 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Memory Learning for Fine-Grained Scene Graph Generation
Mar 23, 2022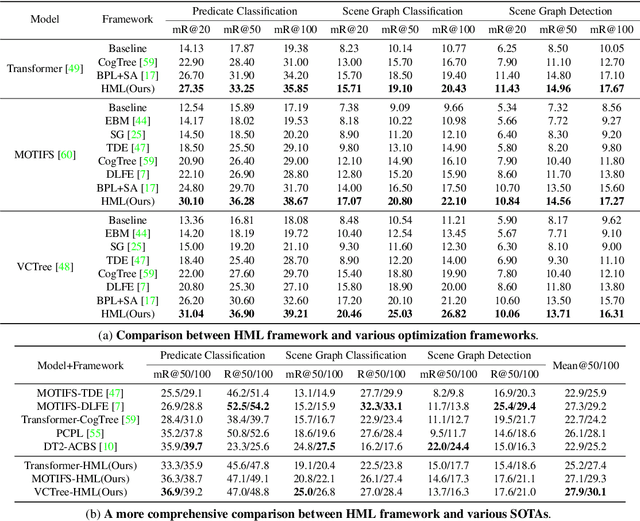
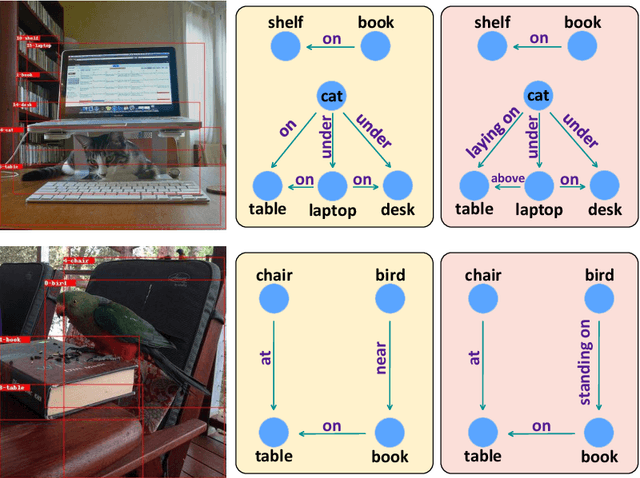
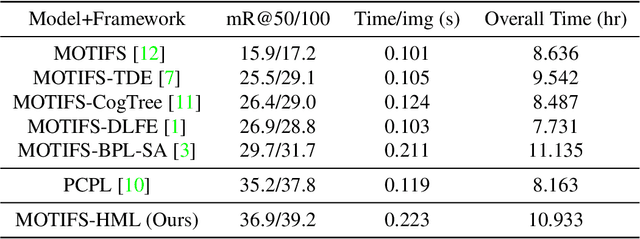
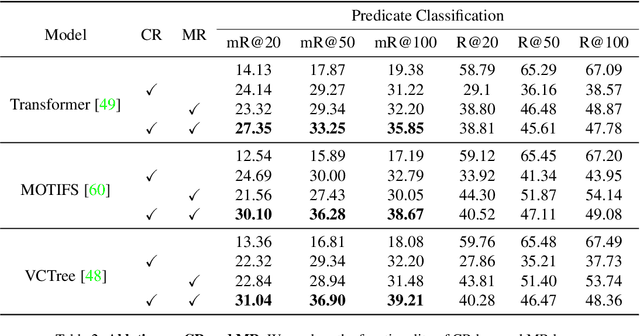
As far as Scene Graph Generation (SGG), coarse and fine predicates mix in the dataset due to the crowd-sourced labeling, and the long-tail problem is also pronounced. Given this tricky situation, many existing SGG methods treat the predicates equally and learn the model under the supervision of mixed-granularity predicates in one stage, leading to relatively coarse predictions. In order to alleviate the negative impact of the suboptimum mixed-granularity annotation and long-tail effect problems, this paper proposes a novel Hierarchical Memory Learning (HML) framework to learn the model from simple to complex, which is similar to the human beings' hierarchical memory learning process. After the autonomous partition of coarse and fine predicates, the model is first trained on the coarse predicates and then learns the fine predicates. In order to realize this hierarchical learning pattern, this paper, for the first time, formulates the HML framework using the new Concept Reconstruction (CR) and Model Reconstruction (MR) constraints. It is worth noticing that the HML framework can be taken as one general optimization strategy to improve various SGG models, and significant improvement can be achieved on the SGG benchmark (i.e., Visual Genome).
Long-Tailed Classification with Gradual Balanced Loss and Adaptive Feature Generation
Feb 28, 2022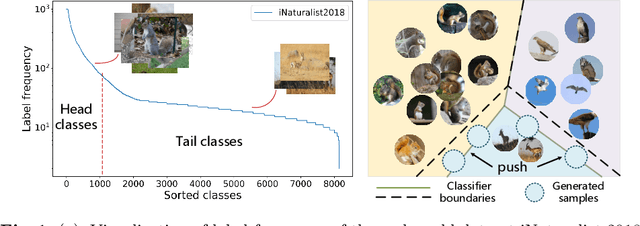
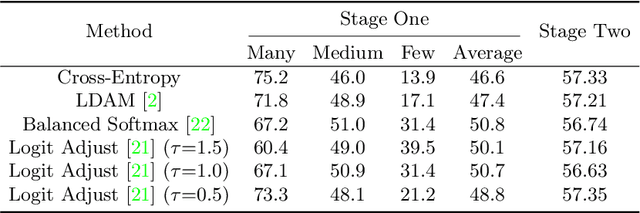
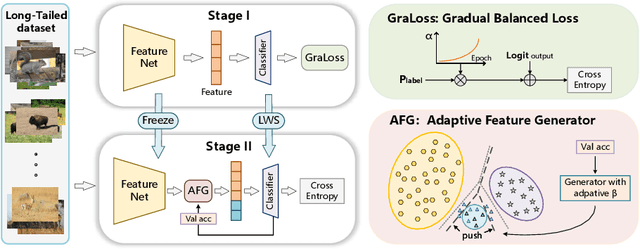
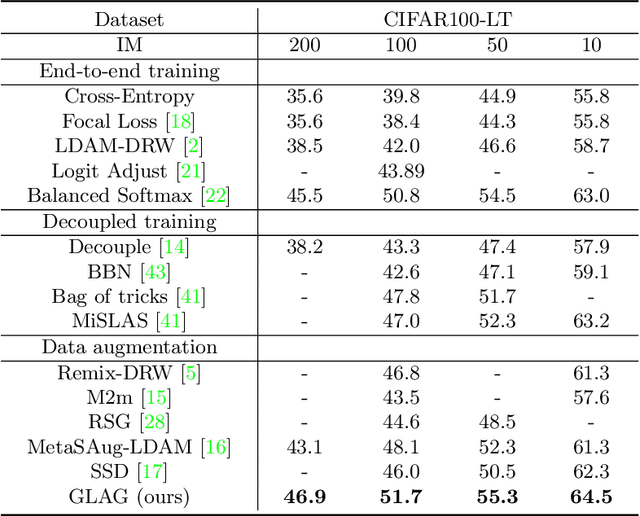
The real-world data distribution is essentially long-tailed, which poses great challenge to the deep model. In this work, we propose a new method, Gradual Balanced Loss and Adaptive Feature Generator (GLAG) to alleviate imbalance. GLAG first learns a balanced and robust feature model with Gradual Balanced Loss, then fixes the feature model and augments the under-represented tail classes on the feature level with the knowledge from well-represented head classes. And the generated samples are mixed up with real training samples during training epochs. Gradual Balanced Loss is a general loss and it can combine with different decoupled training methods to improve the original performance. State-of-the-art results have been achieved on long-tail datasets such as CIFAR100-LT, ImageNetLT, and iNaturalist, which demonstrates the effectiveness of GLAG for long-tailed visual recognition.
Introduction to The Dynamic Pickup and Delivery Problem Benchmark -- ICAPS 2021 Competition
Jan 19, 2022The Dynamic Pickup and Delivery Problem (DPDP) is an essential problem within the logistics domain. So far, research on this problem has mainly focused on using artificial data which fails to reflect the complexity of real-world problems. In this draft, we would like to introduce a new benchmark from real business scenarios as well as a simulator supporting the dynamic evaluation. The benchmark and simulator have been published and successfully supported the ICAPS 2021 Dynamic Pickup and Delivery Problem competition participated by 152 teams.
Coarse-To-Fine Incremental Few-Shot Learning
Nov 24, 2021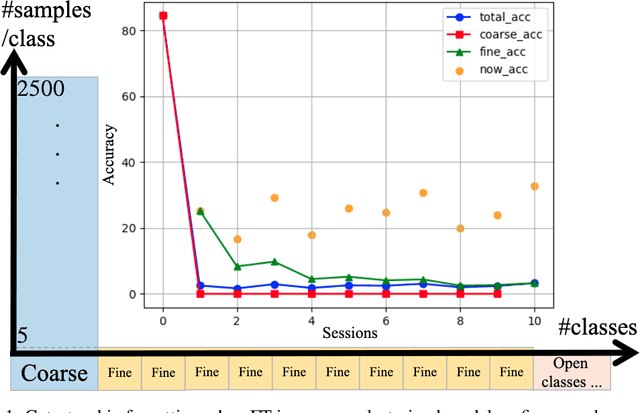

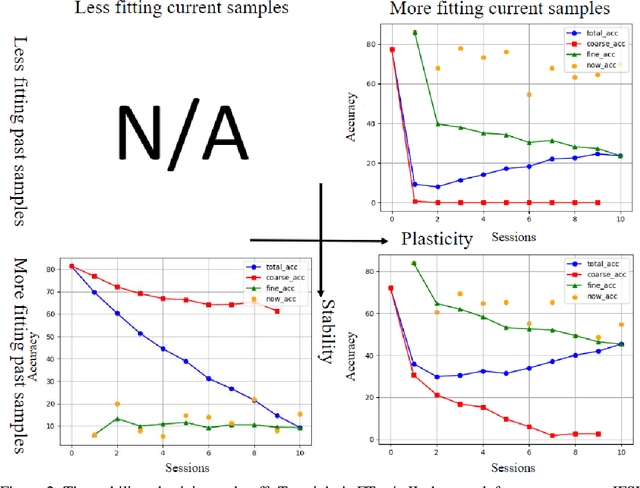
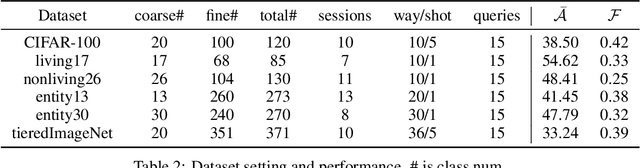
Different from fine-tuning models pre-trained on a large-scale dataset of preset classes, class-incremental learning (CIL) aims to recognize novel classes over time without forgetting pre-trained classes. However, a given model will be challenged by test images with finer-grained classes, e.g., a basenji is at most recognized as a dog. Such images form a new training set (i.e., support set) so that the incremental model is hoped to recognize a basenji (i.e., query) as a basenji next time. This paper formulates such a hybrid natural problem of coarse-to-fine few-shot (C2FS) recognition as a CIL problem named C2FSCIL, and proposes a simple, effective, and theoretically-sound strategy Knowe: to learn, normalize, and freeze a classifier's weights from fine labels, once learning an embedding space contrastively from coarse labels. Besides, as CIL aims at a stability-plasticity balance, new overall performance metrics are proposed. In that sense, on CIFAR-100, BREEDS, and tieredImageNet, Knowe outperforms all recent relevant CIL/FSCIL methods that are tailored to the new problem setting for the first time.
Entropy-based Optimization via A* Algorithm for Parking Space Recommendation
Apr 19, 2021
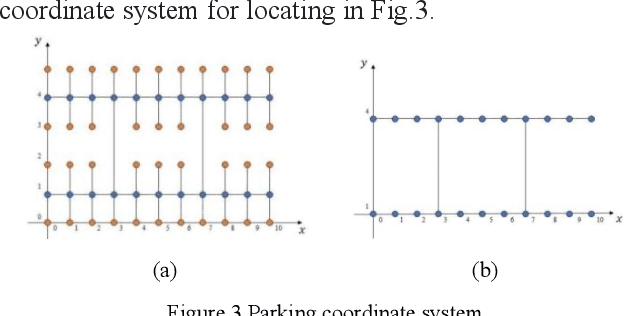
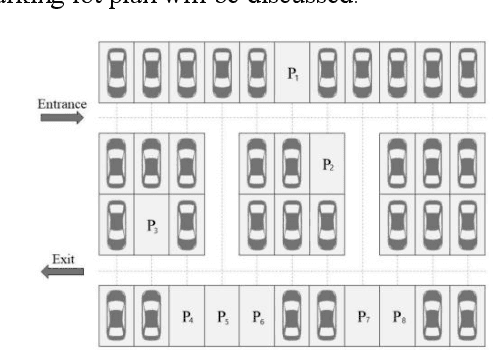
This paper addresses the path planning problems for recommending parking spaces, given the difficulties of identifying the most optimal route to vacant parking spaces and the shortest time to leave the parking space. Our optimization approach is based on the entropy method and realized by the A* algorithm. Experiments have shown that the combination of A* and the entropy value induces the optimal parking solution with the shortest route while being robust to environmental factors.
Adversarial Deep Structured Nets for Mass Segmentation from Mammograms
Dec 25, 2017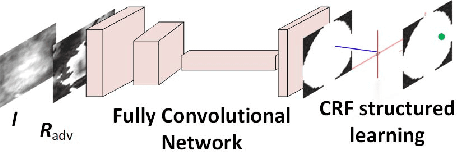
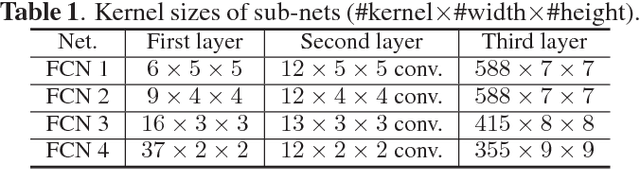

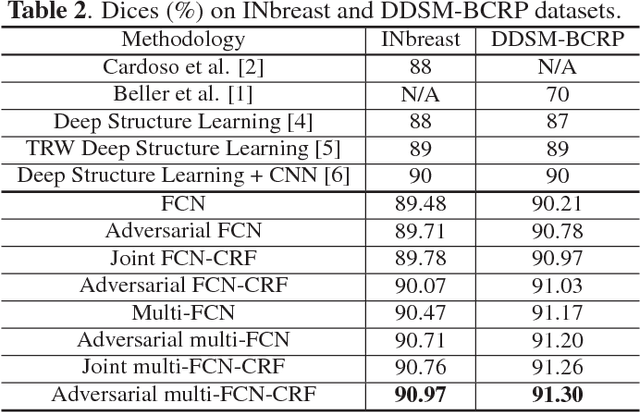
Mass segmentation provides effective morphological features which are important for mass diagnosis. In this work, we propose a novel end-to-end network for mammographic mass segmentation which employs a fully convolutional network (FCN) to model a potential function, followed by a CRF to perform structured learning. Because the mass distribution varies greatly with pixel position, the FCN is combined with a position priori. Further, we employ adversarial training to eliminate over-fitting due to the small sizes of mammogram datasets. Multi-scale FCN is employed to improve the segmentation performance. Experimental results on two public datasets, INbreast and DDSM-BCRP, demonstrate that our end-to-end network achieves better performance than state-of-the-art approaches. \footnote{https://github.com/wentaozhu/adversarial-deep-structural-networks.git}
NormFace: L2 Hypersphere Embedding for Face Verification
Jul 26, 2017
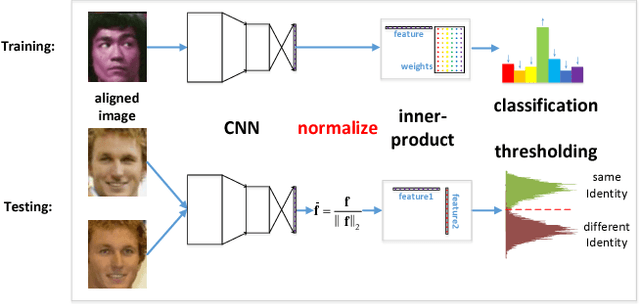
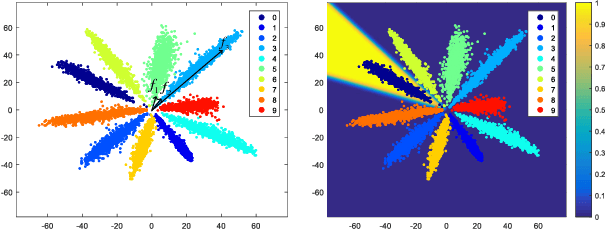
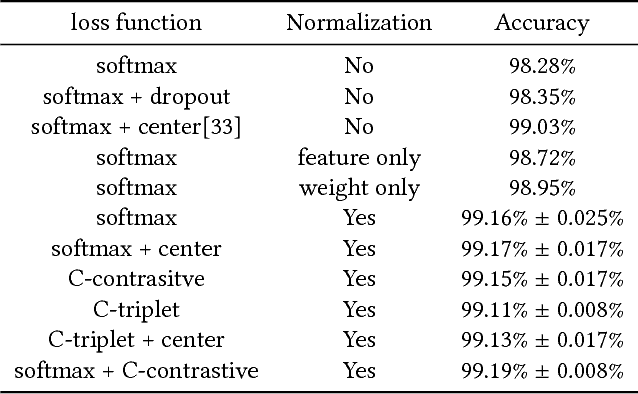
Thanks to the recent developments of Convolutional Neural Networks, the performance of face verification methods has increased rapidly. In a typical face verification method, feature normalization is a critical step for boosting performance. This motivates us to introduce and study the effect of normalization during training. But we find this is non-trivial, despite normalization being differentiable. We identify and study four issues related to normalization through mathematical analysis, which yields understanding and helps with parameter settings. Based on this analysis we propose two strategies for training using normalized features. The first is a modification of softmax loss, which optimizes cosine similarity instead of inner-product. The second is a reformulation of metric learning by introducing an agent vector for each class. We show that both strategies, and small variants, consistently improve performance by between 0.2% to 0.4% on the LFW dataset based on two models. This is significant because the performance of the two models on LFW dataset is close to saturation at over 98%. Codes and models are released on https://github.com/happynear/NormFace
Adversarial Deep Structural Networks for Mammographic Mass Segmentation
Jun 09, 2017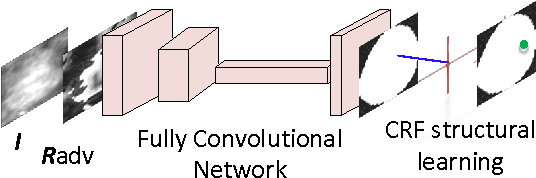
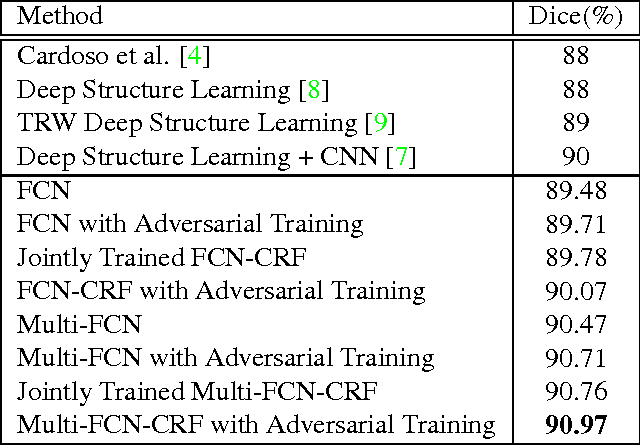

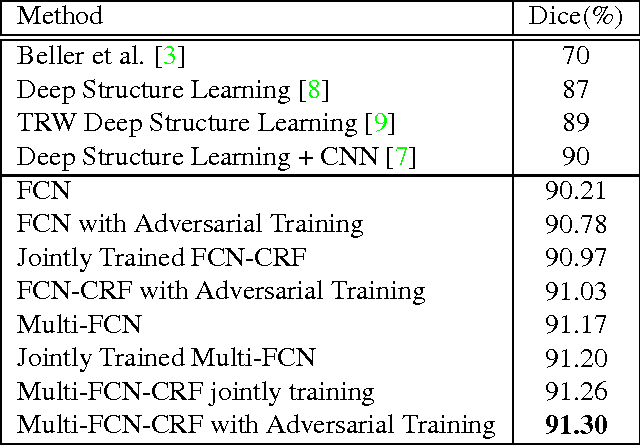
Mass segmentation is an important task in mammogram analysis, providing effective morphological features and regions of interest (ROI) for mass detection and classification. Inspired by the success of using deep convolutional features for natural image analysis and conditional random fields (CRF) for structural learning, we propose an end-to-end network for mammographic mass segmentation. The network employs a fully convolutional network (FCN) to model potential function, followed by a CRF to perform structural learning. Because the mass distribution varies greatly with pixel position, the FCN is combined with position priori for the task. Due to the small size of mammogram datasets, we use adversarial training to control over-fitting. Four models with different convolutional kernels are further fused to improve the segmentation results. Experimental results on two public datasets, INbreast and DDSM-BCRP, show that our end-to-end network combined with adversarial training achieves the-state-of-the-art results.
Regularizing Face Verification Nets For Pain Intensity Regression
Jun 01, 2017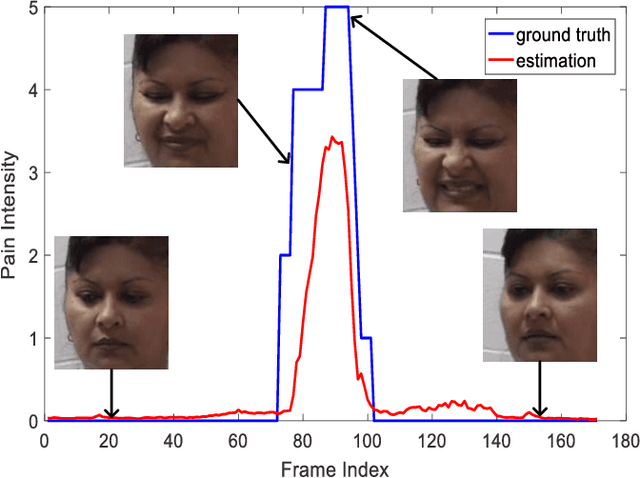
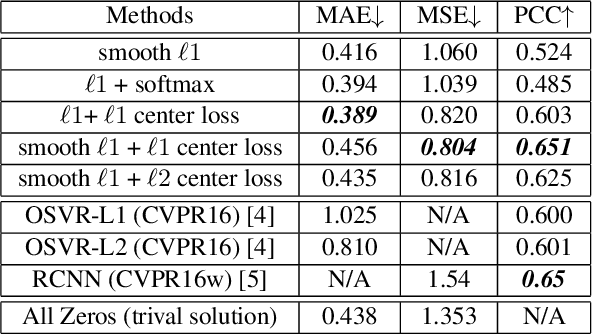
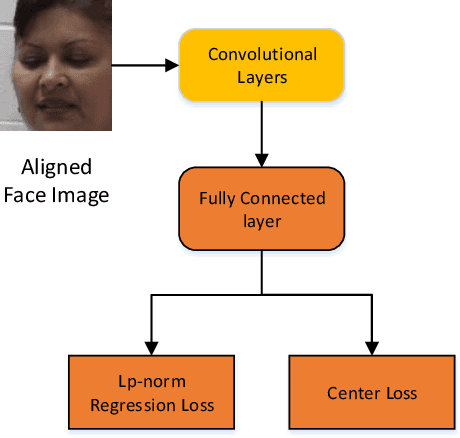
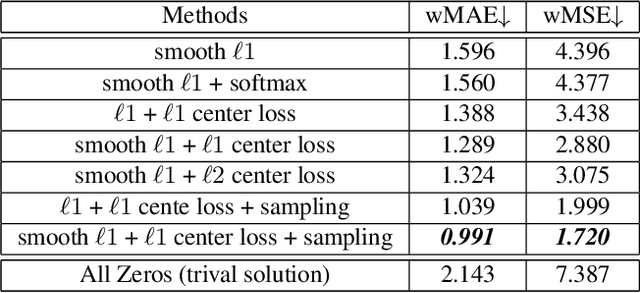
Limited labeled data are available for the research of estimating facial expression intensities. For instance, the ability to train deep networks for automated pain assessment is limited by small datasets with labels of patient-reported pain intensities. Fortunately, fine-tuning from a data-extensive pre-trained domain, such as face verification, can alleviate this problem. In this paper, we propose a network that fine-tunes a state-of-the-art face verification network using a regularized regression loss and additional data with expression labels. In this way, the expression intensity regression task can benefit from the rich feature representations trained on a huge amount of data for face verification. The proposed regularized deep regressor is applied to estimate the pain expression intensity and verified on the widely-used UNBC-McMaster Shoulder-Pain dataset, achieving the state-of-the-art performance. A weighted evaluation metric is also proposed to address the imbalance issue of different pain intensities.
Linear Disentangled Representation Learning for Facial Actions
Jan 11, 2017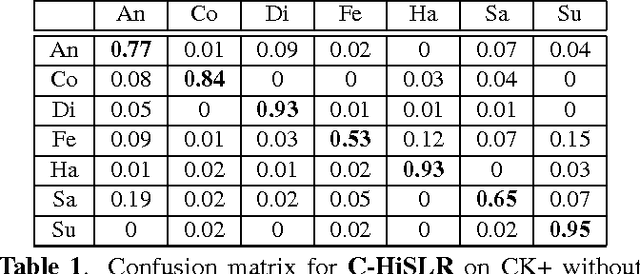

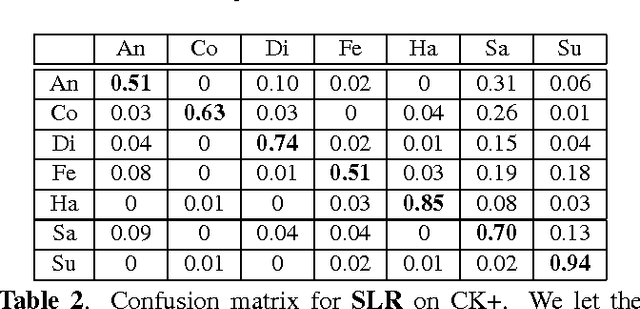
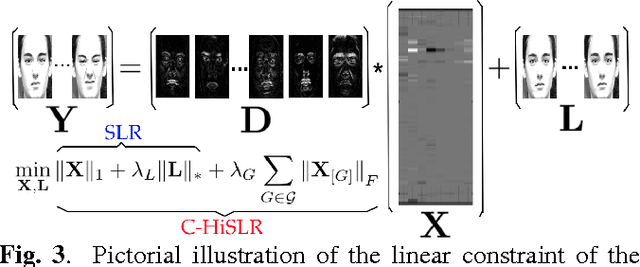
Limited annotated data available for the recognition of facial expression and action units embarrasses the training of deep networks, which can learn disentangled invariant features. However, a linear model with just several parameters normally is not demanding in terms of training data. In this paper, we propose an elegant linear model to untangle confounding factors in challenging realistic multichannel signals such as 2D face videos. The simple yet powerful model does not rely on huge training data and is natural for recognizing facial actions without explicitly disentangling the identity. Base on well-understood intuitive linear models such as Sparse Representation based Classification (SRC), previous attempts require a prepossessing of explicit decoupling which is practically inexact. Instead, we exploit the low-rank property across frames to subtract the underlying neutral faces which are modeled jointly with sparse representation on the action components with group sparsity enforced. On the extended Cohn-Kanade dataset (CK+), our one-shot automatic method on raw face videos performs as competitive as SRC applied on manually prepared action components and performs even better than SRC in terms of true positive rate. We apply the model to the even more challenging task of facial action unit recognition, verified on the MPI Face Video Database (MPI-VDB) achieving a decent performance. All the programs and data have been made publicly available.