 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Scale Semantics-Guided Neural Networks for Efficient Skeleton-Based Human Action Recognition
Nov 07, 2021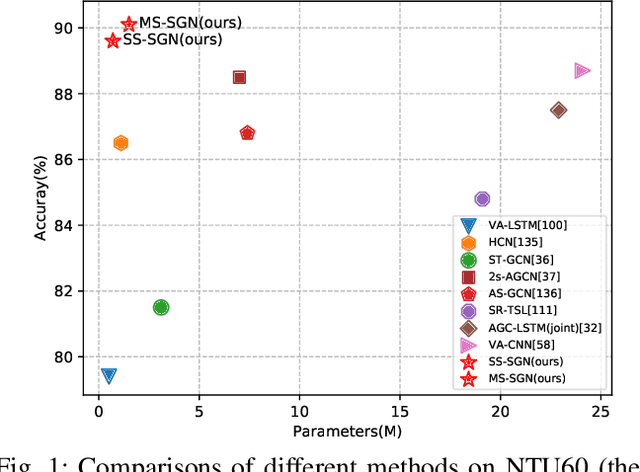

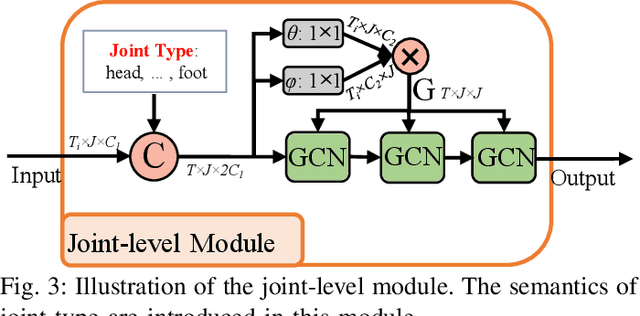
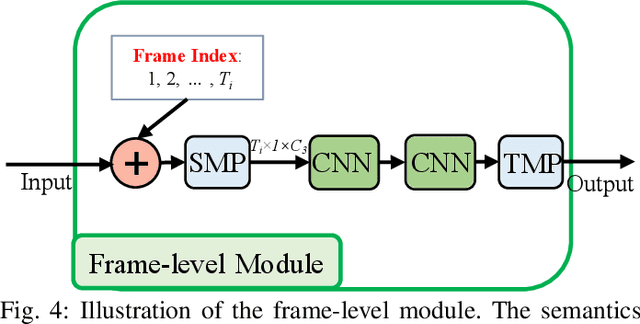
Skeleton data is of low dimension. However, there is a trend of using very deep and complicated feedforward neural networks to model the skeleton sequence without considering the complexity in recent year. In this paper, a simple yet effective multi-scale semantics-guided neural network (MS-SGN) is proposed for skeleton-based action recognition. We explicitly introduce the high level semantics of joints (joint type and frame index) into the network to enhance the feature representation capability of joints. Moreover, a multi-scale strategy is proposed to be robust to the temporal scale variations. In addition, we exploit the relationship of joints hierarchically through two modules, i.e., a joint-level module for modeling the correlations of joints in the same frame and a frame-level module for modeling the temporal dependencies of frames. With an order of magnitude smaller model size than most previous methods, MSSGN achieves the state-of-the-art performance on the NTU60, NTU120, and SYSU datasets.
Skeleton-Based Mutually Assisted Interacted Object Localization and Human Action Recognition
Oct 28, 2021
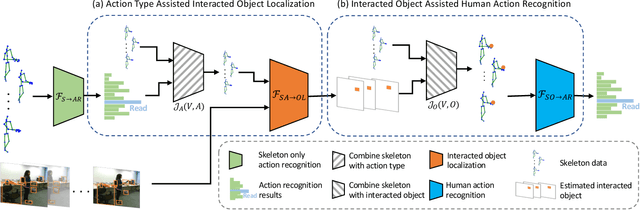

Skeleton data carries valuable motion information and is widely explored in human action recognition. However, not only the motion information but also the interaction with the environment provides discriminative cues to recognize the action of persons. In this paper, we propose a joint learning framework for mutually assisted "interacted object localization" and "human action recognition" based on skeleton data. The two tasks are serialized together and collaborate to promote each other, where preliminary action type derived from skeleton alone helps improve interacted object localization, which in turn provides valuable cues for the final human action recognition. Besides, we explore the temporal consistency of interacted object as constraint to better localize the interacted object with the absence of ground-truth labels. Extensive experiments on the datasets of SYSU-3D, NTU60 RGB+D and Northwestern-UCLA show that our method achieves the best or competitive performance with the state-of-the-art methods for human action recognition. Visualization results show that our method can also provide reasonable interacted object localization results.
WEDGE: Web-Image Assisted Domain Generalization for Semantic Segmentation
Sep 29, 2021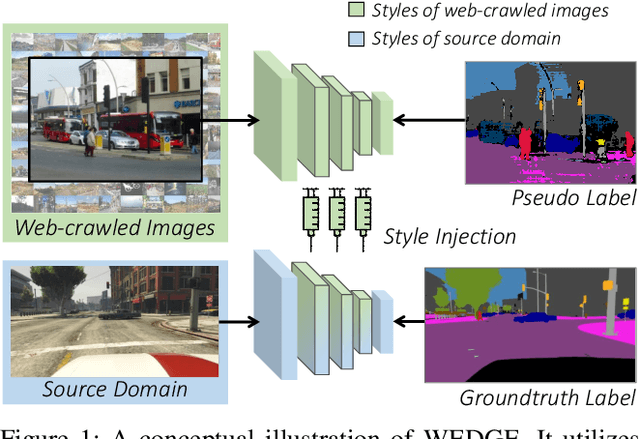
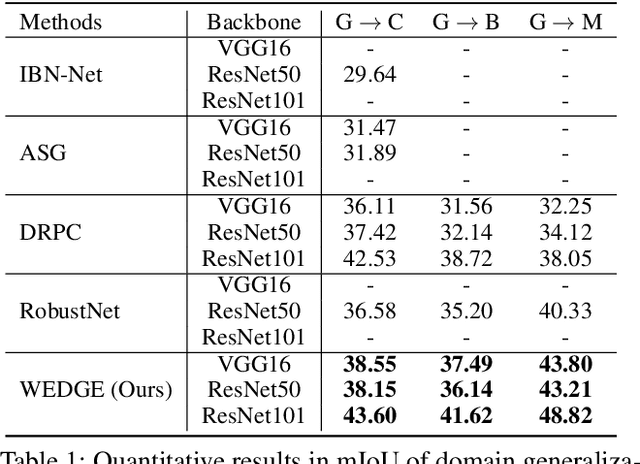
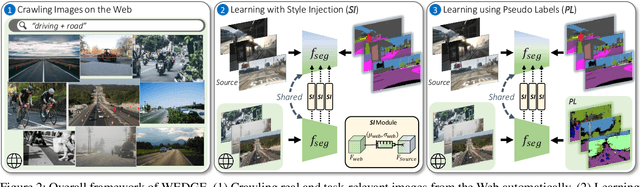
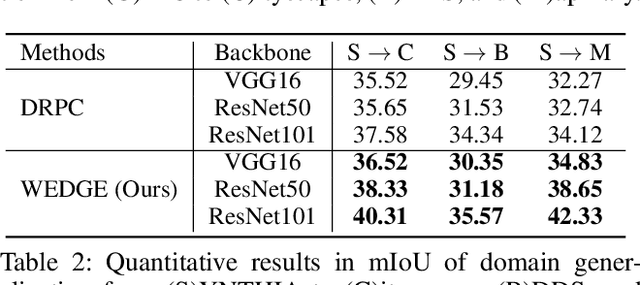
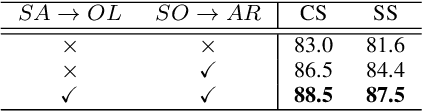
Domain generalization for semantic segmentation is highly demanded in real applications, where a trained model is expected to work well in previously unseen domains. One challenge lies in the lack of data which could cover the diverse distributions of the possible unseen domains for training. In this paper, we propose a WEb-image assisted Domain GEneralization (WEDGE) scheme, which is the first to exploit the diversity of web-crawled images for generalizable semantic segmentation. To explore and exploit the real-world data distributions, we collect a web-crawled dataset which presents large diversity in terms of weather conditions, sites, lighting, camera styles, etc. We also present a method which injects the style representation of the web-crawled data into the source domain on-the-fly during training, which enables the network to experience images of diverse styles with reliable labels for effective training. Moreover, we use the web-crawled dataset with predicted pseudo labels for training to further enhance the capability of the network. Extensive experiments demonstrate that our method clearly outperforms existing domain generalization techniques.
Zero-Shot Text-to-Speech for Text-Based Insertion in Audio Narration
Sep 12, 2021
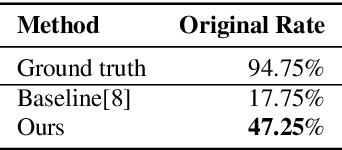
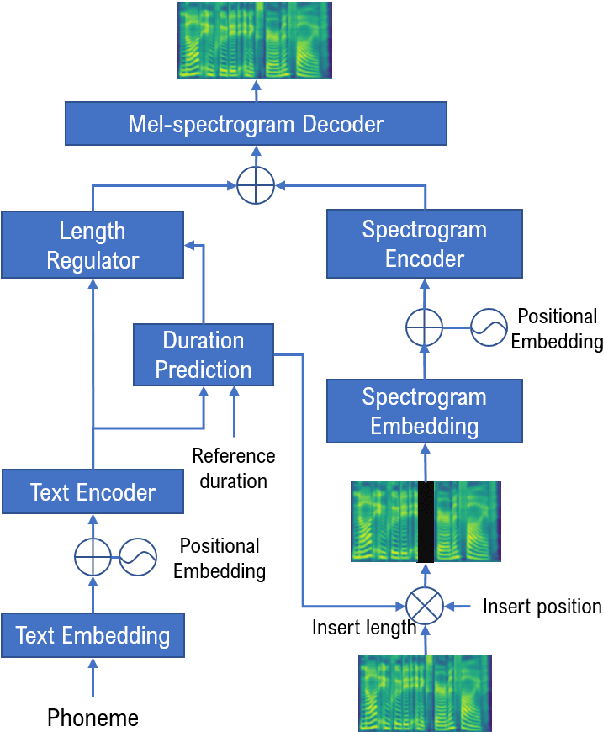
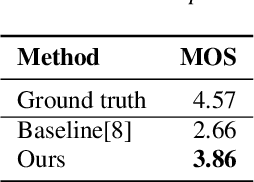
Given a piece of speech and its transcript text, text-based speech editing aims to generate speech that can be seamlessly inserted into the given speech by editing the transcript. Existing methods adopt a two-stage approach: synthesize the input text using a generic text-to-speech (TTS) engine and then transform the voice to the desired voice using voice conversion (VC). A major problem of this framework is that VC is a challenging problem which usually needs a moderate amount of parallel training data to work satisfactorily. In this paper, we propose a one-stage context-aware framework to generate natural and coherent target speech without any training data of the target speaker. In particular, we manage to perform accurate zero-shot duration prediction for the inserted text. The predicted duration is used to regulate both text embedding and speech embedding. Then, based on the aligned cross-modality input, we directly generate the mel-spectrogram of the edited speech with a transformer-based decoder. Subjective listening tests show that despite the lack of training data for the speaker, our method has achieved satisfactory results. It outperforms a recent zero-shot TTS engine by a large margin.
Sparse MLP for Image Recognition: Is Self-Attention Really Necessary?
Sep 12, 2021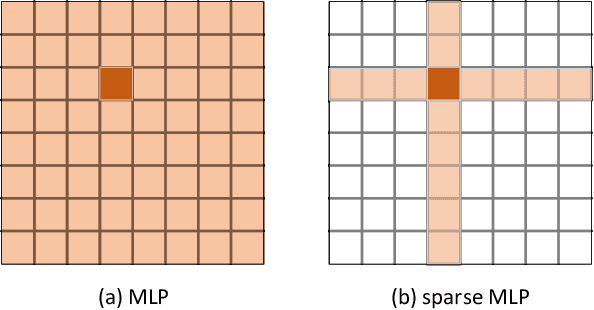

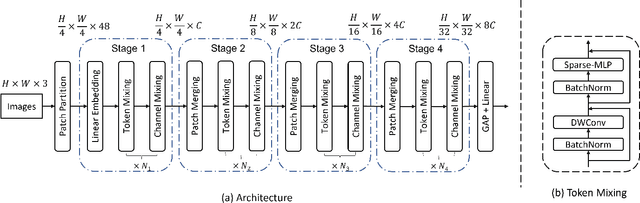
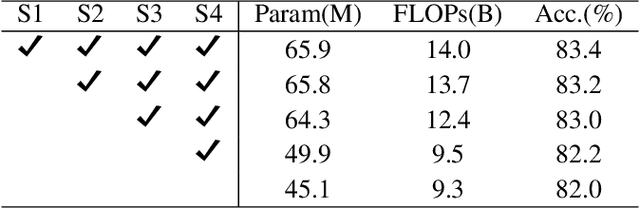
Transformers have sprung up in the field of computer vision. In this work, we explore whether the core self-attention module in Transformer is the key to achieving excellent performance in image recognition. To this end, we build an attention-free network called sMLPNet based on the existing MLP-based vision models. Specifically, we replace the MLP module in the token-mixing step with a novel sparse MLP (sMLP) module. For 2D image tokens, sMLP applies 1D MLP along the axial directions and the parameters are shared among rows or columns. By sparse connection and weight sharing, sMLP module significantly reduces the number of model parameters and computational complexity, avoiding the common over-fitting problem that plagues the performance of MLP-like models. When only trained on the ImageNet-1K dataset, the proposed sMLPNet achieves 81.9% top-1 accuracy with only 24M parameters, which is much better than most CNNs and vision Transformers under the same model size constraint. When scaling up to 66M parameters, sMLPNet achieves 83.4% top-1 accuracy, which is on par with the state-of-the-art Swin Transformer. The success of sMLPNet suggests that the self-attention mechanism is not necessarily a silver bullet in computer vision. Code will be made publicly available.
A Battle of Network Structures: An Empirical Study of CNN, Transformer, and MLP
Aug 30, 2021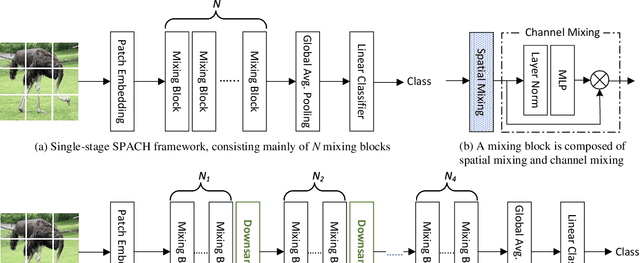
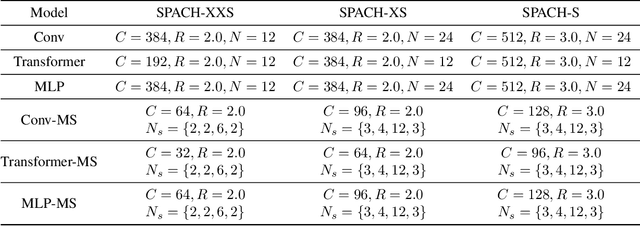
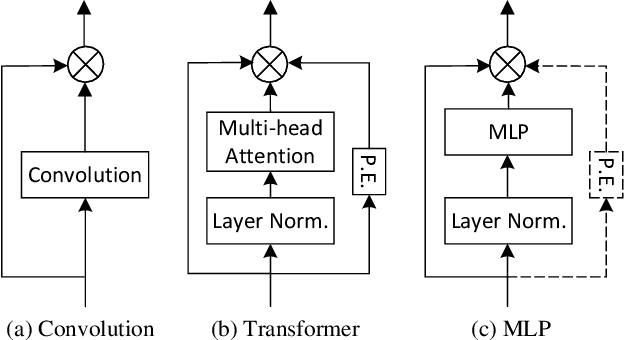
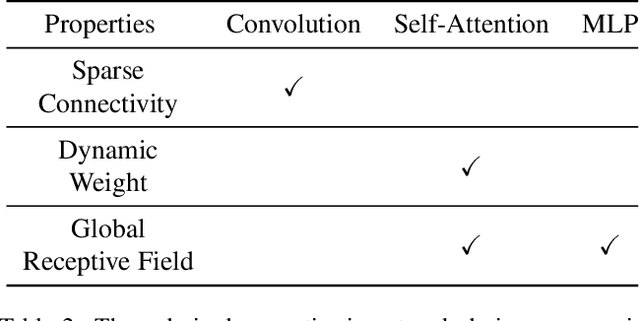
Convolutional neural networks (CNN) are the dominant deep neural network (DNN) architecture for computer vision. Recently, Transformer and multi-layer perceptron (MLP)-based models, such as Vision Transformer and MLP-Mixer, started to lead new trends as they showed promising results in the ImageNet classification task. In this paper, we conduct empirical studies on these DNN structures and try to understand their respective pros and cons. To ensure a fair comparison, we first develop a unified framework called SPACH which adopts separate modules for spatial and channel processing. Our experiments under the SPACH framework reveal that all structures can achieve competitive performance at a moderate scale. However, they demonstrate distinctive behaviors when the network size scales up. Based on our findings, we propose two hybrid models using convolution and Transformer modules. The resulting Hybrid-MS-S+ model achieves 83.9% top-1 accuracy with 63M parameters and 12.3G FLOPS. It is already on par with the SOTA models with sophisticated designs. The code and models will be made publicly available.
Pose-Guided Feature Learning with Knowledge Distillation for Occluded Person Re-Identification
Aug 23, 2021
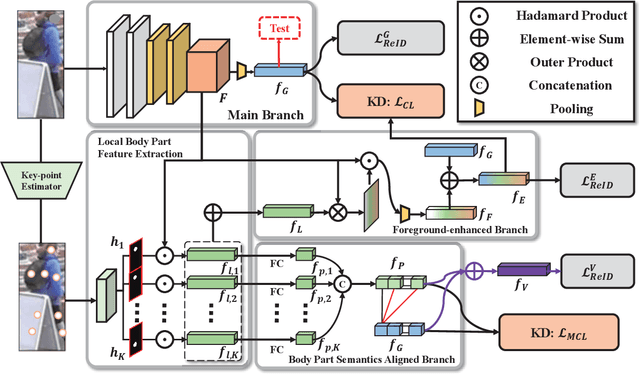
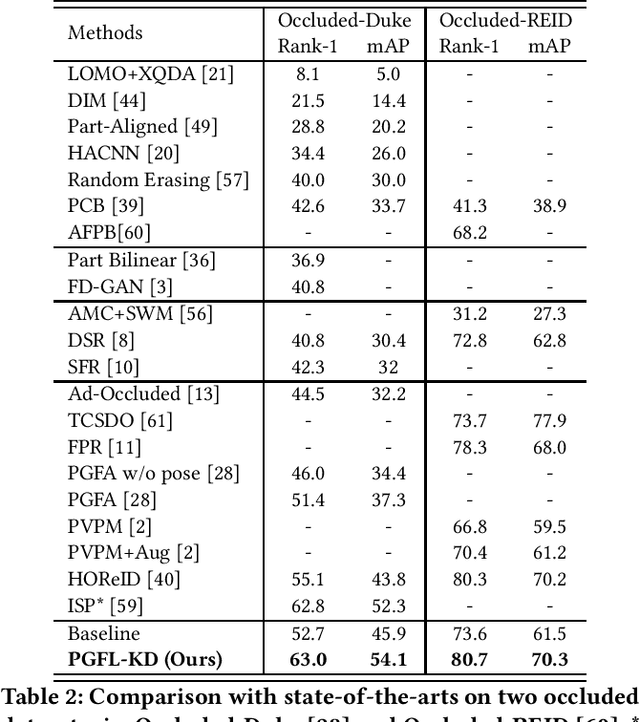
Occluded person re-identification (ReID) aims to match person images with occlusion. It is fundamentally challenging because of the serious occlusion which aggravates the misalignment problem between images. At the cost of incorporating a pose estimator, many works introduce pose information to alleviate the misalignment in both training and testing. To achieve high accuracy while preserving low inference complexity, we propose a network named Pose-Guided Feature Learning with Knowledge Distillation (PGFL-KD), where the pose information is exploited to regularize the learning of semantics aligned features but is discarded in testing. PGFL-KD consists of a main branch (MB), and two pose-guided branches, \ieno, a foreground-enhanced branch (FEB), and a body part semantics aligned branch (SAB). The FEB intends to emphasise the features of visible body parts while excluding the interference of obstructions and background (\ieno, foreground feature alignment). The SAB encourages different channel groups to focus on different body parts to have body part semantics aligned representation. To get rid of the dependency on pose information when testing, we regularize the MB to learn the merits of the FEB and SAB through knowledge distillation and interaction-based training. Extensive experiments on occluded, partial, and holistic ReID tasks show the effectiveness of our proposed network.
Self-Supervised Visual Representations Learning by Contrastive Mask Prediction
Aug 18, 2021

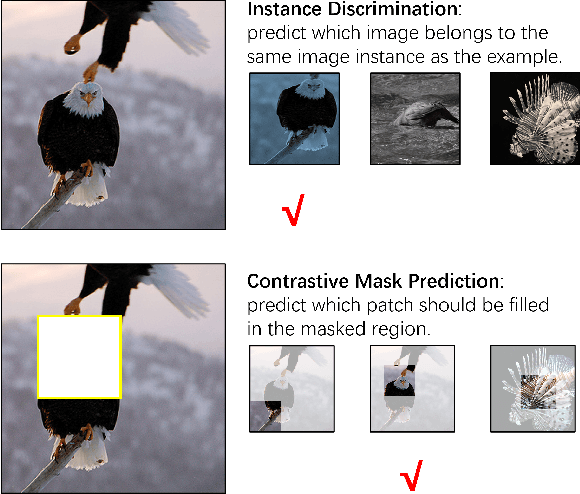
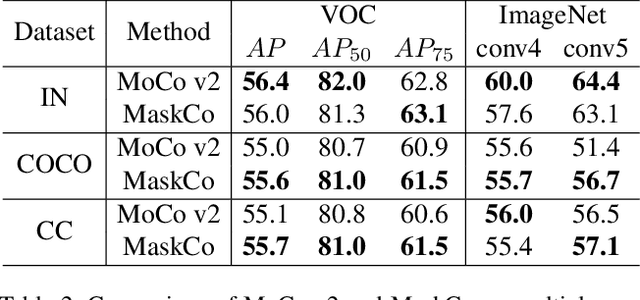
Advanced self-supervised visual representation learning methods rely on the instance discrimination (ID) pretext task. We point out that the ID task has an implicit semantic consistency (SC) assumption, which may not hold in unconstrained datasets. In this paper, we propose a novel contrastive mask prediction (CMP) task for visual representation learning and design a mask contrast (MaskCo) framework to implement the idea. MaskCo contrasts region-level features instead of view-level features, which makes it possible to identify the positive sample without any assumptions. To solve the domain gap between masked and unmasked features, we design a dedicated mask prediction head in MaskCo. This module is shown to be the key to the success of the CMP. We evaluated MaskCo on training datasets beyond ImageNet and compare its performance with MoCo V2. Results show that MaskCo achieves comparable performance with MoCo V2 using ImageNet training dataset, but demonstrates a stronger performance across a range of downstream tasks when COCO or Conceptual Captions are used for training. MaskCo provides a promising alternative to the ID-based methods for self-supervised learning in the wild.
VoxelTrack: Multi-Person 3D Human Pose Estimation and Tracking in the Wild
Aug 05, 2021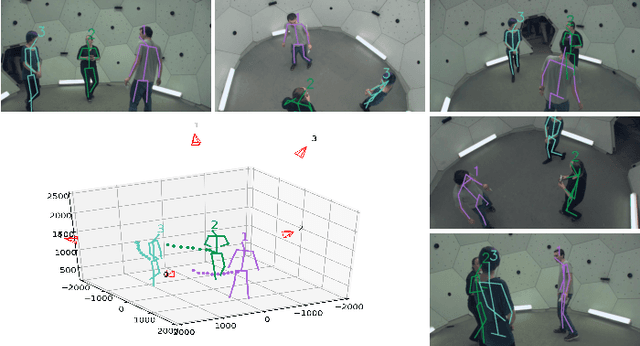
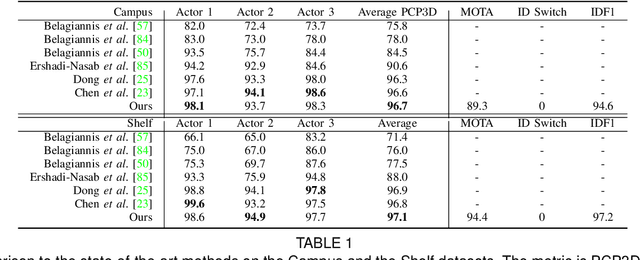
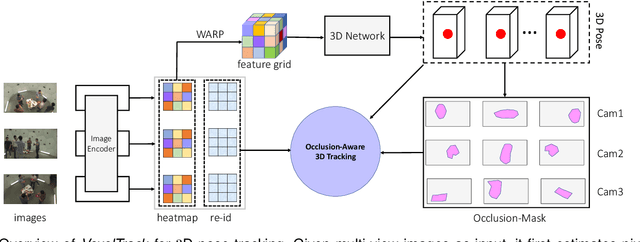

We present VoxelTrack for multi-person 3D pose estimation and tracking from a few cameras which are separated by wide baselines. It employs a multi-branch network to jointly estimate 3D poses and re-identification (Re-ID) features for all people in the environment. In contrast to previous efforts which require to establish cross-view correspondence based on noisy 2D pose estimates, it directly estimates and tracks 3D poses from a 3D voxel-based representation constructed from multi-view images. We first discretize the 3D space by regular voxels and compute a feature vector for each voxel by averaging the body joint heatmaps that are inversely projected from all views. We estimate 3D poses from the voxel representation by predicting whether each voxel contains a particular body joint. Similarly, a Re-ID feature is computed for each voxel which is used to track the estimated 3D poses over time. The main advantage of the approach is that it avoids making any hard decisions based on individual images. The approach can robustly estimate and track 3D poses even when people are severely occluded in some cameras. It outperforms the state-of-the-art methods by a large margin on three public datasets including Shelf, Campus and CMU Panoptic.
Markov Decision Process modeled with Bandits for Sequential Decision Making in Linear-flow
Jul 01, 2021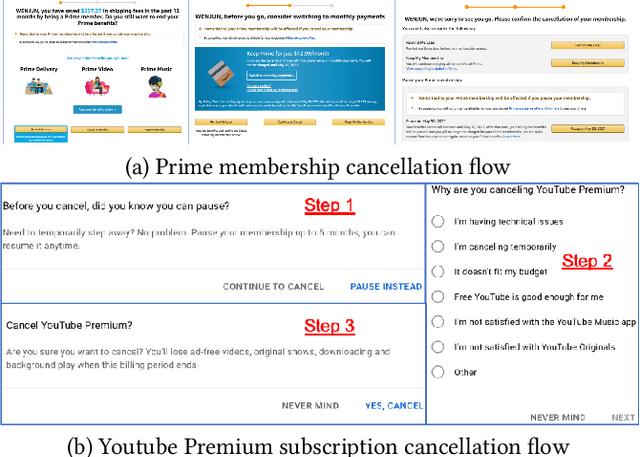
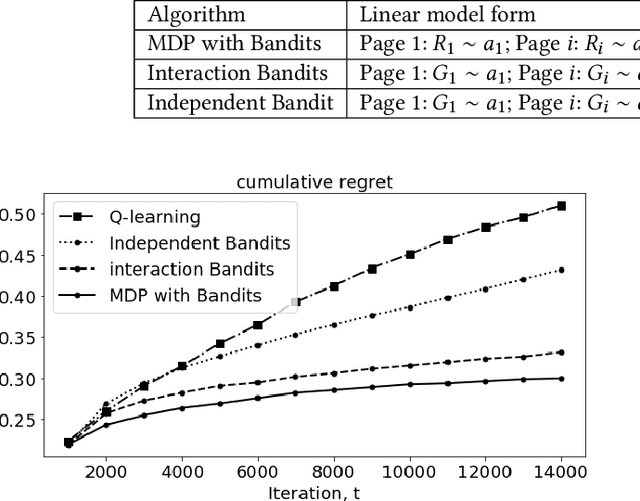
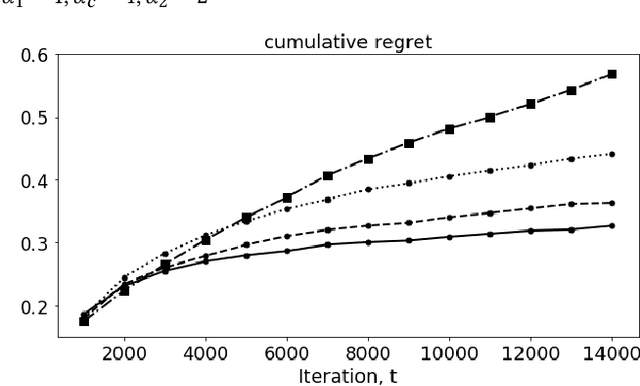
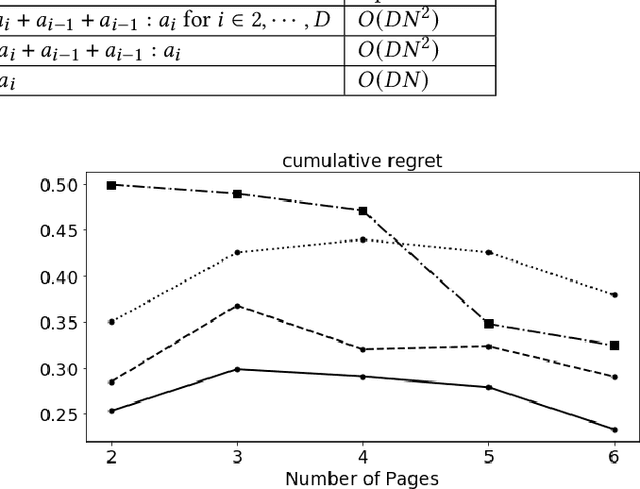
In membership/subscriber acquisition and retention, we sometimes need to recommend marketing content for multiple pages in sequence. Different from general sequential decision making process, the use cases have a simpler flow where customers per seeing recommended content on each page can only return feedback as moving forward in the process or dropping from it until a termination state. We refer to this type of problems as sequential decision making in linear--flow. We propose to formulate the problem as an MDP with Bandits where Bandits are employed to model the transition probability matrix. At recommendation time, we use Thompson sampling (TS) to sample the transition probabilities and allocate the best series of actions with analytical solution through exact dynamic programming. The way that we formulate the problem allows us to leverage TS's efficiency in balancing exploration and exploitation and Bandit's convenience in modeling actions' incompatibility. In the simulation study, we observe the proposed MDP with Bandits algorithm outperforms Q-learning with $\epsilon$-greedy and decreasing $\epsilon$, independent Bandits, and interaction Bandits. We also find the proposed algorithm's performance is the most robust to changes in the across-page interdependence strength.