 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaRA: Metamorphic Robustness Assessment for Multimodal Large Language Model-based Visual Question Answering Systems
May 19, 2026Visual Question Answering (VQA), as the representative multimodal task, serves as a key benchmark for evaluating the reasoning capabilities of Multimodal Large Language Models (MLLMs). However, existing evaluations largely rely on static datasets and accuracy-based metrics, which fail to capture robustness, consistency, and generalization. Inspired by Metamorphic Testing (MT), we propose Metamorphic Robustness Assessment (MetaRA), a testing framework that employs Metamorphic Relations (MRs) to systematically probe vulnerabilities in MLLM-based VQA systems. MetaRA generates controlled variations of image-question inputs based on specific MRs and evaluates models across diverse conditions. Applying MetaRA to multiple MLLM-based VQA models across different tasks reveals nuanced failure patterns, including sensitivity to linguistic perturbations, over-reliance on superficial visual cues, and deeper weaknesses in multimodal reasoning. Experimental results demonstrate that MetaRA provides richer diagnostic insights than conventional accuracy metrics, exposing failure modes that remain hidden under standard benchmarks. Overall, this work highlights the need for systematic robustness evaluation in VQA and positions metamorphic assessment as a scalable, model-agnostic approach toward trustworthy multimodal AI.
Enhancing Visual Question Answering with Multimodal LLMs via Chain-of-Question Guided Retrieval-Augmented Generation
May 05, 2026With advances in multimodal research and deep learning, Multimodal Large Language Models (MLLMs) have emerged as a powerful paradigm for a wide range of multimodal tasks. As a core problem in vision-language research, Visual Question Answering (VQA) has increasingly employed MLLMs to improve performance, particularly in open-domain settings where external knowledge is essential. In this work, we aim to further enhance retrieval-based VQA by more effectively integrating MLLMs with structured reasoning and knowledge acquisition. We introduce a logical prompting strategy that fuses Chain-of-Thought (CoT) reasoning with Visual Question Decomposition (VQD), termed CoVQD, to guide retrieval toward more accurate and relevant knowledge for MLLM inference. Building on this idea, we propose a new framework, CoVQD-guided RAG (CgRAG), which enables MLLMs to access more comprehensive and coherent external knowledge while benefiting from structured visual-text reasoning guidance, thereby improving generalization and reliability in complex cross-domain VQA scenarios. Extensive experiments on E-VQA, InfoSeek, and OKVQA benchmarks demonstrate the effectiveness of the proposed method.
PC-MNet: Dual-Level Congruity Modeling for Multimodal Sarcasm Detection via Polarity-Modulated Attention
May 04, 2026Multimodal sarcasm detection, which aims to precisely identify pragmatic incongruities between literal text and nonverbal cues, has gained substantial attention in multimodal understanding. Recent advancements have predominantly relied on naïve similarity-based attention mechanisms and uniform late fusion strategies.Furthermore, given that functional entanglement restricts traditional late fusions, we incorporate a scalar congruity routing mechanism and a prior-guided contextual graph. This mechanism anchors a generalized incongruity manifold through a two-stage asymmetric optimization driven by inconsistency-aware contrastive learning, selectively fusing only the most discriminative multi-granularity evidence. Extensive experiments on the \texttt{MUStARD} benchmark and its spurious-correlation-mitigated balanced datasets demonstrate that our approach achieves new state-of-the-art performance, surpassing the strongest multimodal baseline by a substantial 3.14\% improvement in Macro-F1. By architecturally isolating atomic, composition, and contextual conflicts. This work provides a robust, decoupled paradigm for modeling subtle pragmatic incongruities in human communication.
HABD: a houma alliance book ancient handwritten character recognition database
Aug 26, 2024



The Houma Alliance Book, one of history's earliest calligraphic examples, was unearthed in the 1970s. These artifacts were meticulously organized, reproduced, and copied by the Shanxi Provincial Institute of Cultural Relics. However, because of their ancient origins and severe ink erosion, identifying characters in the Houma Alliance Book is challenging, necessitating the use of digital technology. In this paper, we propose a new ancient handwritten character recognition database for the Houma alliance book, along with a novel benchmark based on deep learning architectures. More specifically, a collection of 26,732 characters samples from the Houma Alliance Book were gathered, encompassing 327 different types of ancient characters through iterative annotation. Furthermore, benchmark algorithms were proposed by combining four deep neural network classifiers with two data augmentation methods. This research provides valuable resources and technical support for further studies on the Houma Alliance Book and other ancient characters. This contributes to our understanding of ancient culture and history, as well as the preservation and inheritance of humanity's cultural heritage.
An Empirical Study of Super-resolution on Low-resolution Micro-expression Recognition
Oct 16, 2023



Micro-expression recognition (MER) in low-resolution (LR) scenarios presents an important and complex challenge, particularly for practical applications such as group MER in crowded environments. Despite considerable advancements in super-resolution techniques for enhancing the quality of LR images and videos, few study has focused on investigate super-resolution for improving LR MER. The scarcity of investigation can be attributed to the inherent difficulty in capturing the subtle motions of micro-expressions, even in original-resolution MER samples, which becomes even more challenging in LR samples due to the loss of distinctive features. Furthermore, a lack of systematic benchmarking and thorough analysis of super-resolution-assisted MER methods has been noted. This paper tackles these issues by conducting a series of benchmark experiments that integrate both super-resolution (SR) and MER methods, guided by an in-depth literature survey. Specifically, we employ seven cutting-edge state-of-the-art (SOTA) MER techniques and evaluate their performance on samples generated from 13 SOTA SR techniques, thereby addressing the problem of super-resolution in MER. Through our empirical study, we uncover the primary challenges associated with SR-assisted MER and identify avenues to tackle these challenges by leveraging recent advancements in both SR and MER methodologies. Our analysis provides insights for progressing toward more efficient SR-assisted MER.
Towards A Robust Group-level Emotion Recognition via Uncertainty-Aware Learning
Oct 06, 2023



Group-level emotion recognition (GER) is an inseparable part of human behavior analysis, aiming to recognize an overall emotion in a multi-person scene. However, the existing methods are devoted to combing diverse emotion cues while ignoring the inherent uncertainties under unconstrained environments, such as congestion and occlusion occurring within a group. Additionally, since only group-level labels are available, inconsistent emotion predictions among individuals in one group can confuse the network. In this paper, we propose an uncertainty-aware learning (UAL) method to extract more robust representations for GER. By explicitly modeling the uncertainty of each individual, we utilize stochastic embedding drawn from a Gaussian distribution instead of deterministic point embedding. This representation captures the probabilities of different emotions and generates diverse predictions through this stochasticity during the inference stage. Furthermore, uncertainty-sensitive scores are adaptively assigned as the fusion weights of individuals' face within each group. Moreover, we develop an image enhancement module to enhance the model's robustness against severe noise. The overall three-branch model, encompassing face, object, and scene component, is guided by a proportional-weighted fusion strategy and integrates the proposed uncertainty-aware method to produce the final group-level output. Experimental results demonstrate the effectiveness and generalization ability of our method across three widely used databases.
EMC2A-Net: An Efficient Multibranch Cross-channel Attention Network for SAR Target Classification
Aug 03, 2022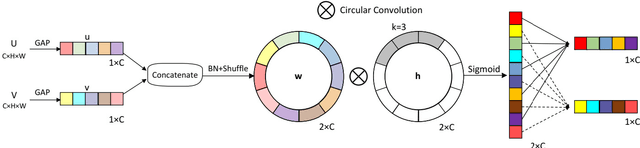
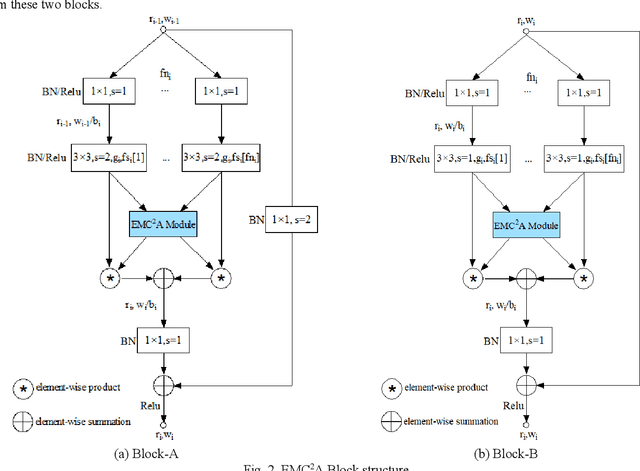
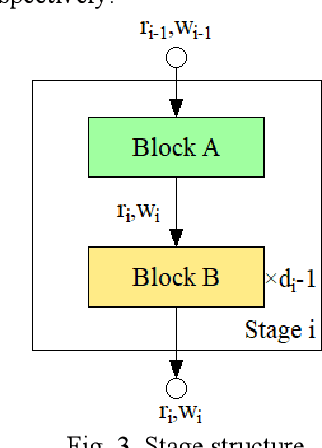
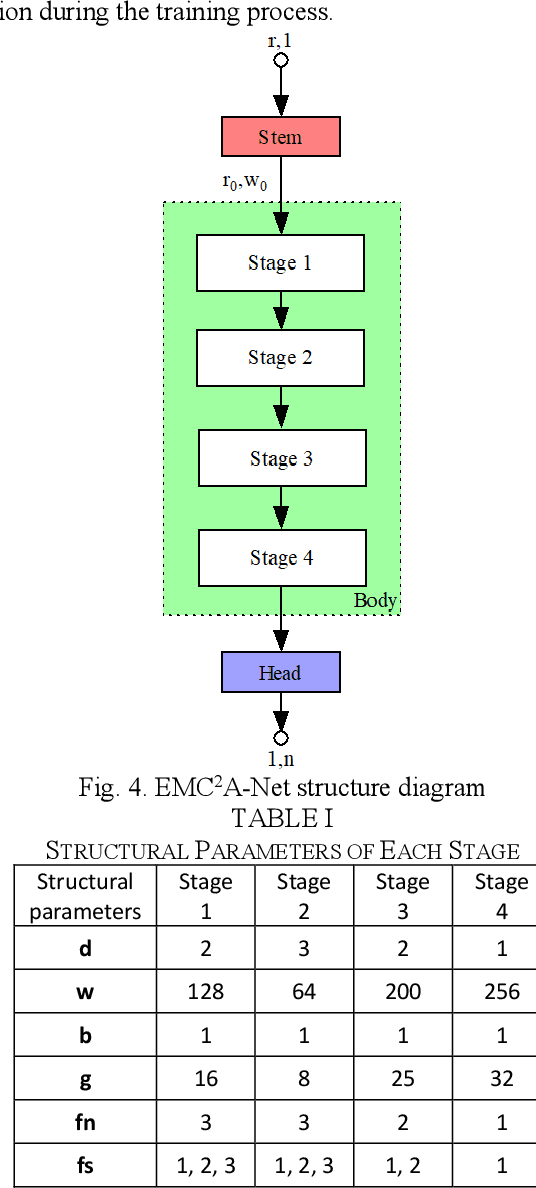
In recent years, convolutional neural networks (CNNs) have shown great potential in synthetic aperture radar (SAR) target recognition. SAR images have a strong sense of granularity and have different scales of texture features, such as speckle noise, target dominant scatterers and target contours, which are rarely considered in the traditional CNN model. This paper proposed two residual blocks, namely EMC2A blocks with multiscale receptive fields(RFs), based on a multibranch structure and then designed an efficient isotopic architecture deep CNN (DCNN), EMC2A-Net. EMC2A blocks utilize parallel dilated convolution with different dilation rates, which can effectively capture multiscale context features without significantly increasing the computational burden. To further improve the efficiency of multiscale feature fusion, this paper proposed a multiscale feature cross-channel attention module, namely the EMC2A module, adopting a local multiscale feature interaction strategy without dimensionality reduction. This strategy adaptively adjusts the weights of each channel through efficient one-dimensional (1D)-circular convolution and sigmoid function to guide attention at the global channel wise level. The comparative results on the MSTAR dataset show that EMC2A-Net outperforms the existing available models of the same type and has relatively lightweight network structure. The ablation experiment results show that the EMC2A module significantly improves the performance of the model by using only a few parameters and appropriate cross-channel interactions.
A new database of Houma Alliance Book ancient handwritten characters and its baseline algorithm
Jul 17, 2022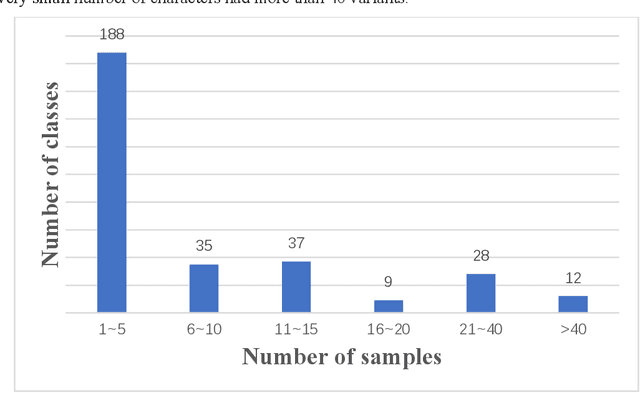

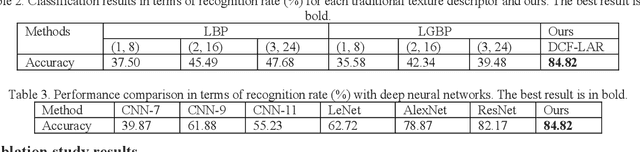

The Houma Alliance Book is one of the national treasures of the Museum in Shanxi Museum Town in China. It has great historical significance in researching ancient history. To date, the research on the Houma Alliance Book has been staying in the identification of paper documents, which is inefficient to identify and difficult to display, study and publicize. Therefore, the digitization of the recognized ancient characters of Houma League can effectively improve the efficiency of recognizing ancient characters and provide more reliable technical support and text data. This paper proposes a new database of Houma Alliance Book ancient handwritten characters and a multi-modal fusion method to recognize ancient handwritten characters. In the database, 297 classes and 3,547 samples of Houma Alliance ancient handwritten characters are collected from the original book collection and by human imitative writing. Furthermore, the decision-level classifier fusion strategy is applied to fuse three well-known deep neural network architectures for ancient handwritten character recognition. Experiments are performed on our new database. The experimental results first provide the baseline result of the new database to the research community and then demonstrate the efficiency of our proposed method.
Region attention and graph embedding network for occlusion objective class-based micro-expression recognition
Jul 13, 2021
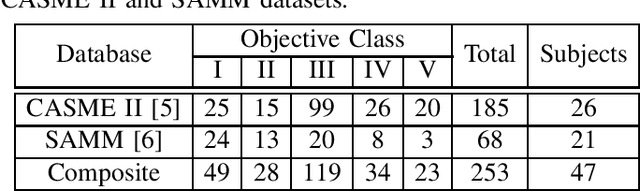
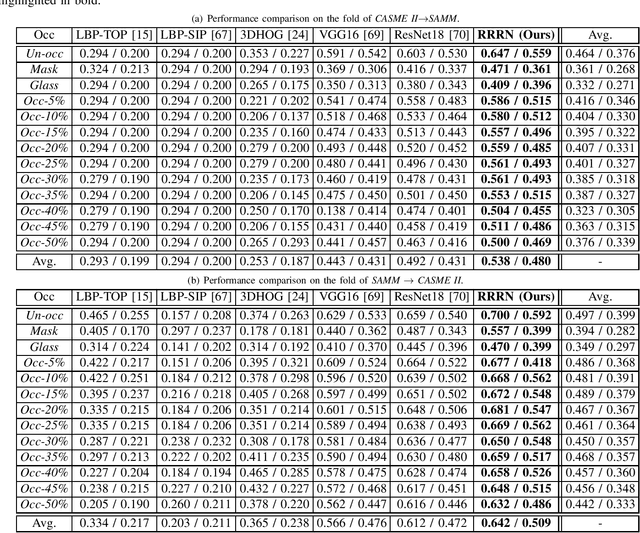
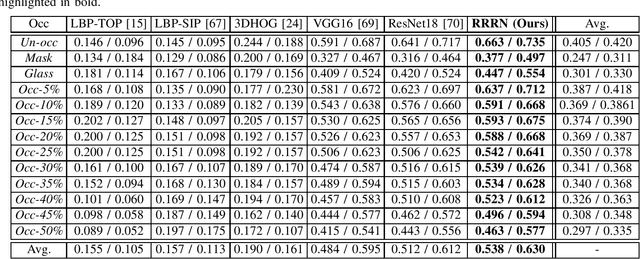
Micro-expression recognition (\textbf{MER}) has attracted lots of researchers' attention in a decade. However, occlusion will occur for MER in real-world scenarios. This paper deeply investigates an interesting but unexplored challenging issue in MER, \ie, occlusion MER. First, to research MER under real-world occlusion, synthetic occluded micro-expression databases are created by using various mask for the community. Second, to suppress the influence of occlusion, a \underline{R}egion-inspired \underline{R}elation \underline{R}easoning \underline{N}etwork (\textbf{RRRN}) is proposed to model relations between various facial regions. RRRN consists of a backbone network, the Region-Inspired (\textbf{RI}) module and Relation Reasoning (\textbf{RR}) module. More specifically, the backbone network aims at extracting feature representations from different facial regions, RI module computing an adaptive weight from the region itself based on attention mechanism with respect to the unobstructedness and importance for suppressing the influence of occlusion, and RR module exploiting the progressive interactions among these regions by performing graph convolutions. Experiments are conducted on handout-database evaluation and composite database evaluation tasks of MEGC 2018 protocol. Experimental results show that RRRN can significantly explore the importance of facial regions and capture the cooperative complementary relationship of facial regions for MER. The results also demonstrate RRRN outperforms the state-of-the-art approaches, especially on occlusion, and RRRN acts more robust to occlusion.
Feature refinement: An expression-specific feature learning and fusion method for micro-expression recognition
Jan 13, 2021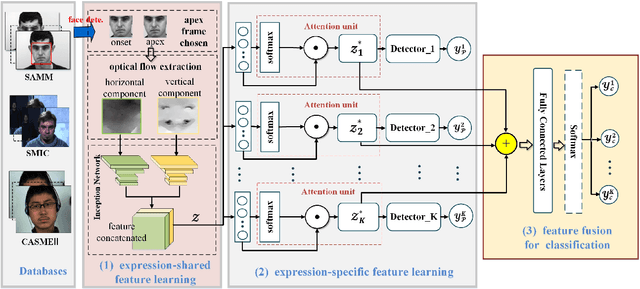

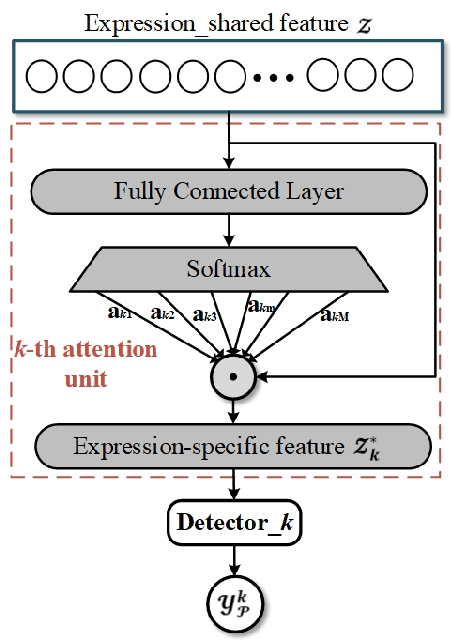
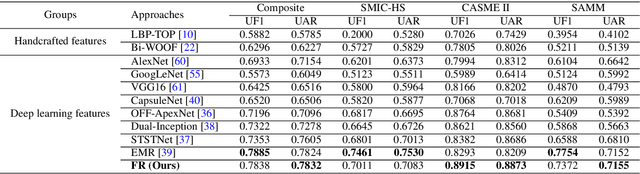
Micro-Expression Recognition has become challenging, as it is extremely difficult to extract the subtle facial changes of micro-expressions. Recently, several approaches proposed several expression-shared features algorithms for micro-expression recognition. However, they do not reveal the specific discriminative characteristics, which lead to sub-optimal performance. This paper proposes a novel Feature Refinement ({FR}) with expression-specific feature learning and fusion for micro-expression recognition. It aims to obtain salient and discriminative features for specific expressions and also predict expression by fusing the expression-specific features. FR consists of an expression proposal module with attention mechanism and a classification branch. First, an inception module is designed based on optical flow to obtain expression-shared features. Second, in order to extract salient and discriminative features for specific expression, expression-shared features are fed into an expression proposal module with attention factors and proposal loss. Last, in the classification branch, labels of categories are predicted by a fusion of the expression-specific features. Experiments on three publicly available databases validate the effectiveness of FR under different protocol. Results on public benchmarks demonstrate that our FR provides salient and discriminative information for micro-expression recognition. The results also show our FR achieves better or competitive performance with the existing state-of-the-art methods on micro-expression recognition.