 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTagged-MRI Sequence to Audio Synthesis via Self Residual Attention Guided Heterogeneous Translator
Jun 09, 2022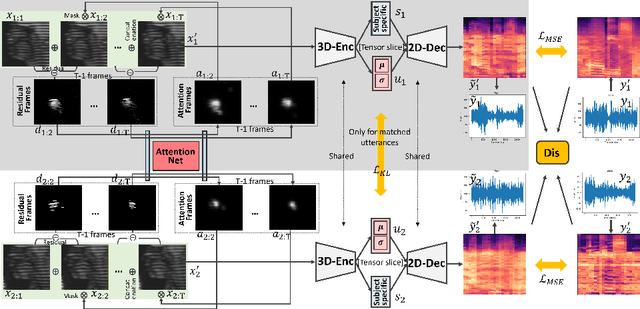
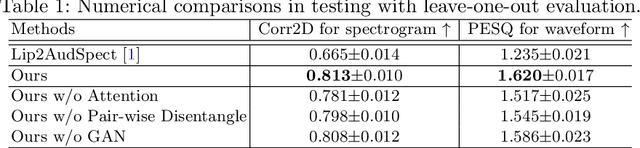
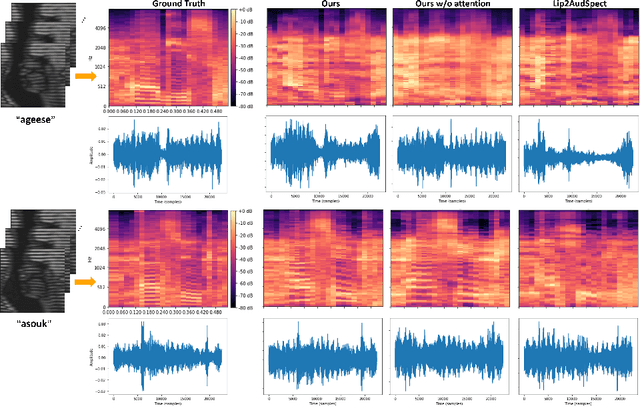
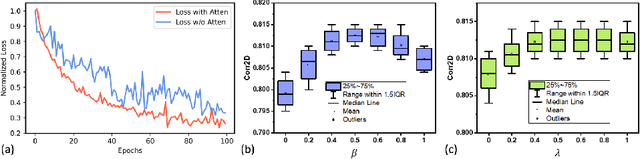
Understanding the underlying relationship between tongue and oropharyngeal muscle deformation seen in tagged-MRI and intelligible speech plays an important role in advancing speech motor control theories and treatment of speech related-disorders. Because of their heterogeneous representations, however, direct mapping between the two modalities -- i.e., two-dimensional (mid-sagittal slice) plus time tagged-MRI sequence and its corresponding one-dimensional waveform -- is not straightforward. Instead, we resort to two-dimensional spectrograms as an intermediate representation, which contains both pitch and resonance, from which to develop an end-to-end deep learning framework to translate from a sequence of tagged-MRI to its corresponding audio waveform with limited dataset size.~Our framework is based on a novel fully convolutional asymmetry translator with guidance of a self residual attention strategy to specifically exploit the moving muscular structures during speech.~In addition, we leverage a pairwise correlation of the samples with the same utterances with a latent space representation disentanglement strategy.~Furthermore, we incorporate an adversarial training approach with generative adversarial networks to offer improved realism on our generated spectrograms.~Our experimental results, carried out with a total of 63 tagged-MRI sequences alongside speech acoustics, showed that our framework enabled the generation of clear audio waveforms from a sequence of tagged-MRI, surpassing competing methods. Thus, our framework provides the great potential to help better understand the relationship between the two modalities.
Sparse Federated Learning with Hierarchical Personalization Models
Mar 25, 2022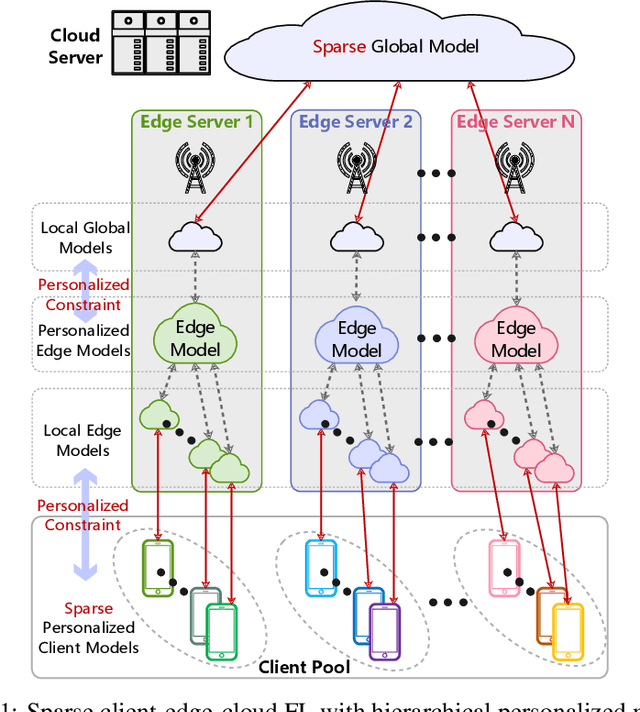
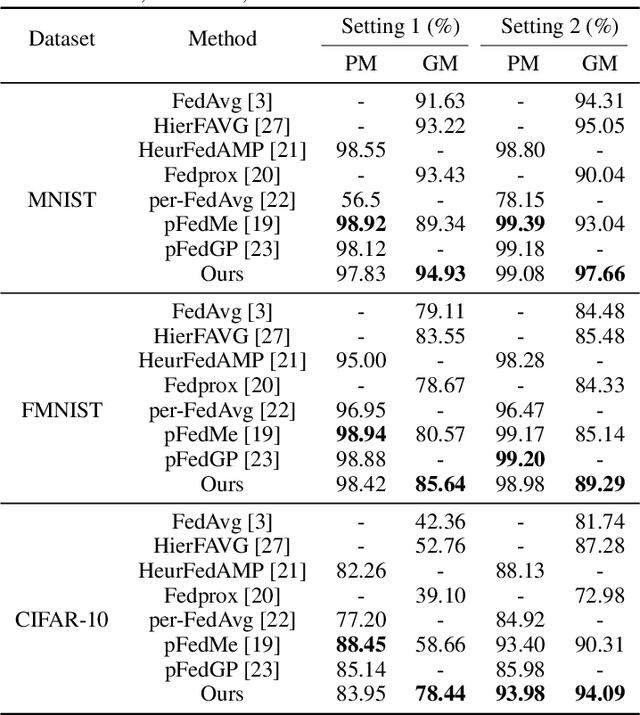
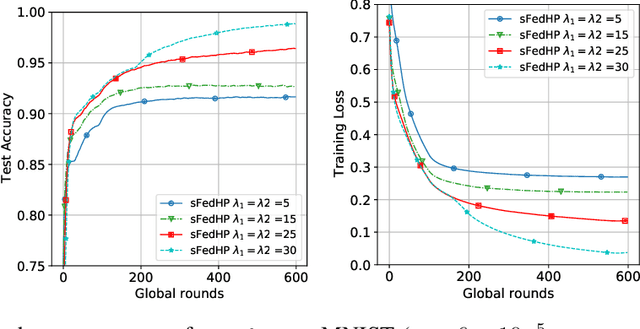
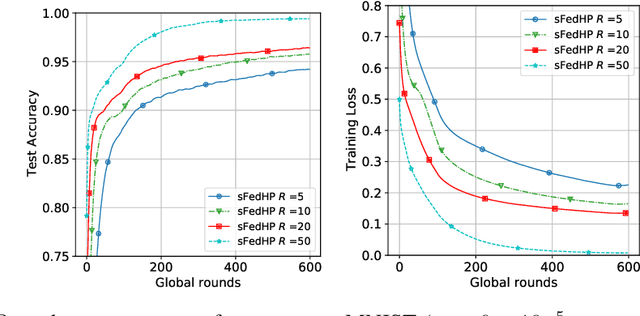
Federated learning (FL) is widely used in the Internet of Things (IoT), wireless networks, mobile devices, autonomous vehicles, and human activity due to its excellent potential in cybersecurity and privacy security. Though FL method can achieve privacy-safe and reliable collaborative training without collecting users' privacy data, it suffers from many challenges during both training and deployment. The main challenges in FL are the difficulty of non-i.i.d co-training data caused by the statistical diversity of the data from various participants, and the difficulty of application deployment caused by the excessive traffic volume and long communication delay between the central server and the client. To address these problems, we propose a sparse FL scheme with hierarchical personalization models (sFedHP), which minimizes clients' loss functions including the properties of an approximated L1-norm and the hierarchical proximal mapping, to reduce the communicational and computational loads required in the network, while improving the performance on statistical diversity data. Convergence analysis shows that the sparse constraint in sFedHP only reduces the convergence speed to a small extent, while the communication cost is greatly reduced. Experimentally, we demonstrate the benefits of this sparse hierarchical personalization architecture compared with the client-edge-cloud hierarchical FedAvg and the state-of-the-art personalization methods.
Bathymetry Inversion using a Deep-Learning-Based Surrogate for Shallow Water Equations Solvers
Mar 05, 2022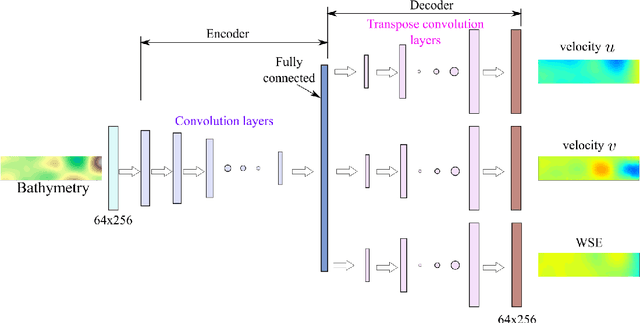
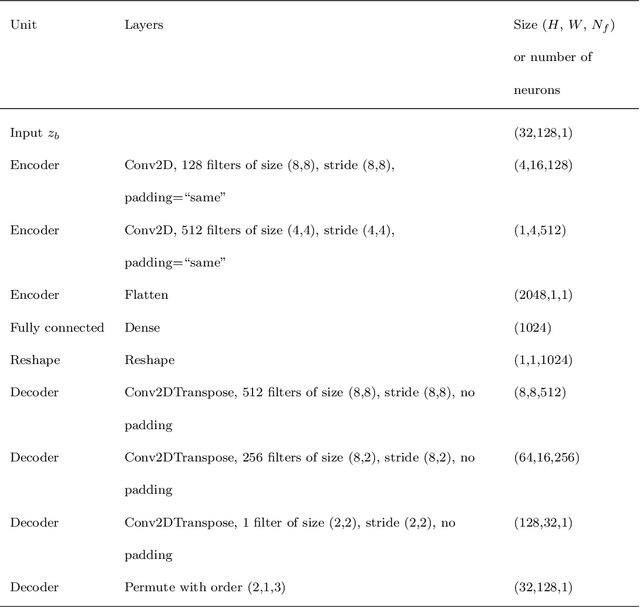
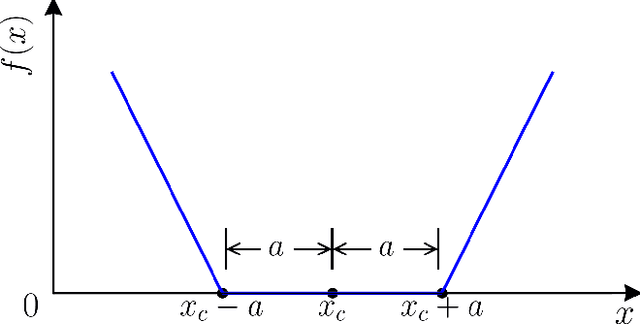
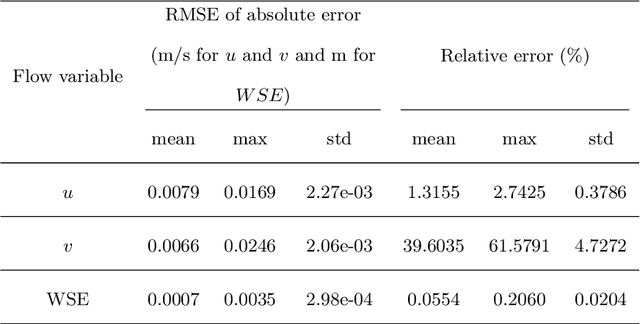
River bathymetry is critical for many aspects of water resources management. We propose and demonstrate a bathymetry inversion method using a deep-learning-based surrogate for shallow water equations solvers. The surrogate uses the convolutional autoencoder with a shared-encoder, separate-decoder architecture. It encodes the input bathymetry and decodes to separate outputs for flow-field variables. A gradient-based optimizer is used to perform bathymetry inversion with the trained surrogate. Two physically-based constraints on both bed elevation value and slope have to be added as inversion loss regularizations to obtain usable inversion results. Using the "L-curve" criterion, a heuristic approach was proposed to determine the regularization parameters. Both the surrogate model and the inversion algorithm show good performance. We found the bathymetry inversion process has two distinctive stages, which resembles the sculptural process of initial broad-brush calving and final detailing. The inversion loss due to flow prediction error reaches its minimum in the first stage and remains almost constant afterward. The bed elevation value and slope regularizations play the dominant role in the second stage in selecting the most probable solution. We also found the surrogate architecture (whether with both velocity and water surface elevation or velocity only as outputs) does not show significant impact on inversion result.
Structure-aware Unsupervised Tagged-to-Cine MRI Synthesis with Self Disentanglement
Feb 25, 2022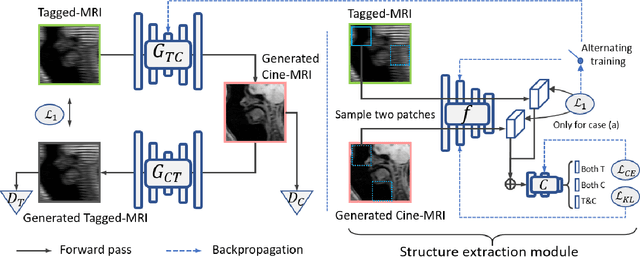

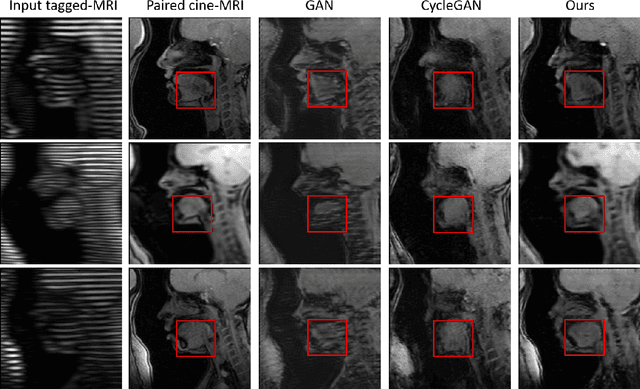
Cycle reconstruction regularized adversarial training -- e.g., CycleGAN, DiscoGAN, and DualGAN -- has been widely used for image style transfer with unpaired training data. Several recent works, however, have shown that local distortions are frequent, and structural consistency cannot be guaranteed. Targeting this issue, prior works usually relied on additional segmentation or consistent feature extraction steps that are task-specific. To counter this, this work aims to learn a general add-on structural feature extractor, by explicitly enforcing the structural alignment between an input and its synthesized image. Specifically, we propose a novel input-output image patches self-training scheme to achieve a disentanglement of underlying anatomical structures and imaging modalities. The translator and structure encoder are updated, following an alternating training protocol. In addition, the information w.r.t. imaging modality can be eliminated with an asymmetric adversarial game. We train, validate, and test our network on 1,768, 416, and 1,560 unpaired subject-independent slices of tagged and cine magnetic resonance imaging from a total of twenty healthy subjects, respectively, demonstrating superior performance over competing methods.
A Multi-modal Fusion Framework Based on Multi-task Correlation Learning for Cancer Prognosis Prediction
Jan 22, 2022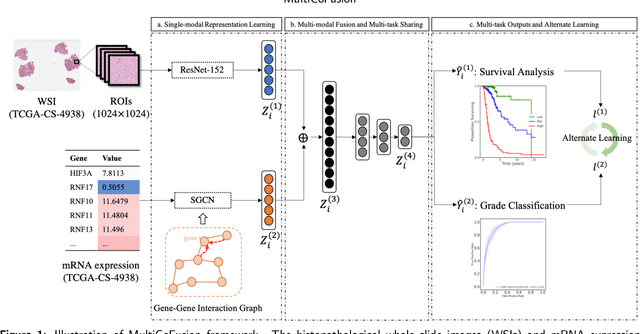
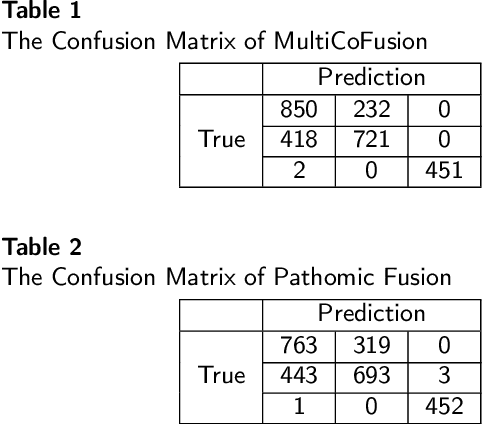
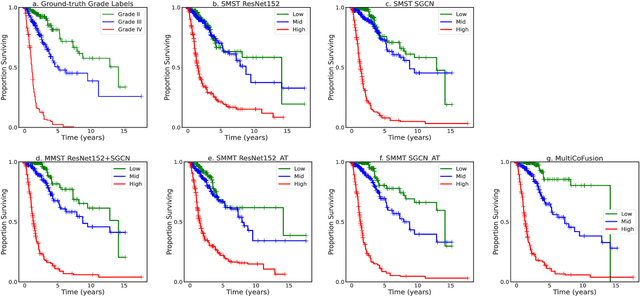
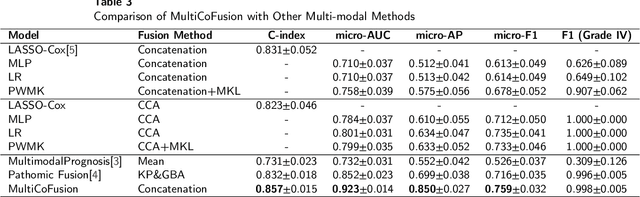
Morphological attributes from histopathological images and molecular profiles from genomic data are important information to drive diagnosis, prognosis, and therapy of cancers. By integrating these heterogeneous but complementary data, many multi-modal methods are proposed to study the complex mechanisms of cancers, and most of them achieve comparable or better results from previous single-modal methods. However, these multi-modal methods are restricted to a single task (e.g., survival analysis or grade classification), and thus neglect the correlation between different tasks. In this study, we present a multi-modal fusion framework based on multi-task correlation learning (MultiCoFusion) for survival analysis and cancer grade classification, which combines the power of multiple modalities and multiple tasks. Specifically, a pre-trained ResNet-152 and a sparse graph convolutional network (SGCN) are used to learn the representations of histopathological images and mRNA expression data respectively. Then these representations are fused by a fully connected neural network (FCNN), which is also a multi-task shared network. Finally, the results of survival analysis and cancer grade classification output simultaneously. The framework is trained by an alternate scheme. We systematically evaluate our framework using glioma datasets from The Cancer Genome Atlas (TCGA). Results demonstrate that MultiCoFusion learns better representations than traditional feature extraction methods. With the help of multi-task alternating learning, even simple multi-modal concatenation can achieve better performance than other deep learning and traditional methods. Multi-task learning can improve the performance of multiple tasks not just one of them, and it is effective in both single-modal and multi-modal data.
Variational Inference for Quantifying Inter-observer Variability in Segmentation of Anatomical Structures
Jan 18, 2022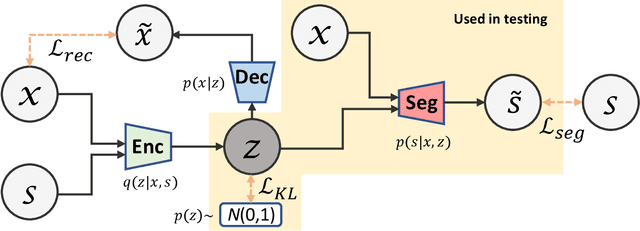

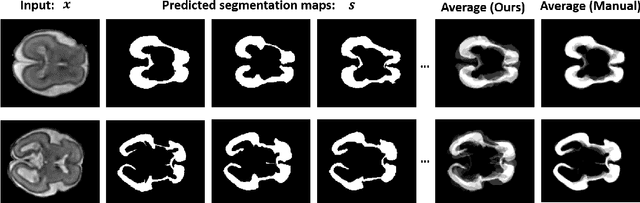

Lesions or organ boundaries visible through medical imaging data are often ambiguous, thus resulting in significant variations in multi-reader delineations, i.e., the source of aleatoric uncertainty. In particular, quantifying the inter-observer variability of manual annotations with Magnetic Resonance (MR) Imaging data plays a crucial role in establishing a reference standard for various diagnosis and treatment tasks. Most segmentation methods, however, simply model a mapping from an image to its single segmentation map and do not take the disagreement of annotators into consideration. In order to account for inter-observer variability, without sacrificing accuracy, we propose a novel variational inference framework to model the distribution of plausible segmentation maps, given a specific MR image, which explicitly represents the multi-reader variability. Specifically, we resort to a latent vector to encode the multi-reader variability and counteract the inherent information loss in the imaging data. Then, we apply a variational autoencoder network and optimize its evidence lower bound (ELBO) to efficiently approximate the distribution of the segmentation map, given an MR image. Experimental results, carried out with the QUBIQ brain growth MRI segmentation datasets with seven annotators, demonstrate the effectiveness of our approach.
Self-semantic contour adaptation for cross modality brain tumor segmentation
Jan 13, 2022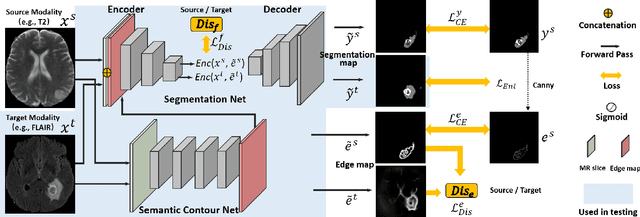
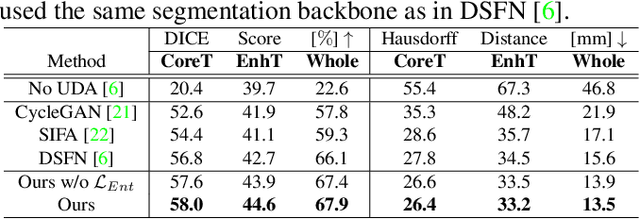
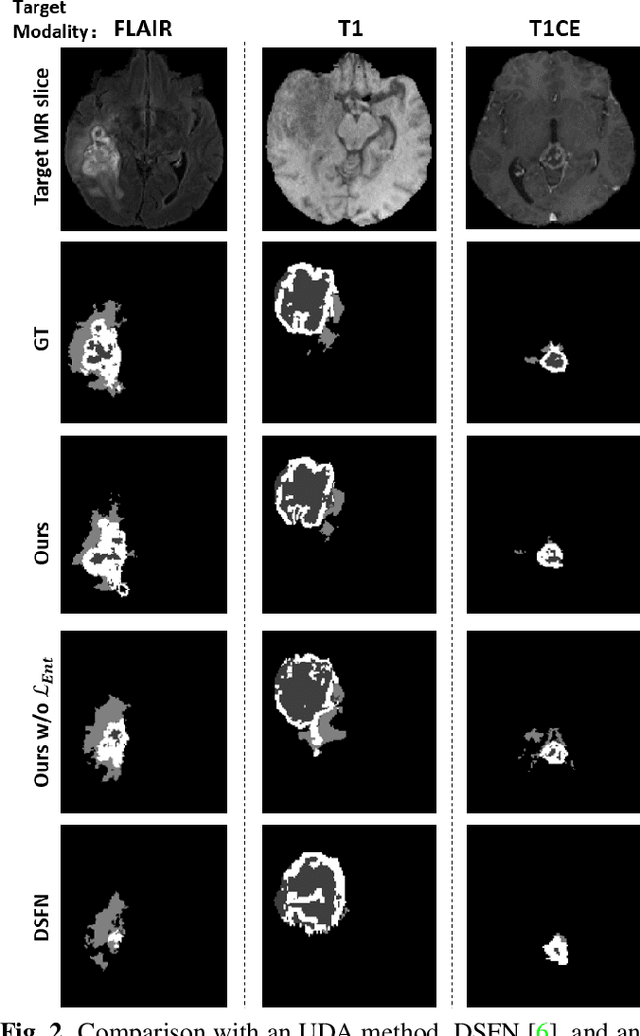
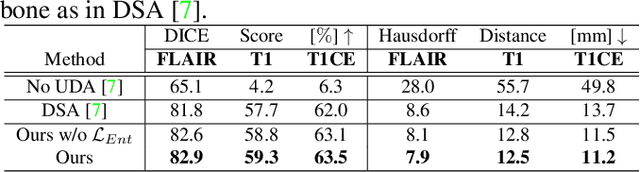
Unsupervised domain adaptation (UDA) between two significantly disparate domains to learn high-level semantic alignment is a crucial yet challenging task.~To this end, in this work, we propose exploiting low-level edge information to facilitate the adaptation as a precursor task, which has a small cross-domain gap, compared with semantic segmentation.~The precise contour then provides spatial information to guide the semantic adaptation. More specifically, we propose a multi-task framework to learn a contouring adaptation network along with a semantic segmentation adaptation network, which takes both magnetic resonance imaging (MRI) slice and its initial edge map as input.~These two networks are jointly trained with source domain labels, and the feature and edge map level adversarial learning is carried out for cross-domain alignment. In addition, self-entropy minimization is incorporated to further enhance segmentation performance. We evaluated our framework on the BraTS2018 database for cross-modality segmentation of brain tumors, showing the validity and superiority of our approach, compared with competing methods.
Surrogate Model for Shallow Water Equations Solvers with Deep Learning
Dec 20, 2021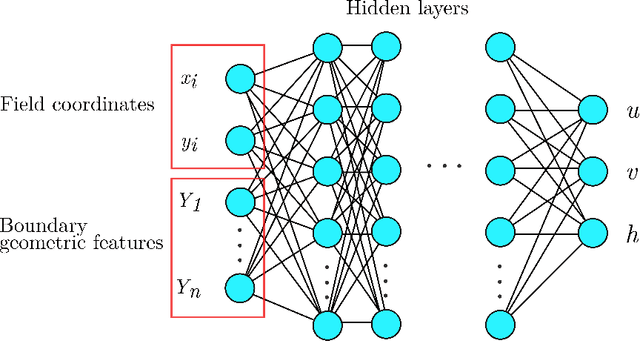
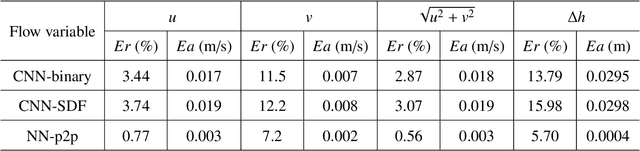
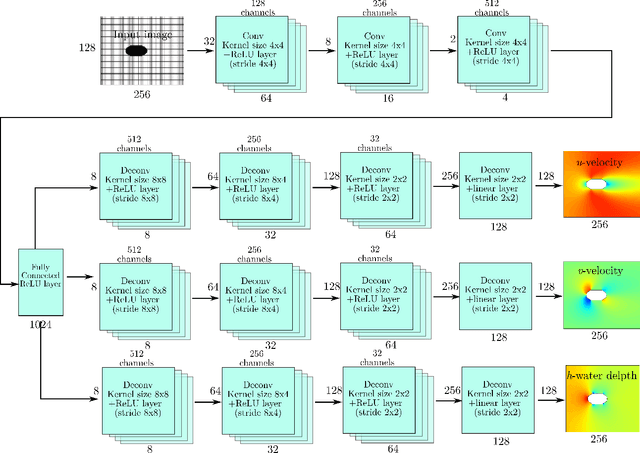

Shallow water equations are the foundation of most models for flooding and river hydraulics analysis. These physics-based models are usually expensive and slow to run, thus not suitable for real-time prediction or parameter inversion. An attractive alternative is surrogate model. This work introduces an efficient, accurate, and flexible surrogate model, NN-p2p, based on deep learning and it can make point-to-point predictions on unstructured or irregular meshes. The new method was evaluated and compared against existing methods based on convolutional neural networks (CNNs), which can only make image-to-image predictions on structured or regular meshes. In NN-p2p, the input includes both spatial coordinates and boundary features that can describe the geometry of hydraulic structures, such as bridge piers. All surrogate models perform well in predicting flow around different types of piers in the training domain. However, only NN-p2p works well when spatial extrapolation is performed. The limitations of CNN-based methods are rooted in their raster-image nature which cannot capture boundary geometry and flow features exactly, which are of paramount importance to fluid dynamics. NN-p2p also has good performance in predicting flow around piers unseen by the neural network. The NN-p2p model also respects conservation laws more strictly. The application of the proposed surrogate model was demonstrated by calculating the drag coefficient $C_D$ for piers and a new linear relationship between $C_D$ and the logarithmic transformation of pier's length/width ratio was discovered.
Recursively Conditional Gaussian for Ordinal Unsupervised Domain Adaptation
Aug 17, 2021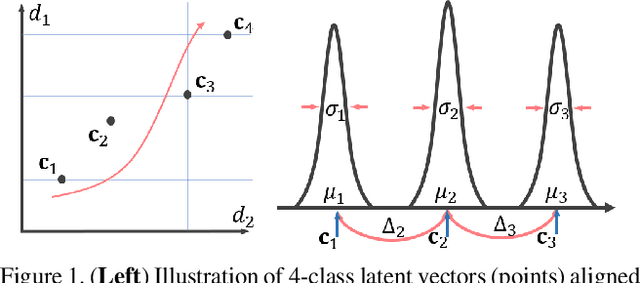
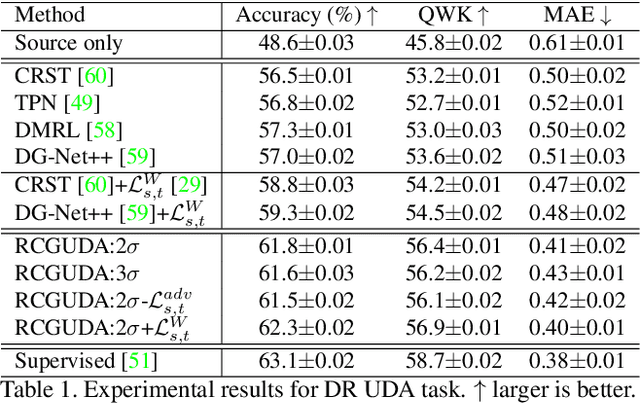
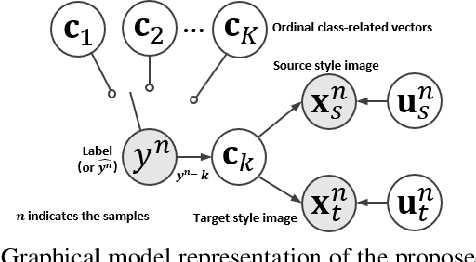
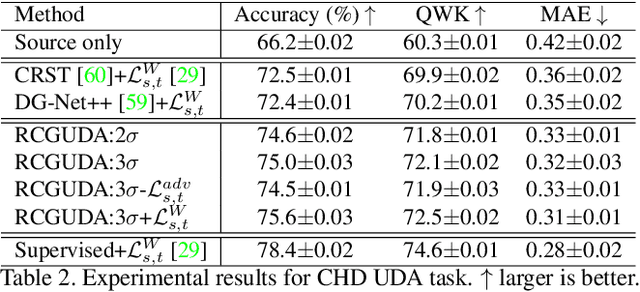
The unsupervised domain adaptation (UDA) has been widely adopted to alleviate the data scalability issue, while the existing works usually focus on classifying independently discrete labels. However, in many tasks (e.g., medical diagnosis), the labels are discrete and successively distributed. The UDA for ordinal classification requires inducing non-trivial ordinal distribution prior to the latent space. Target for this, the partially ordered set (poset) is defined for constraining the latent vector. Instead of the typically i.i.d. Gaussian latent prior, in this work, a recursively conditional Gaussian (RCG) set is adapted for ordered constraint modeling, which admits a tractable joint distribution prior. Furthermore, we are able to control the density of content vector that violates the poset constraints by a simple "three-sigma rule". We explicitly disentangle the cross-domain images into a shared ordinal prior induced ordinal content space and two separate source/target ordinal-unrelated spaces, and the self-training is worked on the shared space exclusively for ordinal-aware domain alignment. Extensive experiments on UDA medical diagnoses and facial age estimation demonstrate its effectiveness.
Adversarial Unsupervised Domain Adaptation with Conditional and Label Shift: Infer, Align and Iterate
Aug 02, 2021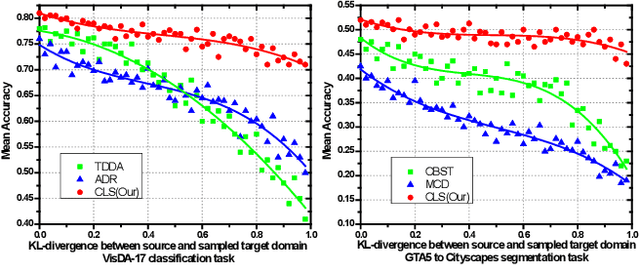
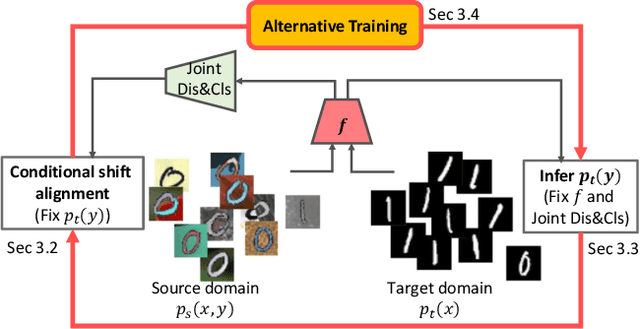
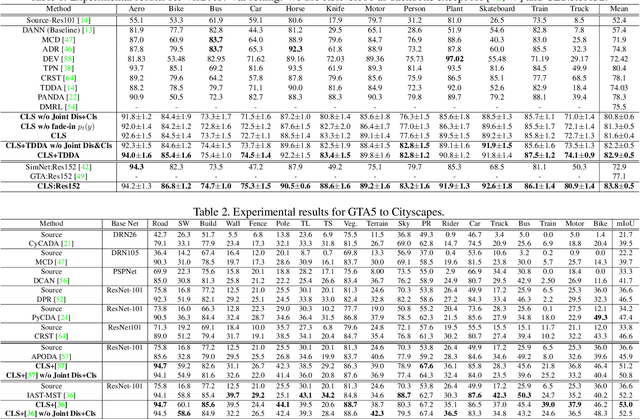
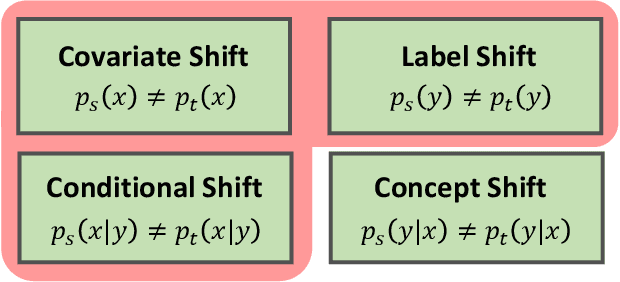
In this work, we propose an adversarial unsupervised domain adaptation (UDA) approach with the inherent conditional and label shifts, in which we aim to align the distributions w.r.t. both $p(x|y)$ and $p(y)$. Since the label is inaccessible in the target domain, the conventional adversarial UDA assumes $p(y)$ is invariant across domains, and relies on aligning $p(x)$ as an alternative to the $p(x|y)$ alignment. To address this, we provide a thorough theoretical and empirical analysis of the conventional adversarial UDA methods under both conditional and label shifts, and propose a novel and practical alternative optimization scheme for adversarial UDA. Specifically, we infer the marginal $p(y)$ and align $p(x|y)$ iteratively in the training, and precisely align the posterior $p(y|x)$ in testing. Our experimental results demonstrate its effectiveness on both classification and segmentation UDA, and partial UDA.