 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFBCIR: Balancing Cross-Modal Focuses in Composed Image Retrieval
Mar 12, 2026Composed image retrieval (CIR) requires multi-modal models to jointly reason over visual content and semantic modifications presented in text-image input pairs. While current CIR models achieve strong performance on common benchmark cases, their accuracies often degrades in more challenging scenarios where negative candidates are semantically aligned with the query image or text. In this paper, we attribute this degradation to focus imbalances, where models disproportionately attend to one modality while neglecting the other. To validate this claim, we propose FBCIR, a multi-modal focus interpretation method that identifies the most crucial visual and textual input components to a model's retrieval decisions. Using FBCIR, we report that focus imbalances are prevalent in existing CIR models, especially under hard negative settings. Building on the analyses, we further propose a CIR data augmentation workflow that facilitates existing CIR datasets with curated hard negatives designed to encourage balanced cross-modal reasoning. Extensive experiments across multiple CIR models demonstrate that the proposed augmentation consistently improves performance in challenging cases, while maintaining their capabilities on standard benchmarks. Together, our interpretation method and data augmentation workflow provide a new perspective on CIR model diagnosis and robustness improvements.
FailureAtlas:Mapping the Failure Landscape of T2I Models via Active Exploration
Sep 26, 2025Static benchmarks have provided a valuable foundation for comparing Text-to-Image (T2I) models. However, their passive design offers limited diagnostic power, struggling to uncover the full landscape of systematic failures or isolate their root causes. We argue for a complementary paradigm: active exploration. We introduce FailureAtlas, the first framework designed to autonomously explore and map the vast failure landscape of T2I models at scale. FailureAtlas frames error discovery as a structured search for minimal, failure-inducing concepts. While it is a computationally explosive problem, we make it tractable with novel acceleration techniques. When applied to Stable Diffusion models, our method uncovers hundreds of thousands of previously unknown error slices (over 247,000 in SD1.5 alone) and provides the first large-scale evidence linking these failures to data scarcity in the training set. By providing a principled and scalable engine for deep model auditing, FailureAtlas establishes a new, diagnostic-first methodology to guide the development of more robust generative AI. The code is available at https://github.com/cure-lab/FailureAtlas
Learning Explicit User Interest Boundary for Recommendation
Nov 22, 2021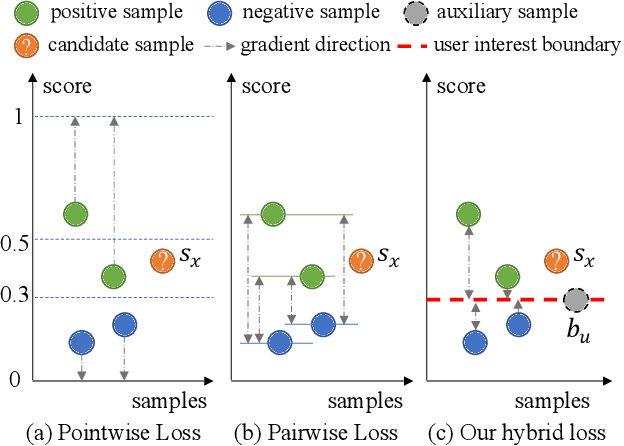

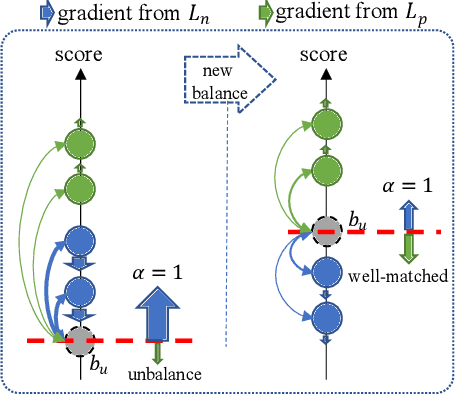

The core objective of modelling recommender systems from implicit feedback is to maximize the positive sample score $s_p$ and minimize the negative sample score $s_n$, which can usually be summarized into two paradigms: the pointwise and the pairwise. The pointwise approaches fit each sample with its label individually, which is flexible in weighting and sampling on instance-level but ignores the inherent ranking property. By qualitatively minimizing the relative score $s_n - s_p$, the pairwise approaches capture the ranking of samples naturally but suffer from training efficiency. Additionally, both approaches are hard to explicitly provide a personalized decision boundary to determine if users are interested in items unseen. To address those issues, we innovatively introduce an auxiliary score $b_u$ for each user to represent the User Interest Boundary(UIB) and individually penalize samples that cross the boundary with pairwise paradigms, i.e., the positive samples whose score is lower than $b_u$ and the negative samples whose score is higher than $b_u$. In this way, our approach successfully achieves a hybrid loss of the pointwise and the pairwise to combine the advantages of both. Analytically, we show that our approach can provide a personalized decision boundary and significantly improve the training efficiency without any special sampling strategy. Extensive results show that our approach achieves significant improvements on not only the classical pointwise or pairwise models but also state-of-the-art models with complex loss function and complicated feature encoding.