 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Biologically Plausible Computing: A Comprehensive Comparison
Jun 23, 2024



Backpropagation is a cornerstone algorithm in training neural networks for supervised learning, which uses a gradient descent method to update network weights by minimizing the discrepancy between actual and desired outputs. Despite its pivotal role in propelling deep learning advancements, the biological plausibility of backpropagation is questioned due to its requirements for weight symmetry, global error computation, and dual-phase training. To address this long-standing challenge, many studies have endeavored to devise biologically plausible training algorithms. However, a fully biologically plausible algorithm for training multilayer neural networks remains elusive, and interpretations of biological plausibility vary among researchers. In this study, we establish criteria for biological plausibility that a desirable learning algorithm should meet. Using these criteria, we evaluate a range of existing algorithms considered to be biologically plausible, including Hebbian learning, spike-timing-dependent plasticity, feedback alignment, target propagation, predictive coding, forward-forward algorithm, perturbation learning, local losses, and energy-based learning. Additionally, we empirically evaluate these algorithms across diverse network architectures and datasets. We compare the feature representations learned by these algorithms with brain activity recorded by non-invasive devices under identical stimuli, aiming to identify which algorithm can most accurately replicate brain activity patterns. We are hopeful that this study could inspire the development of new biologically plausible algorithms for training multilayer networks, thereby fostering progress in both the fields of neuroscience and machine learning.
Promoting Data and Model Privacy in Federated Learning through Quantized LoRA
Jun 16, 2024Conventional federated learning primarily aims to secure the privacy of data distributed across multiple edge devices, with the global model dispatched to edge devices for parameter updates during the learning process. However, the development of large language models (LLMs) requires substantial data and computational resources, rendering them valuable intellectual properties for their developers and owners. To establish a mechanism that protects both data and model privacy in a federated learning context, we introduce a method that just needs to distribute a quantized version of the model's parameters during training. This method enables accurate gradient estimations for parameter updates while preventing clients from accessing a model whose performance is comparable to the centrally hosted one. Moreover, we combine this quantization strategy with LoRA, a popular and parameter-efficient fine-tuning method, to significantly reduce communication costs in federated learning. The proposed framework, named \textsc{FedLPP}, successfully ensures both data and model privacy in the federated learning context. Additionally, the learned central model exhibits good generalization and can be trained in a resource-efficient manner.
Advancing Parameter Efficiency in Fine-tuning via Representation Editing
Feb 28, 2024Parameter Efficient Fine-Tuning (PEFT) has gained significant attention for its ability to achieve competitive results while updating only a small subset of trainable parameters. Despite the promising performance of current PEFT methods, they present challenges in hyperparameter selection, such as determining the rank of LoRA or Adapter, or specifying the length of soft prompts. In addressing these challenges, we propose a novel approach to fine-tuning neural models, termed Representation EDiting (RED), which scales and biases the representation produced at each layer. RED substantially reduces the number of trainable parameters by a factor of $25,700$ compared to full parameter fine-tuning, and by a factor of $32$ compared to LoRA. Remarkably, RED achieves comparable or superior results to full parameter fine-tuning and other PEFT methods. Extensive experiments were conducted across models of varying architectures and scales, including RoBERTa, GPT-2, T5, and Llama-2, and the results demonstrate the efficiency and efficacy of RED, positioning it as a promising PEFT approach for large neural models.
Aligning Large Language Models with Human Preferences through Representation Engineering
Dec 26, 2023



Aligning large language models (LLMs) with human preferences is crucial for enhancing their utility in terms of helpfulness, truthfulness, safety, harmlessness, and interestingness. Existing methods for achieving this alignment often involves employing reinforcement learning from human feedback (RLHF) to fine-tune LLMs based on human labels assessing the relative quality of model responses. Nevertheless, RLHF is susceptible to instability during fine-tuning and presents challenges in implementation.Drawing inspiration from the emerging field of representation engineering (RepE), this study aims to identify relevant representations for high-level human preferences embedded in patterns of activity within an LLM, and achieve precise control of model behavior by transforming its representations. This novel approach, denoted as Representation Alignment from Human Feedback (RAHF), proves to be effective, computationally efficient, and easy to implement.Extensive experiments demonstrate the efficacy of RAHF in not only capturing but also manipulating representations to align with a broad spectrum of human preferences or values, rather than being confined to a singular concept or function (e.g. honesty or bias). RAHF's versatility in accommodating diverse human preferences shows its potential for advancing LLM performance.
SpikeCLIP: A Contrastive Language-Image Pretrained Spiking Neural Network
Oct 12, 2023



Spiking neural networks (SNNs) have demonstrated the capability to achieve comparable performance to deep neural networks (DNNs) in both visual and linguistic domains while offering the advantages of improved energy efficiency and adherence to biological plausibility. However, the extension of such single-modality SNNs into the realm of multimodal scenarios remains an unexplored territory. Drawing inspiration from the concept of contrastive language-image pre-training (CLIP), we introduce a novel framework, named SpikeCLIP, to address the gap between two modalities within the context of spike-based computing through a two-step recipe involving ``Alignment Pre-training + Dual-Loss Fine-tuning". Extensive experiments demonstrate that SNNs achieve comparable results to their DNN counterparts while significantly reducing energy consumption across a variety of datasets commonly used for multimodal model evaluation. Furthermore, SpikeCLIP maintains robust performance in image classification tasks that involve class labels not predefined within specific categories.
Efficiently Aligned Cross-Lingual Transfer Learning for Conversational Tasks using Prompt-Tuning
Apr 03, 2023



Cross-lingual transfer of language models trained on high-resource languages like English has been widely studied for many NLP tasks, but focus on conversational tasks has been rather limited. This is partly due to the high cost of obtaining non-English conversational data, which results in limited coverage. In this work, we introduce XSGD, a parallel and large-scale multilingual conversation dataset that we created by translating the English-only Schema-Guided Dialogue (SGD) dataset (Rastogi et al., 2020) into 105 other languages. XSGD contains approximately 330k utterances per language. To facilitate aligned cross-lingual representations, we develop an efficient prompt-tuning-based method for learning alignment prompts. We also investigate two different classifiers: NLI-based and vanilla classifiers, and test cross-lingual capability enabled by the aligned prompts. We evaluate our model's cross-lingual generalization capabilities on two conversation tasks: slot-filling and intent classification. Our results demonstrate the strong and efficient modeling ability of NLI-based classifiers and the large cross-lingual transfer improvements achieved by our aligned prompts, particularly in few-shot settings.
Conformal Predictor for Improving Zero-shot Text Classification Efficiency
Oct 23, 2022



Pre-trained language models (PLMs) have been shown effective for zero-shot (0shot) text classification. 0shot models based on natural language inference (NLI) and next sentence prediction (NSP) employ cross-encoder architecture and infer by making a forward pass through the model for each label-text pair separately. This increases the computational cost to make inferences linearly in the number of labels. In this work, we improve the efficiency of such cross-encoder-based 0shot models by restricting the number of likely labels using another fast base classifier-based conformal predictor (CP) calibrated on samples labeled by the 0shot model. Since a CP generates prediction sets with coverage guarantees, it reduces the number of target labels without excluding the most probable label based on the 0shot model. We experiment with three intent and two topic classification datasets. With a suitable CP for each dataset, we reduce the average inference time for NLI- and NSP-based models by 25.6% and 22.2% respectively, without dropping performance below the predefined error rate of 1%.
Near-Negative Distinction: Giving a Second Life to Human Evaluation Datasets
May 13, 2022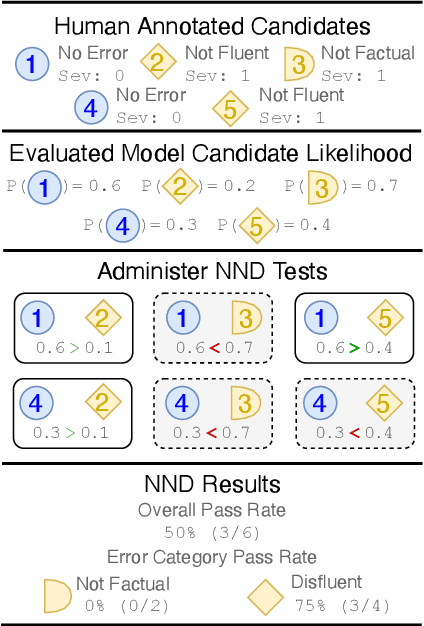
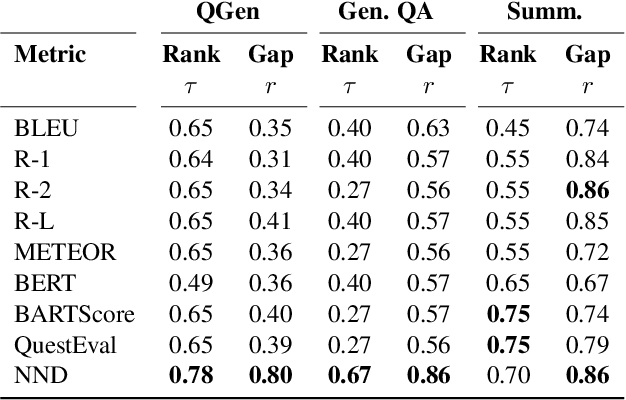
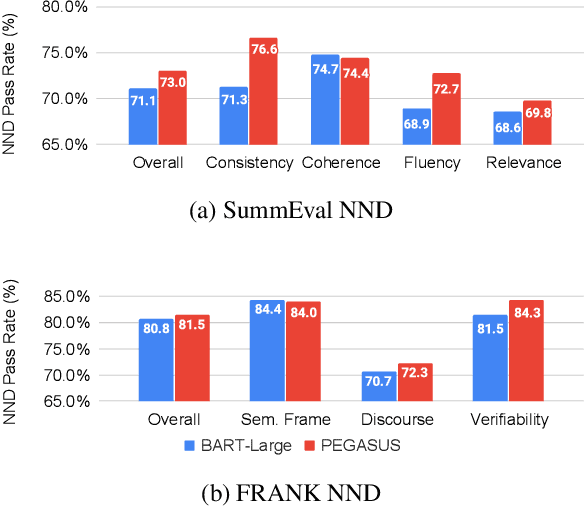
Precisely assessing the progress in natural language generation (NLG) tasks is challenging, and human evaluation to establish preference in a model's output over another is often necessary. However, human evaluation is usually costly, difficult to reproduce, and non-reusable. In this paper, we propose a new and simple automatic evaluation method for NLG called Near-Negative Distinction (NND) that repurposes prior human annotations into NND tests. In an NND test, an NLG model must place higher likelihood on a high-quality output candidate than on a near-negative candidate with a known error. Model performance is established by the number of NND tests a model passes, as well as the distribution over task-specific errors the model fails on. Through experiments on three NLG tasks (question generation, question answering, and summarization), we show that NND achieves higher correlation with human judgments than standard NLG evaluation metrics. We then illustrate NND evaluation in four practical scenarios, for example performing fine-grain model analysis, or studying model training dynamics. Our findings suggest NND can give a second life to human annotations and provide low-cost NLG evaluation.
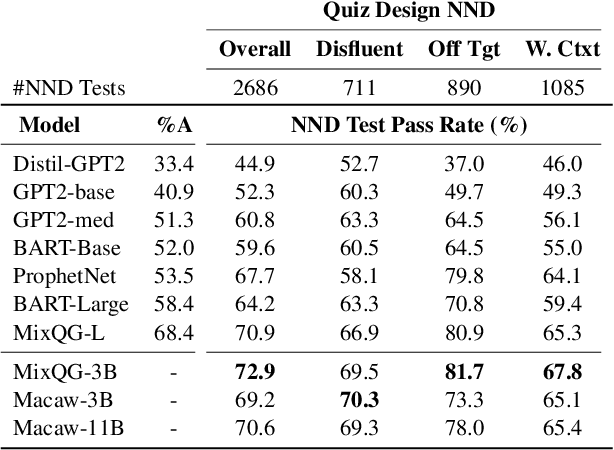
Quiz Design Task: Helping Teachers Create Quizzes with Automated Question Generation
May 03, 2022
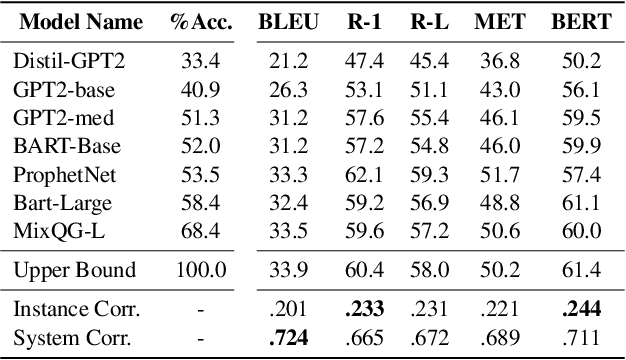
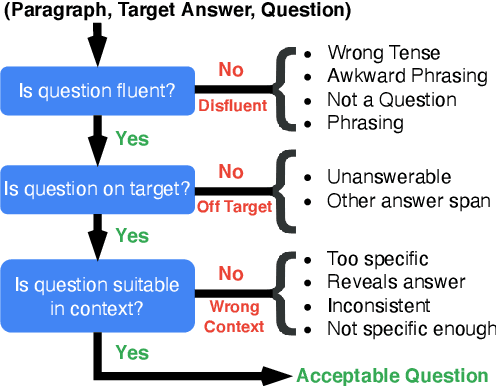
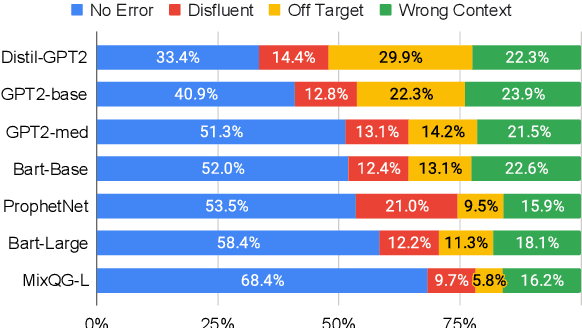
Question generation (QGen) models are often evaluated with standardized NLG metrics that are based on n-gram overlap. In this paper, we measure whether these metric improvements translate to gains in a practical setting, focusing on the use case of helping teachers automate the generation of reading comprehension quizzes. In our study, teachers building a quiz receive question suggestions, which they can either accept or refuse with a reason. Even though we find that recent progress in QGen leads to a significant increase in question acceptance rates, there is still large room for improvement, with the best model having only 68.4% of its questions accepted by the ten teachers who participated in our study. We then leverage the annotations we collected to analyze standard NLG metrics and find that model performance has reached projected upper-bounds, suggesting new automatic metrics are needed to guide QGen research forward.
A Generative Language Model for Few-shot Aspect-Based Sentiment Analysis
Apr 11, 2022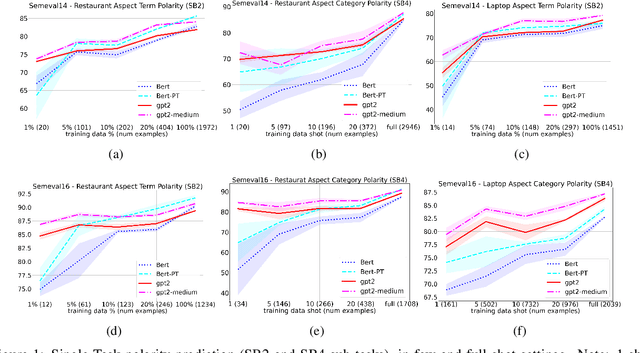
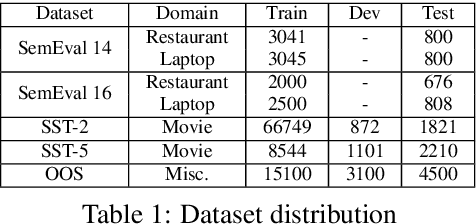
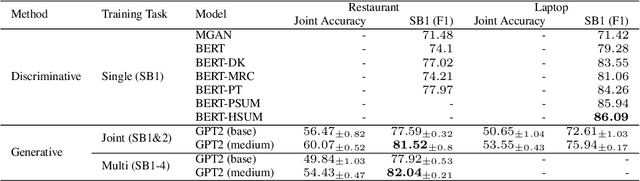
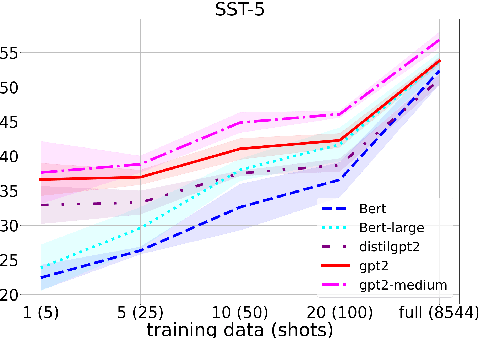
Sentiment analysis is an important task in natural language processing. In recent works, pre-trained language models are often used to achieve state-of-the-art results, especially when training data is scarce. It is common to fine-tune on the downstream task, usually by adding task-specific layers on top of the model. In this paper, we focus on aspect-based sentiment analysis, which involves extracting aspect term, category, and predicting their corresponding polarities. In particular, we are interested in few-shot settings. We propose to reformulate the extraction and prediction tasks into the sequence generation task, using a generative language model with unidirectional attention (GPT2 is used unless stated otherwise). This way, the model learns to accomplish the tasks via language generation without the need of training task-specific layers. Our evaluation results on the single-task polarity prediction show that our approach outperforms the previous state-of-the-art (based on BERT) on average performance by a large margins in few-shot and full-shot settings. More importantly, our generative approach significantly reduces the model variance caused by low-resource data. We further demonstrate that the proposed generative language model can handle joint and multi-task settings, unlike previous work. We observe that the proposed sequence generation method achieves further improved performances on polarity prediction when the model is trained via joint and multi-task settings. Further evaluation on similar sentiment analysis datasets, SST-2, SST- and OOS intent detection validates the superiority and noise robustness of generative language model in few-shot settings.