 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Graph Models: A Perspective
Aug 28, 2023Large models have emerged as the most recent groundbreaking achievements in artificial intelligence, and particularly machine learning. However, when it comes to graphs, large models have not achieved the same level of success as in other fields, such as natural language processing and computer vision. In order to promote applying large models for graphs forward, we present a perspective paper to discuss the challenges and opportunities associated with developing large graph models. First, we discuss the desired characteristics of large graph models. Then, we present detailed discussions from three key perspectives: representation basis, graph data, and graph models. In each category, we provide a brief overview of recent advances and highlight the remaining challenges together with our visions. Finally, we discuss valuable applications of large graph models. We believe this perspective paper is able to encourage further investigations into large graph models, ultimately pushing us one step closer towards artificial general intelligence (AGI).
Graph Interpolation via Fast Fused-Gromovization
Jun 28, 2023Graph data augmentation has proven to be effective in enhancing the generalizability and robustness of graph neural networks (GNNs) for graph-level classifications. However, existing methods mainly focus on augmenting the graph signal space and the graph structure space independently, overlooking their joint interaction. This paper addresses this limitation by formulating the problem as an optimal transport problem that aims to find an optimal strategy for matching nodes between graphs considering the interactions between graph structures and signals. To tackle this problem, we propose a novel graph mixup algorithm dubbed FGWMixup, which leverages the Fused Gromov-Wasserstein (FGW) metric space to identify a "midpoint" of the source graphs. To improve the scalability of our approach, we introduce a relaxed FGW solver that accelerates FGWMixup by enhancing the convergence rate from $\mathcal{O}(t^{-1})$ to $\mathcal{O}(t^{-2})$. Extensive experiments conducted on five datasets, utilizing both classic (MPNNs) and advanced (Graphormers) GNN backbones, demonstrate the effectiveness of FGWMixup in improving the generalizability and robustness of GNNs.
DisenBooth: Disentangled Parameter-Efficient Tuning for Subject-Driven Text-to-Image Generation
May 05, 2023Given a small set of images of a specific subject, subject-driven text-to-image generation aims to generate customized images of the subject according to new text descriptions, which has attracted increasing attention in the community recently. Current subject-driven text-to-image generation methods are mainly based on finetuning a pretrained large-scale text-to-image generation model. However, these finetuning methods map the images of the subject into an embedding highly entangled with subject-identity-unrelated information, which may result in the inconsistency between the generated images and the text descriptions and the changes in the subject identity. To tackle the problem, we propose DisenBooth, a disentangled parameter-efficient tuning framework for subject-driven text-to-image generation. DisenBooth enables generating new images that simultaneously preserve the subject identity and conform to the text descriptions, by disentangling the embedding into an identity-related and an identity-unrelated part. Specifically, DisenBooth is based on the pretrained diffusion models and conducts finetuning in the diffusion denoising process, where a shared identity embedding and an image-specific identity-unrelated embedding are utilized jointly for denoising each image. To make the two embeddings disentangled, two auxiliary objectives are proposed. Additionally, to improve the finetuning efficiency, a parameter-efficient finetuning strategy is adopted. Extensive experiments show that our DisenBooth can faithfully learn well-disentangled identity-related and identity-unrelated embeddings. With the shared identity embedding, DisenBooth demonstrates superior subject-driven text-to-image generation ability. Additionally, DisenBooth provides a more flexible and controllable framework with different combinations of the disentangled embeddings.
DELTA: Direct Embedding Enhancement and Leverage Truncated Conscious Attention for Recommendation System
May 03, 2023Click-Through Rate (CTR) prediction is the most critical task in product and content recommendation, and learning effective feature interaction is the key challenge to exploiting user preferences for products. Some recent research works focus on investigating more sophisticated feature interactions based on soft attention or gate mechanism, while some redundant or contradictory feature combinations are still introduced. According to Global Workspace Theory in conscious processing, human clicks on advertisements ``consciously'': only a specific subset of product features are considered, and the rest are not involved in conscious processing. Therefore, we propose a CTR model that \textbf{D}irectly \textbf{E}nhances the embeddings and \textbf{L}everages \textbf{T}runcated Conscious \textbf{A}ttention during feature interaction, termed DELTA, which contains two key components: (I) conscious truncation module (CTM), which utilizes curriculum learning to apply adaptive truncation on attention weights to select the most critical feature combinations; (II) direct embedding enhancement module (DEM), which directly and independently propagates gradient from the loss layer to the embedding layer to enhance the crucial embeddings via linear feature crossing without introducing any extra cost during inference. Extensive experiments on five challenging CTR datasets demonstrate that DELTA achieves cutting-edge performance among current state-of-the-art CTR methods.
Adversarially Robust Neural Architecture Search for Graph Neural Networks
Apr 09, 2023



Graph Neural Networks (GNNs) obtain tremendous success in modeling relational data. Still, they are prone to adversarial attacks, which are massive threats to applying GNNs to risk-sensitive domains. Existing defensive methods neither guarantee performance facing new data/tasks or adversarial attacks nor provide insights to understand GNN robustness from an architectural perspective. Neural Architecture Search (NAS) has the potential to solve this problem by automating GNN architecture designs. Nevertheless, current graph NAS approaches lack robust design and are vulnerable to adversarial attacks. To tackle these challenges, we propose a novel Robust Neural Architecture search framework for GNNs (G-RNA). Specifically, we design a robust search space for the message-passing mechanism by adding graph structure mask operations into the search space, which comprises various defensive operation candidates and allows us to search for defensive GNNs. Furthermore, we define a robustness metric to guide the search procedure, which helps to filter robust architectures. In this way, G-RNA helps understand GNN robustness from an architectural perspective and effectively searches for optimal adversarial robust GNNs. Extensive experimental results on benchmark datasets show that G-RNA significantly outperforms manually designed robust GNNs and vanilla graph NAS baselines by 12.1% to 23.4% under adversarial attacks.
Curriculum Graph Machine Learning: A Survey
Feb 06, 2023Graph machine learning has been extensively studied in both academia and industry. However, in the literature, most existing graph machine learning models are designed to conduct training with data samples in a random order, which may suffer from suboptimal performance due to ignoring the importance of different graph data samples and their training orders for the model optimization status. To tackle this critical problem, curriculum graph machine learning (Graph CL), which integrates the strength of graph machine learning and curriculum learning, arises and attracts an increasing amount of attention from the research community. Therefore, in this paper, we comprehensively overview approaches on Graph CL and present a detailed survey of recent advances in this direction. Specifically, we first discuss the key challenges of Graph CL and provide its formal problem definition. Then, we categorize and summarize existing methods into three classes based on three kinds of graph machine learning tasks, i.e., node-level, link-level, and graph-level tasks. Finally, we share our thoughts on future research directions. To the best of our knowledge, this paper is the first survey for curriculum graph machine learning.
Disentangled Representation Learning
Nov 21, 2022



Disentangled Representation Learning (DRL) aims to learn a model capable of identifying and disentangling the underlying factors hidden in the observable data in representation form. The process of separating underlying factors of variation into variables with semantic meaning benefits in learning explainable representations of data, which imitates the meaningful understanding process of humans when observing an object or relation. As a general learning strategy, DRL has demonstrated its power in improving the model explainability, controlability, robustness, as well as generalization capacity in a wide range of scenarios such as computer vision, natural language processing, data mining etc. In this article, we comprehensively review DRL from various aspects including motivations, definitions, methodologies, evaluations, applications and model designs. We discuss works on DRL based on two well-recognized definitions, i.e., Intuitive Definition and Group Theory Definition. We further categorize the methodologies for DRL into four groups, i.e., Traditional Statistical Approaches, Variational Auto-encoder Based Approaches, Generative Adversarial Networks Based Approaches, Hierarchical Approaches and Other Approaches. We also analyze principles to design different DRL models that may benefit different tasks in practical applications. Finally, we point out challenges in DRL as well as potential research directions deserving future investigations. We believe this work may provide insights for promoting the DRL research in the community.
Domain Generalization through the Lens of Angular Invariance
Oct 28, 2022



Domain generalization (DG) aims at generalizing a classifier trained on multiple source domains to an unseen target domain with domain shift. A common pervasive theme in existing DG literature is domain-invariant representation learning with various invariance assumptions. However, prior works restrict themselves to a radical assumption for realworld challenges: If a mapping induced by a deep neural network (DNN) could align the source domains well, then such a mapping aligns a target domain as well. In this paper, we simply take DNNs as feature extractors to relax the requirement of distribution alignment. Specifically, we put forward a novel angular invariance and the accompanied norm shift assumption. Based on the proposed term of invariance, we propose a novel deep DG method called Angular Invariance Domain Generalization Network (AIDGN). The optimization objective of AIDGN is developed with a von-Mises Fisher (vMF) mixture model. Extensive experiments on multiple DG benchmark datasets validate the effectiveness of the proposed AIDGN method.
NeurIPS'22 Cross-Domain MetaDL competition: Design and baseline results
Aug 31, 2022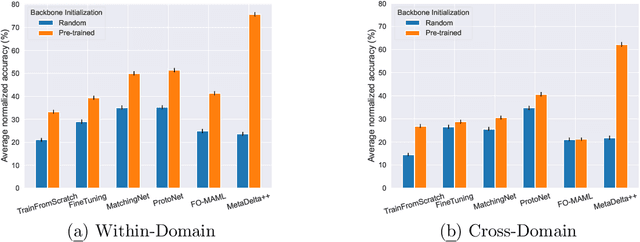

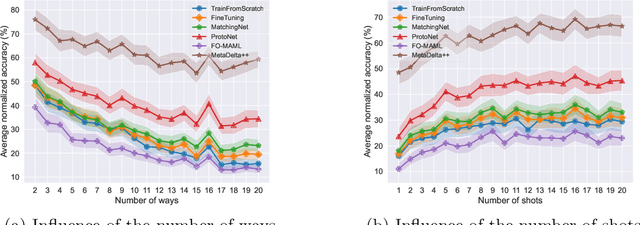

We present the design and baseline results for a new challenge in the ChaLearn meta-learning series, accepted at NeurIPS'22, focusing on "cross-domain" meta-learning. Meta-learning aims to leverage experience gained from previous tasks to solve new tasks efficiently (i.e., with better performance, little training data, and/or modest computational resources). While previous challenges in the series focused on within-domain few-shot learning problems, with the aim of learning efficiently N-way k-shot tasks (i.e., N class classification problems with k training examples), this competition challenges the participants to solve "any-way" and "any-shot" problems drawn from various domains (healthcare, ecology, biology, manufacturing, and others), chosen for their humanitarian and societal impact. To that end, we created Meta-Album, a meta-dataset of 40 image classification datasets from 10 domains, from which we carve out tasks with any number of "ways" (within the range 2-20) and any number of "shots" (within the range 1-20). The competition is with code submission, fully blind-tested on the CodaLab challenge platform. The code of the winners will be open-sourced, enabling the deployment of automated machine learning solutions for few-shot image classification across several domains.
Revisiting Adversarial Attacks on Graph Neural Networks for Graph Classification
Aug 13, 2022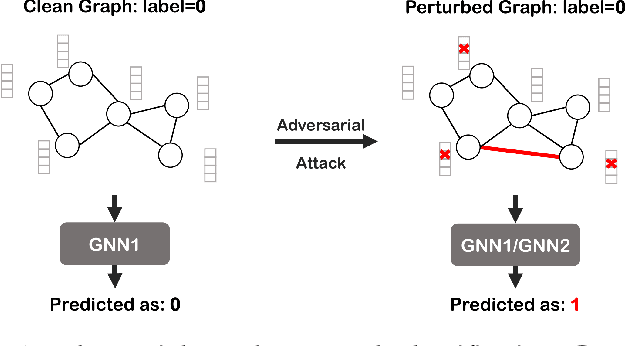
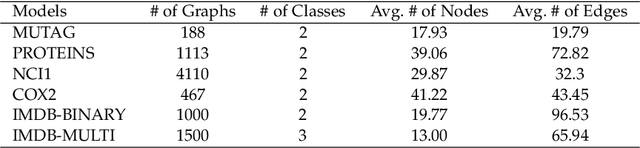
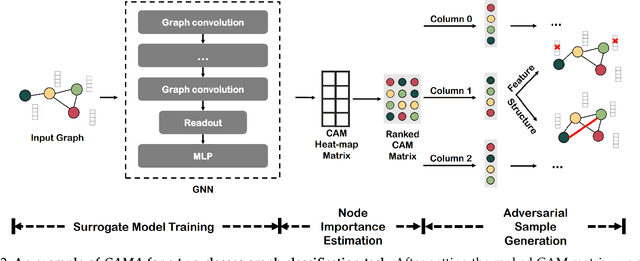
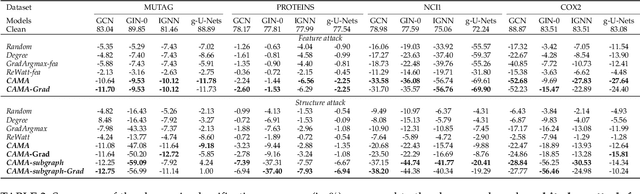
Graph neural networks (GNNs) have achieved tremendous success in the task of graph classification and diverse downstream real-world applications. Despite their success, existing approaches are either limited to structure attacks or restricted to local information. This calls for a more general attack framework on graph classification, which faces significant challenges due to the complexity of generating local-node-level adversarial examples using the global-graph-level information. To address this "global-to-local" problem, we present a general framework CAMA to generate adversarial examples by manipulating graph structure and node features in a hierarchical style. Specifically, we make use of Graph Class Activation Mapping and its variant to produce node-level importance corresponding to the graph classification task. Then through a heuristic design of algorithms, we can perform both feature and structure attacks under unnoticeable perturbation budgets with the help of both node-level and subgraph-level importance. Experiments towards attacking four state-of-the-art graph classification models on six real-world benchmarks verify the flexibility and effectiveness of our framework.