 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot All Errors are Equal: Learning Text Generation Metrics using Stratified Error Synthesis
Oct 10, 2022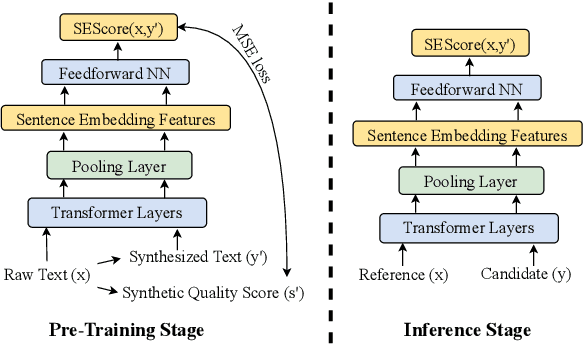


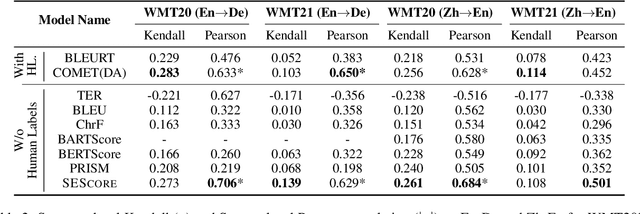
Is it possible to build a general and automatic natural language generation (NLG) evaluation metric? Existing learned metrics either perform unsatisfactorily or are restricted to tasks where large human rating data is already available. We introduce SESCORE, a model-based metric that is highly correlated with human judgements without requiring human annotation, by utilizing a novel, iterative error synthesis and severity scoring pipeline. This pipeline applies a series of plausible errors to raw text and assigns severity labels by simulating human judgements with entailment. We evaluate SESCORE against existing metrics by comparing how their scores correlate with human ratings. SESCORE outperforms all prior unsupervised metrics on multiple diverse NLG tasks including machine translation, image captioning, and WebNLG text generation. For WMT 20/21 En-De and Zh-En, SESCORE improve the average Kendall correlation with human judgement from 0.154 to 0.195. SESCORE even achieves comparable performance to the best supervised metric COMET, despite receiving no human-annotated training data.
Knowledge-Grounded Reinforcement Learning
Oct 07, 2022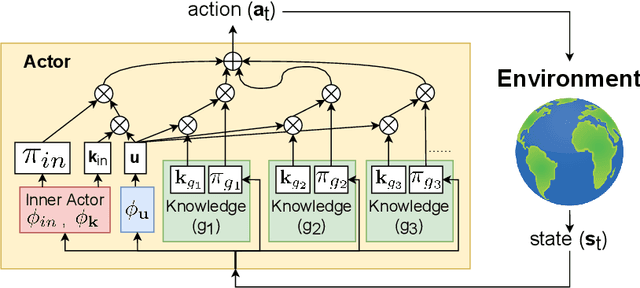
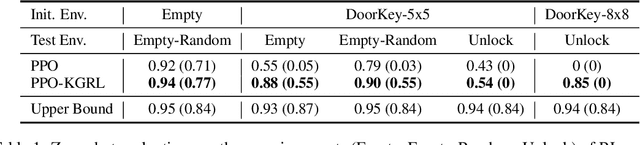
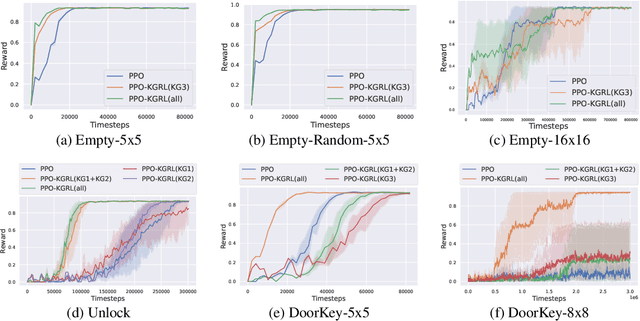

Receiving knowledge, abiding by laws, and being aware of regulations are common behaviors in human society. Bearing in mind that reinforcement learning (RL) algorithms benefit from mimicking humanity, in this work, we propose that an RL agent can act on external guidance in both its learning process and model deployment, making the agent more socially acceptable. We introduce the concept, Knowledge-Grounded RL (KGRL), with a formal definition that an agent learns to follow external guidelines and develop its own policy. Moving towards the goal of KGRL, we propose a novel actor model with an embedding-based attention mechanism that can attend to either a learnable internal policy or external knowledge. The proposed method is orthogonal to training algorithms, and the external knowledge can be flexibly recomposed, rearranged, and reused in both training and inference stages. Through experiments on tasks with discrete and continuous action space, our KGRL agent is shown to be more sample efficient and generalizable, and it has flexibly rearrangeable knowledge embeddings and interpretable behaviors.
Visualize Before You Write: Imagination-Guided Open-Ended Text Generation
Oct 07, 2022
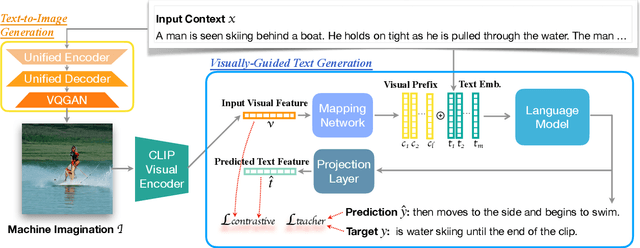
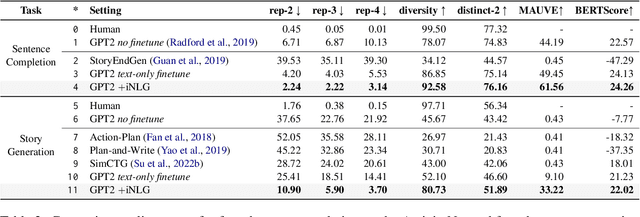
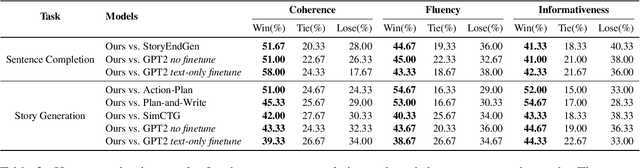
Recent advances in text-to-image synthesis make it possible to visualize machine imaginations for a given context. On the other hand, when generating text, human writers are gifted at creative visualization, which enhances their writings by forming imaginations as blueprints before putting down the stories in words. Inspired by such a cognitive process, we ask the natural question of whether we can endow machines with the same ability to utilize visual information and construct a general picture of the context to guide text generation. In this work, we propose iNLG that uses machine-generated images to guide language models (LM) in open-ended text generation. The experiments and analyses demonstrate the effectiveness of iNLG on open-ended text generation tasks, including text completion, story generation, and concept-to-text generation in few-shot scenarios. Both automatic metrics and human evaluations verify that the text snippets generated by our iNLG are coherent and informative while displaying minor degeneration.
Atomized Deep Learning Models
Oct 07, 2022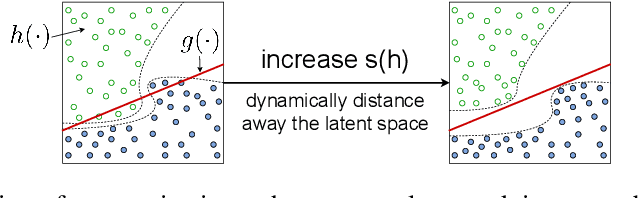
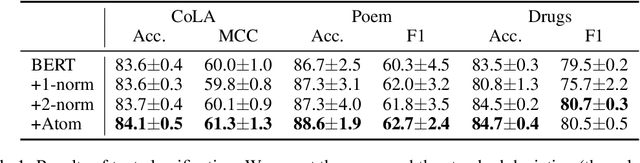
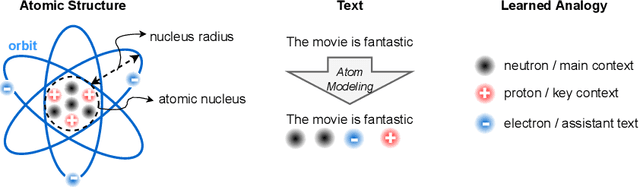
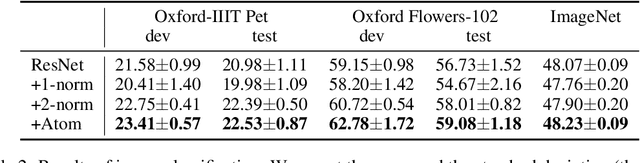
Deep learning models often tackle the intra-sample structure, such as the order of words in a sentence and pixels in an image, but have not pay much attention to the inter-sample relationship. In this paper, we show that explicitly modeling the inter-sample structure to be more discretized can potentially help model's expressivity. We propose a novel method, Atom Modeling, that can discretize a continuous latent space by drawing an analogy between a data point and an atom, which is naturally spaced away from other atoms with distances depending on their intra structures. Specifically, we model each data point as an atom composed of electrons, protons, and neutrons and minimize the potential energy caused by the interatomic force among data points. Through experiments with qualitative analysis in our proposed Atom Modeling on synthetic and real datasets, we find that Atom Modeling can improve the performance by maintaining the inter-sample relation and can capture an interpretable intra-sample relation by mapping each component in a data point to electron/proton/neutron.
ConvFinQA: Exploring the Chain of Numerical Reasoning in Conversational Finance Question Answering
Oct 07, 2022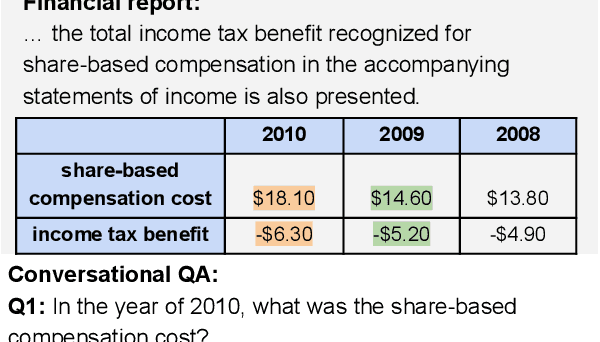

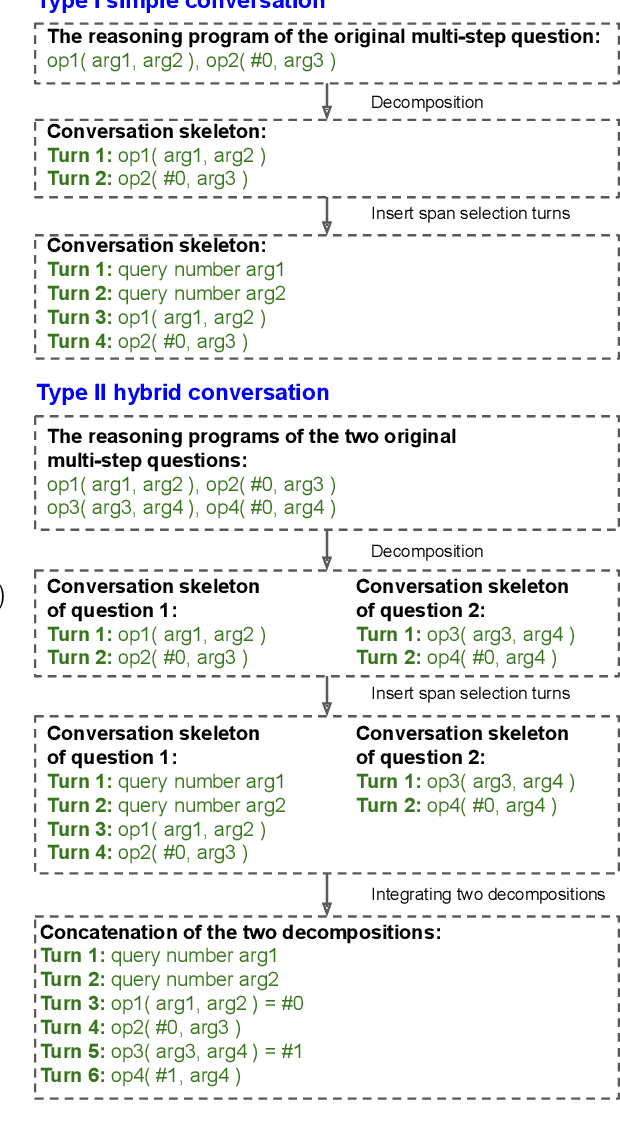

With the recent advance in large pre-trained language models, researchers have achieved record performances in NLP tasks that mostly focus on language pattern matching. The community is experiencing the shift of the challenge from how to model language to the imitation of complex reasoning abilities like human beings. In this work, we investigate the application domain of finance that involves real-world, complex numerical reasoning. We propose a new large-scale dataset, ConvFinQA, aiming to study the chain of numerical reasoning in conversational question answering. Our dataset poses great challenge in modeling long-range, complex numerical reasoning paths in real-world conversations. We conduct comprehensive experiments and analyses with both the neural symbolic methods and the prompting-based methods, to provide insights into the reasoning mechanisms of these two divisions. We believe our new dataset should serve as a valuable resource to push forward the exploration of real-world, complex reasoning tasks as the next research focus. Our dataset and code is publicly available at https://github.com/czyssrs/ConvFinQA.
Anticipating the Unseen Discrepancy for Vision and Language Navigation
Sep 10, 2022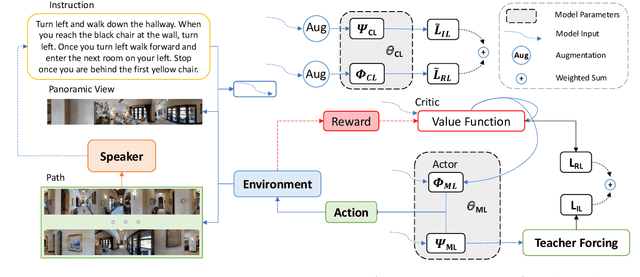
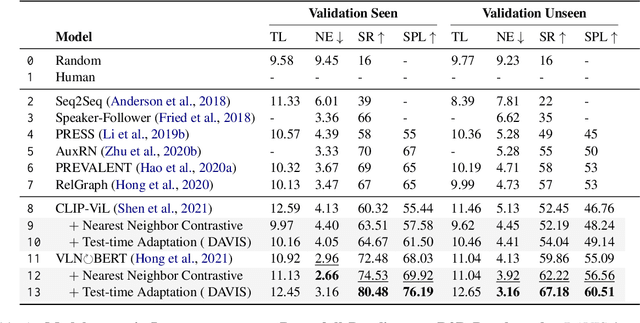
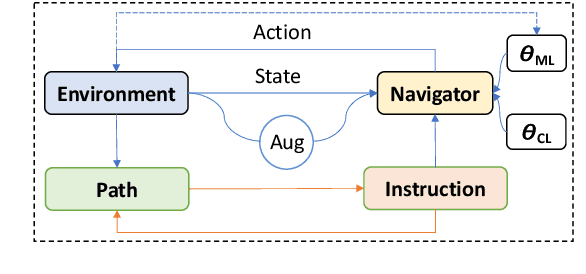
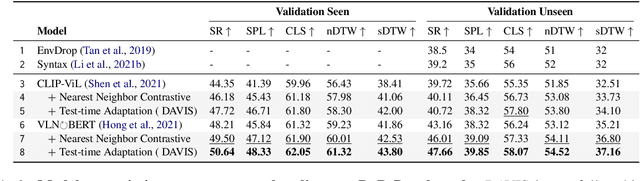
Vision-Language Navigation requires the agent to follow natural language instructions to reach a specific target. The large discrepancy between seen and unseen environments makes it challenging for the agent to generalize well. Previous studies propose data augmentation methods to mitigate the data bias explicitly or implicitly and provide improvements in generalization. However, they try to memorize augmented trajectories and ignore the distribution shifts under unseen environments at test time. In this paper, we propose an Unseen Discrepancy Anticipating Vision and Language Navigation (DAVIS) that learns to generalize to unseen environments via encouraging test-time visual consistency. Specifically, we devise: 1) a semi-supervised framework DAVIS that leverages visual consistency signals across similar semantic observations. 2) a two-stage learning procedure that encourages adaptation to test-time distribution. The framework enhances the basic mixture of imitation and reinforcement learning with Momentum Contrast to encourage stable decision-making on similar observations under a joint training stage and a test-time adaptation stage. Extensive experiments show that DAVIS achieves model-agnostic improvement over previous state-of-the-art VLN baselines on R2R and RxR benchmarks. Our source code and data are in supplemental materials.
An Empirical Study of End-to-End Video-Language Transformers with Masked Visual Modeling
Sep 04, 2022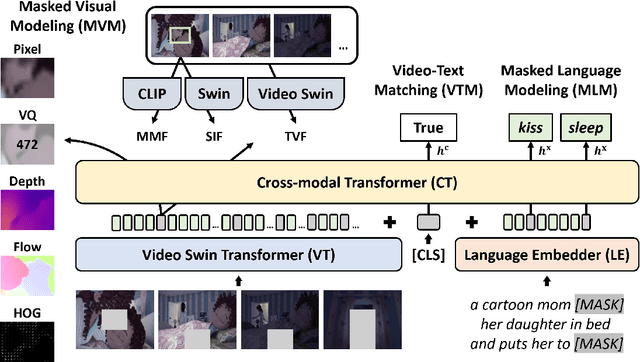
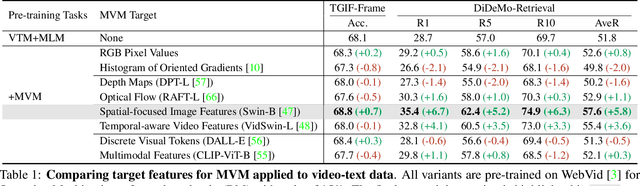
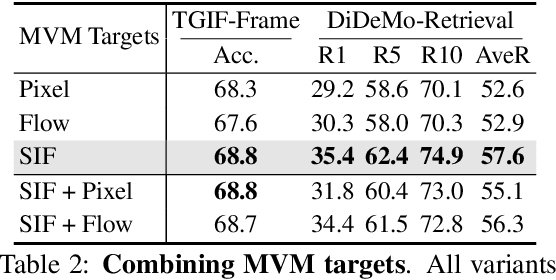

Masked visual modeling (MVM) has been recently proven effective for visual pre-training. While similar reconstructive objectives on video inputs (e.g., masked frame modeling) have been explored in video-language (VidL) pre-training, the pre-extracted video features in previous studies cannot be refined through MVM during pre-training, and thus leading to unsatisfactory downstream performance. In this work, we systematically examine the potential of MVM in the context of VidL learning. Specifically, we base our study on a fully end-to-end VIdeO-LanguagE Transformer (VIOLET), which mitigates the disconnection between fixed video representations and MVM training. In total, eight different reconstructive targets of MVM are explored, from low-level pixel values and oriented gradients to high-level depth maps, optical flow, discrete visual tokens and latent visual features. We conduct comprehensive experiments and provide insights on the factors leading to effective MVM training. Empirically, we show VIOLET pre-trained with MVM objective achieves notable improvements on 13 VidL benchmarks, ranging from video question answering, video captioning, to text-to-video retrieval.
Causal Balancing for Domain Generalization
Jun 10, 2022
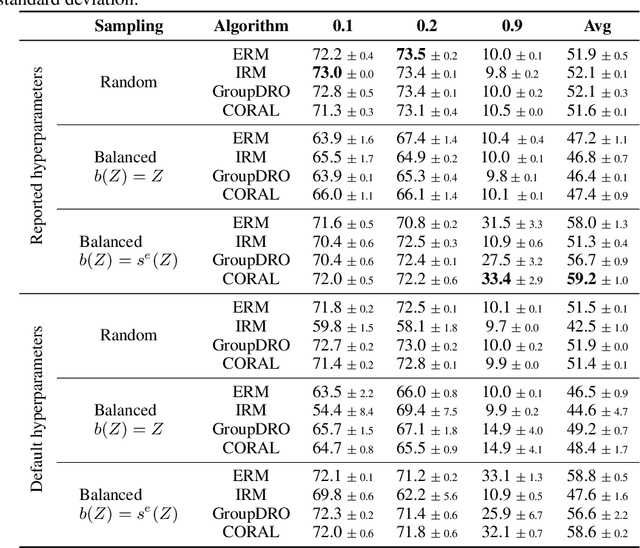
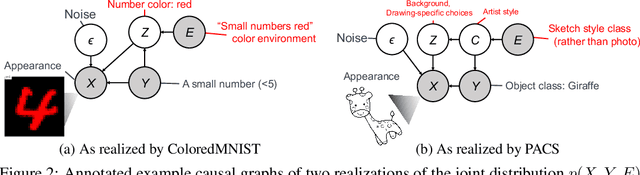
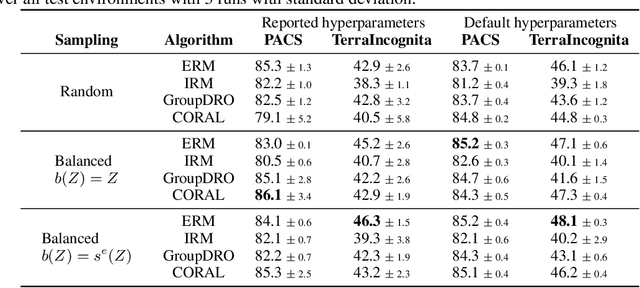
While machine learning models rapidly advance the state-of-the-art on various real-world tasks, out-of-domain (OOD) generalization remains a challenging problem given the vulnerability of these models to spurious correlations. While current domain generalization methods usually focus on enforcing certain invariance properties across different domains by new loss function designs, we propose a balanced mini-batch sampling strategy to reduce the domain-specific spurious correlations in the observed training distributions. More specifically, we propose a two-phased method that 1) identifies the source of spurious correlations, and 2) builds balanced mini-batches free from spurious correlations by matching on the identified source. We provide an identifiability guarantee of the source of spuriousness and show that our proposed approach provably samples from a balanced, spurious-free distribution over all training environments. Experiments are conducted on three computer vision datasets with documented spurious correlations, demonstrating empirically that our balanced mini-batch sampling strategy improves the performance of four different established domain generalization model baselines compared to the random mini-batch sampling strategy.
Neuro-Symbolic Causal Language Planning with Commonsense Prompting
Jun 06, 2022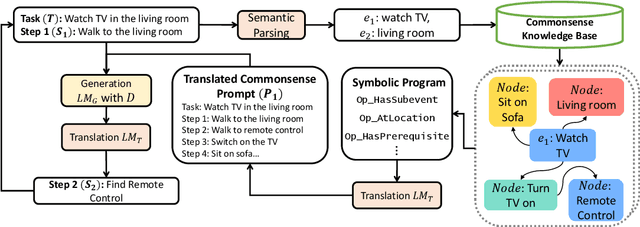

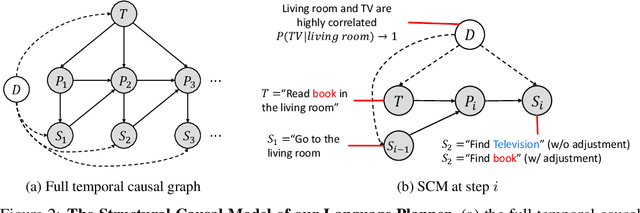
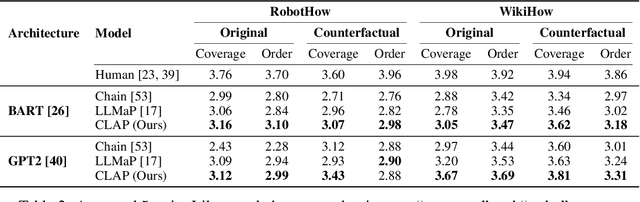
Language planning aims to implement complex high-level goals by decomposition into sequential simpler low-level steps. Such procedural reasoning ability is essential for applications such as household robots and virtual assistants. Although language planning is a basic skill set for humans in daily life, it remains a challenge for large language models (LLMs) that lack deep-level commonsense knowledge in the real world. Previous methods require either manual exemplars or annotated programs to acquire such ability from LLMs. In contrast, this paper proposes Neuro-Symbolic Causal Language Planner (CLAP) that elicits procedural knowledge from the LLMs with commonsense-infused prompting. Pre-trained knowledge in LLMs is essentially an unobserved confounder that causes spurious correlations between tasks and action plans. Through the lens of a Structural Causal Model (SCM), we propose an effective strategy in CLAP to construct prompts as a causal intervention toward our SCM. Using graph sampling techniques and symbolic program executors, our strategy formalizes the structured causal prompts from commonsense knowledge bases. CLAP obtains state-of-the-art performance on WikiHow and RobotHow, achieving a relative improvement of 5.28% in human evaluations under the counterfactual setting. This indicates the superiority of CLAP in causal language planning semantically and sequentially.
Towards Understanding Gender-Seniority Compound Bias in Natural Language Generation
May 19, 2022

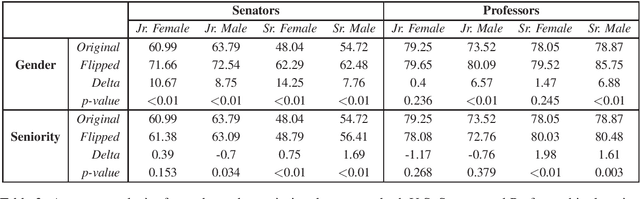

Women are often perceived as junior to their male counterparts, even within the same job titles. While there has been significant progress in the evaluation of gender bias in natural language processing (NLP), existing studies seldom investigate how biases toward gender groups change when compounded with other societal biases. In this work, we investigate how seniority impacts the degree of gender bias exhibited in pretrained neural generation models by introducing a novel framework for probing compound bias. We contribute a benchmark robustness-testing dataset spanning two domains, U.S. senatorship and professorship, created using a distant-supervision method. Our dataset includes human-written text with underlying ground truth and paired counterfactuals. We then examine GPT-2 perplexity and the frequency of gendered language in generated text. Our results show that GPT-2 amplifies bias by considering women as junior and men as senior more often than the ground truth in both domains. These results suggest that NLP applications built using GPT-2 may harm women in professional capacities.