 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMesh-based 3D Motion Tracking in Cardiac MRI using Deep Learning
Sep 05, 2022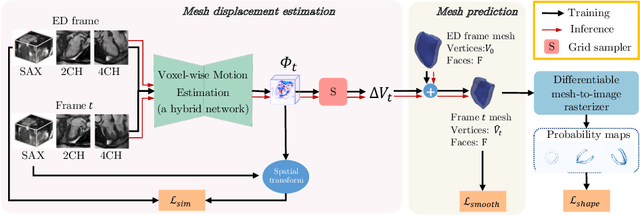
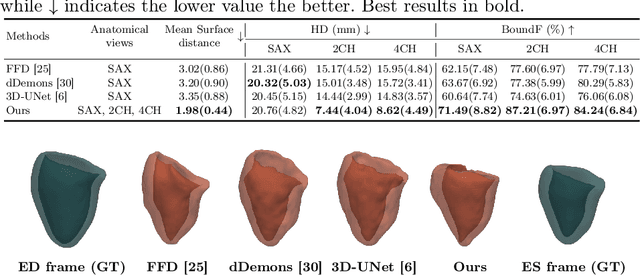
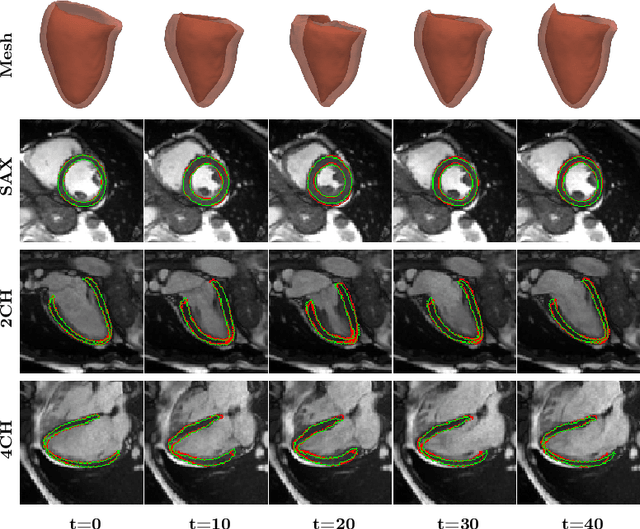

3D motion estimation from cine cardiac magnetic resonance (CMR) images is important for the assessment of cardiac function and diagnosis of cardiovascular diseases. Most of the previous methods focus on estimating pixel-/voxel-wise motion fields in the full image space, which ignore the fact that motion estimation is mainly relevant and useful within the object of interest, e.g., the heart. In this work, we model the heart as a 3D geometric mesh and propose a novel deep learning-based method that can estimate 3D motion of the heart mesh from 2D short- and long-axis CMR images. By developing a differentiable mesh-to-image rasterizer, the method is able to leverage the anatomical shape information from 2D multi-view CMR images for 3D motion estimation. The differentiability of the rasterizer enables us to train the method end-to-end. One advantage of the proposed method is that by tracking the motion of each vertex, it is able to keep the vertex correspondence of 3D meshes between time frames, which is important for quantitative assessment of the cardiac function on the mesh. We evaluate the proposed method on CMR images acquired from the UK Biobank study. Experimental results show that the proposed method quantitatively and qualitatively outperforms both conventional and learning-based cardiac motion tracking methods.
Generative Modelling of the Ageing Heart with Cross-Sectional Imaging and Clinical Data
Aug 28, 2022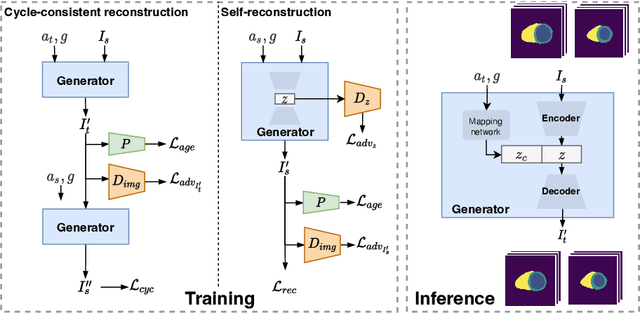

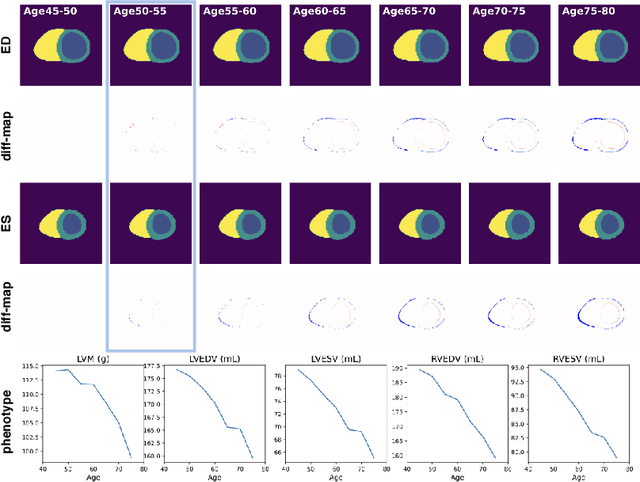

Cardiovascular disease, the leading cause of death globally, is an age-related disease. Understanding the morphological and functional changes of the heart during ageing is a key scientific question, the answer to which will help us define important risk factors of cardiovascular disease and monitor disease progression. In this work, we propose a novel conditional generative model to describe the changes of 3D anatomy of the heart during ageing. The proposed model is flexible and allows integration of multiple clinical factors (e.g. age, gender) into the generating process. We train the model on a large-scale cross-sectional dataset of cardiac anatomies and evaluate on both cross-sectional and longitudinal datasets. The model demonstrates excellent performance in predicting the longitudinal evolution of the ageing heart and modelling its data distribution.
Improved post-hoc probability calibration for out-of-domain MRI segmentation
Aug 04, 2022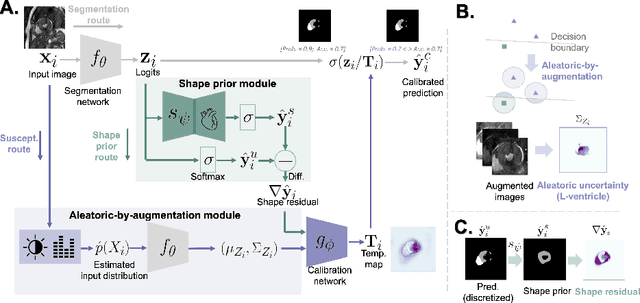
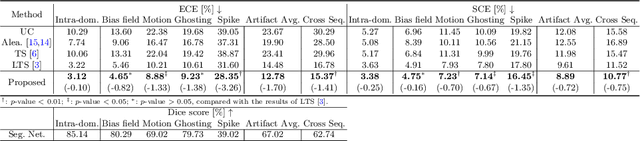

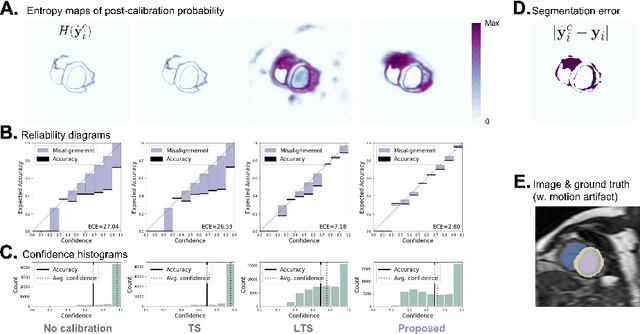
Probability calibration for deep models is highly desirable in safety-critical applications such as medical imaging. It makes output probabilities of deep networks interpretable, by aligning prediction probabilities with the actual accuracy in test data. In image segmentation, well-calibrated probabilities allow radiologists to identify regions where model-predicted segmentations are unreliable. These unreliable predictions often occur to out-of-domain (OOD) images that are caused by imaging artifacts or unseen imaging protocols. Unfortunately, most previous calibration methods for image segmentation perform sub-optimally on OOD images. To reduce the calibration error when confronted with OOD images, we propose a novel post-hoc calibration model. Our model leverages the pixel susceptibility against perturbations at the local level, and the shape prior information at the global level. The model is tested on cardiac MRI segmentation datasets that contain unseen imaging artifacts and images from an unseen imaging protocol. We demonstrate reduced calibration errors compared with the state-of-the-art calibration algorithm.
Subject-Specific Lesion Generation and Pseudo-Healthy Synthesis for Multiple Sclerosis Brain Images
Aug 03, 2022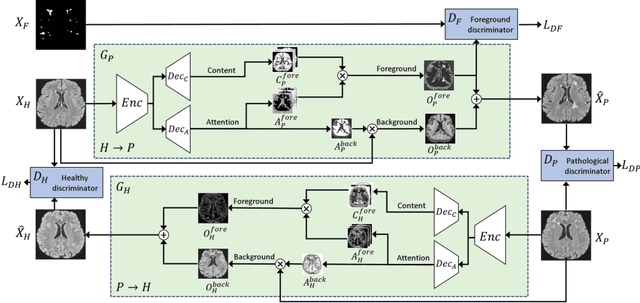
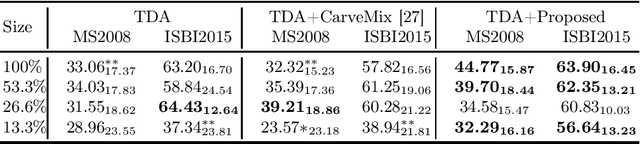
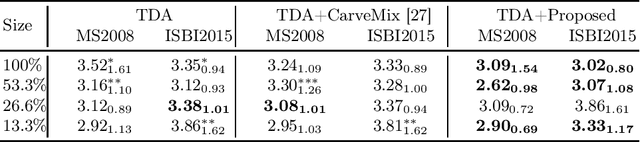
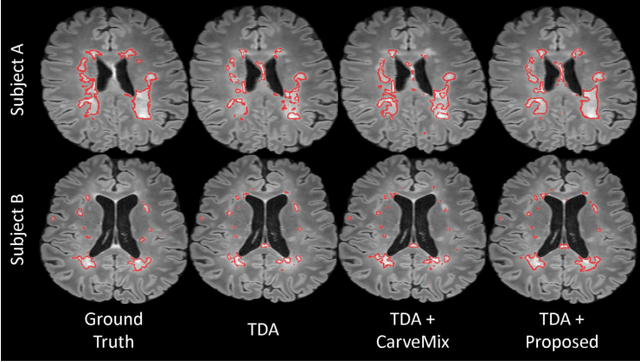
Understanding the intensity characteristics of brain lesions is key for defining image-based biomarkers in neurological studies and for predicting disease burden and outcome. In this work, we present a novel foreground-based generative method for modelling the local lesion characteristics that can both generate synthetic lesions on healthy images and synthesize subject-specific pseudo-healthy images from pathological images. Furthermore, the proposed method can be used as a data augmentation module to generate synthetic images for training brain image segmentation networks. Experiments on multiple sclerosis (MS) brain images acquired on magnetic resonance imaging (MRI) demonstrate that the proposed method can generate highly realistic pseudo-healthy and pseudo-pathological brain images. Data augmentation using the synthetic images improves the brain image segmentation performance compared to traditional data augmentation methods as well as a recent lesion-aware data augmentation technique, CarveMix. The code will be released at https://github.com/dogabasaran/lesion-synthesis.
MulViMotion: Shape-aware 3D Myocardial Motion Tracking from Multi-View Cardiac MRI
Jul 29, 2022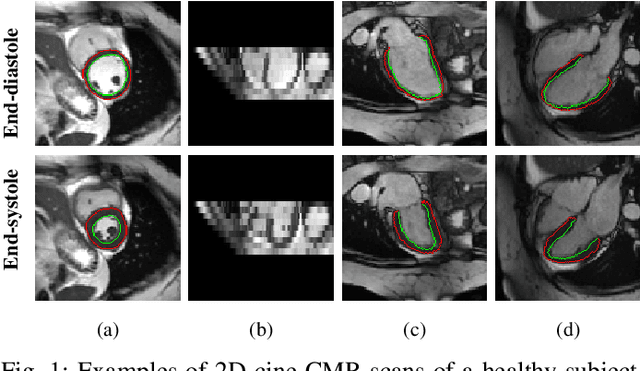
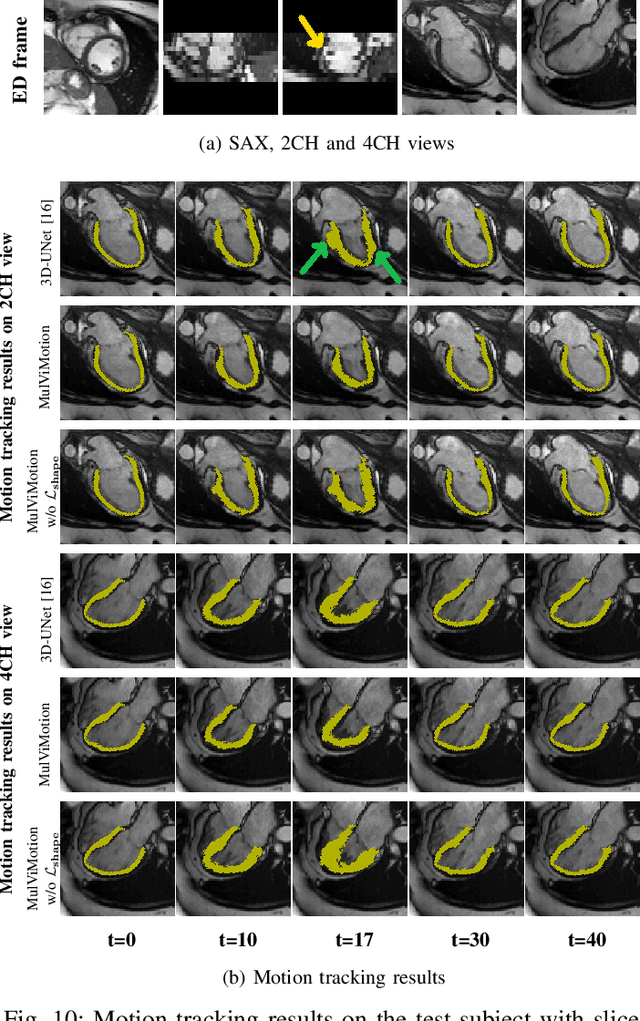
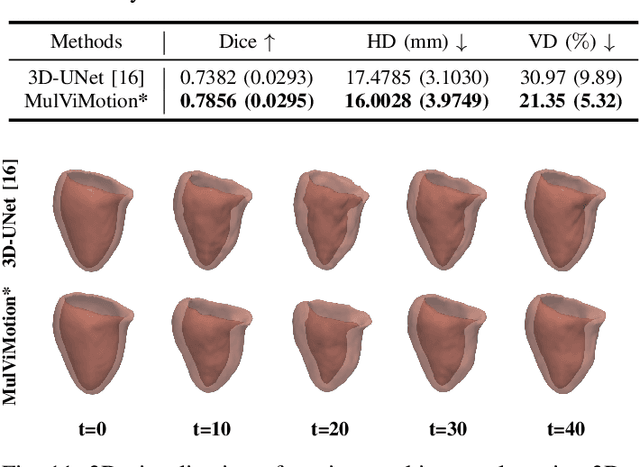
Recovering the 3D motion of the heart from cine cardiac magnetic resonance (CMR) imaging enables the assessment of regional myocardial function and is important for understanding and analyzing cardiovascular disease. However, 3D cardiac motion estimation is challenging because the acquired cine CMR images are usually 2D slices which limit the accurate estimation of through-plane motion. To address this problem, we propose a novel multi-view motion estimation network (MulViMotion), which integrates 2D cine CMR images acquired in short-axis and long-axis planes to learn a consistent 3D motion field of the heart. In the proposed method, a hybrid 2D/3D network is built to generate dense 3D motion fields by learning fused representations from multi-view images. To ensure that the motion estimation is consistent in 3D, a shape regularization module is introduced during training, where shape information from multi-view images is exploited to provide weak supervision to 3D motion estimation. We extensively evaluate the proposed method on 2D cine CMR images from 580 subjects of the UK Biobank study for 3D motion tracking of the left ventricular myocardium. Experimental results show that the proposed method quantitatively and qualitatively outperforms competing methods.
Generative Myocardial Motion Tracking via Latent Space Exploration with Biomechanics-informed Prior
Jun 08, 2022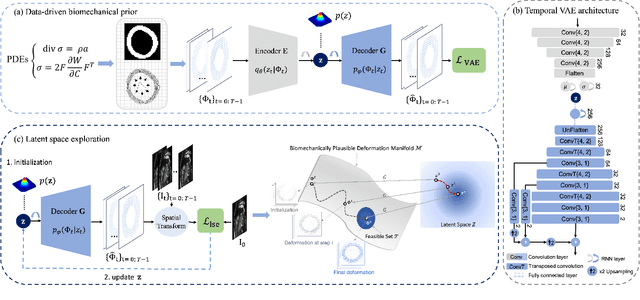
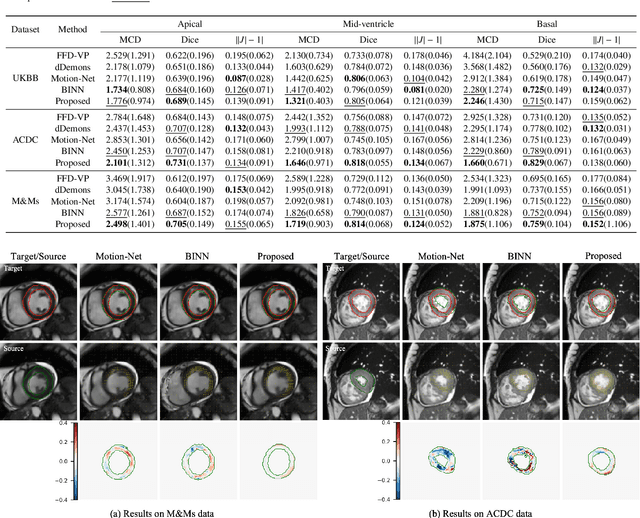
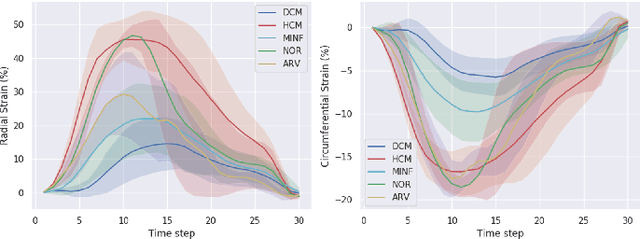
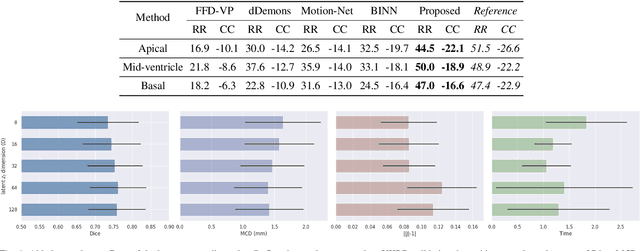
Myocardial motion and deformation are rich descriptors that characterize cardiac function. Image registration, as the most commonly used technique for myocardial motion tracking, is an ill-posed inverse problem which often requires prior assumptions on the solution space. In contrast to most existing approaches which impose explicit generic regularization such as smoothness, in this work we propose a novel method that can implicitly learn an application-specific biomechanics-informed prior and embed it into a neural network-parameterized transformation model. Particularly, the proposed method leverages a variational autoencoder-based generative model to learn a manifold for biomechanically plausible deformations. The motion tracking then can be performed via traversing the learnt manifold to search for the optimal transformations while considering the sequence information. The proposed method is validated on three public cardiac cine MRI datasets with comprehensive evaluations. The results demonstrate that the proposed method can outperform other approaches, yielding higher motion tracking accuracy with reasonable volume preservation and better generalizability to varying data distributions. It also enables better estimates of myocardial strains, which indicates the potential of the method in characterizing spatiotemporal signatures for understanding cardiovascular diseases.
MaxStyle: Adversarial Style Composition for Robust Medical Image Segmentation
Jun 02, 2022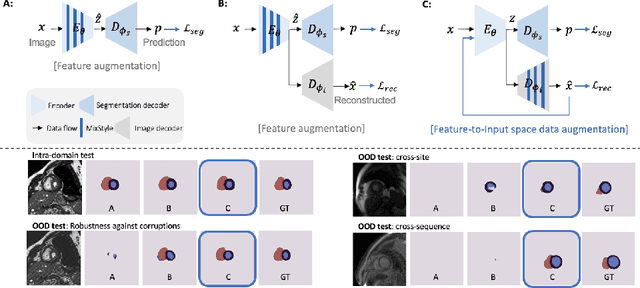

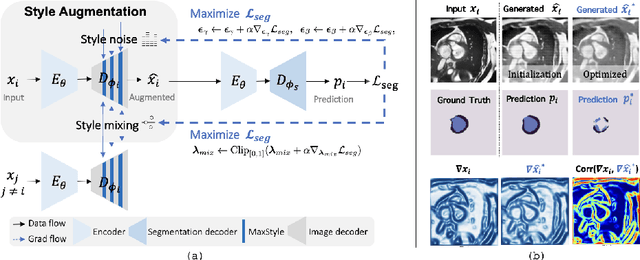
Convolutional neural networks (CNNs) have achieved remarkable segmentation accuracy on benchmark datasets where training and test sets are from the same domain, yet their performance can degrade significantly on unseen domains, which hinders the deployment of CNNs in many clinical scenarios. Most existing works improve model out-of-domain (OOD) robustness by collecting multi-domain datasets for training, which is expensive and may not always be feasible due to privacy and logistical issues. In this work, we focus on improving model robustness using a single-domain dataset only. We propose a novel data augmentation framework called MaxStyle, which maximizes the effectiveness of style augmentation for model OOD performance. It attaches an auxiliary style-augmented image decoder to a segmentation network for robust feature learning and data augmentation. Importantly, MaxStyle augments data with improved image style diversity and hardness, by expanding the style space with noise and searching for the worst-case style composition of latent features via adversarial training. With extensive experiments on multiple public cardiac and prostate MR datasets, we demonstrate that MaxStyle leads to significantly improved out-of-distribution robustness against unseen corruptions as well as common distribution shifts across multiple, different, unseen sites and unknown image sequences under both low- and high-training data settings. The code can be found at https://github.com/cherise215/MaxStyle.
Suggestive Annotation of Brain MR Images with Gradient-guided Sampling
Jun 02, 2022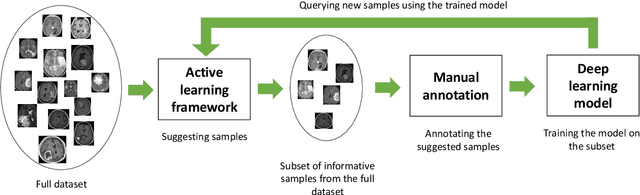
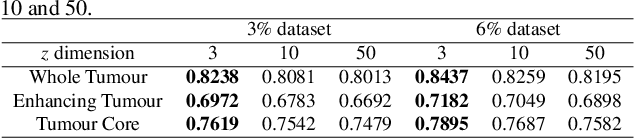
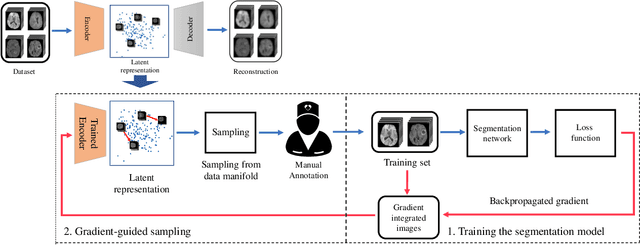

Machine learning has been widely adopted for medical image analysis in recent years given its promising performance in image segmentation and classification tasks. The success of machine learning, in particular supervised learning, depends on the availability of manually annotated datasets. For medical imaging applications, such annotated datasets are not easy to acquire, it takes a substantial amount of time and resource to curate an annotated medical image set. In this paper, we propose an efficient annotation framework for brain MR images that can suggest informative sample images for human experts to annotate. We evaluate the framework on two different brain image analysis tasks, namely brain tumour segmentation and whole brain segmentation. Experiments show that for brain tumour segmentation task on the BraTS 2019 dataset, training a segmentation model with only 7% suggestively annotated image samples can achieve a performance comparable to that of training on the full dataset. For whole brain segmentation on the MALC dataset, training with 42% suggestively annotated image samples can achieve a comparable performance to training on the full dataset. The proposed framework demonstrates a promising way to save manual annotation cost and improve data efficiency in medical imaging applications.
Memory-efficient Segmentation of High-resolution Volumetric MicroCT Images
May 31, 2022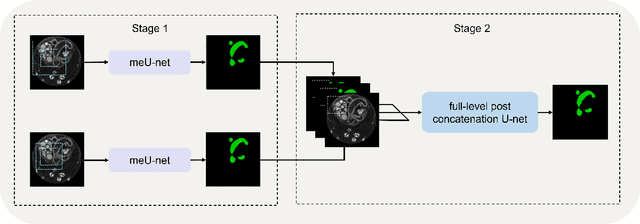
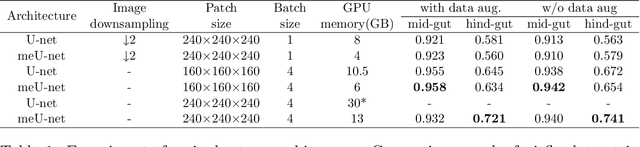
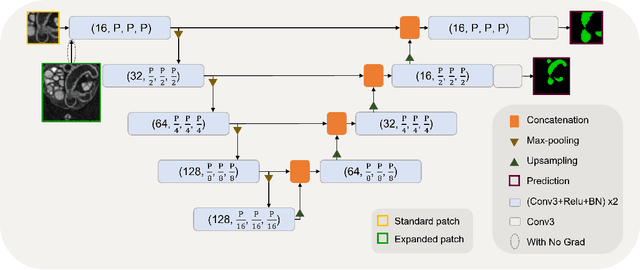

In recent years, 3D convolutional neural networks have become the dominant approach for volumetric medical image segmentation. However, compared to their 2D counterparts, 3D networks introduce substantially more training parameters and higher requirement for the GPU memory. This has become a major limiting factor for designing and training 3D networks for high-resolution volumetric images. In this work, we propose a novel memory-efficient network architecture for 3D high-resolution image segmentation. The network incorporates both global and local features via a two-stage U-net-based cascaded framework and at the first stage, a memory-efficient U-net (meU-net) is developed. The features learnt at the two stages are connected via post-concatenation, which further improves the information flow. The proposed segmentation method is evaluated on an ultra high-resolution microCT dataset with typically 250 million voxels per volume. Experiments show that it outperforms state-of-the-art 3D segmentation methods in terms of both segmentation accuracy and memory efficiency.
QU-BraTS: MICCAI BraTS 2020 Challenge on Quantifying Uncertainty in Brain Tumor Segmentation -- Analysis of Ranking Metrics and Benchmarking Results
Dec 19, 2021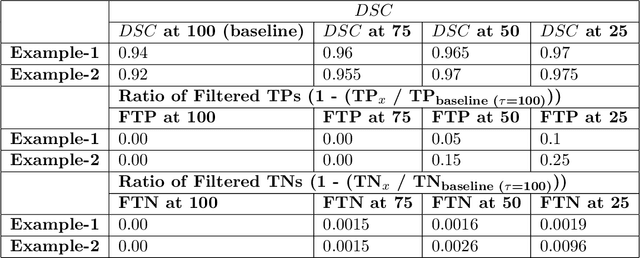
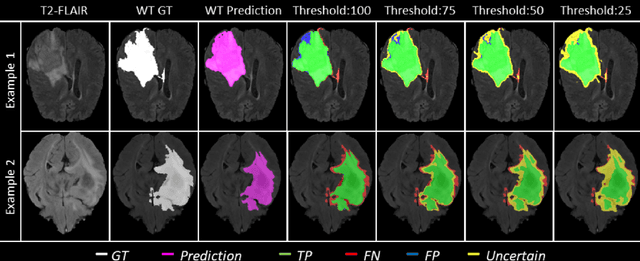
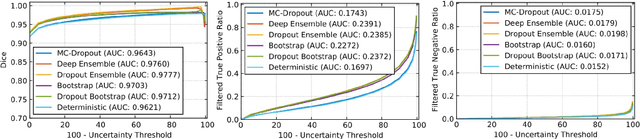
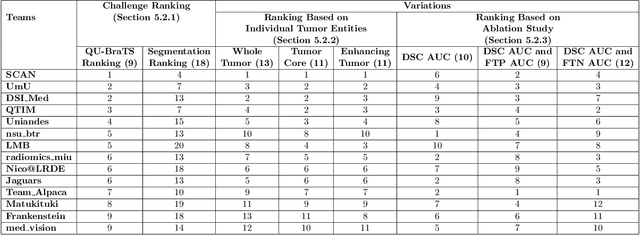
Deep learning (DL) models have provided the state-of-the-art performance in a wide variety of medical imaging benchmarking challenges, including the Brain Tumor Segmentation (BraTS) challenges. However, the task of focal pathology multi-compartment segmentation (e.g., tumor and lesion sub-regions) is particularly challenging, and potential errors hinder the translation of DL models into clinical workflows. Quantifying the reliability of DL model predictions in the form of uncertainties, could enable clinical review of the most uncertain regions, thereby building trust and paving the way towards clinical translation. Recently, a number of uncertainty estimation methods have been introduced for DL medical image segmentation tasks. Developing metrics to evaluate and compare the performance of uncertainty measures will assist the end-user in making more informed decisions. In this study, we explore and evaluate a metric developed during the BraTS 2019-2020 task on uncertainty quantification (QU-BraTS), and designed to assess and rank uncertainty estimates for brain tumor multi-compartment segmentation. This metric (1) rewards uncertainty estimates that produce high confidence in correct assertions, and those that assign low confidence levels at incorrect assertions, and (2) penalizes uncertainty measures that lead to a higher percentages of under-confident correct assertions. We further benchmark the segmentation uncertainties generated by 14 independent participating teams of QU-BraTS 2020, all of which also participated in the main BraTS segmentation task. Overall, our findings confirm the importance and complementary value that uncertainty estimates provide to segmentation algorithms, and hence highlight the need for uncertainty quantification in medical image analyses. Our evaluation code is made publicly available at https://github.com/RagMeh11/QU-BraTS.