 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Intelligence: Representation Learning, Information Fusion, and Applications
Nov 10, 2019Deep learning has revolutionized speech recognition, image recognition, and natural language processing since 2010, each involving a single modality in the input signal. However, many applications in artificial intelligence involve more than one modality. It is therefore of broad interest to study the more difficult and complex problem of modeling and learning across multiple modalities. In this paper, a technical review of the models and learning methods for multimodal intelligence is provided. The main focus is the combination of vision and natural language, which has become an important area in both computer vision and natural language processing research communities. This review provides a comprehensive analysis of recent work on multimodal deep learning from three new angles - learning multimodal representations, the fusion of multimodal signals at various levels, and multimodal applications. On multimodal representation learning, we review the key concept of embedding, which unifies the multimodal signals into the same vector space and thus enables cross-modality signal processing. We also review the properties of the many types of embedding constructed and learned for general downstream tasks. On multimodal fusion, this review focuses on special architectures for the integration of the representation of unimodal signals for a particular task. On applications, selected areas of a broad interest in current literature are covered, including caption generation, text-to-image generation, and visual question answering. We believe this review can facilitate future studies in the emerging field of multimodal intelligence for the community.
Orthogonal Relation Transforms with Graph Context Modeling for Knowledge Graph Embedding
Nov 09, 2019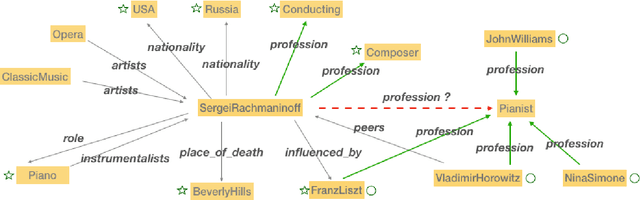
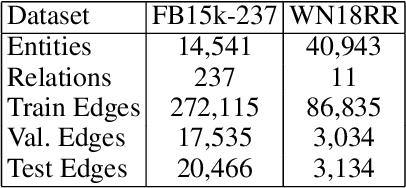
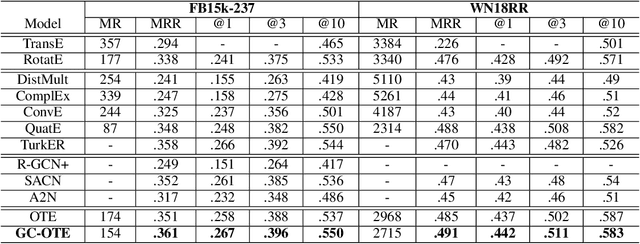
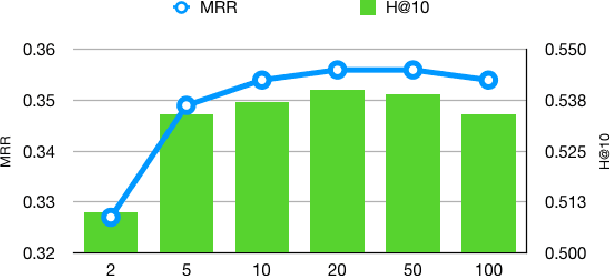
Translational distance-based knowledge graph embedding has shown progressive improvements on the link prediction task, from TransE to the latest state-of-the-art RotatE. However, N-1, 1-N and N-N predictions still remain challenging. In this work, we propose a novel translational distance-based approach for knowledge graph link prediction. The proposed method includes two-folds, first we extend the RotatE from 2D complex domain to high dimension space with orthogonal transforms to model relations for better modeling capacity. Second, the graph context is explicitly modeled via two directed context representations. These context representations are used as part of the distance scoring function to measure the plausibility of the triples during training and inference. The proposed approach effectively improves prediction accuracy on the difficult N-1, 1-N and N-N cases for knowledge graph link prediction task. The experimental results show that it achieves better performance on two benchmark data sets compared to the baseline RotatE, especially on data set (FB15k-237) with many high in-degree connection nodes.
Selective Attention Based Graph Convolutional Networks for Aspect-Level Sentiment Classification
Oct 24, 2019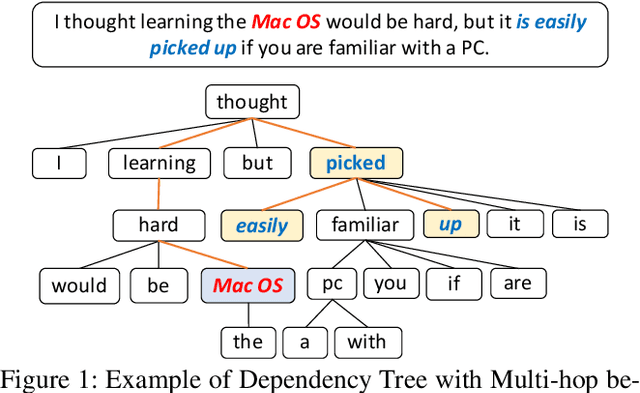
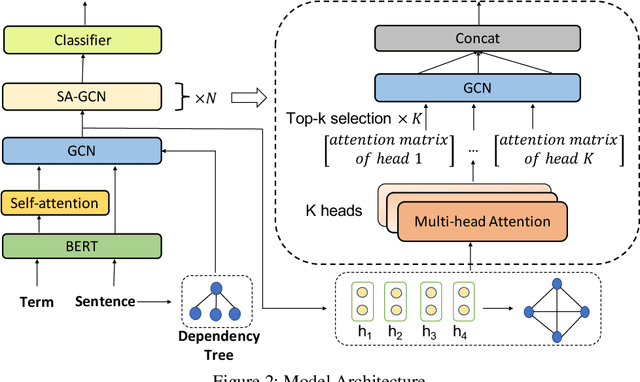
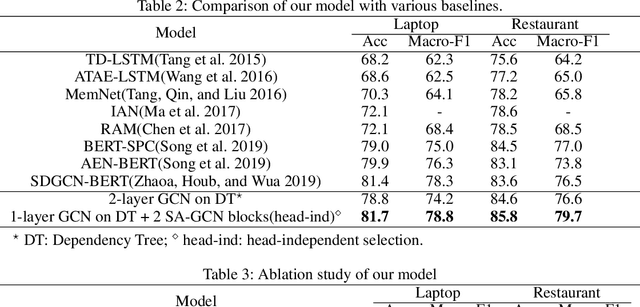
Aspect-level sentiment classification aims to identify the sentiment polarity towards a specific aspect term in a sentence. Most current approaches mainly consider the semantic information by utilizing attention mechanisms to capture the interactions between the context and the aspect term. In this paper, we propose to employ graph convolutional networks (GCNs) on the dependency tree to learn syntax-aware representations of aspect terms. GCNs often show the best performance with two layers, and deeper GCNs do not bring additional gain due to over-smoothing problem. However, in some cases, important context words cannot be reached within two hops on the dependency tree. Therefore we design a selective attention based GCN block (SA-GCN) to find the most important context words, and directly aggregate these information into the aspect-term representation. We conduct experiments on the SemEval 2014 Task 4 datasets. Our experimental results show that our model outperforms the current state-of-the-art.
Relation Module for Non-answerable Prediction on Question Answering
Oct 23, 2019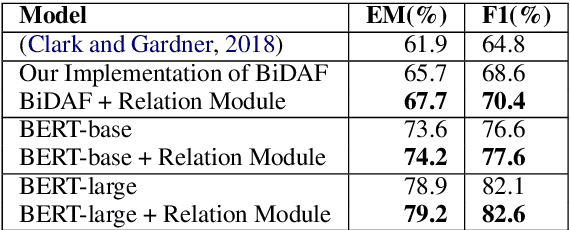
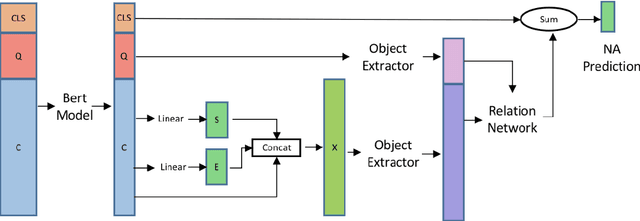

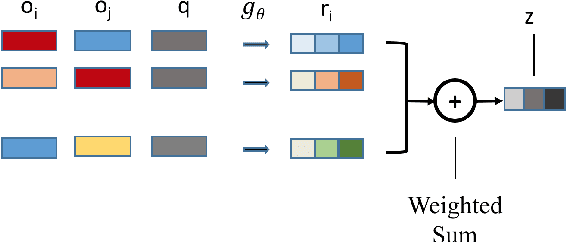
Machine reading comprehension(MRC) has attracted significant amounts of research attention recently, due to an increase of challenging reading comprehension datasets. In this paper, we aim to improve a MRC model's ability to determine whether a question has an answer in a given context (e.g. the recently proposed SQuAD 2.0 task). Our solution is a relation module that is adaptable to any MRC model. The relation module consists of both semantic extraction and relational information. We first extract high level semantics as objects from both question and context with multi-head self-attentive pooling. These semantic objects are then passed to a relation network, which generates relationship scores for each object pair in a sentence. These scores are used to determine whether a question is non-answerable. We test the relation module on the SQuAD 2.0 dataset using both BiDAF and BERT models as baseline readers. We obtain 1.8% gain of F1 on top of the BiDAF reader, and 1.0% on top of the BERT base model. These results show the effectiveness of our relation module on MRC
Zero-shot Text-to-SQL Learning with Auxiliary Task
Aug 29, 2019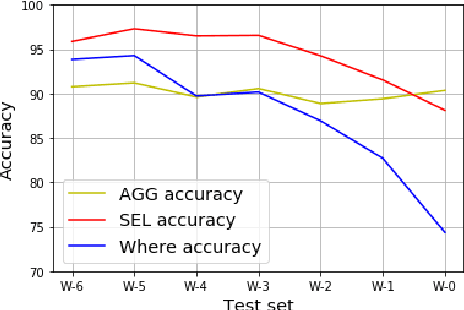
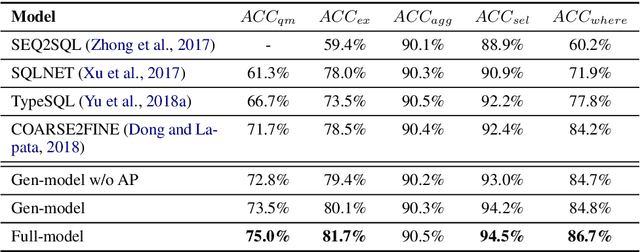
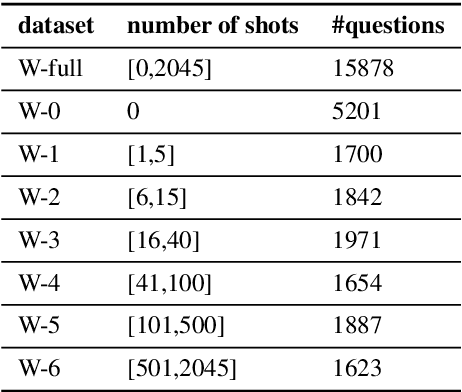
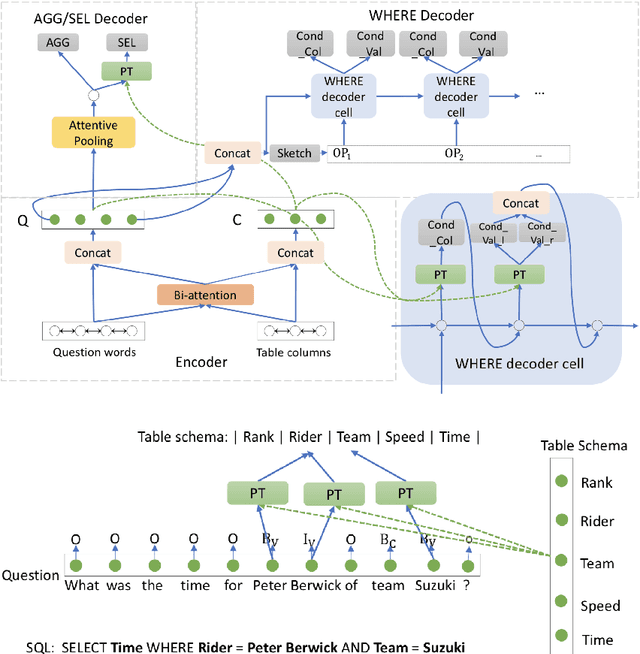
Recent years have seen great success in the use of neural seq2seq models on the text-to-SQL task. However, little work has paid attention to how these models generalize to realistic unseen data, which naturally raises a question: does this impressive performance signify a perfect generalization model, or are there still some limitations? In this paper, we first diagnose the bottleneck of text-to-SQL task by providing a new testbed, in which we observe that existing models present poor generalization ability on rarely-seen data. The above analysis encourages us to design a simple but effective auxiliary task, which serves as a supportive model as well as a regularization term to the generation task to increase the models generalization. Experimentally, We evaluate our models on a large text-to-SQL dataset WikiSQL. Compared to a strong baseline coarse-to-fine model, our models improve over the baseline by more than 3% absolute in accuracy on the whole dataset. More interestingly, on a zero-shot subset test of WikiSQL, our models achieve 5% absolute accuracy gain over the baseline, clearly demonstrating its superior generalizability.
Multiple instance learning with graph neural networks
Jun 12, 2019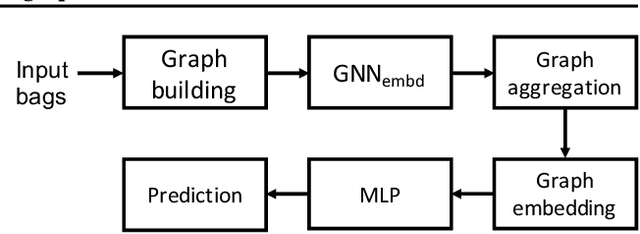
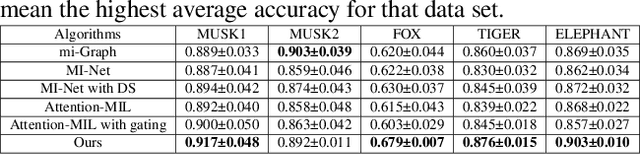
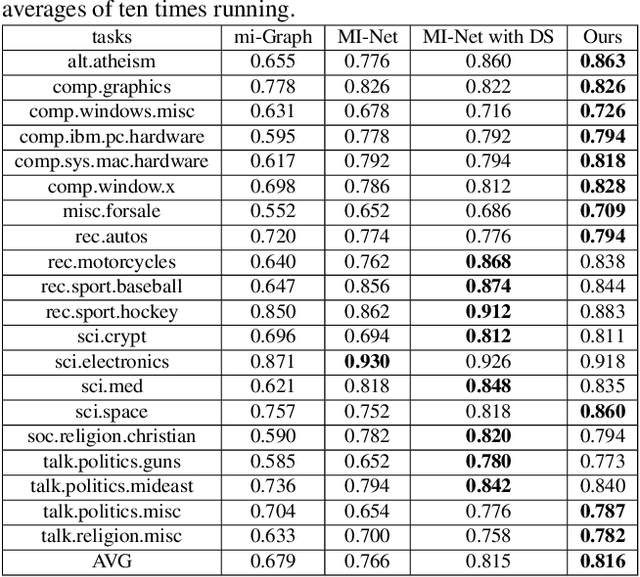
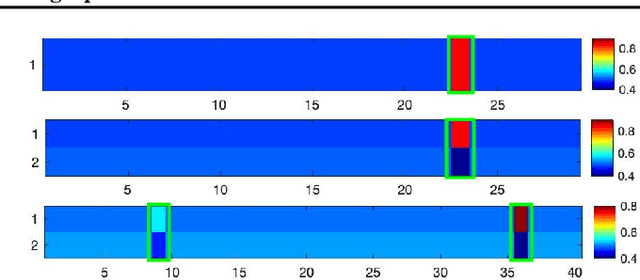
Multiple instance learning (MIL) aims to learn the mapping between a bag of instances and the bag-level label. In this paper, we propose a new end-to-end graph neural network (GNN) based algorithm for MIL: we treat each bag as a graph and use GNN to learn the bag embedding, in order to explore the useful structural information among instances in bags. The final graph representation is fed into a classifier for label prediction. Our algorithm is the first attempt to use GNN for MIL. We empirically show that the proposed algorithm achieves the state of the art performance on several popular MIL data sets without losing model interpretability.
Multi-hop Reading Comprehension across Multiple Documents by Reasoning over Heterogeneous Graphs
Jun 04, 2019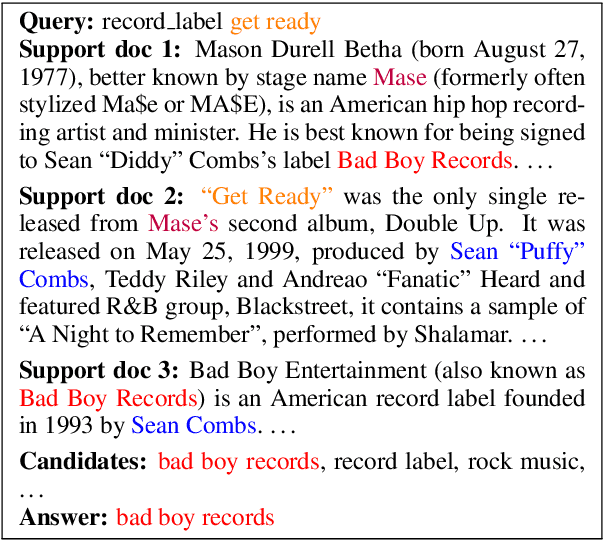
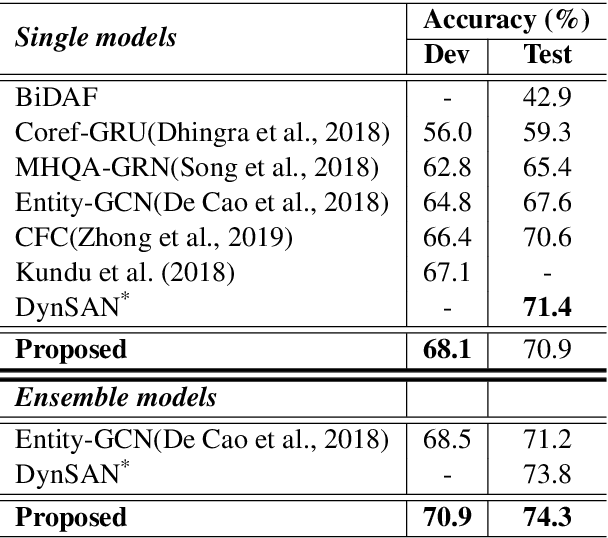
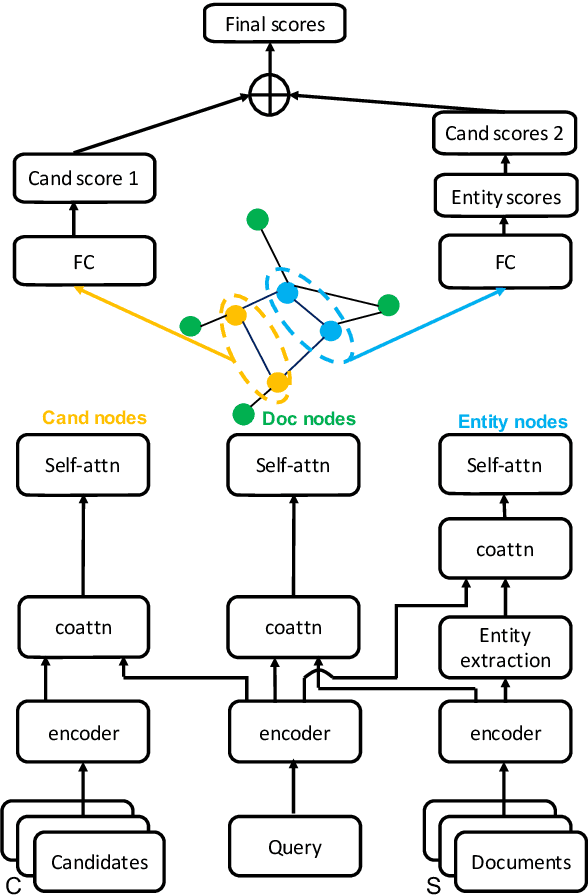
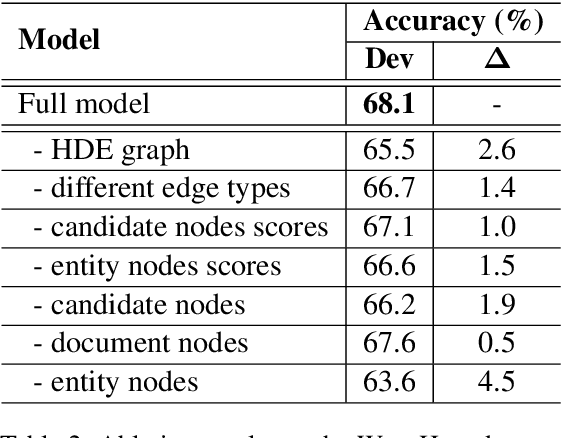
Multi-hop reading comprehension (RC) across documents poses new challenge over single-document RC because it requires reasoning over multiple documents to reach the final answer. In this paper, we propose a new model to tackle the multi-hop RC problem. We introduce a heterogeneous graph with different types of nodes and edges, which is named as Heterogeneous Document-Entity (HDE) graph. The advantage of HDE graph is that it contains different granularity levels of information including candidates, documents and entities in specific document contexts. Our proposed model can do reasoning over the HDE graph with nodes representation initialized with co-attention and self-attention based context encoders. We employ Graph Neural Networks (GNN) based message passing algorithms to accumulate evidences on the proposed HDE graph. Evaluated on the blind test set of the Qangaroo WikiHop data set, our HDE graph based single model delivers competitive result, and the ensemble model achieves the state-of-the-art performance.
Mappa Mundi: An Interactive Artistic Mind Map Generator with Artificial Imagination
May 09, 2019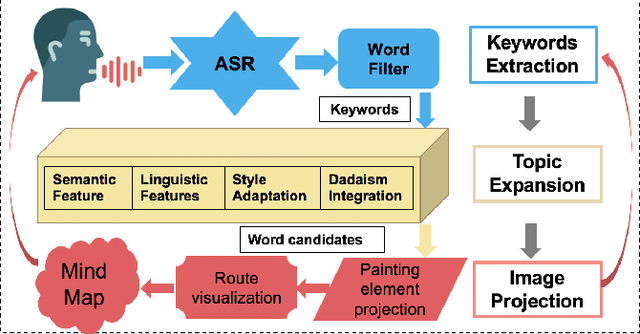
We present a novel real-time, collaborative, and interactive AI painting system, Mappa Mundi, for artistic Mind Map creation. The system consists of a voice-based input interface, an automatic topic expansion module, and an image projection module. The key innovation is to inject Artificial Imagination into painting creation by considering lexical and phonological similarities of language, learning and inheriting artist's original painting style, and applying the principles of Dadaism and impossibility of improvisation. Our system indicates that AI and artist can collaborate seamlessly to create imaginative artistic painting and Mappa Mundi has been applied in art exhibition in UCCA, Beijing
From Knowledge Map to Mind Map: Artificial Imagination
Mar 06, 2019

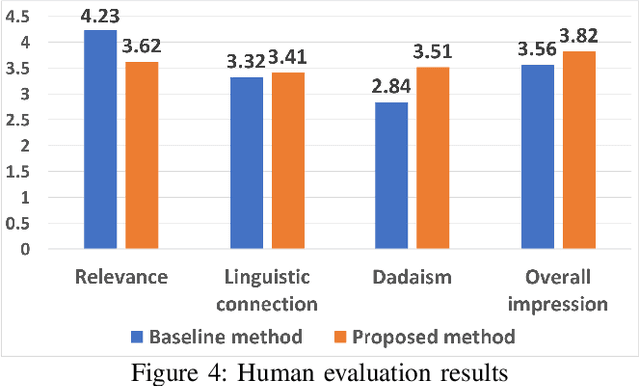
Imagination is one of the most important factors which makes an artistic painting unique and impressive. With the rapid development of Artificial Intelligence, more and more researchers try to create painting with AI technology automatically. However, lacking of imagination is still a main problem for AI painting. In this paper, we propose a novel approach to inject rich imagination into a special painting art Mind Map creation. We firstly consider lexical and phonological similarities of seed word, then learn and inherit original painting style of the author, and finally apply Dadaism and impossibility of improvisation principles into painting process. We also design several metrics for imagination evaluation. Experimental results show that our proposed method can increase imagination of painting and also improve its overall quality.
Object-driven Text-to-Image Synthesis via Adversarial Training
Feb 27, 2019
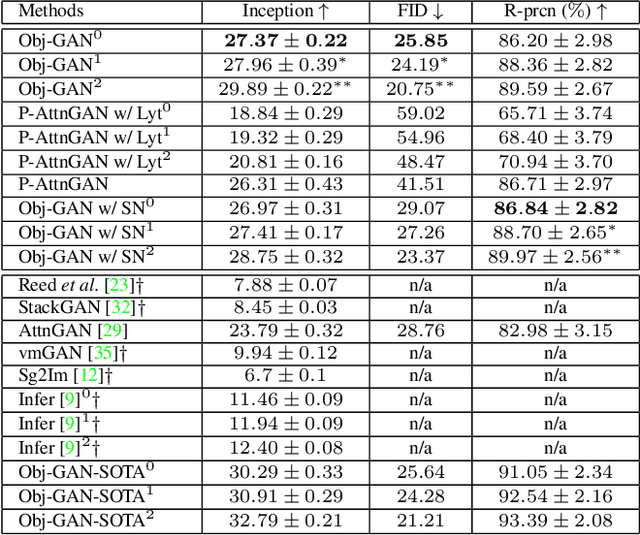
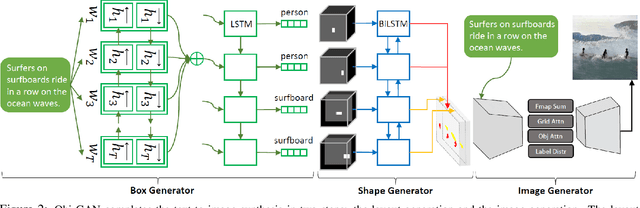

In this paper, we propose Object-driven Attentive Generative Adversarial Newtorks (Obj-GANs) that allow object-centered text-to-image synthesis for complex scenes. Following the two-step (layout-image) generation process, a novel object-driven attentive image generator is proposed to synthesize salient objects by paying attention to the most relevant words in the text description and the pre-generated semantic layout. In addition, a new Fast R-CNN based object-wise discriminator is proposed to provide rich object-wise discrimination signals on whether the synthesized object matches the text description and the pre-generated layout. The proposed Obj-GAN significantly outperforms the previous state of the art in various metrics on the large-scale COCO benchmark, increasing the Inception score by 27% and decreasing the FID score by 11%. A thorough comparison between the traditional grid attention and the new object-driven attention is provided through analyzing their mechanisms and visualizing their attention layers, showing insights of how the proposed model generates complex scenes in high quality.