 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Swin-Transformer: Exploring a Hierarchical Transformer with Shifted Windows for Speech Emotion Recognition
Jan 19, 2024



Swin-Transformer has demonstrated remarkable success in computer vision by leveraging its hierarchical feature representation based on Transformer. In speech signals, emotional information is distributed across different scales of speech features, e.\,g., word, phrase, and utterance. Drawing above inspiration, this paper presents a hierarchical speech Transformer with shifted windows to aggregate multi-scale emotion features for speech emotion recognition (SER), called Speech Swin-Transformer. Specifically, we first divide the speech spectrogram into segment-level patches in the time domain, composed of multiple frame patches. These segment-level patches are then encoded using a stack of Swin blocks, in which a local window Transformer is utilized to explore local inter-frame emotional information across frame patches of each segment patch. After that, we also design a shifted window Transformer to compensate for patch correlations near the boundaries of segment patches. Finally, we employ a patch merging operation to aggregate segment-level emotional features for hierarchical speech representation by expanding the receptive field of Transformer from frame-level to segment-level. Experimental results demonstrate that our proposed Speech Swin-Transformer outperforms the state-of-the-art methods.
Improving Speaker-independent Speech Emotion Recognition Using Dynamic Joint Distribution Adaptation
Jan 18, 2024



In speaker-independent speech emotion recognition, the training and testing samples are collected from diverse speakers, leading to a multi-domain shift challenge across the feature distributions of data from different speakers. Consequently, when the trained model is confronted with data from new speakers, its performance tends to degrade. To address the issue, we propose a Dynamic Joint Distribution Adaptation (DJDA) method under the framework of multi-source domain adaptation. DJDA firstly utilizes joint distribution adaptation (JDA), involving marginal distribution adaptation (MDA) and conditional distribution adaptation (CDA), to more precisely measure the multi-domain distribution shifts caused by different speakers. This helps eliminate speaker bias in emotion features, allowing for learning discriminative and speaker-invariant speech emotion features from coarse-level to fine-level. Furthermore, we quantify the adaptation contributions of MDA and CDA within JDA by using a dynamic balance factor based on $\mathcal{A}$-Distance, promoting to effectively handle the unknown distributions encountered in data from new speakers. Experimental results demonstrate the superior performance of our DJDA as compared to other state-of-the-art (SOTA) methods.
Towards Domain-Specific Cross-Corpus Speech Emotion Recognition Approach
Dec 11, 2023Cross-corpus speech emotion recognition (SER) poses a challenge due to feature distribution mismatch, potentially degrading the performance of established SER methods. In this paper, we tackle this challenge by proposing a novel transfer subspace learning method called acoustic knowledgeguided transfer linear regression (AKTLR). Unlike existing approaches, which often overlook domain-specific knowledge related to SER and simply treat cross-corpus SER as a generic transfer learning task, our AKTLR method is built upon a well-designed acoustic knowledge-guided dual sparsity constraint mechanism. This mechanism emphasizes the potential of minimalistic acoustic parameter feature sets to alleviate classifier overadaptation, which is empirically validated acoustic knowledge in SER, enabling superior generalization in cross-corpus SER tasks compared to using large feature sets. Through this mechanism, we extend a simple transfer linear regression model to AKTLR. This extension harnesses its full capability to seek emotiondiscriminative and corpus-invariant features from established acoustic parameter feature sets used for describing speech signals across two scales: contributive acoustic parameter groups and constituent elements within each contributive group. Our proposed method is evaluated through extensive cross-corpus SER experiments on three widely-used speech emotion corpora: EmoDB, eNTERFACE, and CASIA. The results confirm the effectiveness and superior performance of our method, outperforming recent state-of-the-art transfer subspace learning and deep transfer learning-based cross-corpus SER methods. Furthermore, our work provides experimental evidence supporting the feasibility and superiority of incorporating domain-specific knowledge into the transfer learning model to address cross-corpus SER tasks.
An Empirical Study of Super-resolution on Low-resolution Micro-expression Recognition
Oct 16, 2023



Micro-expression recognition (MER) in low-resolution (LR) scenarios presents an important and complex challenge, particularly for practical applications such as group MER in crowded environments. Despite considerable advancements in super-resolution techniques for enhancing the quality of LR images and videos, few study has focused on investigate super-resolution for improving LR MER. The scarcity of investigation can be attributed to the inherent difficulty in capturing the subtle motions of micro-expressions, even in original-resolution MER samples, which becomes even more challenging in LR samples due to the loss of distinctive features. Furthermore, a lack of systematic benchmarking and thorough analysis of super-resolution-assisted MER methods has been noted. This paper tackles these issues by conducting a series of benchmark experiments that integrate both super-resolution (SR) and MER methods, guided by an in-depth literature survey. Specifically, we employ seven cutting-edge state-of-the-art (SOTA) MER techniques and evaluate their performance on samples generated from 13 SOTA SR techniques, thereby addressing the problem of super-resolution in MER. Through our empirical study, we uncover the primary challenges associated with SR-assisted MER and identify avenues to tackle these challenges by leveraging recent advancements in both SR and MER methodologies. Our analysis provides insights for progressing toward more efficient SR-assisted MER.
Learning to Rank Onset-Occurring-Offset Representations for Micro-Expression Recognition
Oct 07, 2023



This paper focuses on the research of micro-expression recognition (MER) and proposes a flexible and reliable deep learning method called learning to rank onset-occurring-offset representations (LTR3O). The LTR3O method introduces a dynamic and reduced-size sequence structure known as 3O, which consists of onset, occurring, and offset frames, for representing micro-expressions (MEs). This structure facilitates the subsequent learning of ME-discriminative features. A noteworthy advantage of the 3O structure is its flexibility, as the occurring frame is randomly extracted from the original ME sequence without the need for accurate frame spotting methods. Based on the 3O structures, LTR3O generates multiple 3O representation candidates for each ME sample and incorporates well-designed modules to measure and calibrate their emotional expressiveness. This calibration process ensures that the distribution of these candidates aligns with that of macro-expressions (MaMs) over time. Consequently, the visibility of MEs can be implicitly enhanced, facilitating the reliable learning of more discriminative features for MER. Extensive experiments were conducted to evaluate the performance of LTR3O using three widely-used ME databases: CASME II, SMIC, and SAMM. The experimental results demonstrate the effectiveness and superior performance of LTR3O, particularly in terms of its flexibility and reliability, when compared to recent state-of-the-art MER methods.
Towards A Robust Group-level Emotion Recognition via Uncertainty-Aware Learning
Oct 06, 2023



Group-level emotion recognition (GER) is an inseparable part of human behavior analysis, aiming to recognize an overall emotion in a multi-person scene. However, the existing methods are devoted to combing diverse emotion cues while ignoring the inherent uncertainties under unconstrained environments, such as congestion and occlusion occurring within a group. Additionally, since only group-level labels are available, inconsistent emotion predictions among individuals in one group can confuse the network. In this paper, we propose an uncertainty-aware learning (UAL) method to extract more robust representations for GER. By explicitly modeling the uncertainty of each individual, we utilize stochastic embedding drawn from a Gaussian distribution instead of deterministic point embedding. This representation captures the probabilities of different emotions and generates diverse predictions through this stochasticity during the inference stage. Furthermore, uncertainty-sensitive scores are adaptively assigned as the fusion weights of individuals' face within each group. Moreover, we develop an image enhancement module to enhance the model's robustness against severe noise. The overall three-branch model, encompassing face, object, and scene component, is guided by a proportional-weighted fusion strategy and integrates the proposed uncertainty-aware method to produce the final group-level output. Experimental results demonstrate the effectiveness and generalization ability of our method across three widely used databases.
Layer-Adapted Implicit Distribution Alignment Networks for Cross-Corpus Speech Emotion Recognition
Oct 06, 2023In this paper, we propose a new unsupervised domain adaptation (DA) method called layer-adapted implicit distribution alignment networks (LIDAN) to address the challenge of cross-corpus speech emotion recognition (SER). LIDAN extends our previous ICASSP work, deep implicit distribution alignment networks (DIDAN), whose key contribution lies in the introduction of a novel regularization term called implicit distribution alignment (IDA). This term allows DIDAN trained on source (training) speech samples to remain applicable to predicting emotion labels for target (testing) speech samples, regardless of corpus variance in cross-corpus SER. To further enhance this method, we extend IDA to layer-adapted IDA (LIDA), resulting in LIDAN. This layer-adpated extention consists of three modified IDA terms that consider emotion labels at different levels of granularity. These terms are strategically arranged within different fully connected layers in LIDAN, aligning with the increasing emotion-discriminative abilities with respect to the layer depth. This arrangement enables LIDAN to more effectively learn emotion-discriminative and corpus-invariant features for SER across various corpora compared to DIDAN. It is also worthy to mention that unlike most existing methods that rely on estimating statistical moments to describe pre-assumed explicit distributions, both IDA and LIDA take a different approach. They utilize an idea of target sample reconstruction to directly bridge the feature distribution gap without making assumptions about their distribution type. As a result, DIDAN and LIDAN can be viewed as implicit cross-corpus SER methods. To evaluate LIDAN, we conducted extensive cross-corpus SER experiments on EmoDB, eNTERFACE, and CASIA corpora. The experimental results demonstrate that LIDAN surpasses recent state-of-the-art explicit unsupervised DA methods in tackling cross-corpus SER tasks.
EEG-based Emotion Style Transfer Network for Cross-dataset Emotion Recognition
Aug 09, 2023



As the key to realizing aBCIs, EEG emotion recognition has been widely studied by many researchers. Previous methods have performed well for intra-subject EEG emotion recognition. However, the style mismatch between source domain (training data) and target domain (test data) EEG samples caused by huge inter-domain differences is still a critical problem for EEG emotion recognition. To solve the problem of cross-dataset EEG emotion recognition, in this paper, we propose an EEG-based Emotion Style Transfer Network (E2STN) to obtain EEG representations that contain the content information of source domain and the style information of target domain, which is called stylized emotional EEG representations. The representations are helpful for cross-dataset discriminative prediction. Concretely, E2STN consists of three modules, i.e., transfer module, transfer evaluation module, and discriminative prediction module. The transfer module encodes the domain-specific information of source and target domains and then re-constructs the source domain's emotional pattern and the target domain's statistical characteristics into the new stylized EEG representations. In this process, the transfer evaluation module is adopted to constrain the generated representations that can more precisely fuse two kinds of complementary information from source and target domains and avoid distorting. Finally, the generated stylized EEG representations are fed into the discriminative prediction module for final classification. Extensive experiments show that the E2STN can achieve the state-of-the-art performance on cross-dataset EEG emotion recognition tasks.
Deep Implicit Distribution Alignment Networks for Cross-Corpus Speech Emotion Recognition
Feb 17, 2023
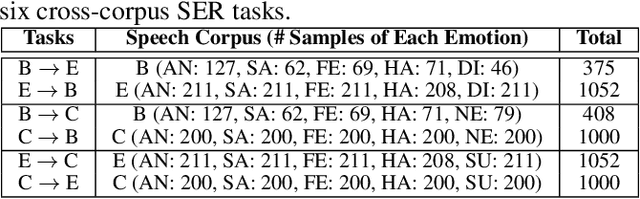
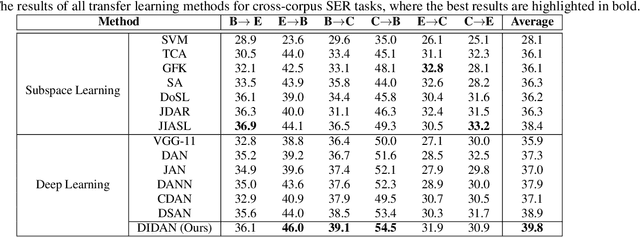
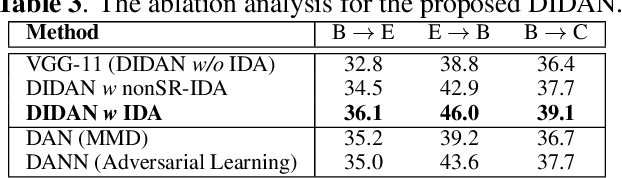
In this paper, we propose a novel deep transfer learning method called deep implicit distribution alignment networks (DIDAN) to deal with cross-corpus speech emotion recognition (SER) problem, in which the labeled training (source) and unlabeled testing (target) speech signals come from different corpora. Specifically, DIDAN first adopts a simple deep regression network consisting of a set of convolutional and fully connected layers to directly regress the source speech spectrums into the emotional labels such that the proposed DIDAN can own the emotion discriminative ability. Then, such ability is transferred to be also applicable to the target speech samples regardless of corpus variance by resorting to a well-designed regularization term called implicit distribution alignment (IDA). Unlike widely-used maximum mean discrepancy (MMD) and its variants, the proposed IDA absorbs the idea of sample reconstruction to implicitly align the distribution gap, which enables DIDAN to learn both emotion discriminative and corpus invariant features from speech spectrums. To evaluate the proposed DIDAN, extensive cross-corpus SER experiments on widely-used speech emotion corpora are carried out. Experimental results show that the proposed DIDAN can outperform lots of recent state-of-the-art methods in coping with the cross-corpus SER tasks.
SDFE-LV: A Large-Scale, Multi-Source, and Unconstrained Database for Spotting Dynamic Facial Expressions in Long Videos
Sep 18, 2022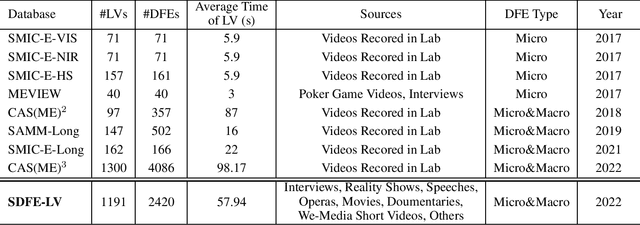
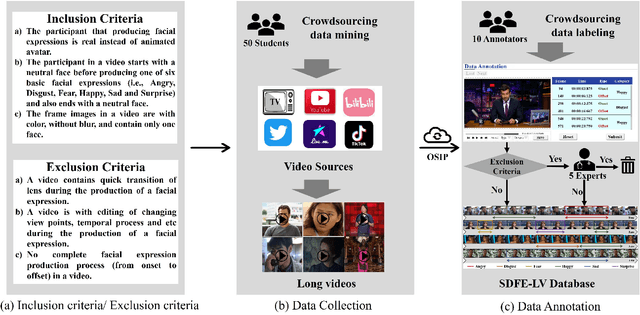
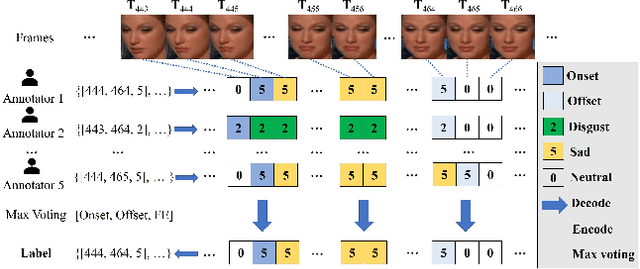

In this paper, we present a large-scale, multi-source, and unconstrained database called SDFE-LV for spotting the onset and offset frames of a complete dynamic facial expression from long videos, which is known as the topic of dynamic facial expression spotting (DFES) and a vital prior step for lots of facial expression analysis tasks. Specifically, SDFE-LV consists of 1,191 long videos, each of which contains one or more complete dynamic facial expressions. Moreover, each complete dynamic facial expression in its corresponding long video was independently labeled for five times by 10 well-trained annotators. To the best of our knowledge, SDFE-LV is the first unconstrained large-scale database for the DFES task whose long videos are collected from multiple real-world/closely real-world media sources, e.g., TV interviews, documentaries, movies, and we-media short videos. Therefore, DFES tasks on SDFE-LV database will encounter numerous difficulties in practice such as head posture changes, occlusions, and illumination. We also provided a comprehensive benchmark evaluation from different angles by using lots of recent state-of-the-art deep spotting methods and hence researchers interested in DFES can quickly and easily get started. Finally, with the deep discussions on the experimental evaluation results, we attempt to point out several meaningful directions to deal with DFES tasks and hope that DFES can be better advanced in the future. In addition, SDFE-LV will be freely released for academic use only as soon as possible.