 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaFIn: Generative Landmark Guided Face Inpainting
Paper and Code

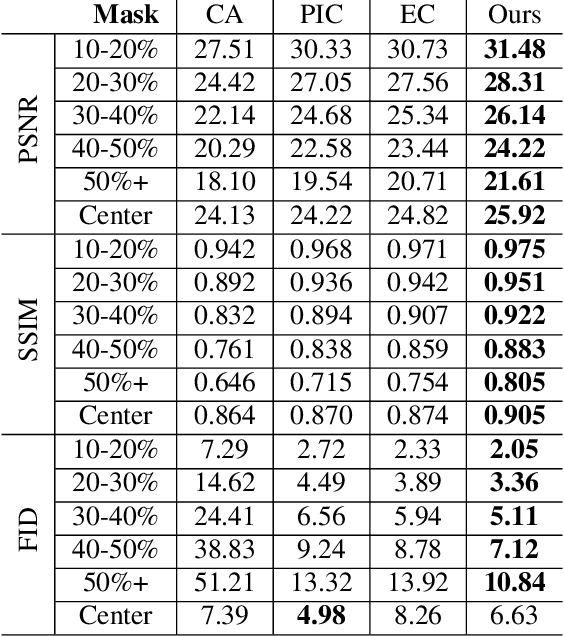
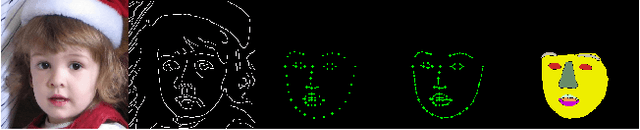
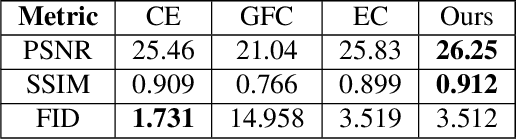
It is challenging to inpaint face images in the wild, due to the large variation of appearance, such as different poses, expressions and occlusions. A good inpainting algorithm should guarantee the realism of output, including the topological structure among eyes, nose and mouth, as well as the attribute consistency on pose, gender, ethnicity, expression, etc. This paper studies an effective deep learning based strategy to deal with these issues, which comprises of a facial landmark predicting subnet and an image inpainting subnet. Concretely, given partial observation, the landmark predictor aims to provide the structural information (e.g. topological relationship and expression) of incomplete faces, while the inpaintor is to generate plausible appearance (e.g. gender and ethnicity) conditioned on the predicted landmarks. Experiments on the CelebA-HQ and CelebA datasets are conducted to reveal the efficacy of our design and, to demonstrate its superiority over state-of-the-art alternatives both qualitatively and quantitatively. In addition, we assume that high-quality completed faces together with their landmarks can be utilized as augmented data to further improve the performance of (any) landmark predictor, which is corroborated by experimental results on the 300W and WFLW datasets.