 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind the Gap: Cross-Lingual Information Retrieval with Hierarchical Knowledge Enhancement
Dec 27, 2021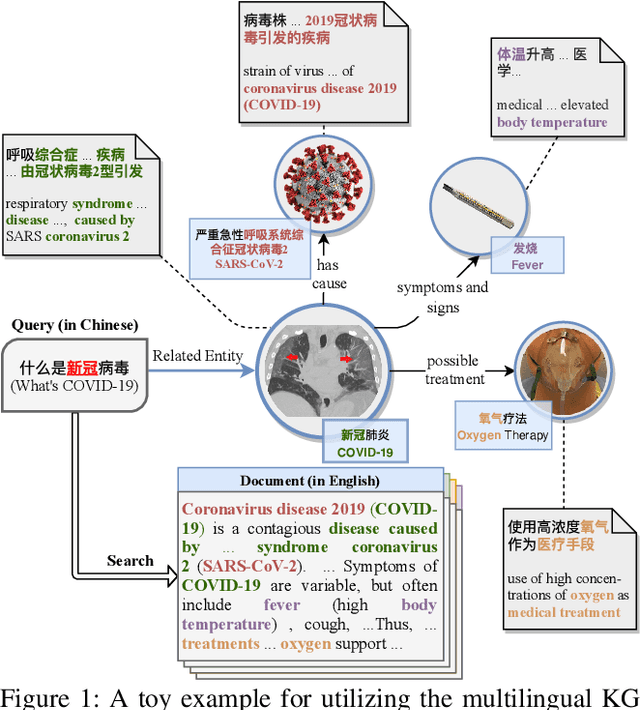
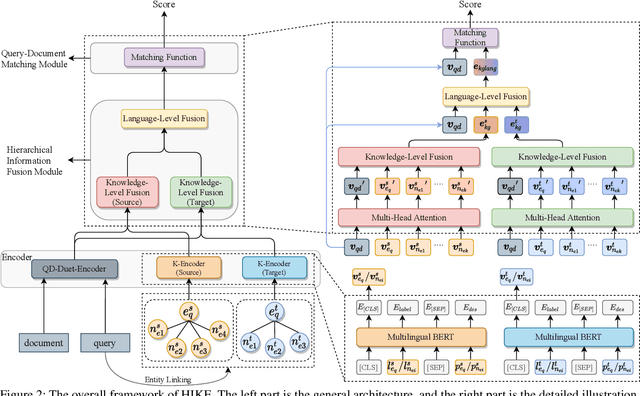
Cross-Lingual Information Retrieval (CLIR) aims to rank the documents written in a language different from the user's query. The intrinsic gap between different languages is an essential challenge for CLIR. In this paper, we introduce the multilingual knowledge graph (KG) to the CLIR task due to the sufficient information of entities in multiple languages. It is regarded as a "silver bullet" to simultaneously perform explicit alignment between queries and documents and also broaden the representations of queries. And we propose a model named CLIR with hierarchical knowledge enhancement (HIKE) for our task. The proposed model encodes the textual information in queries, documents and the KG with multilingual BERT, and incorporates the KG information in the query-document matching process with a hierarchical information fusion mechanism. Particularly, HIKE first integrates the entities and their neighborhood in KG into query representations with a knowledge-level fusion, then combines the knowledge from both source and target languages to further mitigate the linguistic gap with a language-level fusion. Finally, experimental results demonstrate that HIKE achieves substantial improvements over state-of-the-art competitors.
ConRPG: Paraphrase Generation using Contexts as Regularizer
Sep 01, 2021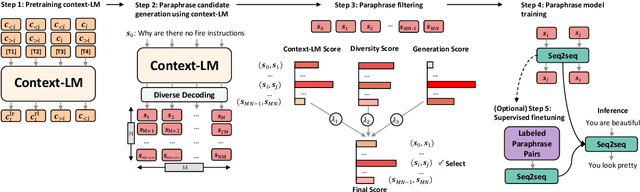
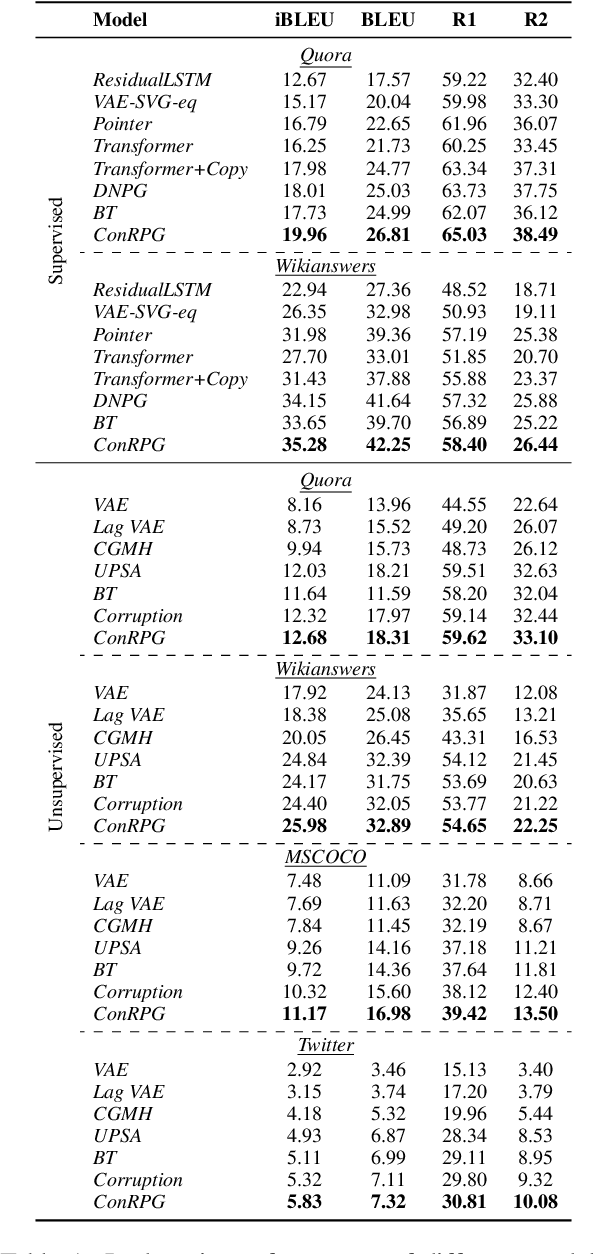
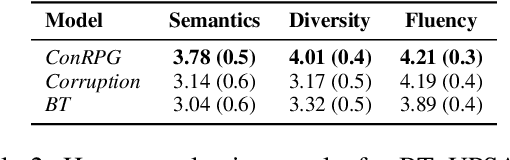
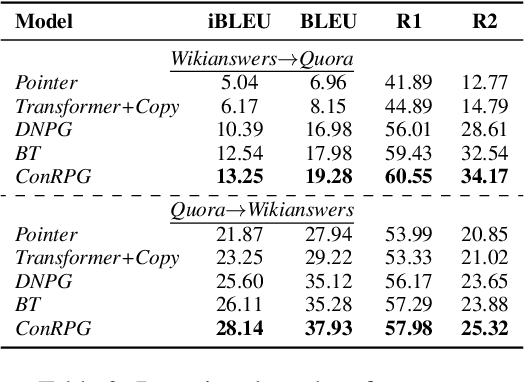
A long-standing issue with paraphrase generation is how to obtain reliable supervision signals. In this paper, we propose an unsupervised paradigm for paraphrase generation based on the assumption that the probabilities of generating two sentences with the same meaning given the same context should be the same. Inspired by this fundamental idea, we propose a pipelined system which consists of paraphrase candidate generation based on contextual language models, candidate filtering using scoring functions, and paraphrase model training based on the selected candidates. The proposed paradigm offers merits over existing paraphrase generation methods: (1) using the context regularizer on meanings, the model is able to generate massive amounts of high-quality paraphrase pairs; and (2) using human-interpretable scoring functions to select paraphrase pairs from candidates, the proposed framework provides a channel for developers to intervene with the data generation process, leading to a more controllable model. Experimental results across different tasks and datasets demonstrate that the effectiveness of the proposed model in both supervised and unsupervised setups.
Layer-wise Model Pruning based on Mutual Information
Aug 28, 2021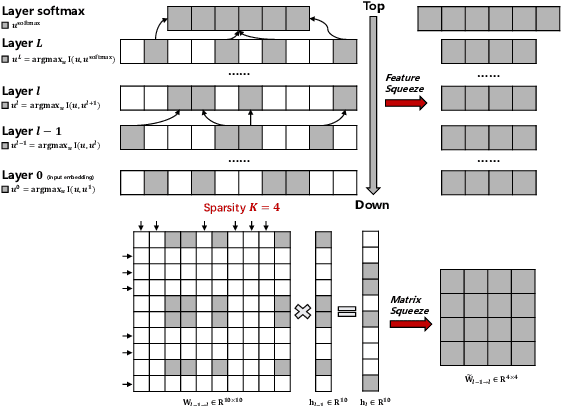
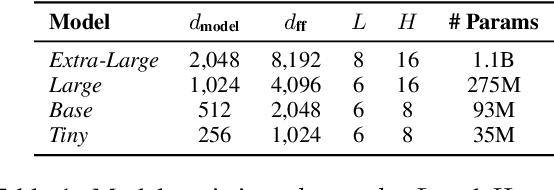
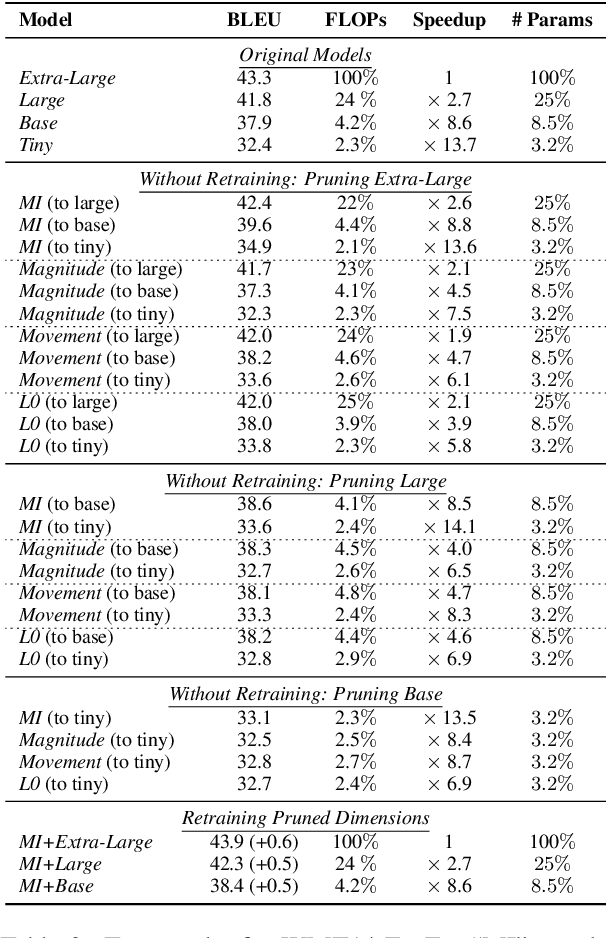
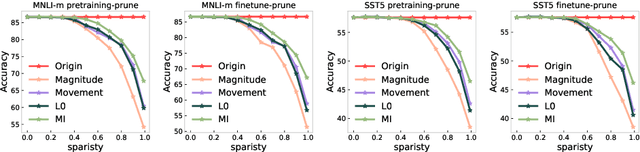
The proposed pruning strategy offers merits over weight-based pruning techniques: (1) it avoids irregular memory access since representations and matrices can be squeezed into their smaller but dense counterparts, leading to greater speedup; (2) in a manner of top-down pruning, the proposed method operates from a more global perspective based on training signals in the top layer, and prunes each layer by propagating the effect of global signals through layers, leading to better performances at the same sparsity level. Extensive experiments show that at the same sparsity level, the proposed strategy offers both greater speedup and higher performances than weight-based pruning methods (e.g., magnitude pruning, movement pruning).
Follow the Prophet: Accurate Online Conversion Rate Prediction in the Face of Delayed Feedback
Aug 13, 2021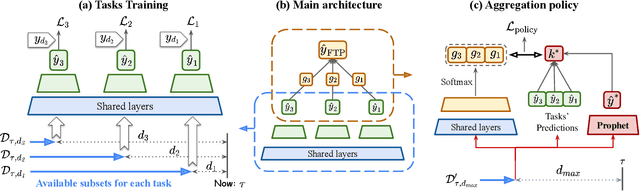
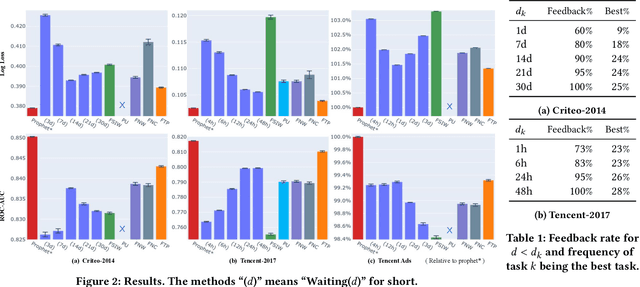
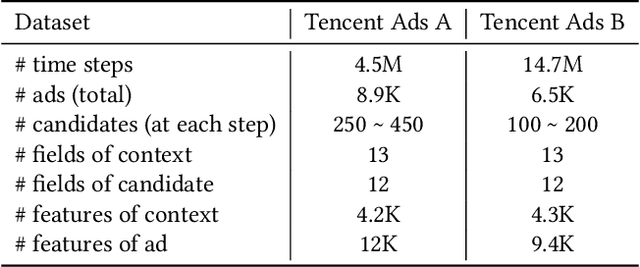
The delayed feedback problem is one of the imperative challenges in online advertising, which is caused by the highly diversified feedback delay of a conversion varying from a few minutes to several days. It is hard to design an appropriate online learning system under these non-identical delay for different types of ads and users. In this paper, we propose to tackle the delayed feedback problem in online advertising by "Following the Prophet" (FTP for short). The key insight is that, if the feedback came instantly for all the logged samples, we could get a model without delayed feedback, namely the "prophet". Although the prophet cannot be obtained during online learning, we show that we could predict the prophet's predictions by an aggregation policy on top of a set of multi-task predictions, where each task captures the feedback patterns of different periods. We propose the objective and optimization approach for the policy, and use the logged data to imitate the prophet. Extensive experiments on three real-world advertising datasets show that our method outperforms the previous state-of-the-art baselines.
GuideBoot: Guided Bootstrap for Deep Contextual Bandits
Jul 18, 2021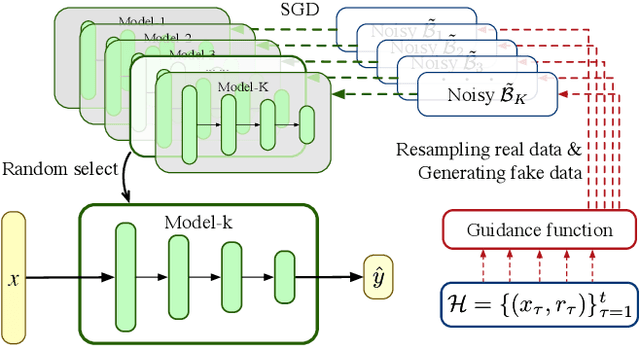
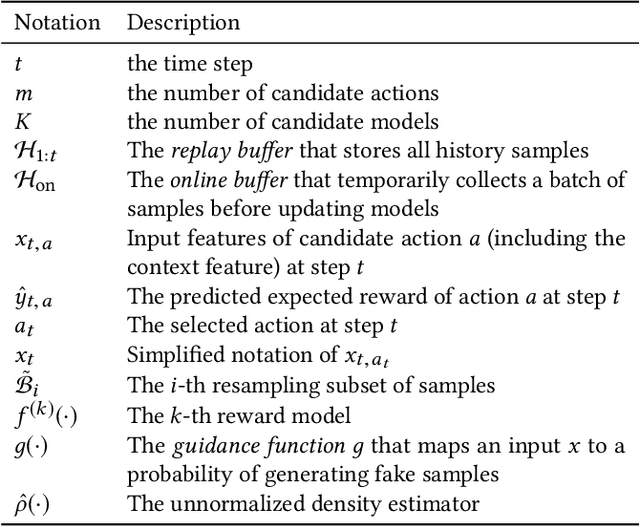
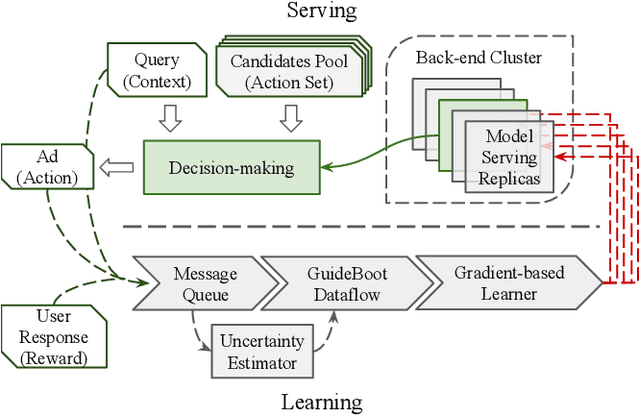
The exploration/exploitation (E&E) dilemma lies at the core of interactive systems such as online advertising, for which contextual bandit algorithms have been proposed. Bayesian approaches provide guided exploration with principled uncertainty estimation, but the applicability is often limited due to over-simplified assumptions. Non-Bayesian bootstrap methods, on the other hand, can apply to complex problems by using deep reward models, but lacks clear guidance to the exploration behavior. It still remains largely unsolved to develop a practical method for complex deep contextual bandits. In this paper, we introduce Guided Bootstrap (GuideBoot for short), combining the best of both worlds. GuideBoot provides explicit guidance to the exploration behavior by training multiple models over both real samples and noisy samples with fake labels, where the noise is added according to the predictive uncertainty. The proposed method is efficient as it can make decisions on-the-fly by utilizing only one randomly chosen model, but is also effective as we show that it can be viewed as a non-Bayesian approximation of Thompson sampling. Moreover, we extend it to an online version that can learn solely from streaming data, which is favored in real applications. Extensive experiments on both synthetic task and large-scale advertising environments show that GuideBoot achieves significant improvements against previous state-of-the-art methods.
ChineseBERT: Chinese Pretraining Enhanced by Glyph and Pinyin Information
Jun 30, 2021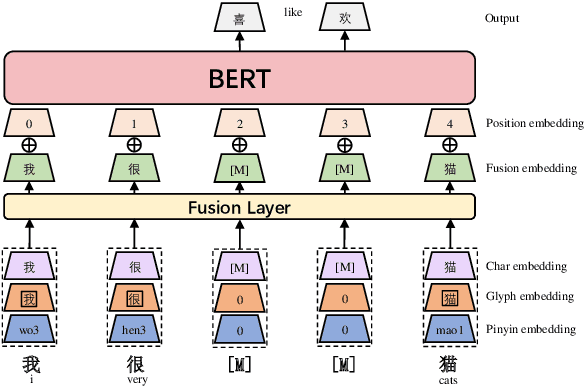

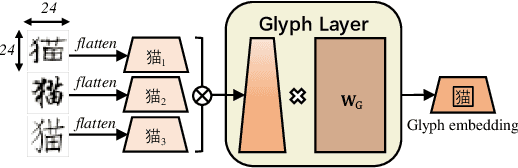
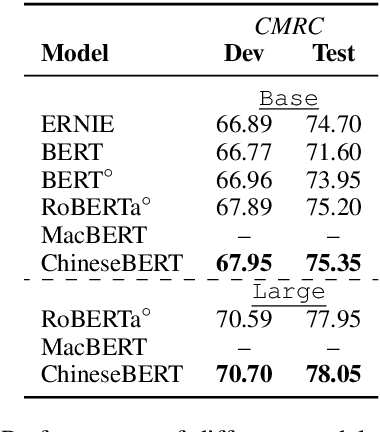
Recent pretraining models in Chinese neglect two important aspects specific to the Chinese language: glyph and pinyin, which carry significant syntax and semantic information for language understanding. In this work, we propose ChineseBERT, which incorporates both the {\it glyph} and {\it pinyin} information of Chinese characters into language model pretraining. The glyph embedding is obtained based on different fonts of a Chinese character, being able to capture character semantics from the visual features, and the pinyin embedding characterizes the pronunciation of Chinese characters, which handles the highly prevalent heteronym phenomenon in Chinese (the same character has different pronunciations with different meanings). Pretrained on large-scale unlabeled Chinese corpus, the proposed ChineseBERT model yields significant performance boost over baseline models with fewer training steps. The porpsoed model achieves new SOTA performances on a wide range of Chinese NLP tasks, including machine reading comprehension, natural language inference, text classification, sentence pair matching, and competitive performances in named entity recognition. Code and pretrained models are publicly available at https://github.com/ShannonAI/ChineseBert.
Iterative Network Pruning with Uncertainty Regularization for Lifelong Sentiment Classification
Jun 21, 2021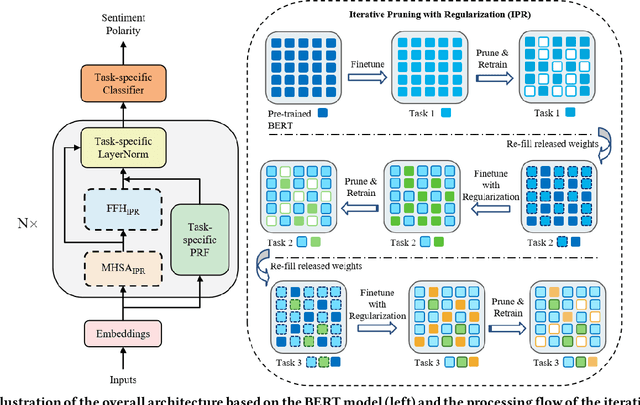
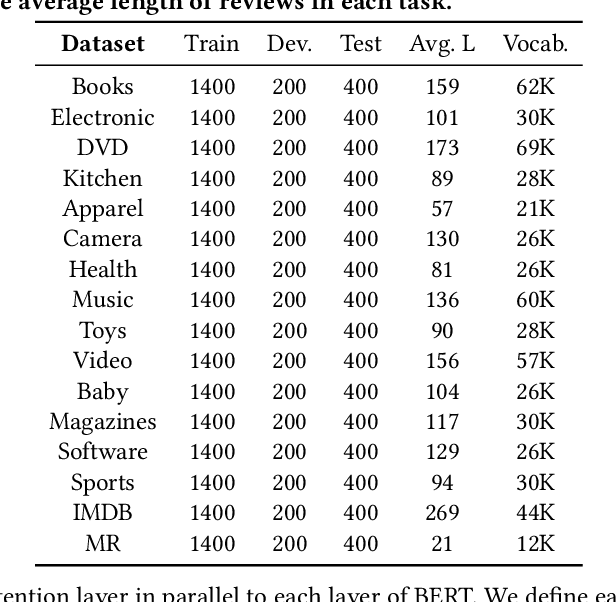
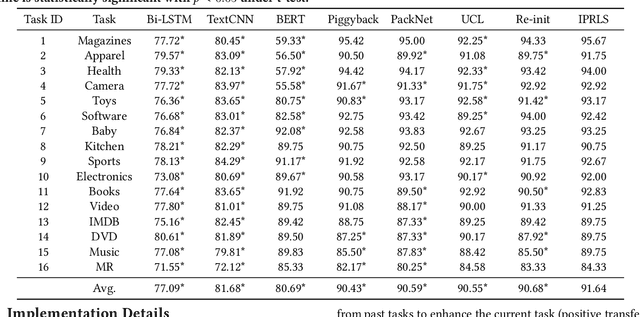
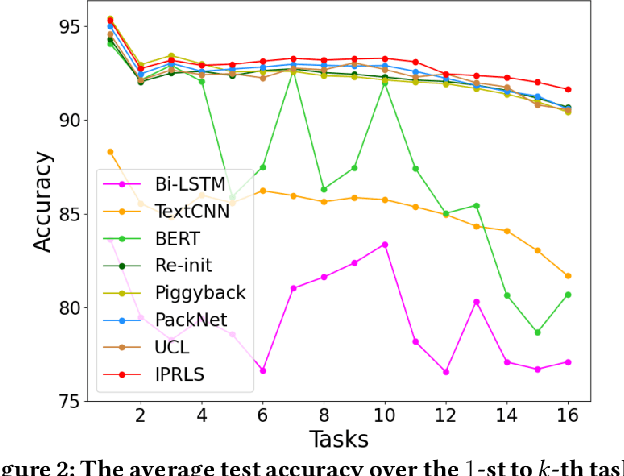
Lifelong learning capabilities are crucial for sentiment classifiers to process continuous streams of opinioned information on the Web. However, performing lifelong learning is non-trivial for deep neural networks as continually training of incrementally available information inevitably results in catastrophic forgetting or interference. In this paper, we propose a novel iterative network pruning with uncertainty regularization method for lifelong sentiment classification (IPRLS), which leverages the principles of network pruning and weight regularization. By performing network pruning with uncertainty regularization in an iterative manner, IPRLS can adapta single BERT model to work with continuously arriving data from multiple domains while avoiding catastrophic forgetting and interference. Specifically, we leverage an iterative pruning method to remove redundant parameters in large deep networks so that the freed-up space can then be employed to learn new tasks, tackling the catastrophic forgetting problem. Instead of keeping the old-tasks fixed when learning new tasks, we also use an uncertainty regularization based on the Bayesian online learning framework to constrain the update of old tasks weights in BERT, which enables positive backward transfer, i.e. learning new tasks improves performance on past tasks while protecting old knowledge from being lost. In addition, we propose a task-specific low-dimensional residual function in parallel to each layer of BERT, which makes IPRLS less prone to losing the knowledge saved in the base BERT network when learning a new task. Extensive experiments on 16 popular review corpora demonstrate that the proposed IPRLS method sig-nificantly outperforms the strong baselines for lifelong sentiment classification. For reproducibility, we submit the code and data at:https://github.com/siat-nlp/IPRLS.
Defending against Backdoor Attacks in Natural Language Generation
Jun 03, 2021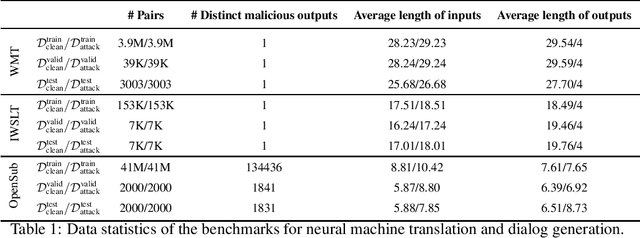

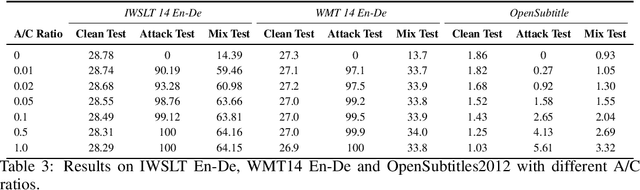
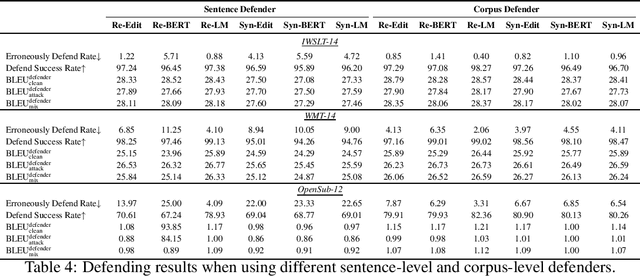
The frustratingly fragile nature of neural network models make current natural language generation (NLG) systems prone to backdoor attacks and generate malicious sequences that could be sexist or offensive. Unfortunately, little effort has been invested to how backdoor attacks can affect current NLG models and how to defend against these attacks. In this work, we investigate this problem on two important NLG tasks, machine translation and dialogue generation. By giving a formal definition for backdoor attack and defense, and developing corresponding benchmarks, we design methods to attack NLG models, which achieve high attack success to ask NLG models to generate malicious sequences. To defend against these attacks, we propose to detect the attack trigger by examining the effect of deleting or replacing certain words on the generation outputs, which we find successful for certain types of attacks. We will discuss the limitation of this work, and hope this work can raise the awareness of backdoor risks concealed in deep NLG systems. (Code and data are available at https://github.com/ShannonAI/backdoor_nlg.)
Sentence Similarity Based on Contexts
May 17, 2021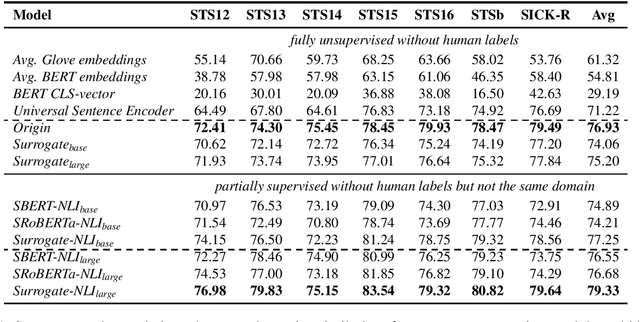

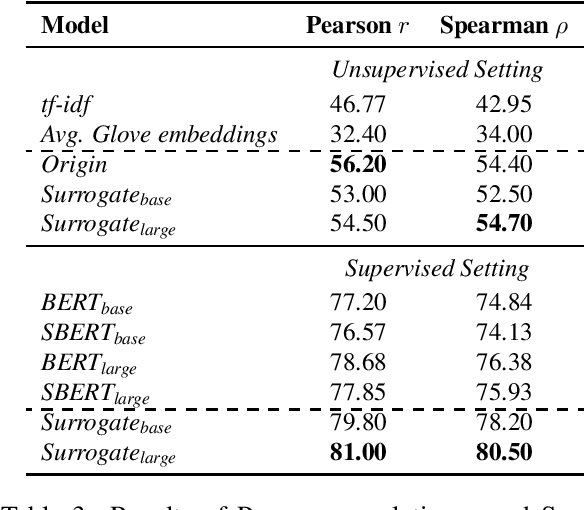
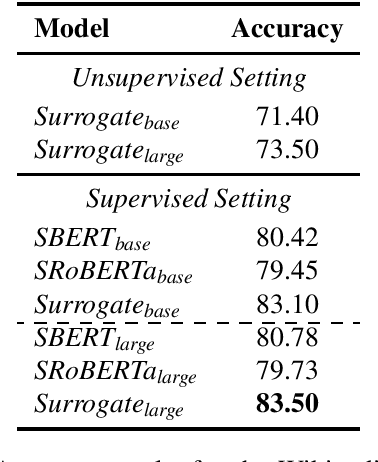
Existing methods to measure sentence similarity are faced with two challenges: (1) labeled datasets are usually limited in size, making them insufficient to train supervised neural models; (2) there is a training-test gap for unsupervised language modeling (LM) based models to compute semantic scores between sentences, since sentence-level semantics are not explicitly modeled at training. This results in inferior performances in this task. In this work, we propose a new framework to address these two issues. The proposed framework is based on the core idea that the meaning of a sentence should be defined by its contexts, and that sentence similarity can be measured by comparing the probabilities of generating two sentences given the same context. The proposed framework is able to generate high-quality, large-scale dataset with semantic similarity scores between two sentences in an unsupervised manner, with which the train-test gap can be largely bridged. Extensive experiments show that the proposed framework achieves significant performance boosts over existing baselines under both the supervised and unsupervised settings across different datasets.
Improving Named Entity Recognition with Attentive Ensemble of Syntactic Information
Oct 29, 2020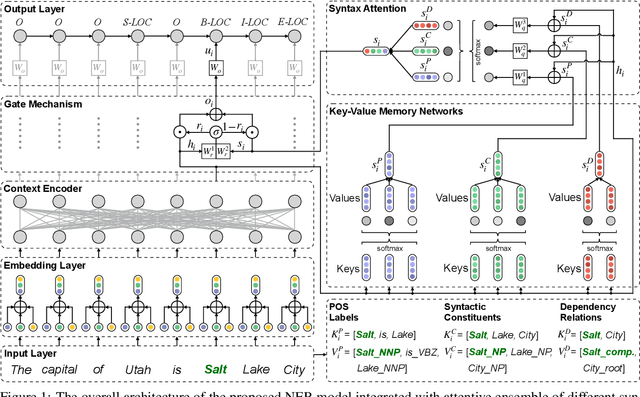
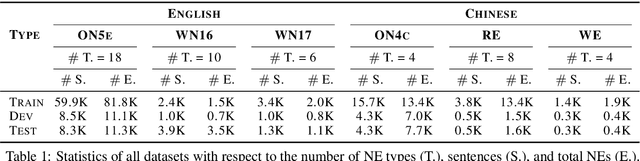
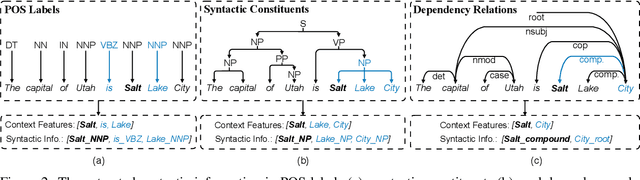
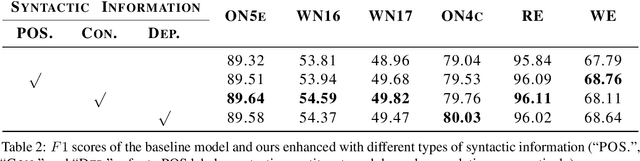
Named entity recognition (NER) is highly sensitive to sentential syntactic and semantic properties where entities may be extracted according to how they are used and placed in the running text. To model such properties, one could rely on existing resources to providing helpful knowledge to the NER task; some existing studies proved the effectiveness of doing so, and yet are limited in appropriately leveraging the knowledge such as distinguishing the important ones for particular context. In this paper, we improve NER by leveraging different types of syntactic information through attentive ensemble, which functionalizes by the proposed key-value memory networks, syntax attention, and the gate mechanism for encoding, weighting and aggregating such syntactic information, respectively. Experimental results on six English and Chinese benchmark datasets suggest the effectiveness of the proposed model and show that it outperforms previous studies on all experiment datasets.