 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMillions of $\text{GeAR}$-s: Extending GraphRAG to Millions of Documents
Jul 23, 2025Recent studies have explored graph-based approaches to retrieval-augmented generation, leveraging structured or semi-structured information -- such as entities and their relations extracted from documents -- to enhance retrieval. However, these methods are typically designed to address specific tasks, such as multi-hop question answering and query-focused summarisation, and therefore, there is limited evidence of their general applicability across broader datasets. In this paper, we aim to adapt a state-of-the-art graph-based RAG solution: $\text{GeAR}$ and explore its performance and limitations on the SIGIR 2025 LiveRAG Challenge.
Masking in Multi-hop QA: An Analysis of How Language Models Perform with Context Permutation
May 16, 2025



Multi-hop Question Answering (MHQA) adds layers of complexity to question answering, making it more challenging. When Language Models (LMs) are prompted with multiple search results, they are tasked not only with retrieving relevant information but also employing multi-hop reasoning across the information sources. Although LMs perform well on traditional question-answering tasks, the causal mask can hinder their capacity to reason across complex contexts. In this paper, we explore how LMs respond to multi-hop questions by permuting search results (retrieved documents) under various configurations. Our study reveals interesting findings as follows: 1) Encoder-decoder models, such as the ones in the Flan-T5 family, generally outperform causal decoder-only LMs in MHQA tasks, despite being significantly smaller in size; 2) altering the order of gold documents reveals distinct trends in both Flan T5 models and fine-tuned decoder-only models, with optimal performance observed when the document order aligns with the reasoning chain order; 3) enhancing causal decoder-only models with bi-directional attention by modifying the causal mask can effectively boost their end performance. In addition to the above, we conduct a thorough investigation of the distribution of LM attention weights in the context of MHQA. Our experiments reveal that attention weights tend to peak at higher values when the resulting answer is correct. We leverage this finding to heuristically improve LMs' performance on this task. Our code is publicly available at https://github.com/hwy9855/MultiHopQA-Reasoning.
An Extensive Evaluation of PDDL Capabilities in off-the-shelf LLMs
Feb 27, 2025


In recent advancements, large language models (LLMs) have exhibited proficiency in code generation and chain-of-thought reasoning, laying the groundwork for tackling automatic formal planning tasks. This study evaluates the potential of LLMs to understand and generate Planning Domain Definition Language (PDDL), an essential representation in artificial intelligence planning. We conduct an extensive analysis across 20 distinct models spanning 7 major LLM families, both commercial and open-source. Our comprehensive evaluation sheds light on the zero-shot LLM capabilities of parsing, generating, and reasoning with PDDL. Our findings indicate that while some models demonstrate notable effectiveness in handling PDDL, others pose limitations in more complex scenarios requiring nuanced planning knowledge. These results highlight the promise and current limitations of LLMs in formal planning tasks, offering insights into their application and guiding future efforts in AI-driven planning paradigms.
GeAR: Graph-enhanced Agent for Retrieval-augmented Generation
Dec 24, 2024Retrieval-augmented generation systems rely on effective document retrieval capabilities. By design, conventional sparse or dense retrievers face challenges in multi-hop retrieval scenarios. In this paper, we present GeAR, which advances RAG performance through two key innovations: (i) graph expansion, which enhances any conventional base retriever, such as BM25, and (ii) an agent framework that incorporates graph expansion. Our evaluation demonstrates GeAR's superior retrieval performance on three multi-hop question answering datasets. Additionally, our system achieves state-of-the-art results with improvements exceeding 10% on the challenging MuSiQue dataset, while requiring fewer tokens and iterations compared to other multi-step retrieval systems.
From An LLM Swarm To A PDDL-Empowered HIVE: Planning Self-Executed Instructions In A Multi-Modal Jungle
Dec 17, 2024



In response to the call for agent-based solutions that leverage the ever-increasing capabilities of the deep models' ecosystem, we introduce Hive -- a comprehensive solution for selecting appropriate models and subsequently planning a set of atomic actions to satisfy the end-users' instructions. Hive operates over sets of models and, upon receiving natural language instructions (i.e. user queries), schedules and executes explainable plans of atomic actions. These actions can involve one or more of the available models to achieve the overall task, while respecting end-users specific constraints. Notably, Hive handles tasks that involve multi-modal inputs and outputs, enabling it to handle complex, real-world queries. Our system is capable of planning complex chains of actions while guaranteeing explainability, using an LLM-based formal logic backbone empowered by PDDL operations. We introduce the MuSE benchmark in order to offer a comprehensive evaluation of the multi-modal capabilities of agent systems. Our findings show that our framework redefines the state-of-the-art for task selection, outperforming other competing systems that plan operations across multiple models while offering transparency guarantees while fully adhering to user constraints.
Less is More: Making Smaller Language Models Competent Subgraph Retrievers for Multi-hop KGQA
Oct 08, 2024Retrieval-Augmented Generation (RAG) is widely used to inject external non-parametric knowledge into large language models (LLMs). Recent works suggest that Knowledge Graphs (KGs) contain valuable external knowledge for LLMs. Retrieving information from KGs differs from extracting it from document sets. Most existing approaches seek to directly retrieve relevant subgraphs, thereby eliminating the need for extensive SPARQL annotations, traditionally required by semantic parsing methods. In this paper, we model the subgraph retrieval task as a conditional generation task handled by small language models. Specifically, we define a subgraph identifier as a sequence of relations, each represented as a special token stored in the language models. Our base generative subgraph retrieval model, consisting of only 220M parameters, achieves competitive retrieval performance compared to state-of-the-art models relying on 7B parameters, demonstrating that small language models are capable of performing the subgraph retrieval task. Furthermore, our largest 3B model, when plugged with an LLM reader, sets new SOTA end-to-end performance on both the WebQSP and CWQ benchmarks. Our model and data will be made available online: https://github.com/hwy9855/GSR.
Improving Retrieval-augmented Text-to-SQL with AST-based Ranking and Schema Pruning
Jul 03, 2024



We focus on Text-to-SQL semantic parsing from the perspective of Large Language Models. Motivated by challenges related to the size of commercial database schemata and the deployability of business intelligence solutions, we propose an approach that dynamically retrieves input database information and uses abstract syntax trees to select few-shot examples for in-context learning. Furthermore, we investigate the extent to which an in-parallel semantic parser can be leveraged for generating $\textit{approximated}$ versions of the expected SQL queries, to support our retrieval. We take this approach to the extreme--we adapt a model consisting of less than $500$M parameters, to act as an extremely efficient approximator, enhancing it with the ability to process schemata in a parallelised manner. We apply our approach to monolingual and cross-lingual benchmarks for semantic parsing, showing improvements over state-of-the-art baselines. Comprehensive experiments highlight the contribution of modules involved in this retrieval-augmented generation setting, revealing interesting directions for future work.
Prompting Large Language Models with Knowledge Graphs for Question Answering Involving Long-tail Facts
May 10, 2024



Although Large Language Models (LLMs) are effective in performing various NLP tasks, they still struggle to handle tasks that require extensive, real-world knowledge, especially when dealing with long-tail facts (facts related to long-tail entities). This limitation highlights the need to supplement LLMs with non-parametric knowledge. To address this issue, we analysed the effects of different types of non-parametric knowledge, including textual passage and knowledge graphs (KGs). Since LLMs have probably seen the majority of factual question-answering datasets already, to facilitate our analysis, we proposed a fully automatic pipeline for creating a benchmark that requires knowledge of long-tail facts for answering the involved questions. Using this pipeline, we introduce the LTGen benchmark. We evaluate state-of-the-art LLMs in different knowledge settings using the proposed benchmark. Our experiments show that LLMs alone struggle with answering these questions, especially when the long-tail level is high or rich knowledge is required. Nonetheless, the performance of the same models improved significantly when they were prompted with non-parametric knowledge. We observed that, in most cases, prompting LLMs with KG triples surpasses passage-based prompting using a state-of-the-art retriever. In addition, while prompting LLMs with both KG triples and documents does not consistently improve knowledge coverage, it can dramatically reduce hallucinations in the generated content.
A Usage-centric Take on Intent Understanding in E-Commerce
Feb 22, 2024



Identifying and understanding user intents is a pivotal task for E-Commerce. Despite its popularity, intent understanding has not been consistently defined or accurately benchmarked. In this paper, we focus on predicative user intents as "how a customer uses a product", and pose intent understanding as a natural language reasoning task, independent of product ontologies. We identify two weaknesses of FolkScope, the SOTA E-Commerce Intent Knowledge Graph, that limit its capacity to reason about user intents and to recommend diverse useful products. Following these observations, we introduce a Product Recovery Benchmark including a novel evaluation framework and an example dataset. We further validate the above FolkScope weaknesses on this benchmark.
Task-specific Pre-training and Prompt Decomposition for Knowledge Graph Population with Language Models
Aug 31, 2022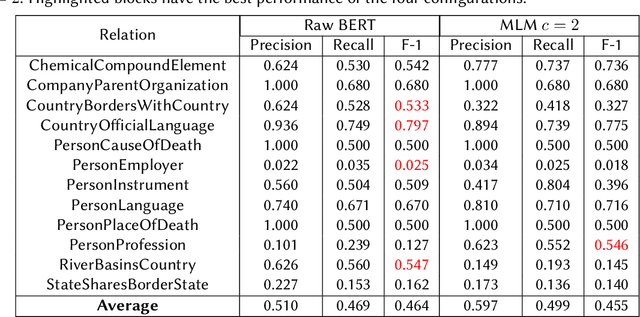
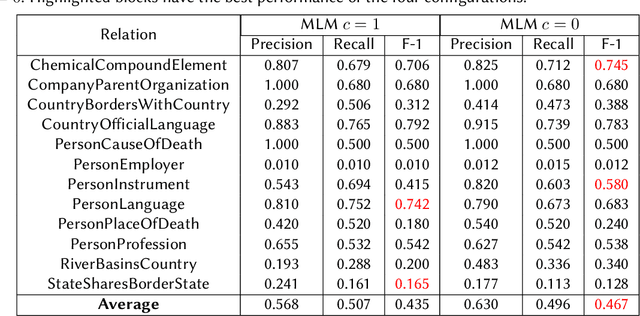
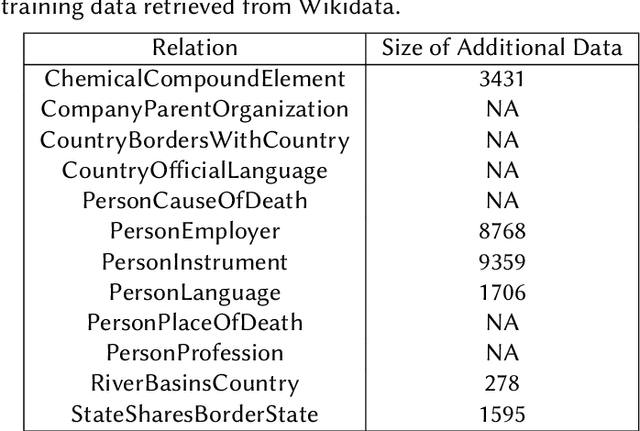
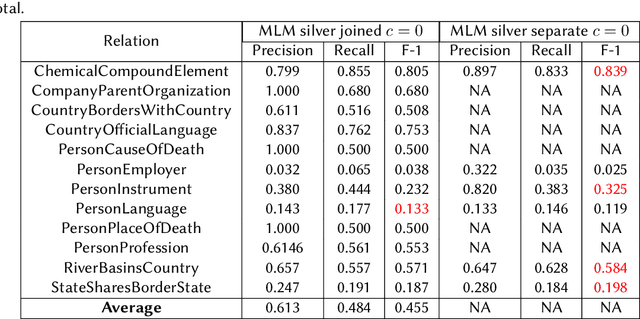
We present a system for knowledge graph population with Language Models, evaluated on the Knowledge Base Construction from Pre-trained Language Models (LM-KBC) challenge at ISWC 2022. Our system involves task-specific pre-training to improve LM representation of the masked object tokens, prompt decomposition for progressive generation of candidate objects, among other methods for higher-quality retrieval. Our system is the winner of track 1 of the LM-KBC challenge, based on BERT LM; it achieves 55.0% F-1 score on the hidden test set of the challenge.