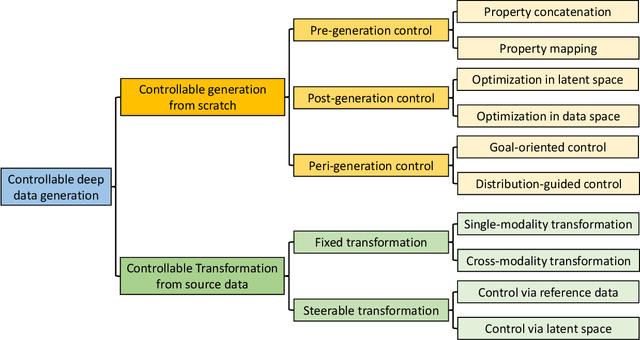
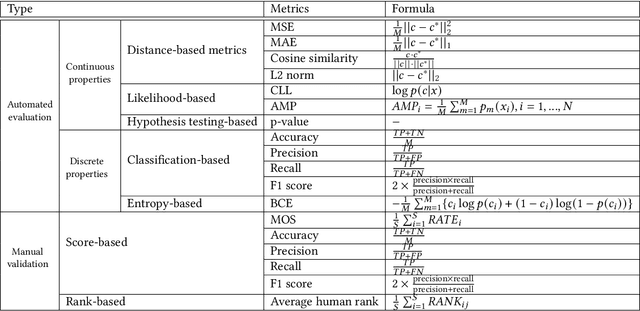
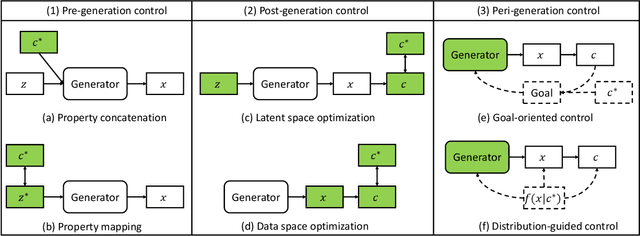
Designing and generating new data under targeted properties has been attracting various critical applications such as molecule design, image editing and speech synthesis. Traditional hand-crafted approaches heavily rely on expertise experience and intensive human efforts, yet still suffer from the insufficiency of scientific knowledge and low throughput to support effective and efficient data generation. Recently, the advancement of deep learning induces expressive methods that can learn the underlying representation and properties of data. Such capability provides new opportunities in figuring out the mutual relationship between the structural patterns and functional properties of the data and leveraging such relationship to generate structural data given the desired properties. This article provides a systematic review of this promising research area, commonly known as controllable deep data generation. Firstly, the potential challenges are raised and preliminaries are provided. Then the controllable deep data generation is formally defined, a taxonomy on various techniques is proposed and the evaluation metrics in this specific domain are summarized. After that, exciting applications of controllable deep data generation are introduced and existing works are experimentally analyzed and compared. Finally, the promising future directions of controllable deep data generation are highlighted and five potential challenges are identified.
Vision-based Uneven BEV Representation Learning with Polar Rasterization and Surface Estimation
Jul 05, 2022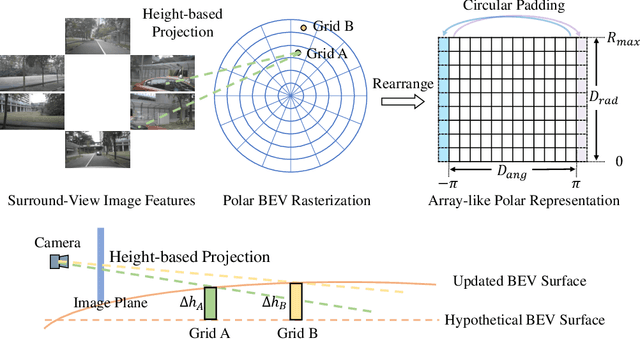
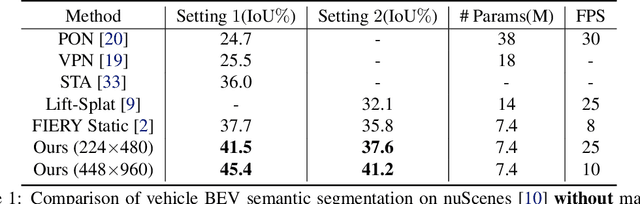
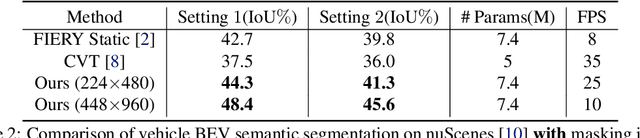

In this work, we propose PolarBEV for vision-based uneven BEV representation learning. To adapt to the foreshortening effect of camera imaging, we rasterize the BEV space both angularly and radially, and introduce polar embedding decomposition to model the associations among polar grids. Polar grids are rearranged to an array-like regular representation for efficient processing. Besides, to determine the 2D-to-3D correspondence, we iteratively update the BEV surface based on a hypothetical plane, and adopt height-based feature transformation. PolarBEV keeps real-time inference speed on a single 2080Ti GPU, and outperforms other methods for both BEV semantic segmentation and BEV instance segmentation. Thorough ablations are presented to validate the design. The code will be released at \url{https://github.com/SuperZ-Liu/PolarBEV}.