 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBatch Normalization-Free Fully Integer Quantized Neural Networks via Progressive Tandem Learning
Dec 18, 2025Quantised neural networks (QNNs) shrink models and reduce inference energy through low-bit arithmetic, yet most still depend on a running statistics batch normalisation (BN) layer, preventing true integer-only deployment. Prior attempts remove BN by parameter folding or tailored initialisation; while helpful, they rarely recover BN's stability and accuracy and often impose bespoke constraints. We present a BN-free, fully integer QNN trained via a progressive, layer-wise distillation scheme that slots into existing low-bit pipelines. Starting from a pretrained BN-enabled teacher, we use layer-wise targets and progressive compensation to train a student that performs inference exclusively with integer arithmetic and contains no BN operations. On ImageNet with AlexNet, the BN-free model attains competitive Top-1 accuracy under aggressive quantisation. The procedure integrates directly with standard quantisation workflows, enabling end-to-end integer-only inference for resource-constrained settings such as edge and embedded devices.
FailureAtlas:Mapping the Failure Landscape of T2I Models via Active Exploration
Sep 26, 2025Static benchmarks have provided a valuable foundation for comparing Text-to-Image (T2I) models. However, their passive design offers limited diagnostic power, struggling to uncover the full landscape of systematic failures or isolate their root causes. We argue for a complementary paradigm: active exploration. We introduce FailureAtlas, the first framework designed to autonomously explore and map the vast failure landscape of T2I models at scale. FailureAtlas frames error discovery as a structured search for minimal, failure-inducing concepts. While it is a computationally explosive problem, we make it tractable with novel acceleration techniques. When applied to Stable Diffusion models, our method uncovers hundreds of thousands of previously unknown error slices (over 247,000 in SD1.5 alone) and provides the first large-scale evidence linking these failures to data scarcity in the training set. By providing a principled and scalable engine for deep model auditing, FailureAtlas establishes a new, diagnostic-first methodology to guide the development of more robust generative AI. The code is available at https://github.com/cure-lab/FailureAtlas
Efficient Membership Inference Attacks by Bayesian Neural Network
Mar 10, 2025Membership Inference Attacks (MIAs) aim to estimate whether a specific data point was used in the training of a given model. Previous attacks often utilize multiple reference models to approximate the conditional score distribution, leading to significant computational overhead. While recent work leverages quantile regression to estimate conditional thresholds, it fails to capture epistemic uncertainty, resulting in bias in low-density regions. In this work, we propose a novel approach - Bayesian Membership Inference Attack (BMIA), which performs conditional attack through Bayesian inference. In particular, we transform a trained reference model into Bayesian neural networks by Laplace approximation, enabling the direct estimation of the conditional score distribution by probabilistic model parameters. Our method addresses both epistemic and aleatoric uncertainty with only a reference model, enabling efficient and powerful MIA. Extensive experiments on five datasets demonstrate the effectiveness and efficiency of BMIA.
On the Noise Robustness of In-Context Learning for Text Generation
May 27, 2024



Large language models (LLMs) have shown impressive performance on downstream tasks by in-context learning (ICL), which heavily relies on the quality of demonstrations selected from a large set of annotated examples. Recent works claim that in-context learning is robust to noisy demonstrations in text classification. In this work, we show that, on text generation tasks, noisy annotations significantly hurt the performance of in-context learning. To circumvent the issue, we propose a simple and effective approach called Local Perplexity Ranking (LPR), which replaces the "noisy" candidates with their nearest neighbors that are more likely to be clean. Our method is motivated by analyzing the perplexity deviation caused by noisy labels and decomposing perplexity into inherent perplexity and matching perplexity. Our key idea behind LPR is thus to decouple the matching perplexity by performing the ranking among the neighbors in semantic space. Our approach can prevent the selected demonstrations from including mismatched input-label pairs while preserving the effectiveness of the original selection methods. Extensive experiments demonstrate the effectiveness of LPR, improving the EM score by up to 18.75 on common benchmarks with noisy annotations.
Similarity-Navigated Conformal Prediction for Graph Neural Networks
May 23, 2024



Graph Neural Networks have achieved remarkable accuracy in semi-supervised node classification tasks. However, these results lack reliable uncertainty estimates. Conformal prediction methods provide a theoretical guarantee for node classification tasks, ensuring that the conformal prediction set contains the ground-truth label with a desired probability (e.g., 95%). In this paper, we empirically show that for each node, aggregating the non-conformity scores of nodes with the same label can improve the efficiency of conformal prediction sets. This observation motivates us to propose a novel algorithm named Similarity-Navigated Adaptive Prediction Sets (SNAPS), which aggregates the non-conformity scores based on feature similarity and structural neighborhood. The key idea behind SNAPS is that nodes with high feature similarity or direct connections tend to have the same label. By incorporating adaptive similar nodes information, SNAPS can generate compact prediction sets and increase the singleton hit ratio (correct prediction sets of size one). Moreover, we theoretically provide a finite-sample coverage guarantee of SNAPS. Extensive experiments demonstrate the superiority of SNAPS, improving the efficiency of prediction sets and singleton hit ratio while maintaining valid coverage.
Exploring Learning Complexity for Downstream Data Pruning
Feb 08, 2024



The over-parameterized pre-trained models pose a great challenge to fine-tuning with limited computation resources. An intuitive solution is to prune the less informative samples from the fine-tuning dataset. A series of training-based scoring functions are proposed to quantify the informativeness of the data subset but the pruning cost becomes non-negligible due to the heavy parameter updating. For efficient pruning, it is viable to adapt the similarity scoring function of geometric-based methods from training-based to training-free. However, we empirically show that such adaption distorts the original pruning and results in inferior performance on the downstream tasks. In this paper, we propose to treat the learning complexity (LC) as the scoring function for classification and regression tasks. Specifically, the learning complexity is defined as the average predicted confidence of subnets with different capacities, which encapsulates data processing within a converged model. Then we preserve the diverse and easy samples for fine-tuning. Extensive experiments with vision datasets demonstrate the effectiveness and efficiency of the proposed scoring function for classification tasks. For the instruction fine-tuning of large language models, our method achieves state-of-the-art performance with stable convergence, outperforming the full training with only 10\% of the instruction dataset.
Robust Anti-jamming Communications with DMA-Based Reconfigurable Heterogeneous Array
Oct 14, 2023



In the future commercial and military communication systems, anti-jamming remains a critical issue. Existing homogeneous or heterogeneous arrays with a limited degrees of freedom (DoF) and high consumption are unable to meet the requirements of communication in rapidly changing and intense jamming environments. To address these challenges, we propose a reconfigurable heterogeneous array (RHA) architecture based on dynamic metasurface antenna (DMA), which will increase the DoF and further improve anti-jamming capabilities. We propose a two-step anti-jamming scheme based on RHA, where the multipaths are estimated by an atomic norm minimization (ANM) based scheme, and then the received signal-to-interference-plus-noise ratio (SINR) is maximized by jointly designing the phase shift of each DMA element and the weights of the array elements. To solve the challenging non-convex discrete fractional problem along with the estimation error in the direction of arrival (DoA) and channel state information (CSI), we propose a robust alternative algorithm based on the S-procedure to solve the lower-bound SINR maximization problem. Simulation results demonstrate that the proposed RHA architecture and corresponding schemes have superior performance in terms of jamming immunity and robustness.
DOS: Diverse Outlier Sampling for Out-of-Distribution Detection
Jun 03, 2023Modern neural networks are known to give overconfident prediction for out-of-distribution inputs when deployed in the open world. It is common practice to leverage a surrogate outlier dataset to regularize the model during training, and recent studies emphasize the role of uncertainty in designing the sampling strategy for outlier dataset. However, the OOD samples selected solely based on predictive uncertainty can be biased towards certain types, which may fail to capture the full outlier distribution. In this work, we empirically show that diversity is critical in sampling outliers for OOD detection performance. Motivated by the observation, we propose a straightforward and novel sampling strategy named DOS (Diverse Outlier Sampling) to select diverse and informative outliers. Specifically, we cluster the normalized features at each iteration, and the most informative outlier from each cluster is selected for model training with absent category loss. With DOS, the sampled outliers efficiently shape a globally compact decision boundary between ID and OOD data. Extensive experiments demonstrate the superiority of DOS, reducing the average FPR95 by up to 25.79% on CIFAR-100 with TI-300K.
MixBoost: Improving the Robustness of Deep Neural Networks by Boosting Data Augmentation
Dec 08, 2022



As more and more artificial intelligence (AI) technologies move from the laboratory to real-world applications, the open-set and robustness challenges brought by data from the real world have received increasing attention. Data augmentation is a widely used method to improve model performance, and some recent works have also confirmed its positive effect on the robustness of AI models. However, most of the existing data augmentation methods are heuristic, lacking the exploration of their internal mechanisms. We apply the explainable artificial intelligence (XAI) method, explore the internal mechanisms of popular data augmentation methods, analyze the relationship between game interactions and some widely used robustness metrics, and propose a new proxy for model robustness in the open-set environment. Based on the analysis of the internal mechanisms, we develop a mask-based boosting method for data augmentation that comprehensively improves several robustness measures of AI models and beats state-of-the-art data augmentation approaches. Experiments show that our method can be widely applied to many popular data augmentation methods. Different from the adversarial training, our boosting method not only significantly improves the robustness of models, but also improves the accuracy of test sets. Our code is available at \url{https://github.com/Anonymous_for_submission}.
Explanation-based Counterfactual Retraining(XCR): A Calibration Method for Black-box Models
Jun 22, 2022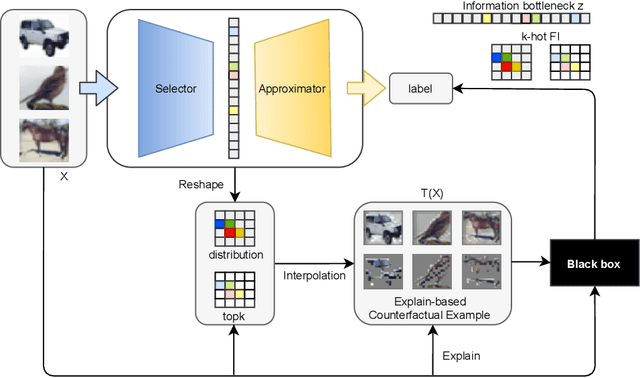


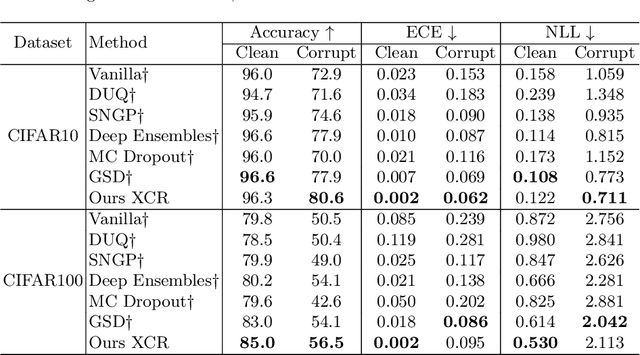
With the rapid development of eXplainable Artificial Intelligence (XAI), a long line of past work has shown concerns about the Out-of-Distribution (OOD) problem in perturbation-based post-hoc XAI models and explanations are socially misaligned. We explore the limitations of post-hoc explanation methods that use approximators to mimic the behavior of black-box models. Then we propose eXplanation-based Counterfactual Retraining (XCR), which extracts feature importance fastly. XCR applies the explanations generated by the XAI model as counterfactual input to retrain the black-box model to address OOD and social misalignment problems. Evaluation of popular image datasets shows that XCR can improve model performance when only retaining 12.5% of the most crucial features without changing the black-box model structure. Furthermore, the evaluation of the benchmark of corruption datasets shows that the XCR is very helpful for improving model robustness and positively impacts the calibration of OOD problems. Even though not calibrated in the validation set like some OOD calibration methods, the corrupted data metric outperforms existing methods. Our method also beats current OOD calibration methods on the OOD calibration metric if calibration on the validation set is applied.