 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Transferable Facial Emotion Representations from Large-Scale Semantically Rich Captions
Jul 28, 2025Current facial emotion recognition systems are predominately trained to predict a fixed set of predefined categories or abstract dimensional values. This constrained form of supervision hinders generalization and applicability, as it reduces the rich and nuanced spectrum of emotions into oversimplified labels or scales. In contrast, natural language provides a more flexible, expressive, and interpretable way to represent emotions, offering a much broader source of supervision. Yet, leveraging semantically rich natural language captions as supervisory signals for facial emotion representation learning remains relatively underexplored, primarily due to two key challenges: 1) the lack of large-scale caption datasets with rich emotional semantics, and 2) the absence of effective frameworks tailored to harness such rich supervision. To this end, we introduce EmoCap100K, a large-scale facial emotion caption dataset comprising over 100,000 samples, featuring rich and structured semantic descriptions that capture both global affective states and fine-grained local facial behaviors. Building upon this dataset, we further propose EmoCapCLIP, which incorporates a joint global-local contrastive learning framework enhanced by a cross-modal guided positive mining module. This design facilitates the comprehensive exploitation of multi-level caption information while accommodating semantic similarities between closely related expressions. Extensive evaluations on over 20 benchmarks covering five tasks demonstrate the superior performance of our method, highlighting the promise of learning facial emotion representations from large-scale semantically rich captions. The code and data will be available at https://github.com/sunlicai/EmoCapCLIP.
Infused Suppression Of Magnification Artefacts For Micro-AU Detection
Apr 12, 2025Facial micro-expressions are spontaneous, brief and subtle facial motions that unveil the underlying, suppressed emotions. Detecting Action Units (AUs) in micro-expressions is crucial because it yields a finer representation of facial motions than categorical emotions, effectively resolving the ambiguity among different expressions. One of the difficulties in micro-expression analysis is that facial motions are subtle and brief, thereby increasing the difficulty in correlating facial motion features to AU occurrence. To bridge the subtlety issue, flow-related features and motion magnification are a few common approaches as they can yield descriptive motion changes and increased motion amplitude respectively. While motion magnification can amplify the motion changes, it also accounts for illumination changes and projection errors during the amplification process, thereby creating motion artefacts that confuse the model to learn inauthentic magnified motion features. The problem is further aggravated in the context of a more complicated task where more AU classes are analyzed in cross-database settings. To address this issue, we propose InfuseNet, a layer-wise unitary feature infusion framework that leverages motion context to constrain the Action Unit (AU) learning within an informative facial movement region, thereby alleviating the influence of magnification artefacts. On top of that, we propose leveraging magnified latent features instead of reconstructing magnified samples to limit the distortion and artefacts caused by the projection inaccuracy in the motion reconstruction process. Via alleviating the magnification artefacts, InfuseNet has surpassed the state-of-the-art results in the CD6ME protocol. Further quantitative studies have also demonstrated the efficacy of motion artefacts alleviation.
Towards Consistent and Controllable Image Synthesis for Face Editing
Feb 04, 2025Current face editing methods mainly rely on GAN-based techniques, but recent focus has shifted to diffusion-based models due to their success in image reconstruction. However, diffusion models still face challenges in manipulating fine-grained attributes and preserving consistency of attributes that should remain unchanged. To address these issues and facilitate more convenient editing of face images, we propose a novel approach that leverages the power of Stable-Diffusion models and crude 3D face models to control the lighting, facial expression and head pose of a portrait photo. We observe that this task essentially involve combinations of target background, identity and different face attributes. We aim to sufficiently disentangle the control of these factors to enable high-quality of face editing. Specifically, our method, coined as RigFace, contains: 1) A Spatial Arrtibute Encoder that provides presise and decoupled conditions of background, pose, expression and lighting; 2) An Identity Encoder that transfers identity features to the denoising UNet of a pre-trained Stable-Diffusion model; 3) An Attribute Rigger that injects those conditions into the denoising UNet. Our model achieves comparable or even superior performance in both identity preservation and photorealism compared to existing face editing models.
MagicFace: High-Fidelity Facial Expression Editing with Action-Unit Control
Jan 04, 2025



We address the problem of facial expression editing by controling the relative variation of facial action-unit (AU) from the same person. This enables us to edit this specific person's expression in a fine-grained, continuous and interpretable manner, while preserving their identity, pose, background and detailed facial attributes. Key to our model, which we dub MagicFace, is a diffusion model conditioned on AU variations and an ID encoder to preserve facial details of high consistency. Specifically, to preserve the facial details with the input identity, we leverage the power of pretrained Stable-Diffusion models and design an ID encoder to merge appearance features through self-attention. To keep background and pose consistency, we introduce an efficient Attribute Controller by explicitly informing the model of current background and pose of the target. By injecting AU variations into a denoising UNet, our model can animate arbitrary identities with various AU combinations, yielding superior results in high-fidelity expression editing compared to other facial expression editing works. Code is publicly available at https://github.com/weimengting/MagicFace.
SDFE-LV: A Large-Scale, Multi-Source, and Unconstrained Database for Spotting Dynamic Facial Expressions in Long Videos
Sep 18, 2022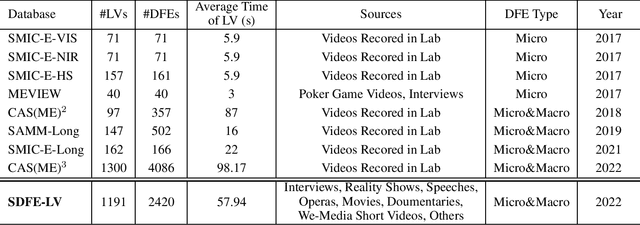
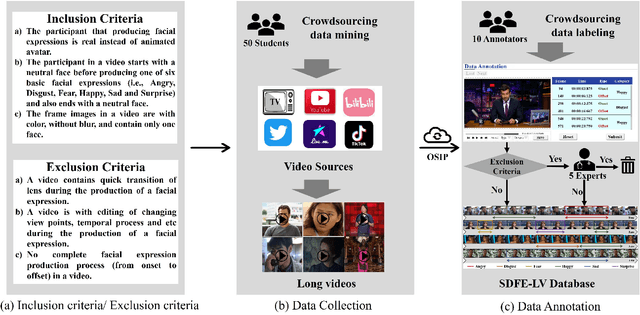
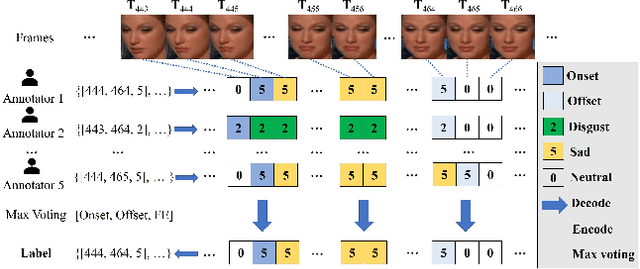

In this paper, we present a large-scale, multi-source, and unconstrained database called SDFE-LV for spotting the onset and offset frames of a complete dynamic facial expression from long videos, which is known as the topic of dynamic facial expression spotting (DFES) and a vital prior step for lots of facial expression analysis tasks. Specifically, SDFE-LV consists of 1,191 long videos, each of which contains one or more complete dynamic facial expressions. Moreover, each complete dynamic facial expression in its corresponding long video was independently labeled for five times by 10 well-trained annotators. To the best of our knowledge, SDFE-LV is the first unconstrained large-scale database for the DFES task whose long videos are collected from multiple real-world/closely real-world media sources, e.g., TV interviews, documentaries, movies, and we-media short videos. Therefore, DFES tasks on SDFE-LV database will encounter numerous difficulties in practice such as head posture changes, occlusions, and illumination. We also provided a comprehensive benchmark evaluation from different angles by using lots of recent state-of-the-art deep spotting methods and hence researchers interested in DFES can quickly and easily get started. Finally, with the deep discussions on the experimental evaluation results, we attempt to point out several meaningful directions to deal with DFES tasks and hope that DFES can be better advanced in the future. In addition, SDFE-LV will be freely released for academic use only as soon as possible.
Seeking Salient Facial Regions for Cross-Database Micro-Expression Recognition
Nov 30, 2021

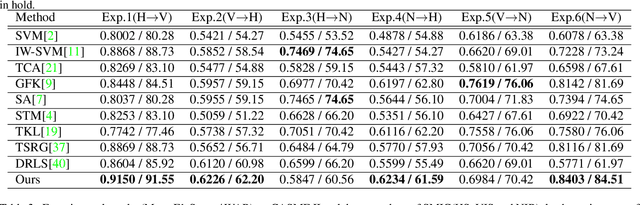
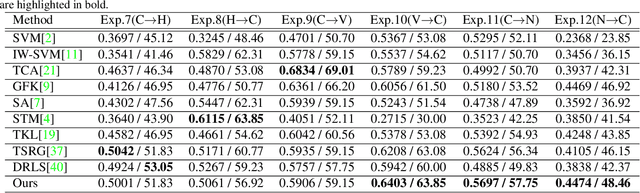
This paper focuses on the research of cross-database micro-expression recognition, in which the training and test micro-expression samples belong to different microexpression databases. Mismatched feature distributions between the training and testing micro-expression feature degrade the performance of most well-performing micro-expression methods. To deal with cross-database micro-expression recognition, we propose a novel domain adaption method called Transfer Group Sparse Regression (TGSR). TGSR learns a sparse regression matrix for selecting salient facial local regions and the corresponding relationship of the training set and test set. We evaluate our TGSR model in CASME II and SMIC databases. Experimental results show that the proposed TGSR achieves satisfactory performance and outperforms most state-of-the-art subspace learning-based domain adaption methods.
DFEW: A Large-Scale Database for Recognizing Dynamic Facial Expressions in the Wild
Aug 13, 2020
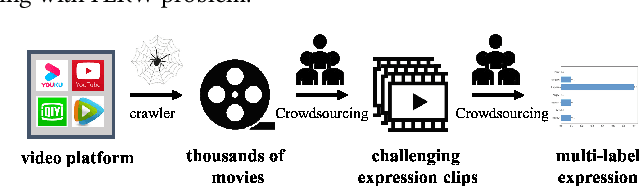

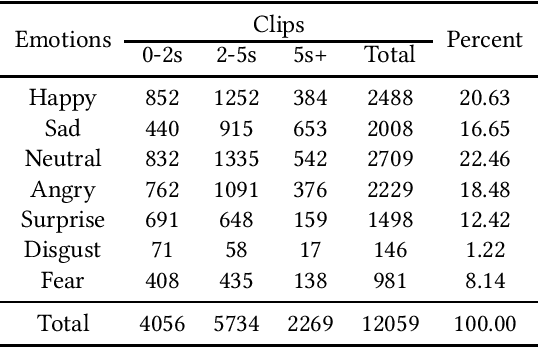
Recently, facial expression recognition (FER) in the wild has gained a lot of researchers' attention because it is a valuable topic to enable the FER techniques to move from the laboratory to the real applications. In this paper, we focus on this challenging but interesting topic and make contributions from three aspects. First, we present a new large-scale 'in-the-wild' dynamic facial expression database, DFEW (Dynamic Facial Expression in the Wild), consisting of over 16,000 video clips from thousands of movies. These video clips contain various challenging interferences in practical scenarios such as extreme illumination, occlusions, and capricious pose changes. Second, we propose a novel method called Expression-Clustered Spatiotemporal Feature Learning (EC-STFL) framework to deal with dynamic FER in the wild. Third, we conduct extensive benchmark experiments on DFEW using a lot of spatiotemporal deep feature learning methods as well as our proposed EC-STFL. Experimental results show that DFEW is a well-designed and challenging database, and the proposed EC-STFL can promisingly improve the performance of existing spatiotemporal deep neural networks in coping with the problem of dynamic FER in the wild. Our DFEW database is publicly available and can be freely downloaded from https://dfew-dataset.github.io/.