 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory-T1: Reinforcement Learning for Temporal Reasoning in Multi-session Agents
Dec 23, 2025Temporal reasoning over long, multi-session dialogues is a critical capability for conversational agents. However, existing works and our pilot study have shown that as dialogue histories grow in length and accumulate noise, current long-context models struggle to accurately identify temporally pertinent information, significantly impairing reasoning performance. To address this, we introduce Memory-T1, a framework that learns a time-aware memory selection policy using reinforcement learning (RL). It employs a coarse-to-fine strategy, first pruning the dialogue history into a candidate set using temporal and relevance filters, followed by an RL agent that selects the precise evidence sessions. The RL training is guided by a multi-level reward function optimizing (i) answer accuracy, (ii) evidence grounding, and (iii) temporal consistency. In particular, the temporal consistency reward provides a dense signal by evaluating alignment with the query time scope at both the session-level (chronological proximity) and the utterance-level (chronological fidelity), enabling the agent to resolve subtle chronological ambiguities. On the Time-Dialog benchmark, Memory-T1 boosts a 7B model to an overall score of 67.0\%, establishing a new state-of-the-art performance for open-source models and outperforming a 14B baseline by 10.2\%. Ablation studies show temporal consistency and evidence grounding rewards jointly contribute to a 15.0\% performance gain. Moreover, Memory-T1 maintains robustness up to 128k tokens, where baseline models collapse, proving effectiveness against noise in extensive dialogue histories. The code and datasets are publicly available at https://github.com/Elvin-Yiming-Du/Memory-T1/
Rethinking Stateful Tool Use in Multi-Turn Dialogues: Benchmarks and Challenges
May 19, 2025Existing benchmarks that assess Language Models (LMs) as Language Agents (LAs) for tool use primarily focus on stateless, single-turn interactions or partial evaluations, such as tool selection in a single turn, overlooking the inherent stateful nature of interactions in multi-turn applications. To fulfill this gap, we propose \texttt{DialogTool}, a multi-turn dialogue dataset with stateful tool interactions considering the whole life cycle of tool use, across six key tasks in three stages: 1) \textit{tool creation}; 2) \textit{tool utilization}: tool awareness, tool selection, tool execution; and 3) \textit{role-consistent response}: response generation and role play. Furthermore, we build \texttt{VirtualMobile} -- an embodied virtual mobile evaluation environment to simulate API calls and assess the robustness of the created APIs\footnote{We will use tools and APIs alternatively, there are no significant differences between them in this paper.}. Taking advantage of these artifacts, we conduct comprehensive evaluation on 13 distinct open- and closed-source LLMs and provide detailed analysis at each stage, revealing that the existing state-of-the-art LLMs still cannot perform well to use tools over long horizons.
Masking in Multi-hop QA: An Analysis of How Language Models Perform with Context Permutation
May 16, 2025



Multi-hop Question Answering (MHQA) adds layers of complexity to question answering, making it more challenging. When Language Models (LMs) are prompted with multiple search results, they are tasked not only with retrieving relevant information but also employing multi-hop reasoning across the information sources. Although LMs perform well on traditional question-answering tasks, the causal mask can hinder their capacity to reason across complex contexts. In this paper, we explore how LMs respond to multi-hop questions by permuting search results (retrieved documents) under various configurations. Our study reveals interesting findings as follows: 1) Encoder-decoder models, such as the ones in the Flan-T5 family, generally outperform causal decoder-only LMs in MHQA tasks, despite being significantly smaller in size; 2) altering the order of gold documents reveals distinct trends in both Flan T5 models and fine-tuned decoder-only models, with optimal performance observed when the document order aligns with the reasoning chain order; 3) enhancing causal decoder-only models with bi-directional attention by modifying the causal mask can effectively boost their end performance. In addition to the above, we conduct a thorough investigation of the distribution of LM attention weights in the context of MHQA. Our experiments reveal that attention weights tend to peak at higher values when the resulting answer is correct. We leverage this finding to heuristically improve LMs' performance on this task. Our code is publicly available at https://github.com/hwy9855/MultiHopQA-Reasoning.
Rethinking Memory in AI: Taxonomy, Operations, Topics, and Future Directions
May 01, 2025Memory is a fundamental component of AI systems, underpinning large language models (LLMs) based agents. While prior surveys have focused on memory applications with LLMs, they often overlook the atomic operations that underlie memory dynamics. In this survey, we first categorize memory representations into parametric, contextual structured, and contextual unstructured and then introduce six fundamental memory operations: Consolidation, Updating, Indexing, Forgetting, Retrieval, and Compression. We systematically map these operations to the most relevant research topics across long-term, long-context, parametric modification, and multi-source memory. By reframing memory systems through the lens of atomic operations and representation types, this survey provides a structured and dynamic perspective on research, benchmark datasets, and tools related to memory in AI, clarifying the functional interplay in LLMs based agents while outlining promising directions for future research\footnote{The paper list, datasets, methods and tools are available at \href{https://github.com/Elvin-Yiming-Du/Survey_Memory_in_AI}{https://github.com/Elvin-Yiming-Du/Survey\_Memory\_in\_AI}.}.
Less is More: Making Smaller Language Models Competent Subgraph Retrievers for Multi-hop KGQA
Oct 08, 2024Retrieval-Augmented Generation (RAG) is widely used to inject external non-parametric knowledge into large language models (LLMs). Recent works suggest that Knowledge Graphs (KGs) contain valuable external knowledge for LLMs. Retrieving information from KGs differs from extracting it from document sets. Most existing approaches seek to directly retrieve relevant subgraphs, thereby eliminating the need for extensive SPARQL annotations, traditionally required by semantic parsing methods. In this paper, we model the subgraph retrieval task as a conditional generation task handled by small language models. Specifically, we define a subgraph identifier as a sequence of relations, each represented as a special token stored in the language models. Our base generative subgraph retrieval model, consisting of only 220M parameters, achieves competitive retrieval performance compared to state-of-the-art models relying on 7B parameters, demonstrating that small language models are capable of performing the subgraph retrieval task. Furthermore, our largest 3B model, when plugged with an LLM reader, sets new SOTA end-to-end performance on both the WebQSP and CWQ benchmarks. Our model and data will be made available online: https://github.com/hwy9855/GSR.
Prompting Large Language Models with Knowledge Graphs for Question Answering Involving Long-tail Facts
May 10, 2024



Although Large Language Models (LLMs) are effective in performing various NLP tasks, they still struggle to handle tasks that require extensive, real-world knowledge, especially when dealing with long-tail facts (facts related to long-tail entities). This limitation highlights the need to supplement LLMs with non-parametric knowledge. To address this issue, we analysed the effects of different types of non-parametric knowledge, including textual passage and knowledge graphs (KGs). Since LLMs have probably seen the majority of factual question-answering datasets already, to facilitate our analysis, we proposed a fully automatic pipeline for creating a benchmark that requires knowledge of long-tail facts for answering the involved questions. Using this pipeline, we introduce the LTGen benchmark. We evaluate state-of-the-art LLMs in different knowledge settings using the proposed benchmark. Our experiments show that LLMs alone struggle with answering these questions, especially when the long-tail level is high or rich knowledge is required. Nonetheless, the performance of the same models improved significantly when they were prompted with non-parametric knowledge. We observed that, in most cases, prompting LLMs with KG triples surpasses passage-based prompting using a state-of-the-art retriever. In addition, while prompting LLMs with both KG triples and documents does not consistently improve knowledge coverage, it can dramatically reduce hallucinations in the generated content.
UniMS-RAG: A Unified Multi-source Retrieval-Augmented Generation for Personalized Dialogue Systems
Jan 24, 2024



Large Language Models (LLMs) has shown exceptional capabilities in many natual language understanding and generation tasks. However, the personalization issue still remains a much-coveted property, especially when it comes to the multiple sources involved in the dialogue system. To better plan and incorporate the use of multiple sources in generating personalized response, we firstly decompose it into three sub-tasks: Knowledge Source Selection, Knowledge Retrieval, and Response Generation. We then propose a novel Unified Multi-Source Retrieval-Augmented Generation system (UniMS-RAG) Specifically, we unify these three sub-tasks with different formulations into the same sequence-to-sequence paradigm during the training, to adaptively retrieve evidences and evaluate the relevance on-demand using special tokens, called acting tokens and evaluation tokens. Enabling language models to generate acting tokens facilitates interaction with various knowledge sources, allowing them to adapt their behavior to diverse task requirements. Meanwhile, evaluation tokens gauge the relevance score between the dialogue context and the retrieved evidence. In addition, we carefully design a self-refinement mechanism to iteratively refine the generated response considering 1) the consistency scores between the generated response and retrieved evidence; and 2) the relevance scores. Experiments on two personalized datasets (DuLeMon and KBP) show that UniMS-RAG achieves state-of-the-art performance on the knowledge source selection and response generation task with itself as a retriever in a unified manner. Extensive analyses and discussions are provided for shedding some new perspectives for personalized dialogue systems.
Task-specific Pre-training and Prompt Decomposition for Knowledge Graph Population with Language Models
Aug 31, 2022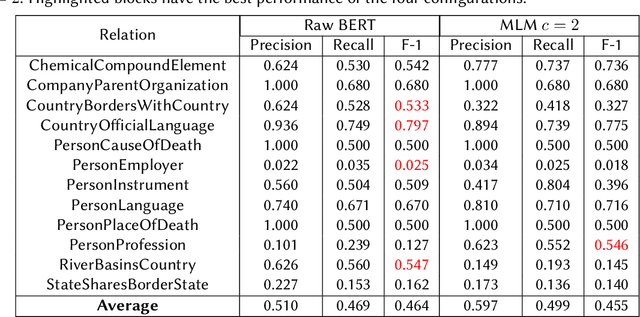
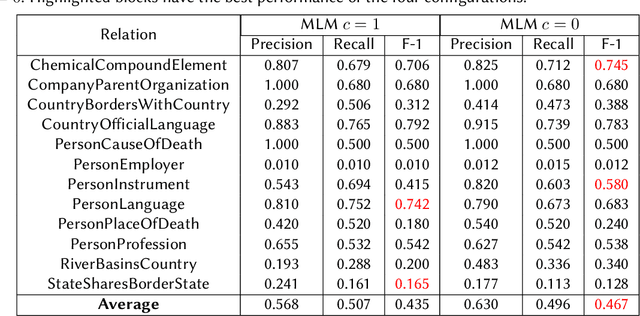
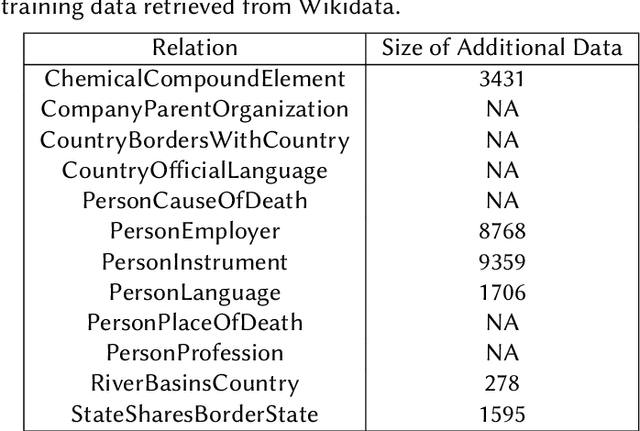
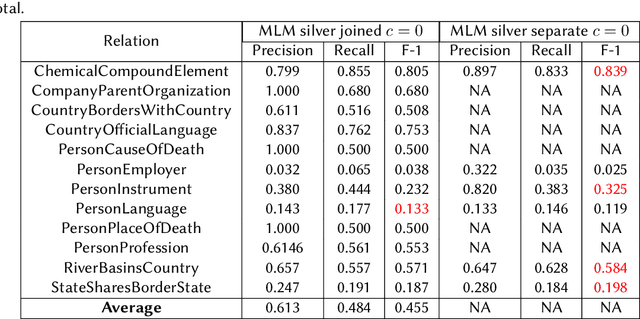
We present a system for knowledge graph population with Language Models, evaluated on the Knowledge Base Construction from Pre-trained Language Models (LM-KBC) challenge at ISWC 2022. Our system involves task-specific pre-training to improve LM representation of the masked object tokens, prompt decomposition for progressive generation of candidate objects, among other methods for higher-quality retrieval. Our system is the winner of track 1 of the LM-KBC challenge, based on BERT LM; it achieves 55.0% F-1 score on the hidden test set of the challenge.