 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Train Your DRAGON: Diverse Augmentation Towards Generalizable Dense Retrieval
Feb 15, 2023



Various techniques have been developed in recent years to improve dense retrieval (DR), such as unsupervised contrastive learning and pseudo-query generation. Existing DRs, however, often suffer from effectiveness tradeoffs between supervised and zero-shot retrieval, which some argue was due to the limited model capacity. We contradict this hypothesis and show that a generalizable DR can be trained to achieve high accuracy in both supervised and zero-shot retrieval without increasing model size. In particular, we systematically examine the contrastive learning of DRs, under the framework of Data Augmentation (DA). Our study shows that common DA practices such as query augmentation with generative models and pseudo-relevance label creation using a cross-encoder, are often inefficient and sub-optimal. We hence propose a new DA approach with diverse queries and sources of supervision to progressively train a generalizable DR. As a result, DRAGON, our dense retriever trained with diverse augmentation, is the first BERT-base-sized DR to achieve state-of-the-art effectiveness in both supervised and zero-shot evaluations and even competes with models using more complex late interaction (ColBERTv2 and SPLADE++).
REPLUG: Retrieval-Augmented Black-Box Language Models
Feb 01, 2023We introduce REPLUG, a retrieval-augmented language modeling framework that treats the language model (LM) as a black box and augments it with a tuneable retrieval model. Unlike prior retrieval-augmented LMs that train language models with special cross attention mechanisms to encode the retrieved text, REPLUG simply prepends retrieved documents to the input for the frozen black-box LM. This simple design can be easily applied to any existing retrieval and language models. Furthermore, we show that the LM can be used to supervise the retrieval model, which can then find documents that help the LM make better predictions. Our experiments demonstrate that REPLUG with the tuned retriever significantly improves the performance of GPT-3 (175B) on language modeling by 6.3%, as well as the performance of Codex on five-shot MMLU by 5.1%.
One Embedder, Any Task: Instruction-Finetuned Text Embeddings
Dec 20, 2022



We introduce INSTRUCTOR, a new method for computing text embeddings given task instructions: every text input is embedded together with instructions explaining the use case (e.g., task and domain descriptions). Unlike encoders from prior work that are more specialized, INSTRUCTOR is a single embedder that can generate text embeddings tailored to different downstream tasks and domains, without any further training. We first annotate instructions for 330 diverse tasks and train INSTRUCTOR on this multitask mixture with a contrastive loss. We evaluate INSTRUCTOR on 70 embedding evaluation tasks (66 of which are unseen during training), ranging from classification and information retrieval to semantic textual similarity and text generation evaluation. INSTRUCTOR, while having an order of magnitude fewer parameters than the previous best model, achieves state-of-the-art performance, with an average improvement of 3.4% compared to the previous best results on the 70 diverse datasets. Our analysis suggests that INSTRUCTOR is robust to changes in instructions, and that instruction finetuning mitigates the challenge of training a single model on diverse datasets. Our model, code, and data are available at https://instructor-embedding.github.io.
Nonparametric Masked Language Modeling
Dec 02, 2022Existing language models (LMs) predict tokens with a softmax over a finite vocabulary, which can make it difficult to predict rare tokens or phrases. We introduce NPM, the first nonparametric masked language model that replaces this softmax with a nonparametric distribution over every phrase in a reference corpus. We show that NPM can be efficiently trained with a contrastive objective and an in-batch approximation to full corpus retrieval. Zero-shot evaluation on 9 closed-set tasks and 7 open-set tasks demonstrates that NPM outperforms significantly larger parametric models, either with or without a retrieve-and-generate approach. It is particularly better on dealing with rare patterns (word senses or facts), and predicting rare or nearly unseen words (e.g., non-Latin script). We release the model and code at github.com/facebookresearch/NPM.
Coder Reviewer Reranking for Code Generation
Nov 29, 2022



Sampling diverse programs from a code language model and reranking with model likelihood is a popular method for code generation but it is prone to preferring degenerate solutions. Inspired by collaborative programming, we propose Coder-Reviewer reranking. We augment Coder language models from past work, which generate programs given language instructions, with Reviewer models, which evaluate the likelihood of the instruction given the generated programs. We perform an extensive study across six datasets with eight models from three model families. Experimental results show that Coder-Reviewer reranking leads to consistent and significant improvement (up to 17% absolute accuracy gain) over reranking with the Coder model only. When combined with executability filtering, Coder-Reviewer reranking can often outperform the minimum Bayes risk method. Coder-Reviewer reranking is easy to implement by prompting, can generalize to different programming languages, and works well with off-the-shelf hyperparameters.
Retrieval-Augmented Multimodal Language Modeling
Nov 22, 2022



Recent multimodal models such as DALL-E and CM3 have achieved remarkable progress in text-to-image and image-to-text generation. However, these models store all learned knowledge (e.g., the appearance of the Eiffel Tower) in the model parameters, requiring increasingly larger models and training data to capture more knowledge. To integrate knowledge in a more scalable and modular way, we propose a retrieval-augmented multimodal model, which enables a base multimodal model (generator) to refer to relevant knowledge fetched by a retriever from external memory (e.g., multimodal documents on the web). Specifically, we implement a retriever using the pretrained CLIP model and a generator using the CM3 Transformer architecture, and train this model using the LAION dataset. Our resulting model, named Retrieval-Augmented CM3 (RA-CM3), is the first multimodal model that can retrieve and generate mixtures of text and images. We show that RA-CM3 significantly outperforms baseline multimodal models such as DALL-E and CM3 on both image and caption generation tasks (12 FID and 17 CIDEr improvements on MS-COCO), while requiring much less compute for training (<30% of DALL-E). Moreover, we show that RA-CM3 exhibits novel capabilities such as knowledge-intensive image generation and multimodal in-context learning.
CITADEL: Conditional Token Interaction via Dynamic Lexical Routing for Efficient and Effective Multi-Vector Retrieval
Nov 18, 2022



Multi-vector retrieval methods combine the merits of sparse (e.g. BM25) and dense (e.g. DPR) retrievers and have achieved state-of-the-art performance on various retrieval tasks. These methods, however, are orders of magnitude slower and need much more space to store their indices compared to their single-vector counterparts. In this paper, we unify different multi-vector retrieval models from a token routing viewpoint and propose conditional token interaction via dynamic lexical routing, namely CITADEL, for efficient and effective multi-vector retrieval. CITADEL learns to route different token vectors to the predicted lexical ``keys'' such that a query token vector only interacts with document token vectors routed to the same key. This design significantly reduces the computation cost while maintaining high accuracy. Notably, CITADEL achieves the same or slightly better performance than the previous state of the art, ColBERT-v2, on both in-domain (MS MARCO) and out-of-domain (BEIR) evaluations, while being nearly 40 times faster. Code and data are available at https://github.com/facebookresearch/dpr-scale.
Task-aware Retrieval with Instructions
Nov 16, 2022



We study the problem of retrieval with instructions, where users of a retrieval system explicitly describe their intent along with their queries, making the system task-aware. We aim to develop a general-purpose task-aware retrieval systems using multi-task instruction tuning that can follow human-written instructions to find the best documents for a given query. To this end, we introduce the first large-scale collection of approximately 40 retrieval datasets with instructions, and present TART, a multi-task retrieval system trained on the diverse retrieval tasks with instructions. TART shows strong capabilities to adapt to a new task via instructions and advances the state of the art on two zero-shot retrieval benchmarks, BEIR and LOTTE, outperforming models up to three times larger. We further introduce a new evaluation setup to better reflect real-world scenarios, pooling diverse documents and tasks. In this setup, TART significantly outperforms competitive baselines, further demonstrating the effectiveness of guiding retrieval with instructions.
RoMQA: A Benchmark for Robust, Multi-evidence, Multi-answer Question Answering
Oct 25, 2022We introduce RoMQA, the first benchmark for robust, multi-evidence, multi-answer question answering (QA). RoMQA contains clusters of questions that are derived from related constraints mined from the Wikidata knowledge graph. RoMQA evaluates robustness of QA models to varying constraints by measuring worst-case performance within each question cluster. Compared to prior QA datasets, RoMQA has more human-written questions that require reasoning over more evidence text and have, on average, many more correct answers. In addition, human annotators rate RoMQA questions as more natural or likely to be asked by people. We evaluate state-of-the-art large language models in zero-shot, few-shot, and fine-tuning settings, and find that RoMQA is challenging: zero-shot and few-shot models perform similarly to naive baselines, while supervised retrieval methods perform well below gold evidence upper bounds. Moreover, existing models are not robust to variations in question constraints, but can be made more robust by tuning on clusters of related questions. Our results show that RoMQA is a challenging benchmark for large language models, and provides a quantifiable test to build more robust QA methods.
Adapting Pretrained Text-to-Text Models for Long Text Sequences
Sep 21, 2022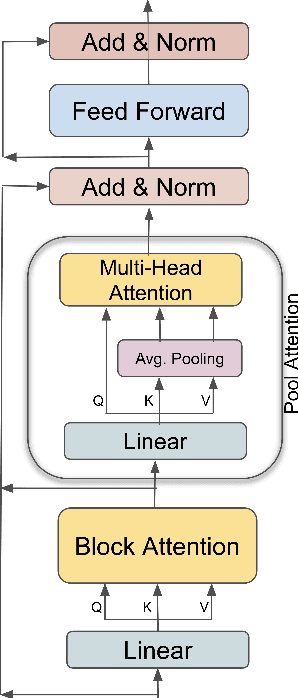
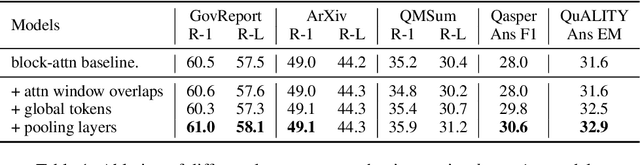
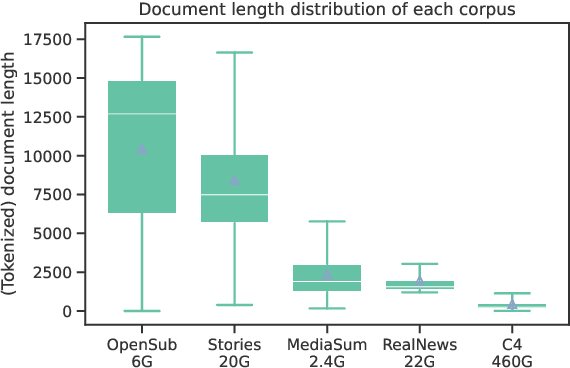
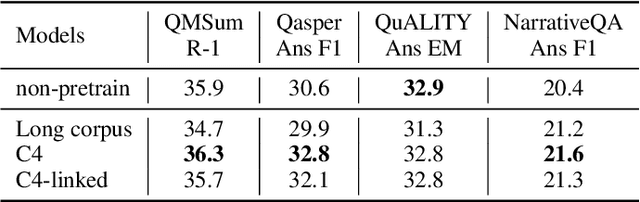
We present an empirical study of adapting an existing pretrained text-to-text model for long-sequence inputs. Through a comprehensive study along three axes of the pretraining pipeline -- model architecture, optimization objective, and pretraining corpus, we propose an effective recipe to build long-context models from existing short-context models. Specifically, we replace the full attention in transformers with pooling-augmented blockwise attention, and pretrain the model with a masked-span prediction task with spans of varying length. In terms of the pretraining corpus, we find that using randomly concatenated short-documents from a large open-domain corpus results in better performance than using existing long document corpora which are typically limited in their domain coverage. With these findings, we build a long-context model that achieves competitive performance on long-text QA tasks and establishes the new state of the art on five long-text summarization datasets, often outperforming previous methods with larger model sizes.