 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Understanding Sample Variance in Visually Grounded Language Generation: Evaluations and Observations
Paper and Code

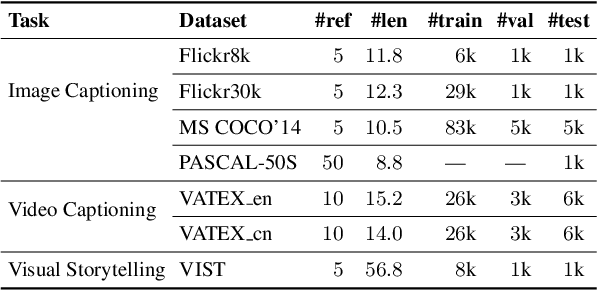
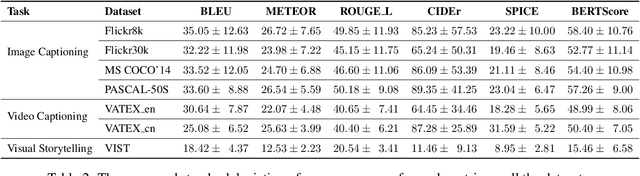
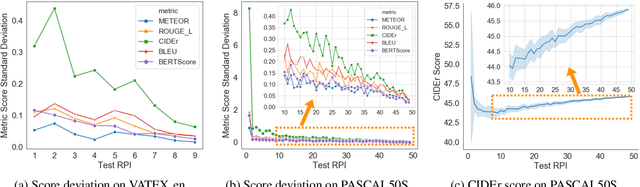
A major challenge in visually grounded language generation is to build robust benchmark datasets and models that can generalize well in real-world settings. To do this, it is critical to ensure that our evaluation protocols are correct, and benchmarks are reliable. In this work, we set forth to design a set of experiments to understand an important but often ignored problem in visually grounded language generation: given that humans have different utilities and visual attention, how will the sample variance in multi-reference datasets affect the models' performance? Empirically, we study several multi-reference datasets and corresponding vision-and-language tasks. We show that it is of paramount importance to report variance in experiments; that human-generated references could vary drastically in different datasets/tasks, revealing the nature of each task; that metric-wise, CIDEr has shown systematically larger variances than others. Our evaluations on reference-per-instance shed light on the design of reliable datasets in the future.