 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Generative Model-based Quality Control for Cardiac MRI Segmentation
Jun 23, 2020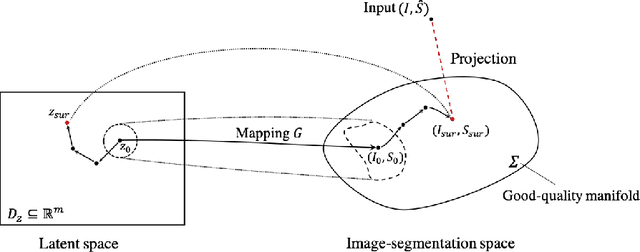
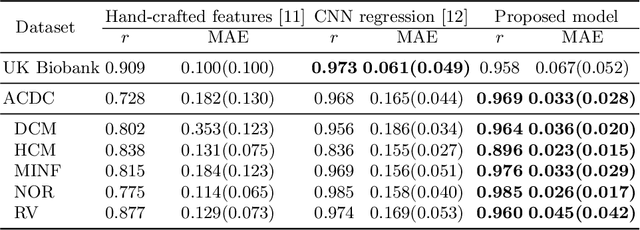
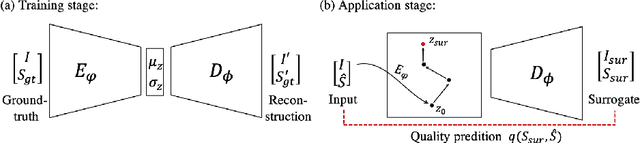
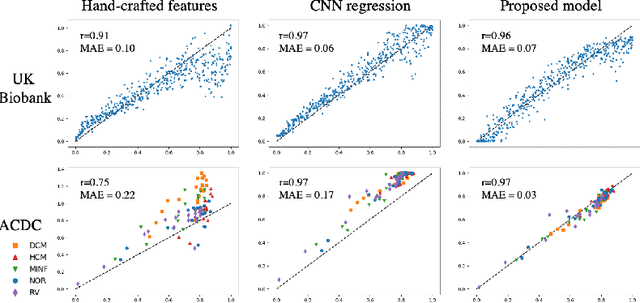
In recent years, convolutional neural networks have demonstrated promising performance in a variety of medical image segmentation tasks. However, when a trained segmentation model is deployed into the real clinical world, the model may not perform optimally. A major challenge is the potential poor-quality segmentations generated due to degraded image quality or domain shift issues. There is a timely need to develop an automated quality control method that can detect poor segmentations and feedback to clinicians. Here we propose a novel deep generative model-based framework for quality control of cardiac MRI segmentation. It first learns a manifold of good-quality image-segmentation pairs using a generative model. The quality of a given test segmentation is then assessed by evaluating the difference from its projection onto the good-quality manifold. In particular, the projection is refined through iterative search in the latent space. The proposed method achieves high prediction accuracy on two publicly available cardiac MRI datasets. Moreover, it shows better generalisation ability than traditional regression-based methods. Our approach provides a real-time and model-agnostic quality control for cardiac MRI segmentation, which has the potential to be integrated into clinical image analysis workflows.
Realistic Adversarial Data Augmentation for MR Image Segmentation
Jun 23, 2020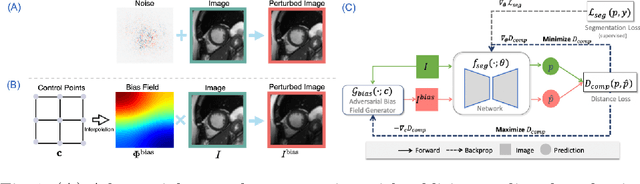
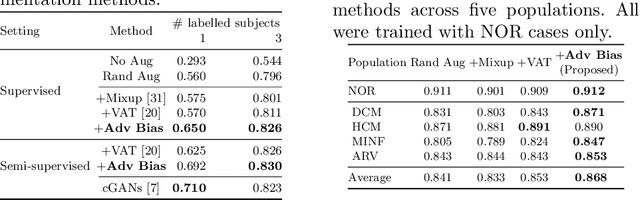
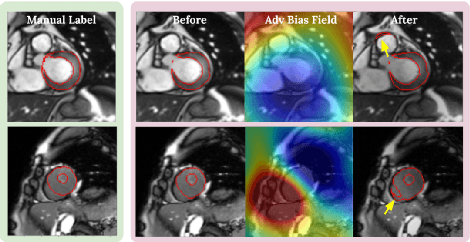
Neural network-based approaches can achieve high accuracy in various medical image segmentation tasks. However, they generally require large labelled datasets for supervised learning. Acquiring and manually labelling a large medical dataset is expensive and sometimes impractical due to data sharing and privacy issues. In this work, we propose an adversarial data augmentation method for training neural networks for medical image segmentation. Instead of generating pixel-wise adversarial attacks, our model generates plausible and realistic signal corruptions, which models the intensity inhomogeneities caused by a common type of artefacts in MR imaging: bias field. The proposed method does not rely on generative networks, and can be used as a plug-in module for general segmentation networks in both supervised and semi-supervised learning. Using cardiac MR imaging we show that such an approach can improve the generalization ability and robustness of models as well as provide significant improvements in low-data scenarios.
A Global Benchmark of Algorithms for Segmenting Late Gadolinium-Enhanced Cardiac Magnetic Resonance Imaging
May 07, 2020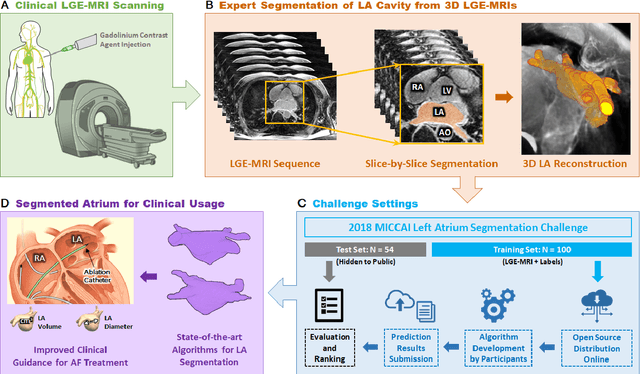
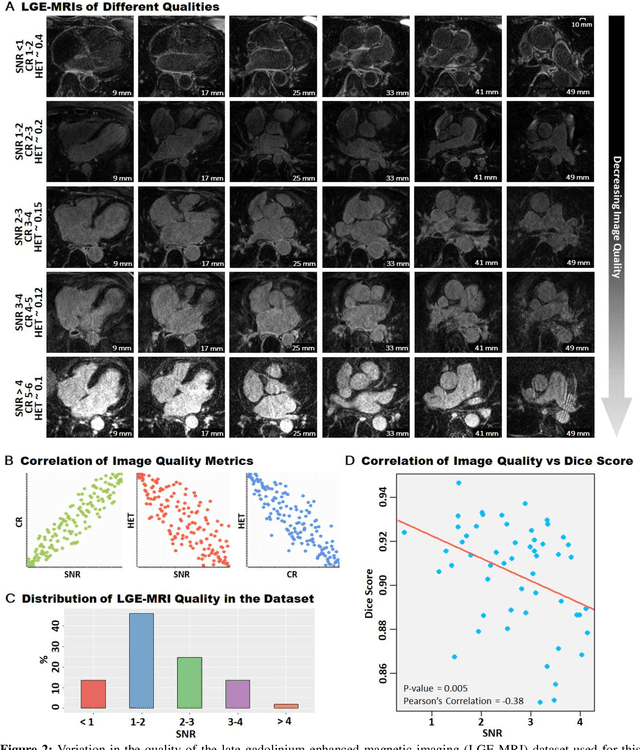
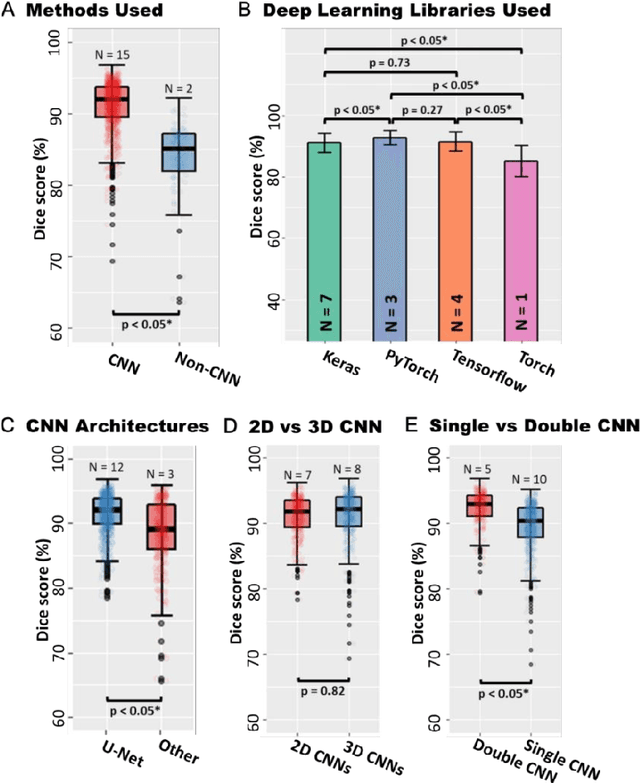
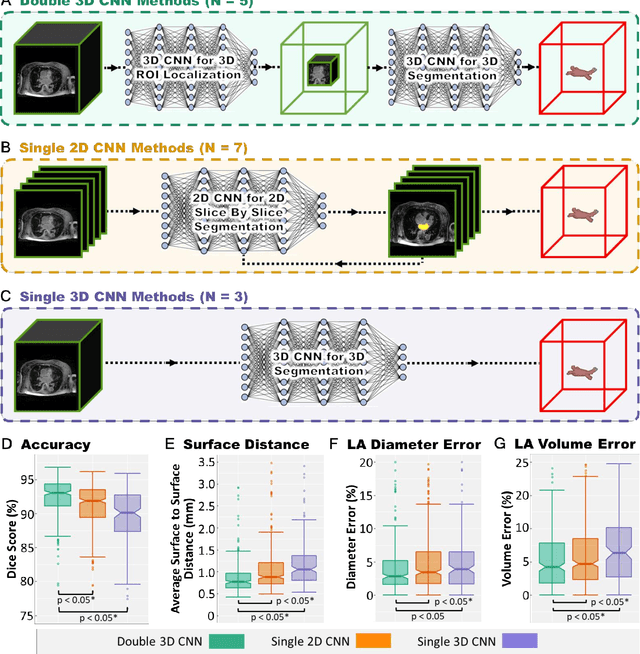
Segmentation of cardiac images, particularly late gadolinium-enhanced magnetic resonance imaging (LGE-MRI) widely used for visualizing diseased cardiac structures, is a crucial first step for clinical diagnosis and treatment. However, direct segmentation of LGE-MRIs is challenging due to its attenuated contrast. Since most clinical studies have relied on manual and labor-intensive approaches, automatic methods are of high interest, particularly optimized machine learning approaches. To address this, we organized the "2018 Left Atrium Segmentation Challenge" using 154 3D LGE-MRIs, currently the world's largest cardiac LGE-MRI dataset, and associated labels of the left atrium segmented by three medical experts, ultimately attracting the participation of 27 international teams. In this paper, extensive analysis of the submitted algorithms using technical and biological metrics was performed by undergoing subgroup analysis and conducting hyper-parameter analysis, offering an overall picture of the major design choices of convolutional neural networks (CNNs) and practical considerations for achieving state-of-the-art left atrium segmentation. Results show the top method achieved a dice score of 93.2% and a mean surface to a surface distance of 0.7 mm, significantly outperforming prior state-of-the-art. Particularly, our analysis demonstrated that double, sequentially used CNNs, in which a first CNN is used for automatic region-of-interest localization and a subsequent CNN is used for refined regional segmentation, achieved far superior results than traditional methods and pipelines containing single CNNs. This large-scale benchmarking study makes a significant step towards much-improved segmentation methods for cardiac LGE-MRIs, and will serve as an important benchmark for evaluating and comparing the future works in the field.
Efficient Deep Representation Learning by Adaptive Latent Space Sampling
Apr 12, 2020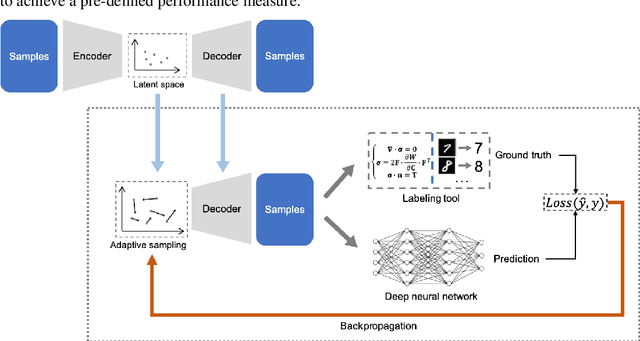

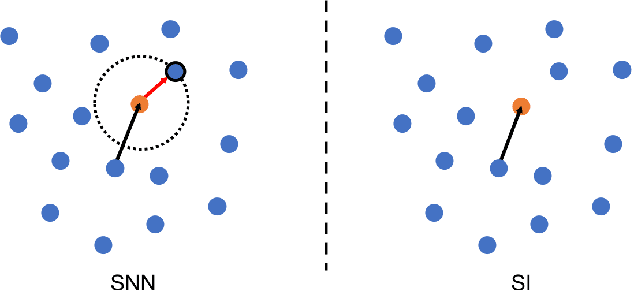
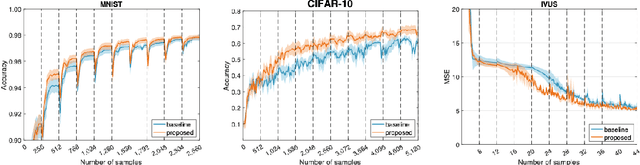
Supervised deep learning requires a large amount of training samples with annotations (e.g. label class for classification task, pixel- or voxel-wised label map for segmentation tasks), which are expensive and time-consuming to obtain. During the training of a deep neural network, the annotated samples are fed into the network in a mini-batch way, where they are often regarded of equal importance. However, some of the samples may become less informative during training, as the magnitude of the gradient start to vanish for these samples. In the meantime, other samples of higher utility or hardness may be more demanded for the training process to proceed and require more exploitation. To address the challenges of expensive annotations and loss of sample informativeness, here we propose a novel training framework which adaptively selects informative samples that are fed to the training process. The adaptive selection or sampling is performed based on a hardness-aware strategy in the latent space constructed by a generative model. To evaluate the proposed training framework, we perform experiments on three different datasets, including MNIST and CIFAR-10 for image classification task and a medical image dataset IVUS for biophysical simulation task. On all three datasets, the proposed framework outperforms a random sampling method, which demonstrates the effectiveness of proposed framework.
Automatic Brain Tumour Segmentation and Biophysics-Guided Survival Prediction
Nov 19, 2019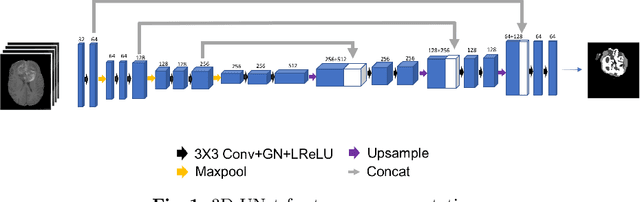
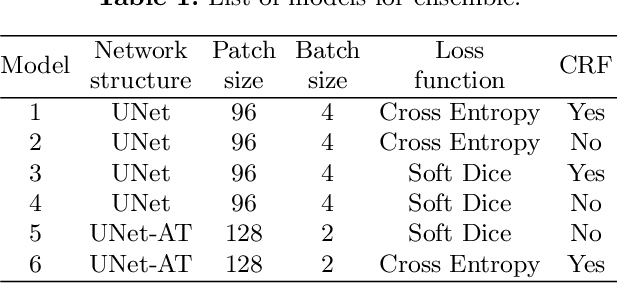
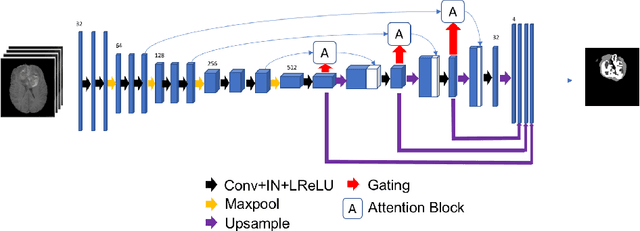
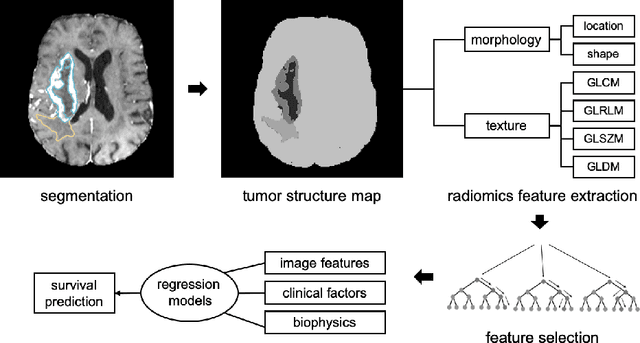
Gliomas are the most common malignant brain tumourswith intrinsic heterogeneity. Accurate segmentation of gliomas and theirsub-regions on multi-parametric magnetic resonance images (mpMRI)is of great clinical importance, which defines tumour size, shape andappearance and provides abundant information for preoperative diag-nosis, treatment planning and survival prediction. Recent developmentson deep learning have significantly improved the performance of auto-mated medical image segmentation. In this paper, we compare severalstate-of-the-art convolutional neural network models for brain tumourimage segmentation. Based on the ensembled segmentation, we presenta biophysics-guided prognostic model for patient overall survival predic-tion which outperforms a data-driven radiomics approach. Our methodwon the second place of the MICCAI 2019 BraTS Challenge for theoverall survival prediction.
Deep learning for cardiac image segmentation: A review
Nov 09, 2019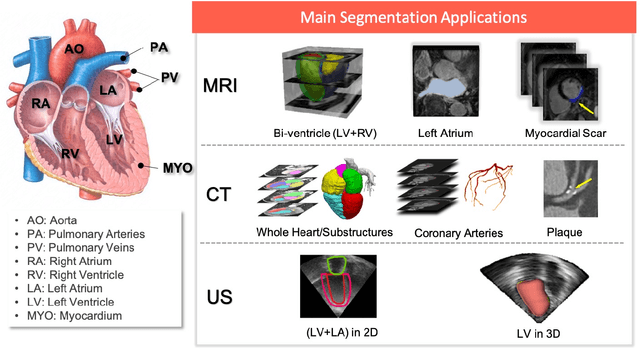
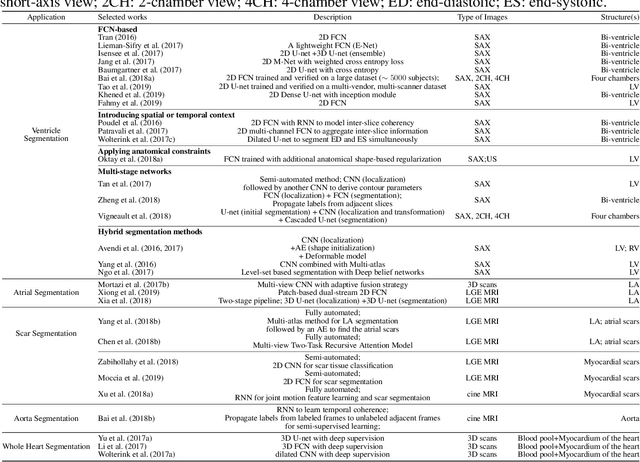
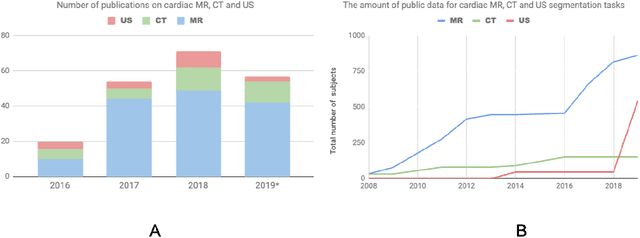

Deep learning has become the most widely used approach for cardiac image segmentation in recent years. In this paper, we provide a review of over 100 cardiac image segmentation papers using deep learning, which covers common imaging modalities including magnetic resonance imaging (MRI), computed tomography (CT), and ultrasound (US) and major anatomical structures of interest (ventricles, atria and vessels). In addition, a summary of publicly available cardiac image datasets and code repositories are included to provide a base for encouraging reproducible research. Finally, we discuss the challenges and limitations with current deep learning-based approaches (scarcity of labels, model generalizability across different domains, interpretability) and suggest potential directions for future research.
Transfer Learning from Partial Annotations for Whole Brain Segmentation
Aug 28, 2019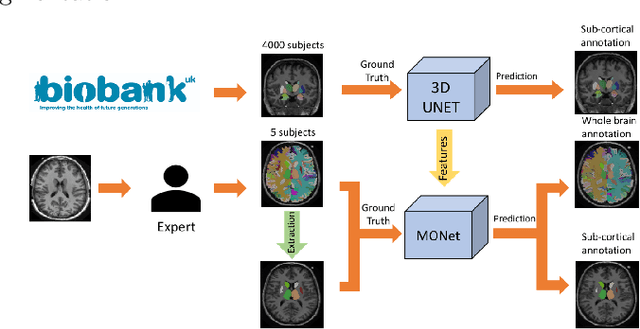

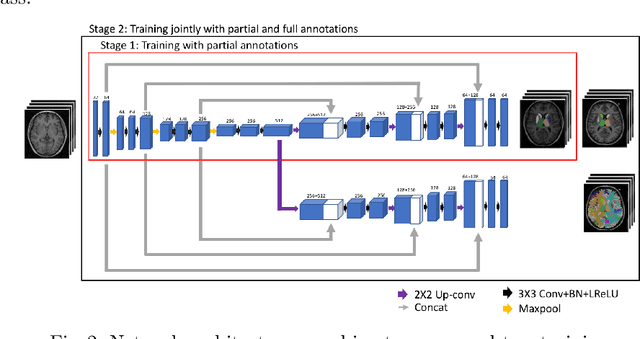
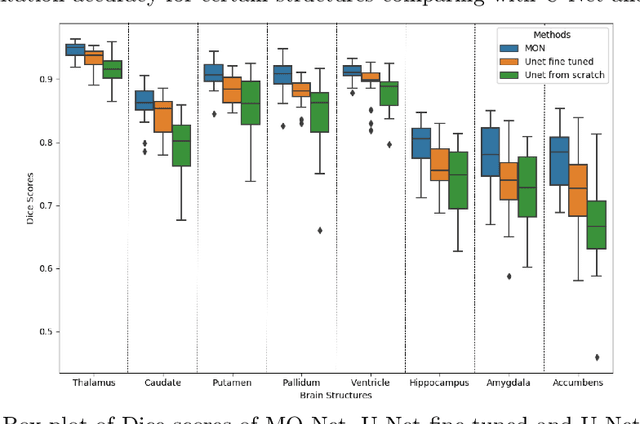
Brain MR image segmentation is a key task in neuroimaging studies. It is commonly conducted using standard computational tools, such as FSL, SPM, multi-atlas segmentation etc, which are often registration-based and suffer from expensive computation cost. Recently, there is an increased interest using deep neural networks for brain image segmentation, which have demonstrated advantages in both speed and performance. However, neural networks-based approaches normally require a large amount of manual annotations for optimising the massive amount of network parameters. For 3D networks used in volumetric image segmentation, this has become a particular challenge, as a 3D network consists of many more parameters compared to its 2D counterpart. Manual annotation of 3D brain images is extremely time-consuming and requires extensive involvement of trained experts. To address the challenge with limited manual annotations, here we propose a novel multi-task learning framework for brain image segmentation, which utilises a large amount of automatically generated partial annotations together with a small set of manually created full annotations for network training. Our method yields a high performance comparable to state-of-the-art methods for whole brain segmentation.
Unsupervised Multi-modal Style Transfer for Cardiac MR Segmentation
Aug 21, 2019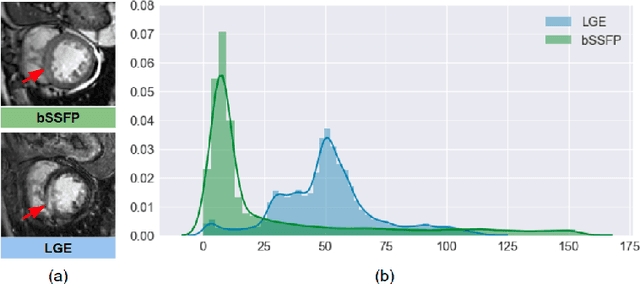
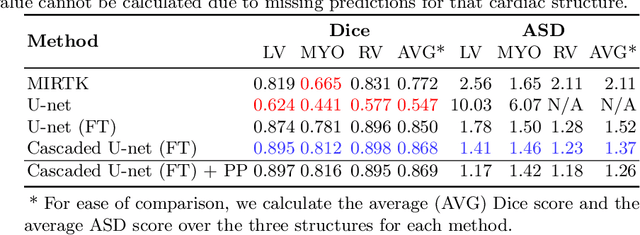
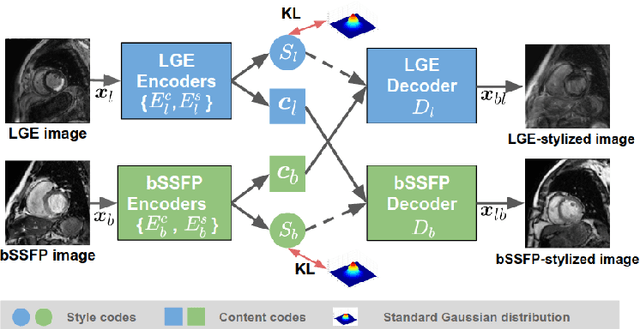
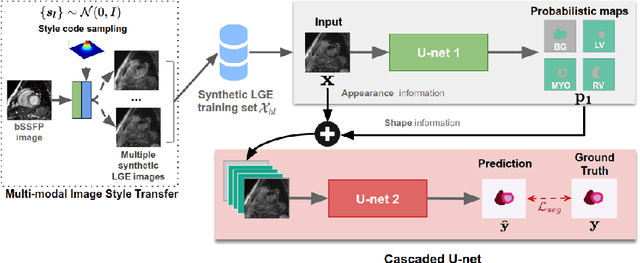
In this work, we present a fully automatic method to segment cardiac structures from late-gadolinium enhanced (LGE) images without using labelled LGE data for training, but instead by transferring the anatomical knowledge and features learned on annotated balanced steady-state free precession (bSSFP) images, which are easier to acquire. Our framework mainly consists of two neural networks: a multi-modal image translation network for style transfer and a cascaded segmentation network for image segmentation. The multi-modal image translation network generates realistic and diverse synthetic LGE images conditioned on a single annotated bSSFP image, forming a synthetic LGE training set. This set is then utilized to fine-tune the segmentation network pre-trained on labelled bSSFP images, achieving the goal of unsupervised LGE image segmentation. In particular, the proposed cascaded segmentation network is able to produce accurate segmentation by taking both shape prior and image appearance into account, achieving an average Dice score of 0.92 for the left ventricle, 0.83 for the myocardium, and 0.88 for the right ventricle on the test set.
Joint Motion Estimation and Segmentation from Undersampled Cardiac MR Image
Aug 20, 2019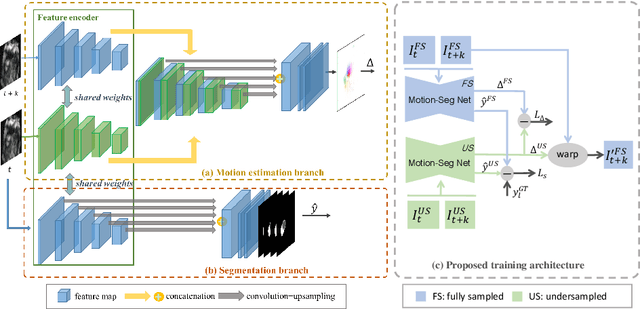
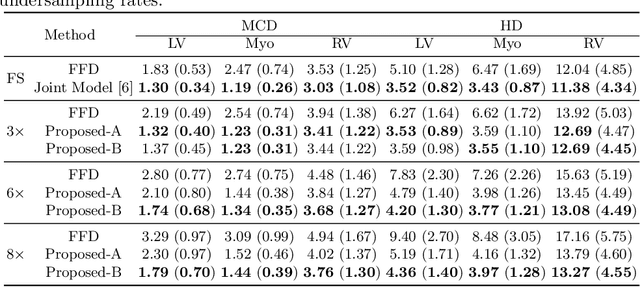
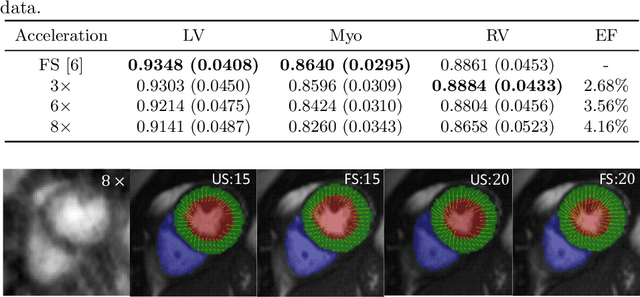
Accelerating the acquisition of magnetic resonance imaging (MRI) is a challenging problem, and many works have been proposed to reconstruct images from undersampled k-space data. However, if the main purpose is to extract certain quantitative measures from the images, perfect reconstructions may not always be necessary as long as the images enable the means of extracting the clinically relevant measures. In this paper, we work on jointly predicting cardiac motion estimation and segmentation directly from undersampled data, which are two important steps in quantitatively assessing cardiac function and diagnosing cardiovascular diseases. In particular, a unified model consisting of both motion estimation branch and segmentation branch is learned by optimising the two tasks simultaneously. Additional corresponding fully-sampled images are incorporated into the network as a parallel sub-network to enhance and guide the learning during the training process. Experimental results using cardiac MR images from 220 subjects show that the proposed model is robust to undersampled data and is capable of predicting results that are close to that from fully-sampled ones, while bypassing the usual image reconstruction stage.
Learning Shape Priors for Robust Cardiac MR Segmentation from Multi-view Images
Jul 23, 2019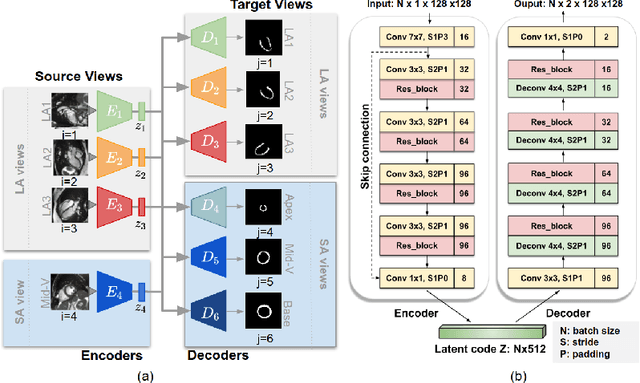
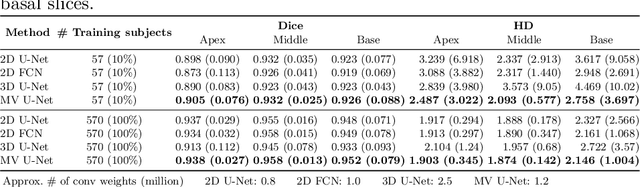
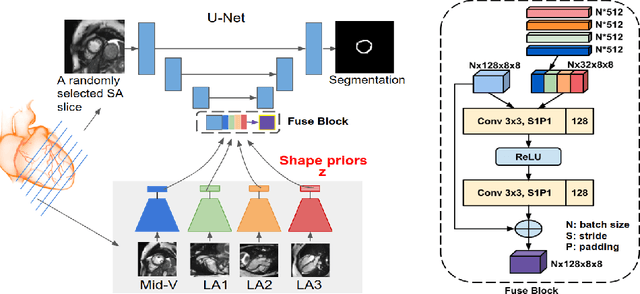
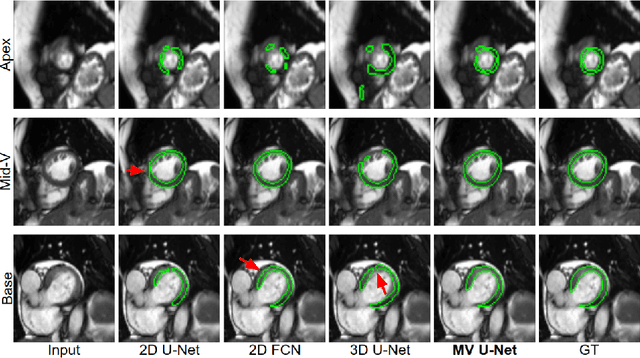
Cardiac MR image segmentation is essential for the morphological and functional analysis of the heart. Inspired by how experienced clinicians assess the cardiac morphology and function across multiple standard views (i.e. long- and short-axis views), we propose a novel approach which learns anatomical shape priors across different 2D standard views and leverages these priors to segment the left ventricular (LV) myocardium from short-axis MR image stacks. The proposed segmentation method has the advantage of being a 2D network but at the same time incorporates spatial context from multiple, complementary views that span a 3D space. Our method achieves accurate and robust segmentation of the myocardium across different short-axis slices (from apex to base), outperforming baseline models (e.g. 2D U-Net, 3D U-Net) while achieving higher data efficiency. Compared to the 2D U-Net, the proposed method reduces the mean Hausdorff distance (mm) from 3.24 to 2.49 on the apical slices, from 2.34 to 2.09 on the middle slices and from 3.62 to 2.76 on the basal slices on the test set, when only 10% of the training data was used.