 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInter-GPS: Interpretable Geometry Problem Solving with Formal Language and Symbolic Reasoning
Jun 01, 2021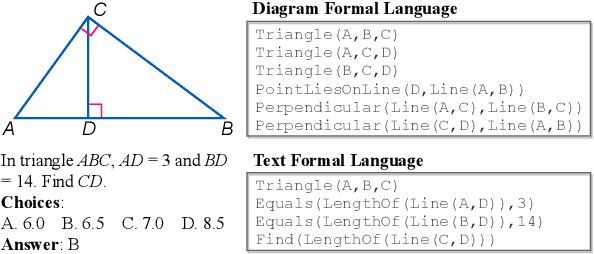

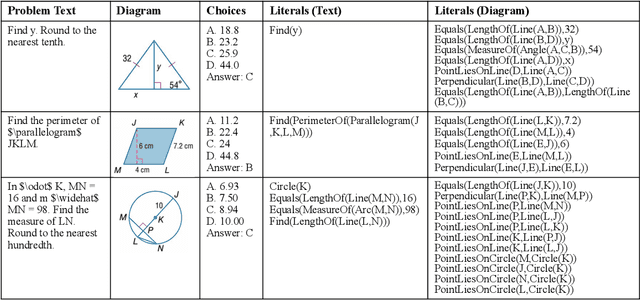

Geometry problem solving has attracted much attention in the NLP community recently. The task is challenging as it requires abstract problem understanding and symbolic reasoning with axiomatic knowledge. However, current datasets are either small in scale or not publicly available. Thus, we construct a new large-scale benchmark, Geometry3K, consisting of 3,002 geometry problems with dense annotation in formal language. We further propose a novel geometry solving approach with formal language and symbolic reasoning, called Interpretable Geometry Problem Solver (Inter-GPS). Inter-GPS first parses the problem text and diagram into formal language automatically via rule-based text parsing and neural object detecting, respectively. Unlike implicit learning in existing methods, Inter-GPS incorporates theorem knowledge as conditional rules and performs symbolic reasoning step by step. Also, a theorem predictor is designed to infer the theorem application sequence fed to the symbolic solver for the more efficient and reasonable searching path. Extensive experiments on the Geometry3K and GEOS datasets demonstrate that Inter-GPS achieves significant improvements over existing methods. The project with code and data is available at https://lupantech.github.io/inter-gps.
Towards Quantifiable Dialogue Coherence Evaluation
Jun 01, 2021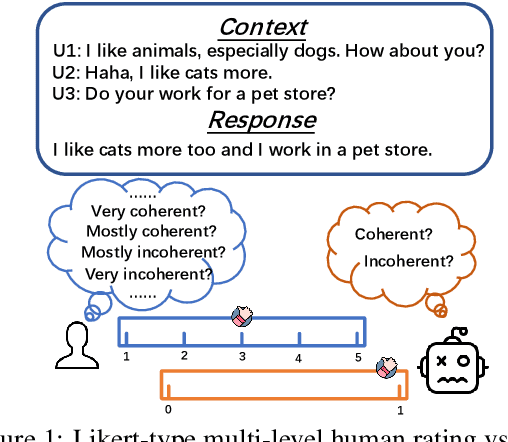
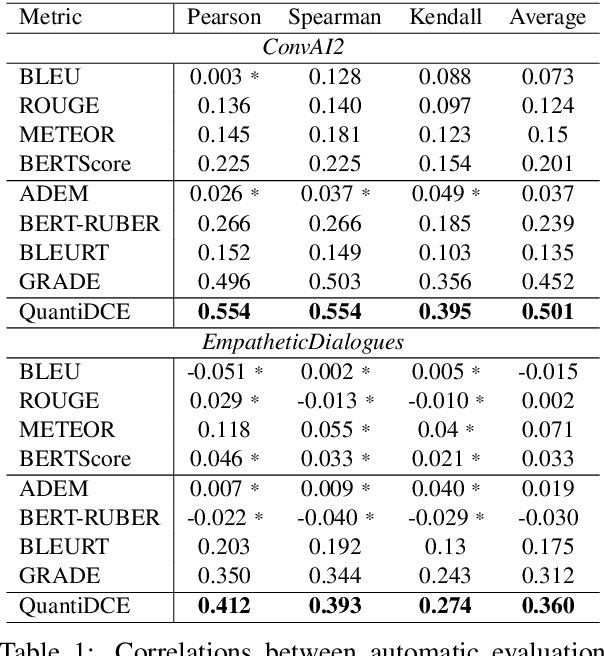
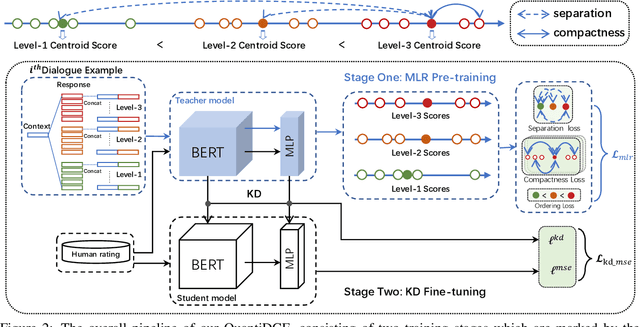
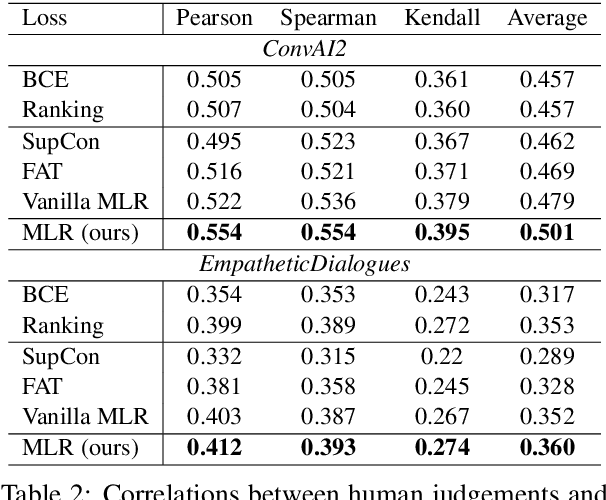
Automatic dialogue coherence evaluation has attracted increasing attention and is crucial for developing promising dialogue systems. However, existing metrics have two major limitations: (a) they are mostly trained in a simplified two-level setting (coherent vs. incoherent), while humans give Likert-type multi-level coherence scores, dubbed as "quantifiable"; (b) their predicted coherence scores cannot align with the actual human rating standards due to the absence of human guidance during training. To address these limitations, we propose Quantifiable Dialogue Coherence Evaluation (QuantiDCE), a novel framework aiming to train a quantifiable dialogue coherence metric that can reflect the actual human rating standards. Specifically, QuantiDCE includes two training stages, Multi-Level Ranking (MLR) pre-training and Knowledge Distillation (KD) fine-tuning. During MLR pre-training, a new MLR loss is proposed for enabling the model to learn the coarse judgement of coherence degrees. Then, during KD fine-tuning, the pretrained model is further finetuned to learn the actual human rating standards with only very few human-annotated data. To advocate the generalizability even with limited fine-tuning data, a novel KD regularization is introduced to retain the knowledge learned at the pre-training stage. Experimental results show that the model trained by QuantiDCE presents stronger correlations with human judgements than the other state-of-the-art metrics.
TransNAS-Bench-101: Improving Transferability and Generalizability of Cross-Task Neural Architecture Search
May 25, 2021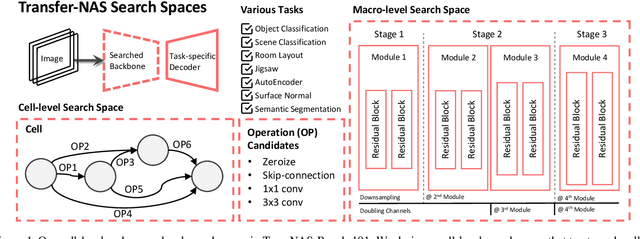
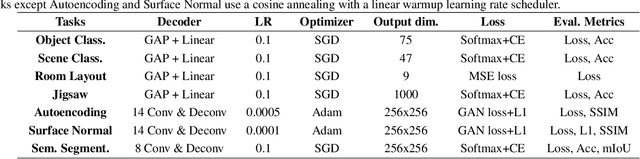


Recent breakthroughs of Neural Architecture Search (NAS) extend the field's research scope towards a broader range of vision tasks and more diversified search spaces. While existing NAS methods mostly design architectures on a single task, algorithms that look beyond single-task search are surging to pursue a more efficient and universal solution across various tasks. Many of them leverage transfer learning and seek to preserve, reuse, and refine network design knowledge to achieve higher efficiency in future tasks. However, the enormous computational cost and experiment complexity of cross-task NAS are imposing barriers for valuable research in this direction. Existing NAS benchmarks all focus on one type of vision task, i.e., classification. In this work, we propose TransNAS-Bench-101, a benchmark dataset containing network performance across seven tasks, covering classification, regression, pixel-level prediction, and self-supervised tasks. This diversity provides opportunities to transfer NAS methods among tasks and allows for more complex transfer schemes to evolve. We explore two fundamentally different types of search space: cell-level search space and macro-level search space. With 7,352 backbones evaluated on seven tasks, 51,464 trained models with detailed training information are provided. With TransNAS-Bench-101, we hope to encourage the advent of exceptional NAS algorithms that raise cross-task search efficiency and generalizability to the next level. Our dataset file will be available at Mindspore, VEGA.
DAGN: Discourse-Aware Graph Network for Logical Reasoning
Apr 08, 2021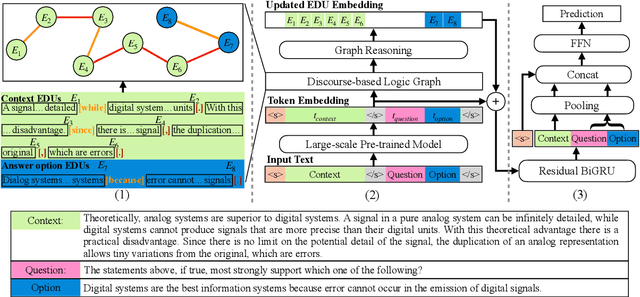
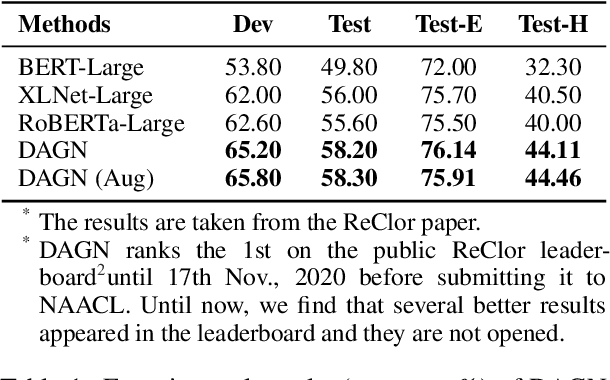
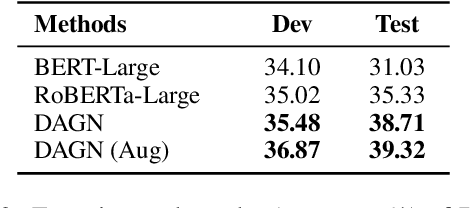

Recent QA with logical reasoning questions requires passage-level relations among the sentences. However, current approaches still focus on sentence-level relations interacting among tokens. In this work, we explore aggregating passage-level clues for solving logical reasoning QA by using discourse-based information. We propose a discourse-aware graph network (DAGN) that reasons relying on the discourse structure of the texts. The model encodes discourse information as a graph with elementary discourse units (EDUs) and discourse relations, and learns the discourse-aware features via a graph network for downstream QA tasks. Experiments are conducted on two logical reasoning QA datasets, ReClor and LogiQA, and our proposed DAGN achieves competitive results. The source code is available at https://github.com/Eleanor-H/DAGN.
SOON: Scenario Oriented Object Navigation with Graph-based Exploration
Mar 31, 2021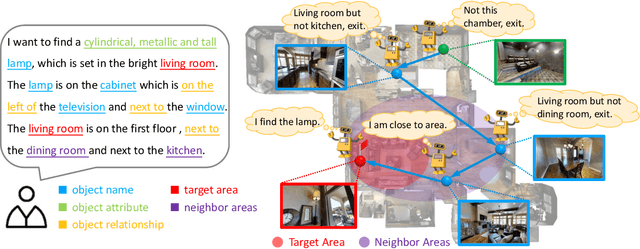
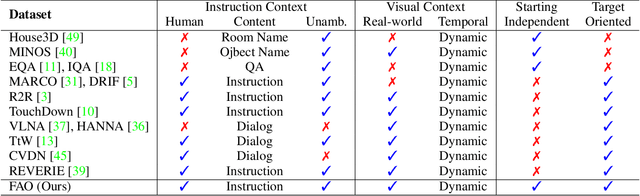
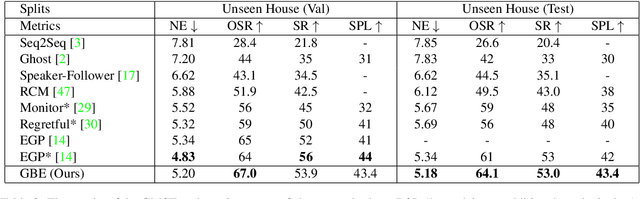
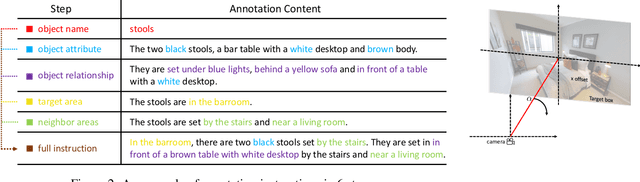
The ability to navigate like a human towards a language-guided target from anywhere in a 3D embodied environment is one of the 'holy grail' goals of intelligent robots. Most visual navigation benchmarks, however, focus on navigating toward a target from a fixed starting point, guided by an elaborate set of instructions that depicts step-by-step. This approach deviates from real-world problems in which human-only describes what the object and its surrounding look like and asks the robot to start navigation from anywhere. Accordingly, in this paper, we introduce a Scenario Oriented Object Navigation (SOON) task. In this task, an agent is required to navigate from an arbitrary position in a 3D embodied environment to localize a target following a scene description. To give a promising direction to solve this task, we propose a novel graph-based exploration (GBE) method, which models the navigation state as a graph and introduces a novel graph-based exploration approach to learn knowledge from the graph and stabilize training by learning sub-optimal trajectories. We also propose a new large-scale benchmark named From Anywhere to Object (FAO) dataset. To avoid target ambiguity, the descriptions in FAO provide rich semantic scene information includes: object attribute, object relationship, region description, and nearby region description. Our experiments reveal that the proposed GBE outperforms various state-of-the-arts on both FAO and R2R datasets. And the ablation studies on FAO validates the quality of the dataset.
BossNAS: Exploring Hybrid CNN-transformers with Block-wisely Self-supervised Neural Architecture Search
Mar 24, 2021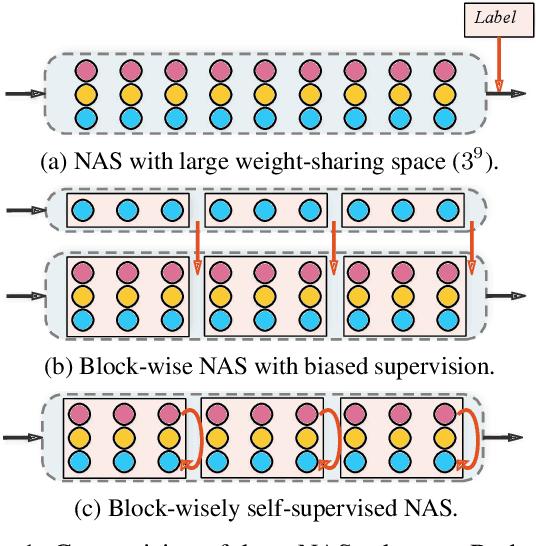
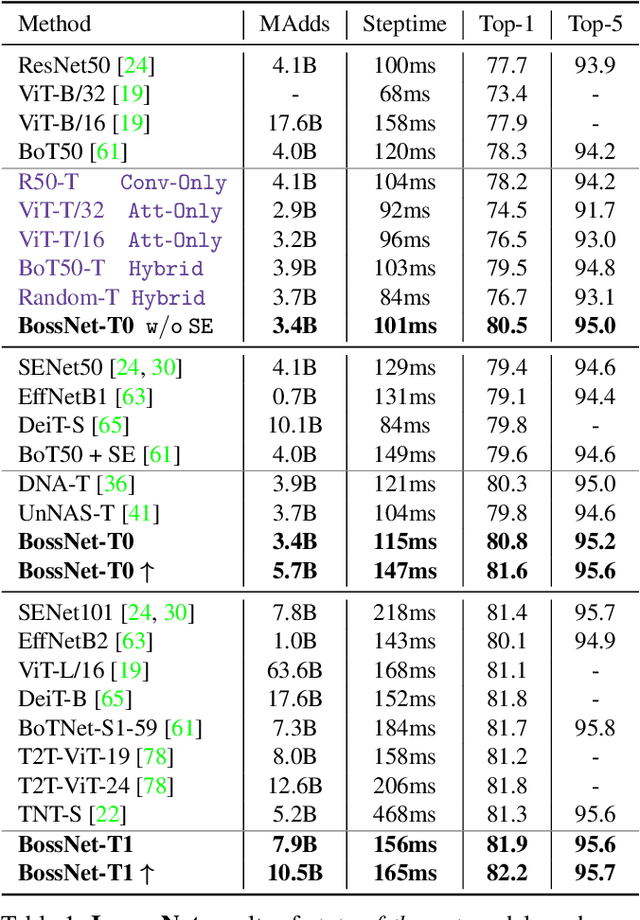
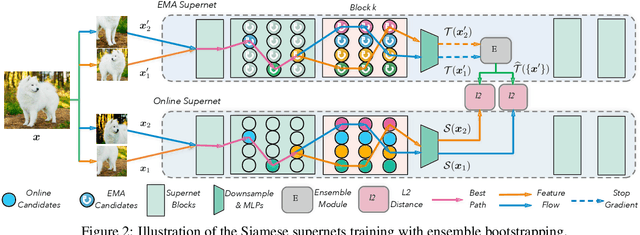
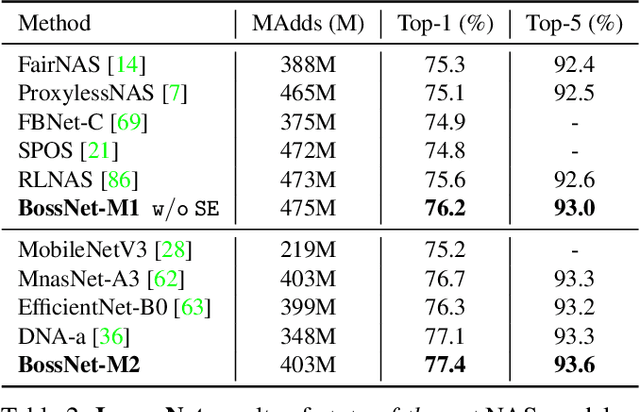
A myriad of recent breakthroughs in hand-crafted neural architectures for visual recognition have highlighted the urgent need to explore hybrid architectures consisting of diversified building blocks. Meanwhile, neural architecture search methods are surging with an expectation to reduce human efforts. However, whether NAS methods can efficiently and effectively handle diversified search spaces with disparate candidates (e.g. CNNs and transformers) is still an open question. In this work, we present Block-wisely Self-supervised Neural Architecture Search (BossNAS), an unsupervised NAS method that addresses the problem of inaccurate architecture rating caused by large weight-sharing space and biased supervision in previous methods. More specifically, we factorize the search space into blocks and utilize a novel self-supervised training scheme, named ensemble bootstrapping, to train each block separately before searching them as a whole towards the population center. Additionally, we present HyTra search space, a fabric-like hybrid CNN-transformer search space with searchable down-sampling positions. On this challenging search space, our searched model, BossNet-T, achieves up to 82.2% accuracy on ImageNet, surpassing EfficientNet by 2.1% with comparable compute time. Moreover, our method achieves superior architecture rating accuracy with 0.78 and 0.76 Spearman correlation on the canonical MBConv search space with ImageNet and on NATS-Bench size search space with CIFAR-100, respectively, surpassing state-of-the-art NAS methods. Code and pretrained models are available at https://github.com/changlin31/BossNAS .
Dynamic Slimmable Network
Mar 24, 2021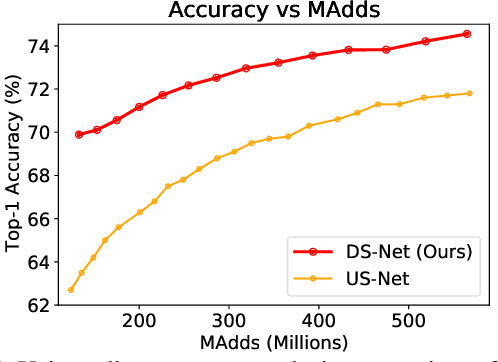

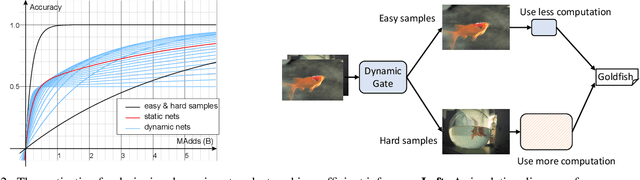
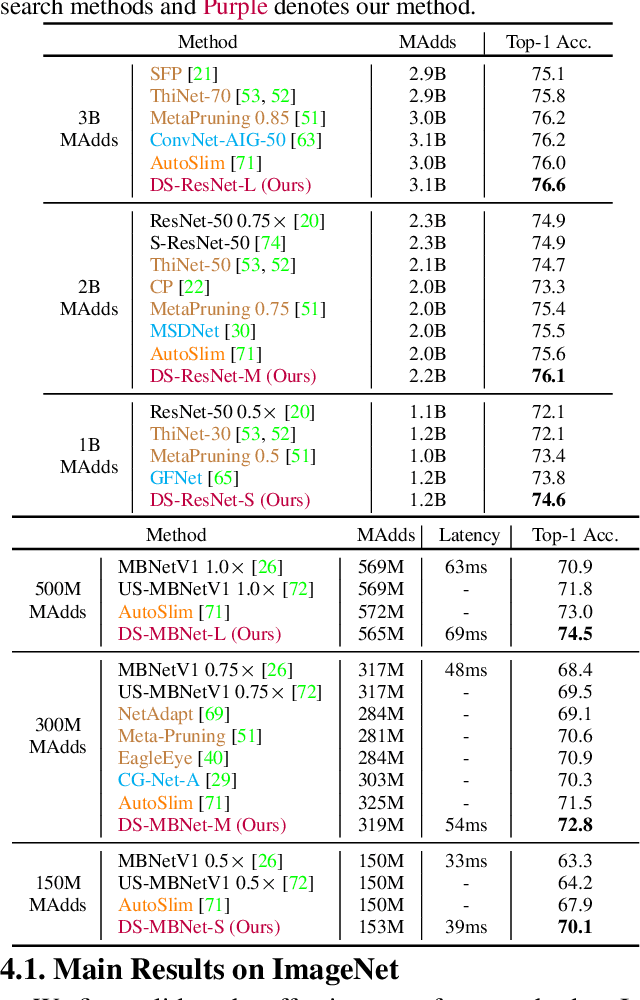
Current dynamic networks and dynamic pruning methods have shown their promising capability in reducing theoretical computation complexity. However, dynamic sparse patterns on convolutional filters fail to achieve actual acceleration in real-world implementation, due to the extra burden of indexing, weight-copying, or zero-masking. Here, we explore a dynamic network slimming regime, named Dynamic Slimmable Network (DS-Net), which aims to achieve good hardware-efficiency via dynamically adjusting filter numbers of networks at test time with respect to different inputs, while keeping filters stored statically and contiguously in hardware to prevent the extra burden. Our DS-Net is empowered with the ability of dynamic inference by the proposed double-headed dynamic gate that comprises an attention head and a slimming head to predictively adjust network width with negligible extra computation cost. To ensure generality of each candidate architecture and the fairness of gate, we propose a disentangled two-stage training scheme inspired by one-shot NAS. In the first stage, a novel training technique for weight-sharing networks named In-place Ensemble Bootstrapping is proposed to improve the supernet training efficacy. In the second stage, Sandwich Gate Sparsification is proposed to assist the gate training by identifying easy and hard samples in an online way. Extensive experiments demonstrate our DS-Net consistently outperforms its static counterparts as well as state-of-the-art static and dynamic model compression methods by a large margin (up to 5.9%). Typically, DS-Net achieves 2-4x computation reduction and 1.62x real-world acceleration over ResNet-50 and MobileNet with minimal accuracy drops on ImageNet. Code release: https://github.com/changlin31/DS-Net .
A Data-Centric Framework for Composable NLP Workflows
Mar 03, 2021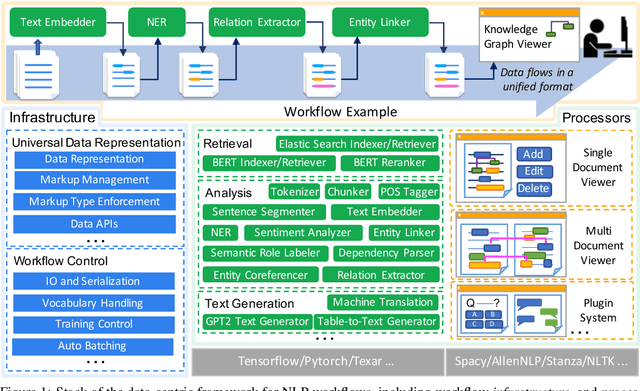
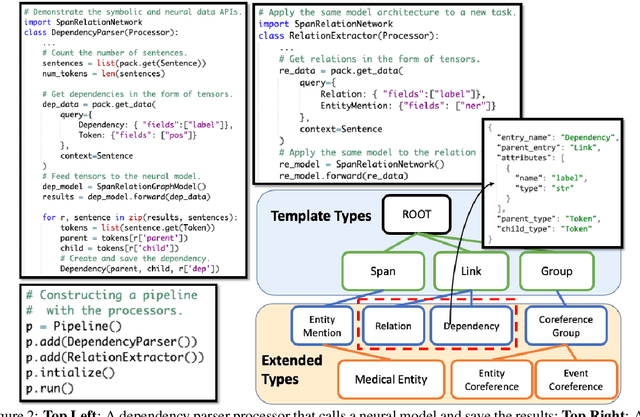
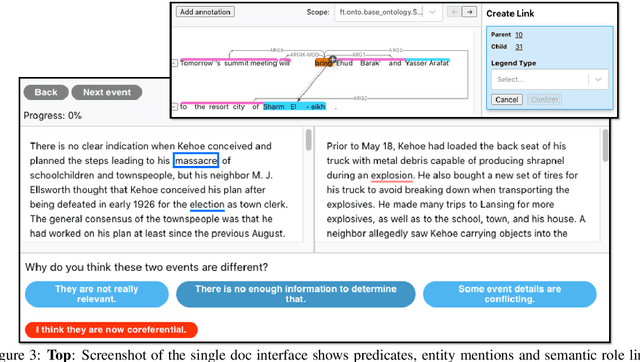
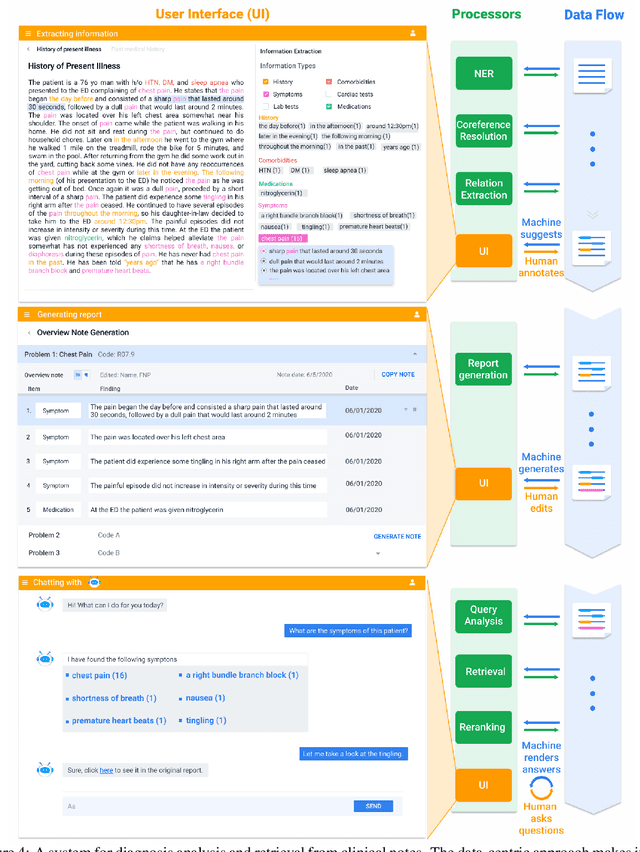
Empirical natural language processing (NLP) systems in application domains (e.g., healthcare, finance, education) involve interoperation among multiple components, ranging from data ingestion, human annotation, to text retrieval, analysis, generation, and visualization. We establish a unified open-source framework to support fast development of such sophisticated NLP workflows in a composable manner. The framework introduces a uniform data representation to encode heterogeneous results by a wide range of NLP tasks. It offers a large repository of processors for NLP tasks, visualization, and annotation, which can be easily assembled with full interoperability under the unified representation. The highly extensible framework allows plugging in custom processors from external off-the-shelf NLP and deep learning libraries. The whole framework is delivered through two modularized yet integratable open-source projects, namely Forte1 (for workflow infrastructure and NLP function processors) and Stave2 (for user interaction, visualization, and annotation).
SparseBERT: Rethinking the Importance Analysis in Self-attention
Feb 25, 2021
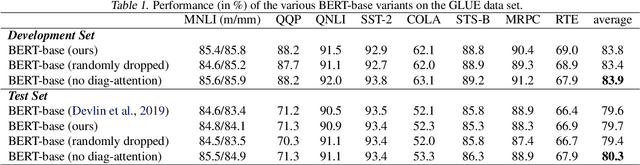
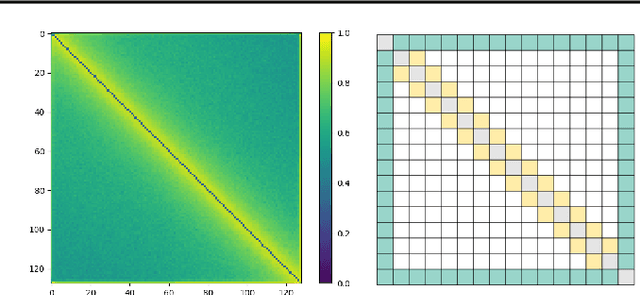
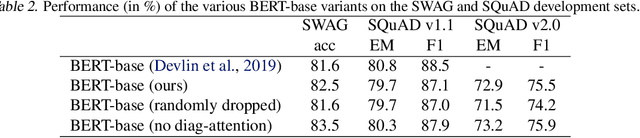
Transformer-based models are popular for natural language processing (NLP) tasks due to its powerful capacity. As the core component, self-attention module has aroused widespread interests. Attention map visualization of a pre-trained model is one direct method for understanding self-attention mechanism and some common patterns are observed in visualization. Based on these patterns, a series of efficient transformers are proposed with corresponding sparse attention masks. Besides above empirical results, universal approximability of Transformer-based models is also discovered from a theoretical perspective. However, above understanding and analysis of self-attention is based on a pre-trained model. To rethink the importance analysis in self-attention, we delve into dynamics of attention matrix importance during pre-training. One of surprising results is that the diagonal elements in the attention map are the most unimportant compared with other attention positions and we also provide a proof to show these elements can be removed without damaging the model performance. Furthermore, we propose a Differentiable Attention Mask (DAM) algorithm, which can be also applied in guidance of SparseBERT design further. The extensive experiments verify our interesting findings and illustrate the effect of our proposed algorithm.
Loss Function Discovery for Object Detection via Convergence-Simulation Driven Search
Feb 09, 2021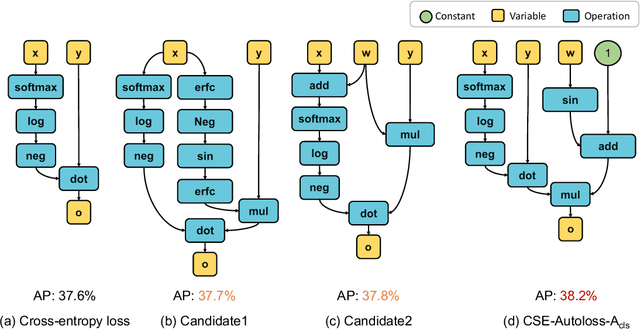
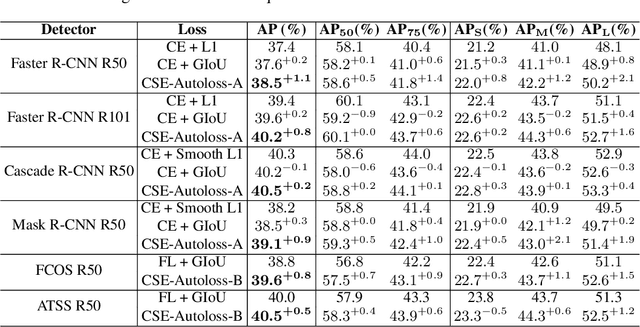
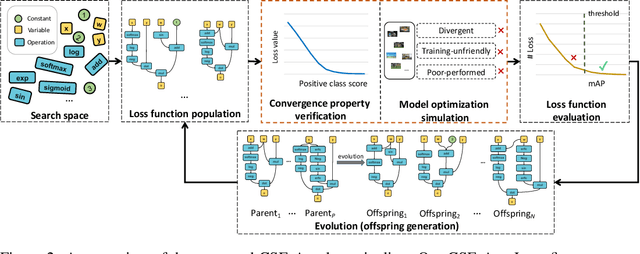

Designing proper loss functions for vision tasks has been a long-standing research direction to advance the capability of existing models. For object detection, the well-established classification and regression loss functions have been carefully designed by considering diverse learning challenges. Inspired by the recent progress in network architecture search, it is interesting to explore the possibility of discovering new loss function formulations via directly searching the primitive operation combinations. So that the learned losses not only fit for diverse object detection challenges to alleviate huge human efforts, but also have better alignment with evaluation metric and good mathematical convergence property. Beyond the previous auto-loss works on face recognition and image classification, our work makes the first attempt to discover new loss functions for the challenging object detection from primitive operation levels. We propose an effective convergence-simulation driven evolutionary search algorithm, called CSE-Autoloss, for speeding up the search progress by regularizing the mathematical rationality of loss candidates via convergence property verification and model optimization simulation. CSE-Autoloss involves the search space that cover a wide range of the possible variants of existing losses and discovers best-searched loss function combination within a short time (around 1.5 wall-clock days). We conduct extensive evaluations of loss function search on popular detectors and validate the good generalization capability of searched losses across diverse architectures and datasets. Our experiments show that the best-discovered loss function combinations outperform default combinations by 1.1% and 0.8% in terms of mAP for two-stage and one-stage detectors on COCO respectively. Our searched losses are available at https://github.com/PerdonLiu/CSE-Autoloss.