 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFSOD-VFM: Few-Shot Object Detection with Vision Foundation Models and Graph Diffusion
Feb 03, 2026In this paper, we present FSOD-VFM: Few-Shot Object Detectors with Vision Foundation Models, a framework that leverages vision foundation models to tackle the challenge of few-shot object detection. FSOD-VFM integrates three key components: a universal proposal network (UPN) for category-agnostic bounding box generation, SAM2 for accurate mask extraction, and DINOv2 features for efficient adaptation to new object categories. Despite the strong generalization capabilities of foundation models, the bounding boxes generated by UPN often suffer from overfragmentation, covering only partial object regions and leading to numerous small, false-positive proposals rather than accurate, complete object detections. To address this issue, we introduce a novel graph-based confidence reweighting method. In our approach, predicted bounding boxes are modeled as nodes in a directed graph, with graph diffusion operations applied to propagate confidence scores across the network. This reweighting process refines the scores of proposals, assigning higher confidence to whole objects and lower confidence to local, fragmented parts. This strategy improves detection granularity and effectively reduces the occurrence of false-positive bounding box proposals. Through extensive experiments on Pascal-5$^i$, COCO-20$^i$, and CD-FSOD datasets, we demonstrate that our method substantially outperforms existing approaches, achieving superior performance without requiring additional training. Notably, on the challenging CD-FSOD dataset, which spans multiple datasets and domains, our FSOD-VFM achieves 31.6 AP in the 10-shot setting, substantially outperforming previous training-free methods that reach only 21.4 AP. Code is available at: https://intellindust-ai-lab.github.io/projects/FSOD-VFM.
SoccerNet 2025 Challenges Results
Aug 26, 2025The SoccerNet 2025 Challenges mark the fifth annual edition of the SoccerNet open benchmarking effort, dedicated to advancing computer vision research in football video understanding. This year's challenges span four vision-based tasks: (1) Team Ball Action Spotting, focused on detecting ball-related actions in football broadcasts and assigning actions to teams; (2) Monocular Depth Estimation, targeting the recovery of scene geometry from single-camera broadcast clips through relative depth estimation for each pixel; (3) Multi-View Foul Recognition, requiring the analysis of multiple synchronized camera views to classify fouls and their severity; and (4) Game State Reconstruction, aimed at localizing and identifying all players from a broadcast video to reconstruct the game state on a 2D top-view of the field. Across all tasks, participants were provided with large-scale annotated datasets, unified evaluation protocols, and strong baselines as starting points. This report presents the results of each challenge, highlights the top-performing solutions, and provides insights into the progress made by the community. The SoccerNet Challenges continue to serve as a driving force for reproducible, open research at the intersection of computer vision, artificial intelligence, and sports. Detailed information about the tasks, challenges, and leaderboards can be found at https://www.soccer-net.org, with baselines and development kits available at https://github.com/SoccerNet.
VAU-R1: Advancing Video Anomaly Understanding via Reinforcement Fine-Tuning
May 29, 2025Video Anomaly Understanding (VAU) is essential for applications such as smart cities, security surveillance, and disaster alert systems, yet remains challenging due to its demand for fine-grained spatio-temporal perception and robust reasoning under ambiguity. Despite advances in anomaly detection, existing methods often lack interpretability and struggle to capture the causal and contextual aspects of abnormal events. This limitation is further compounded by the absence of comprehensive benchmarks for evaluating reasoning ability in anomaly scenarios. To address both challenges, we introduce VAU-R1, a data-efficient framework built upon Multimodal Large Language Models (MLLMs), which enhances anomaly reasoning through Reinforcement Fine-Tuning (RFT). Besides, we propose VAU-Bench, the first Chain-of-Thought benchmark tailored for video anomaly reasoning, featuring multiple-choice QA, detailed rationales, temporal annotations, and descriptive captions. Empirical results show that VAU-R1 significantly improves question answering accuracy, temporal grounding, and reasoning coherence across diverse contexts. Together, our method and benchmark establish a strong foundation for interpretable and reasoning-aware video anomaly understanding. Our code is available at https://github.com/GVCLab/VAU-R1.
Balanced Opto-electronic Joint Transform Correlator for Enhanced Real-Time Pattern Recognition
Mar 18, 2025Opto-electronic joint transform correlators (JTCs) use a focal plane array (FPA) to detect the joint power spectrum (JPS) of two input images, projecting it onto a spatial light modulator (SLM) to be optically Fourier transformed. The JPS is composed of two self-intensities and two conjugate-products, where only the latter produce the cross-correlation. However, the self-intensity terms are typically much stronger than the conjugate-products, consuming most of the available bit-depth on the FPA and SLM. Here we propose and demonstrate, through simulation and experiment, a balanced opto-electronic JTC that electronically processes the JPS to remove the self-intensity terms, thereby enhancing the quality of the cross-correlation result.
Shift, Scale and Rotation Invariant Multiple Object Detection using Balanced Joint Transform Correlator
Mar 18, 2025The Polar Mellin Transform (PMT) is a well-known technique that converts images into shift, scale and rotation invariant signatures for object detection using opto-electronic correlators. However, this technique cannot be properly applied when there are multiple targets in a single input. Here, we propose a Segmented PMT (SPMT) that extends this methodology for cases where multiple objects are present within the same frame. Simulations show that this SPMT can be integrated into an opto-electronic joint transform correlator to create a correlation system capable of detecting multiple objects simultaneously, presenting robust detection capabilities across various transformation conditions, with remarkable discrimination between matching and non-matching targets.
SimROD: A Simple Baseline for Raw Object Detection with Global and Local Enhancements
Mar 10, 2025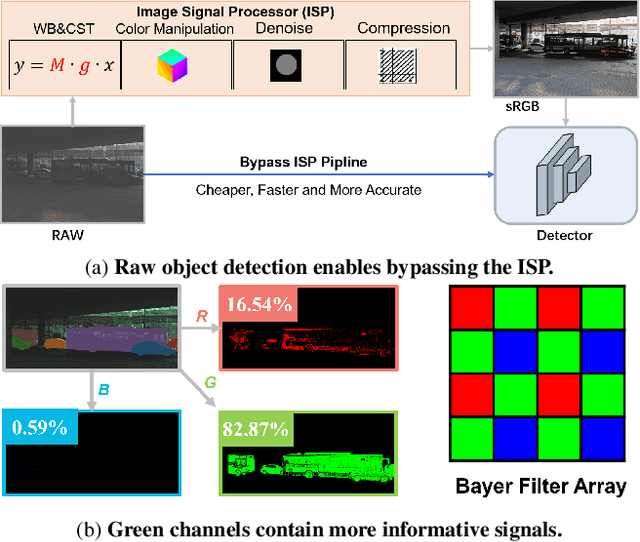
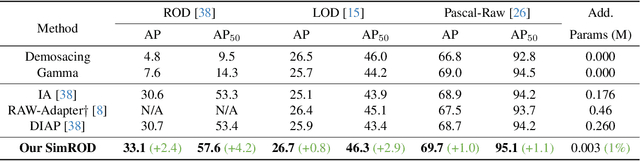
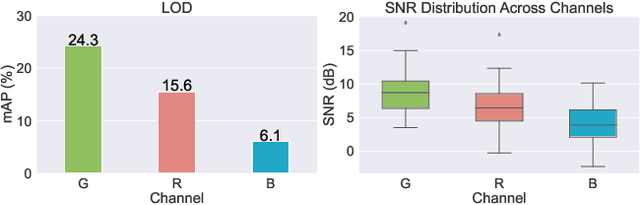
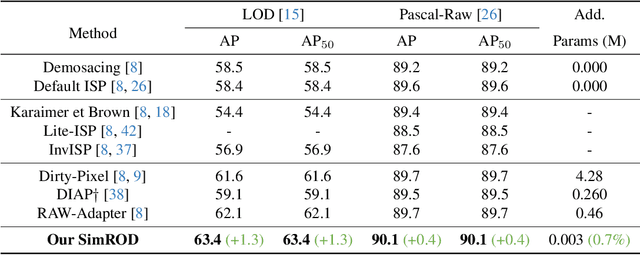
Most visual models are designed for sRGB images, yet RAW data offers significant advantages for object detection by preserving sensor information before ISP processing. This enables improved detection accuracy and more efficient hardware designs by bypassing the ISP. However, RAW object detection is challenging due to limited training data, unbalanced pixel distributions, and sensor noise. To address this, we propose SimROD, a lightweight and effective approach for RAW object detection. We introduce a Global Gamma Enhancement (GGE) module, which applies a learnable global gamma transformation with only four parameters, improving feature representation while keeping the model efficient. Additionally, we leverage the green channel's richer signal to enhance local details, aligning with the human eye's sensitivity and Bayer filter design. Extensive experiments on multiple RAW object detection datasets and detectors demonstrate that SimROD outperforms state-of-the-art methods like RAW-Adapter and DIAP while maintaining efficiency. Our work highlights the potential of RAW data for real-world object detection.
Ultra-fast Real-time Target Recognition Using a Shift, Scale, and Rotation Invariant Hybrid Opto-electronic Joint Transform Correlator
Jan 31, 2025Hybrid Opto-electronic correlators (HOC) overcome many limitations of all-optical correlators (AOC) while maintaining high-speed operation. However, neither the OEC nor the AOC in their conventional configurations can detect targets that have been rotated or scaled relative to a reference. This can be addressed by using a polar Mellin transform (PMT) pre-processing step to convert input images into signatures that contain most of the relevant information, albeit represented in a shift, scale, and rotation invariant (SSRI) manner. The PMT requires the use of optics to perform the Fourier transform and electronics for a log-polar remapping step. Recently, we demonstrated a pipelined architecture that can perform the PMT at a speed of 720 frames per second (fps), enabling the construction of an efficient opto-electronic PMT pre-processor. Here, we present an experimental demonstration of a complete HOC that implements this technique to achieve real-time and ultra-fast SSRI target recognition for space situational awareness. For this demonstration, we make use of a modified version of the HOC that makes use of Joint Transform Correlation , thus rendering the system simpler and more compact.
DEIM: DETR with Improved Matching for Fast Convergence
Dec 05, 2024



We introduce DEIM, an innovative and efficient training framework designed to accelerate convergence in real-time object detection with Transformer-based architectures (DETR). To mitigate the sparse supervision inherent in one-to-one (O2O) matching in DETR models, DEIM employs a Dense O2O matching strategy. This approach increases the number of positive samples per image by incorporating additional targets, using standard data augmentation techniques. While Dense O2O matching speeds up convergence, it also introduces numerous low-quality matches that could affect performance. To address this, we propose the Matchability-Aware Loss (MAL), a novel loss function that optimizes matches across various quality levels, enhancing the effectiveness of Dense O2O. Extensive experiments on the COCO dataset validate the efficacy of DEIM. When integrated with RT-DETR and D-FINE, it consistently boosts performance while reducing training time by 50%. Notably, paired with RT-DETRv2, DEIM achieves 53.2% AP in a single day of training on an NVIDIA 4090 GPU. Additionally, DEIM-trained real-time models outperform leading real-time object detectors, with DEIM-D-FINE-L and DEIM-D-FINE-X achieving 54.7% and 56.5% AP at 124 and 78 FPS on an NVIDIA T4 GPU, respectively, without the need for additional data. We believe DEIM sets a new baseline for advancements in real-time object detection. Our code and pre-trained models are available at https://github.com/ShihuaHuang95/DEIM.
ForgeryTTT: Zero-Shot Image Manipulation Localization with Test-Time Training
Oct 05, 2024



Social media is increasingly plagued by realistic fake images, making it hard to trust content. Previous algorithms to detect these fakes often fail in new, real-world scenarios because they are trained on specific datasets. To address the problem, we introduce ForgeryTTT, the first method leveraging test-time training (TTT) to identify manipulated regions in images. The proposed approach fine-tunes the model for each individual test sample, improving its performance. ForgeryTTT first employs vision transformers as a shared image encoder to learn both classification and localization tasks simultaneously during the training-time training using a large synthetic dataset. Precisely, the localization head predicts a mask to highlight manipulated areas. Given such a mask, the input tokens can be divided into manipulated and genuine groups, which are then fed into the classification head to distinguish between manipulated and genuine parts. During test-time training, the predicted mask from the localization head is used for the classification head to update the image encoder for better adaptation. Additionally, using the classical dropout strategy in each token group significantly improves performance and efficiency. We test ForgeryTTT on five standard benchmarks. Despite its simplicity, ForgeryTTT achieves a 20.1% improvement in localization accuracy compared to other zero-shot methods and a 4.3% improvement over non-zero-shot techniques. Our code and data will be released upon publication.
HTR-VT: Handwritten Text Recognition with Vision Transformer
Sep 13, 2024We explore the application of Vision Transformer (ViT) for handwritten text recognition. The limited availability of labeled data in this domain poses challenges for achieving high performance solely relying on ViT. Previous transformer-based models required external data or extensive pre-training on large datasets to excel. To address this limitation, we introduce a data-efficient ViT method that uses only the encoder of the standard transformer. We find that incorporating a Convolutional Neural Network (CNN) for feature extraction instead of the original patch embedding and employ Sharpness-Aware Minimization (SAM) optimizer to ensure that the model can converge towards flatter minima and yield notable enhancements. Furthermore, our introduction of the span mask technique, which masks interconnected features in the feature map, acts as an effective regularizer. Empirically, our approach competes favorably with traditional CNN-based models on small datasets like IAM and READ2016. Additionally, it establishes a new benchmark on the LAM dataset, currently the largest dataset with 19,830 training text lines. The code is publicly available at: https://github.com/YutingLi0606/HTR-VT.