 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAU-Aware Vision Transformers for Biased Facial Expression Recognition
Nov 12, 2022



Studies have proven that domain bias and label bias exist in different Facial Expression Recognition (FER) datasets, making it hard to improve the performance of a specific dataset by adding other datasets. For the FER bias issue, recent researches mainly focus on the cross-domain issue with advanced domain adaption algorithms. This paper addresses another problem: how to boost FER performance by leveraging cross-domain datasets. Unlike the coarse and biased expression label, the facial Action Unit (AU) is fine-grained and objective suggested by psychological studies. Motivated by this, we resort to the AU information of different FER datasets for performance boosting and make contributions as follows. First, we experimentally show that the naive joint training of multiple FER datasets is harmful to the FER performance of individual datasets. We further introduce expression-specific mean images and AU cosine distances to measure FER dataset bias. This novel measurement shows consistent conclusions with experimental degradation of joint training. Second, we propose a simple yet conceptually-new framework, AU-aware Vision Transformer (AU-ViT). It improves the performance of individual datasets by jointly training auxiliary datasets with AU or pseudo-AU labels. We also find that the AU-ViT is robust to real-world occlusions. Moreover, for the first time, we prove that a carefully-initialized ViT achieves comparable performance to advanced deep convolutional networks. Our AU-ViT achieves state-of-the-art performance on three popular datasets, namely 91.10% on RAF-DB, 65.59% on AffectNet, and 90.15% on FERPlus. The code and models will be released soon.
AU-Supervised Convolutional Vision Transformers for Synthetic Facial Expression Recognition
Jul 22, 2022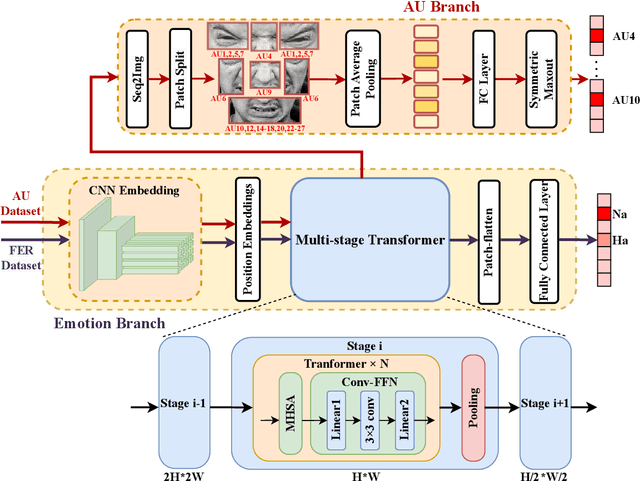
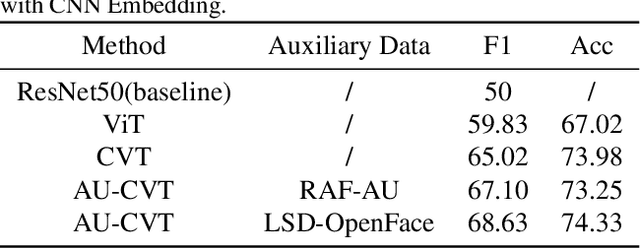
The paper describes our proposed methodology for the six basic expression classification track of Affective Behavior Analysis in-the-wild (ABAW) Competition 2022. In Learing from Synthetic Data(LSD) task, facial expression recognition (FER) methods aim to learn the representation of expression from the artificially generated data and generalise to real data. Because of the ambiguous of the synthetic data and the objectivity of the facial Action Unit (AU), we resort to the AU information for performance boosting, and make contributions as follows. First, to adapt the model to synthetic scenarios, we use the knowledge from pre-trained large-scale face recognition data. Second, we propose a conceptually-new framework, termed as AU-Supervised Convolutional Vision Transformers (AU-CVT), which clearly improves the performance of FER by jointly training auxiliary datasets with AU or pseudo AU labels. Our AU-CVT achieved F1 score as $0.6863$, accuracy as $0.7433$ on the validation set. The source code of our work is publicly available online: https://github.com/msy1412/ABAW4
Video-based Smoky Vehicle Detection with A Coarse-to-Fine Framework
Jul 08, 2022
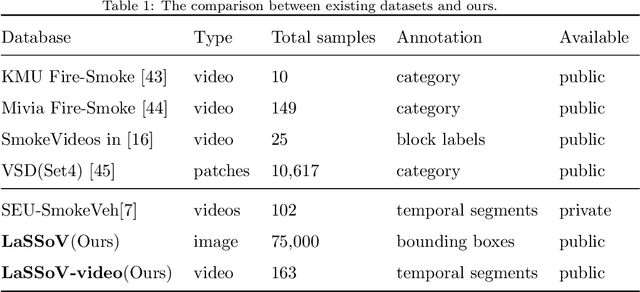

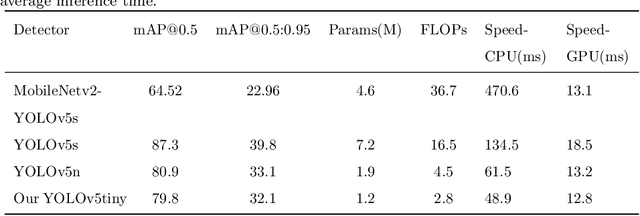
Automatic smoky vehicle detection in videos is a superior solution to the traditional expensive remote sensing one with ultraviolet-infrared light devices for environmental protection agencies. However, it is challenging to distinguish vehicle smoke from shadow and wet regions coming from rear vehicle or clutter roads, and could be worse due to limited annotated data. In this paper, we first introduce a real-world large-scale smoky vehicle dataset with 75,000 annotated smoky vehicle images, facilitating the effective training of advanced deep learning models. To enable fair algorithm comparison, we also build a smoky vehicle video dataset including 163 long videos with segment-level annotations. Moreover, we present a new Coarse-to-fine Deep Smoky vehicle detection (CoDeS) framework for efficient smoky vehicle detection. The CoDeS first leverages a light-weight YOLO detector for fast smoke detection with high recall rate, and then applies a smoke-vehicle matching strategy to eliminate non-vehicle smoke, and finally uses a elaborately-designed 3D model to further refine the results in spatial temporal space. Extensive experiments in four metrics demonstrate that our framework is significantly superior to those hand-crafted feature based methods and recent advanced methods. The code and dataset will be released at https://github.com/pengxj/smokyvehicle.
Video Frame Interpolation Based on Deformable Kernel Region
Apr 25, 2022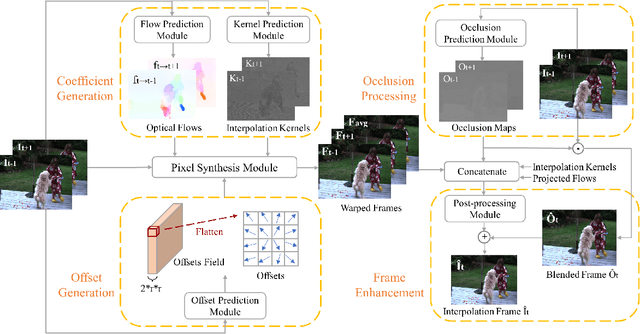
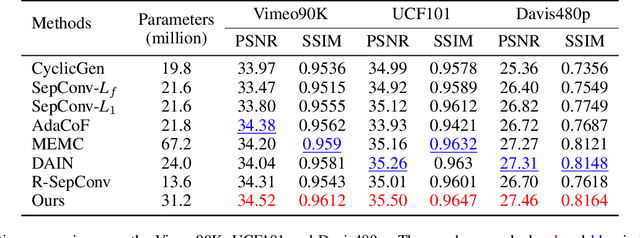
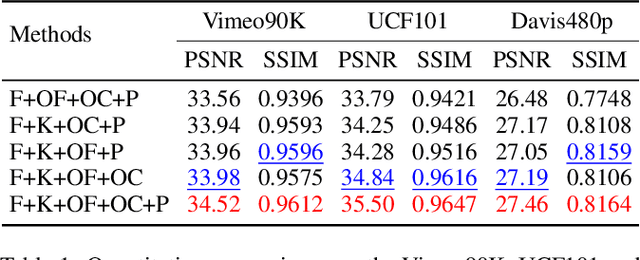

Video frame interpolation task has recently become more and more prevalent in the computer vision field. At present, a number of researches based on deep learning have achieved great success. Most of them are either based on optical flow information, or interpolation kernel, or a combination of these two methods. However, these methods have ignored that there are grid restrictions on the position of kernel region during synthesizing each target pixel. These limitations result in that they cannot well adapt to the irregularity of object shape and uncertainty of motion, which may lead to irrelevant reference pixels used for interpolation. In order to solve this problem, we revisit the deformable convolution for video interpolation, which can break the fixed grid restrictions on the kernel region, making the distribution of reference points more suitable for the shape of the object, and thus warp a more accurate interpolation frame. Experiments are conducted on four datasets to demonstrate the superior performance of the proposed model in comparison to the state-of-the-art alternatives.
Stereo Matching with Cost Volume based Sparse Disparity Propagation
Jan 28, 2022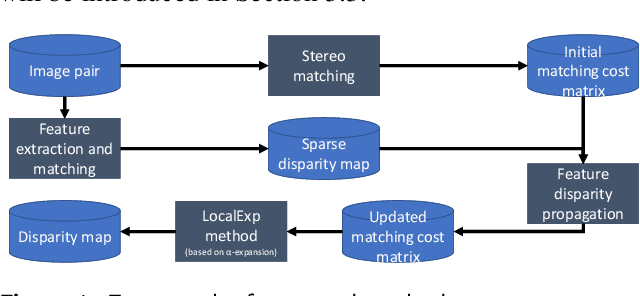

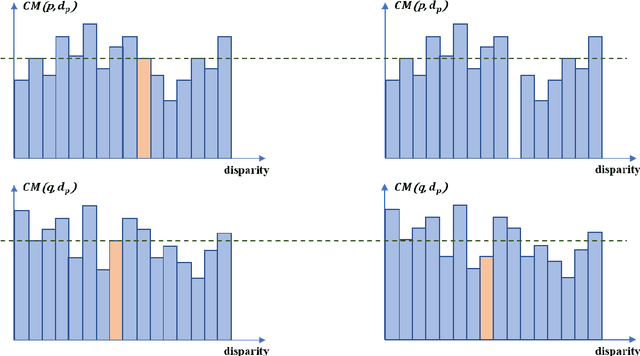
Stereo matching is crucial for binocular stereo vision. Existing methods mainly focus on simple disparity map fusion to improve stereo matching, which require multiple dense or sparse disparity maps. In this paper, we propose a simple yet novel scheme, termed feature disparity propagation, to improve general stereo matching based on matching cost volume and sparse matching feature points. Specifically, our scheme first calculates a reliable sparse disparity map by local feature matching, and then refines the disparity map by propagating reliable disparities to neighboring pixels in the matching cost domain. In addition, considering the gradient and multi-scale information of local disparity regions, we present a $\rho$-Census cost measure based on the well-known AD-Census, which guarantees the robustness of cost volume even without the cost aggregation step. Extensive experiments on Middlebury stereo benchmark V3 demonstrate that our scheme achieves promising performance comparable to state-of-the-art methods.
Self-Ensemling for 3D Point Cloud Domain Adaption
Dec 10, 2021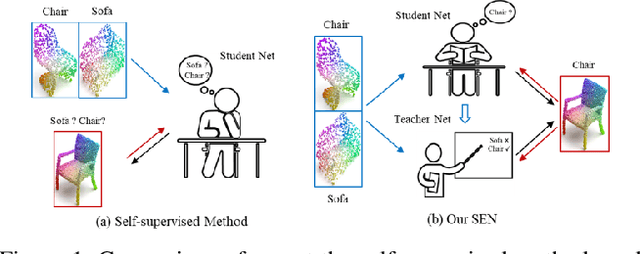
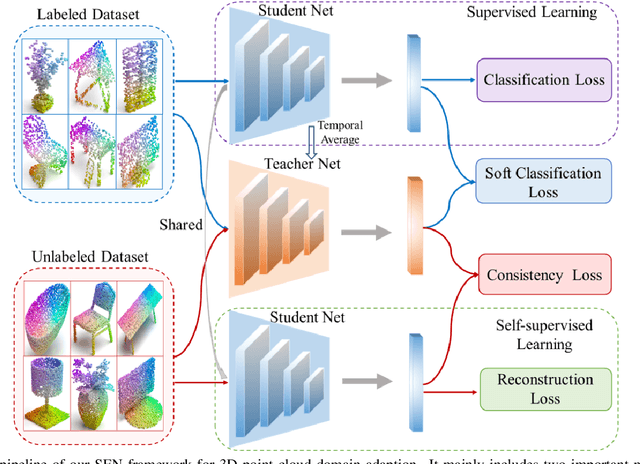

Recently 3D point cloud learning has been a hot topic in computer vision and autonomous driving. Due to the fact that it is difficult to manually annotate a qualitative large-scale 3D point cloud dataset, unsupervised domain adaptation (UDA) is popular in 3D point cloud learning which aims to transfer the learned knowledge from the labeled source domain to the unlabeled target domain. However, the generalization and reconstruction errors caused by domain shift with simply-learned model are inevitable which substantially hinder the model's capability from learning good representations. To address these issues, we propose an end-to-end self-ensembling network (SEN) for 3D point cloud domain adaption tasks. Generally, our SEN resorts to the advantages of Mean Teacher and semi-supervised learning, and introduces a soft classification loss and a consistency loss, aiming to achieve consistent generalization and accurate reconstruction. In SEN, a student network is kept in a collaborative manner with supervised learning and self-supervised learning, and a teacher network conducts temporal consistency to learn useful representations and ensure the quality of point clouds reconstruction. Extensive experiments on several 3D point cloud UDA benchmarks show that our SEN outperforms the state-of-the-art methods on both classification and segmentation tasks. Moreover, further analysis demonstrates that our SEN also achieves better reconstruction results.
Spatial and Temporal Networks for Facial Expression Recognition in the Wild Videos
Jul 12, 2021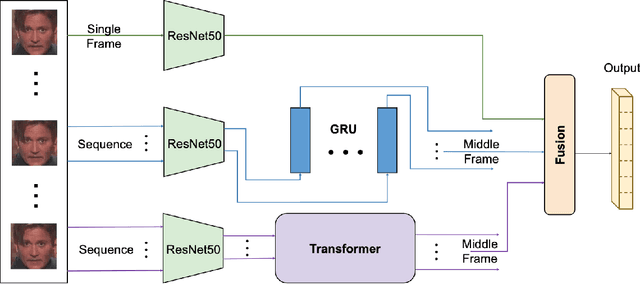
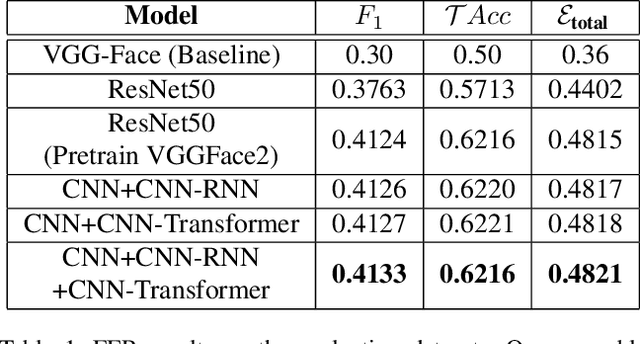
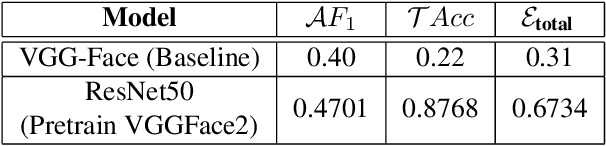
The paper describes our proposed methodology for the seven basic expression classification track of Affective Behavior Analysis in-the-wild (ABAW) Competition 2021. In this task, facial expression recognition (FER) methods aim to classify the correct expression category from a diverse background, but there are several challenges. First, to adapt the model to in-the-wild scenarios, we use the knowledge from pre-trained large-scale face recognition data. Second, we propose an ensemble model with a convolution neural network (CNN), a CNN-recurrent neural network (CNN-RNN), and a CNN-Transformer (CNN-Transformer), to incorporate both spatial and temporal information. Our ensemble model achieved F1 as 0.4133, accuracy as 0.6216 and final metric as 0.4821 on the validation set.
An Efficient Training Approach for Very Large Scale Face Recognition
Jun 04, 2021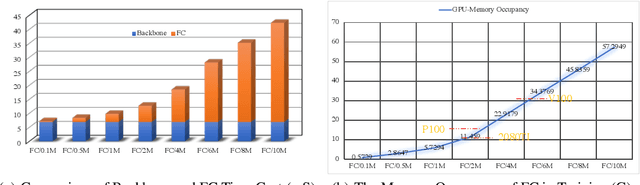
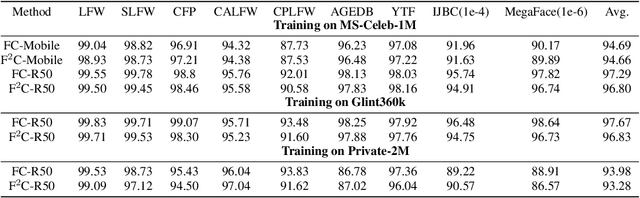
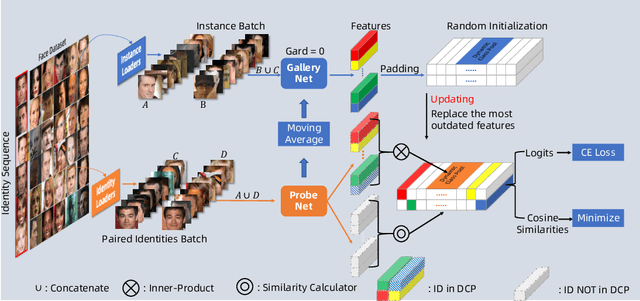
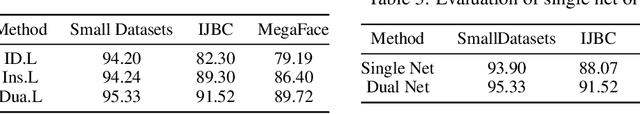
Face recognition has achieved significant progress in deep-learning era due to the ultra-large-scale and well-labeled datasets. However, training on ultra-large-scale datasets is time-consuming and takes up a lot of hardware resource. Therefore, designing an efficient training approach is crucial and indispensable. The heavy computational and memory costs mainly result from the high dimensionality of the Fully-Connected (FC) layer. Specifically, the dimensionality is determined by the number of face identities, which can be million-level or even more. To this end, we propose a novel training approach for ultra-large-scale face datasets, termed Faster Face Classification (F$^2$C). In F$^2$C, we first define a Gallery Net and a Probe Net that are used to generate identities' centers and extract faces' features for face recognition, respectively. Gallery Net has the same structure as Probe Net and inherits the parameters from Probe Net with a moving average paradigm. After that, to reduce the training time and hardware costs of the FC layer, we propose a Dynamic Class Pool (DCP) that stores the features from Gallery Net and calculates the inner product (logits) with positive samples (whose identities are in the DCP) in each mini-batch. DCP can be regarded as a substitute for the FC layer but it is far smaller, thus greatly reducing the computational and memory costs. For negative samples (whose identities are not in DCP), we minimize the cosine similarities between negative samples and those in DCP. Then, to improve the update efficiency of DCP's parameters, we design a dual data-loader including identity-based and instance-based loaders to generate a certain of identities and samples in mini-batches.
Affordance Transfer Learning for Human-Object Interaction Detection
Apr 07, 2021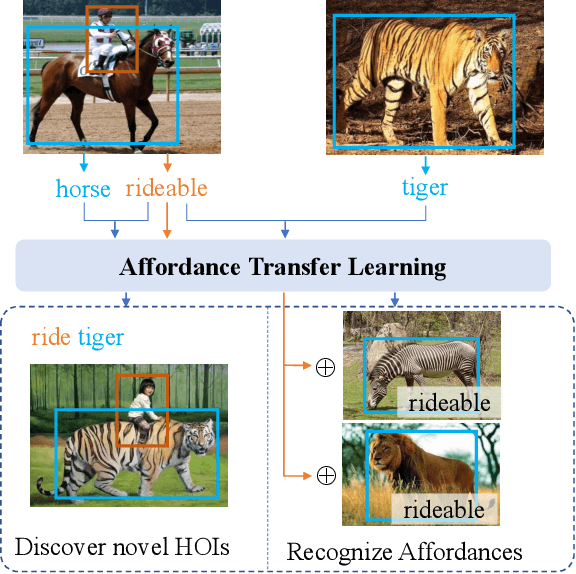
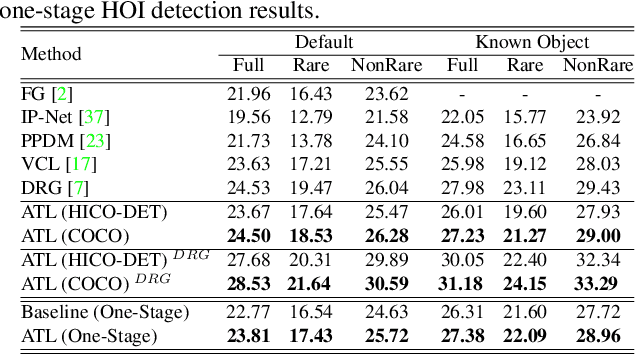
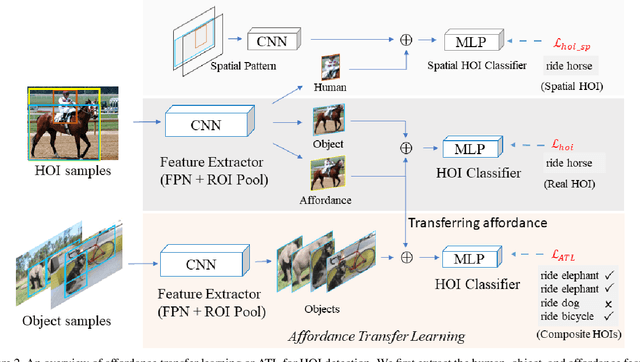
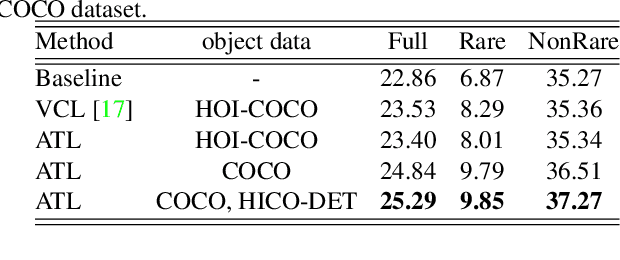
Reasoning the human-object interactions (HOI) is essential for deeper scene understanding, while object affordances (or functionalities) are of great importance for human to discover unseen HOIs with novel objects. Inspired by this, we introduce an affordance transfer learning approach to jointly detect HOIs with novel objects and recognize affordances. Specifically, HOI representations can be decoupled into a combination of affordance and object representations, making it possible to compose novel interactions by combining affordance representations and novel object representations from additional images, i.e. transferring the affordance to novel objects. With the proposed affordance transfer learning, the model is also capable of inferring the affordances of novel objects from known affordance representations. The proposed method can thus be used to 1) improve the performance of HOI detection, especially for the HOIs with unseen objects; and 2) infer the affordances of novel objects. Experimental results on two datasets, HICO-DET and HOI-COCO (from V-COCO), demonstrate significant improvements over recent state-of-the-art methods for HOI detection and object affordance detection. Code is available at https://github.com/zhihou7/HOI-CL
Detecting Human-Object Interaction via Fabricated Compositional Learning
Mar 25, 2021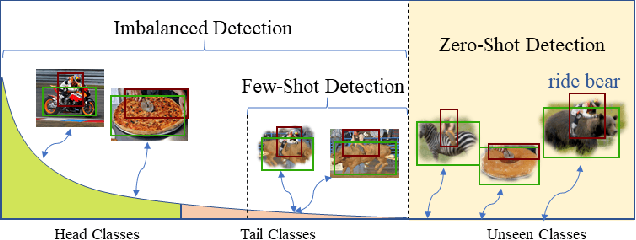
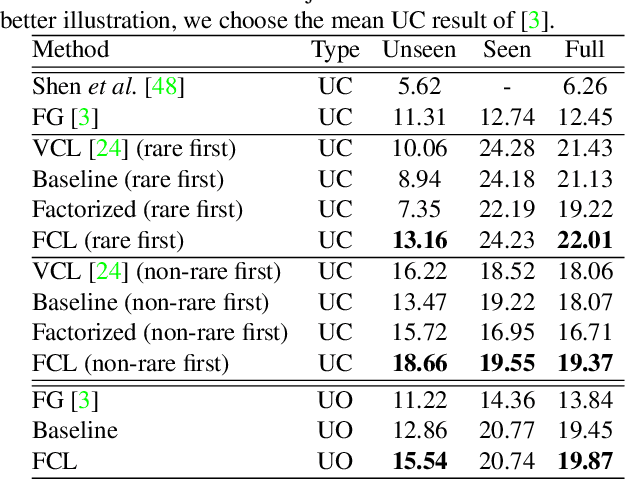
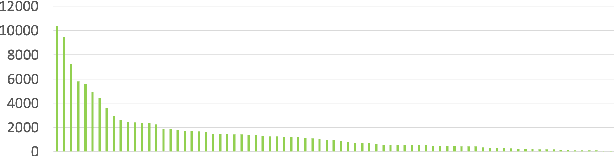
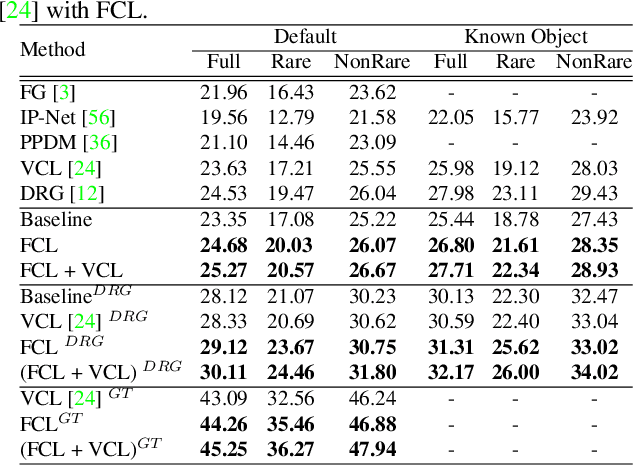
Human-Object Interaction (HOI) detection, inferring the relationships between human and objects from images/videos, is a fundamental task for high-level scene understanding. However, HOI detection usually suffers from the open long-tailed nature of interactions with objects, while human has extremely powerful compositional perception ability to cognize rare or unseen HOI samples. Inspired by this, we devise a novel HOI compositional learning framework, termed as Fabricated Compositional Learning (FCL), to address the problem of open long-tailed HOI detection. Specifically, we introduce an object fabricator to generate effective object representations, and then combine verbs and fabricated objects to compose new HOI samples. With the proposed object fabricator, we are able to generate large-scale HOI samples for rare and unseen categories to alleviate the open long-tailed issues in HOI detection. Extensive experiments on the most popular HOI detection dataset, HICO-DET, demonstrate the effectiveness of the proposed method for imbalanced HOI detection and significantly improve the state-of-the-art performance on rare and unseen HOI categories. Code is available at https://github.com/zhihou7/HOI-CL.