 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Robustness for Pose Estimation via Stable Heatmap Regression
May 08, 2021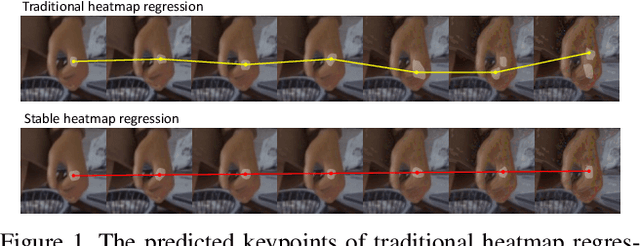

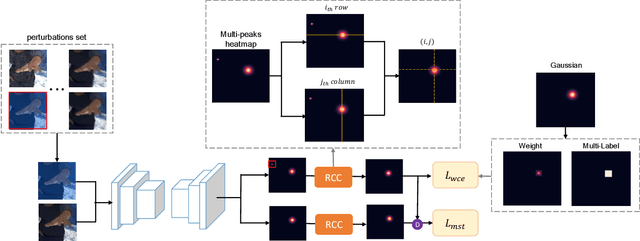

Deep learning methods have achieved excellent performance in pose estimation, but the lack of robustness causes the keypoints to change drastically between similar images. In view of this problem, a stable heatmap regression method is proposed to alleviate network vulnerability to small perturbations. We utilize the correlation between different rows and columns in a heatmap to alleviate the multi-peaks problem, and design a highly differentiated heatmap regression to make a keypoint discriminative from surrounding points. A maximum stability training loss is used to simplify the optimization difficulty when minimizing the prediction gap of two similar images. The proposed method achieves a significant advance in robustness over state-of-the-art approaches on two benchmark datasets and maintains high performance.
Camera-Space Hand Mesh Recovery via Semantic Aggregation and Adaptive 2D-1D Registration
Mar 31, 2021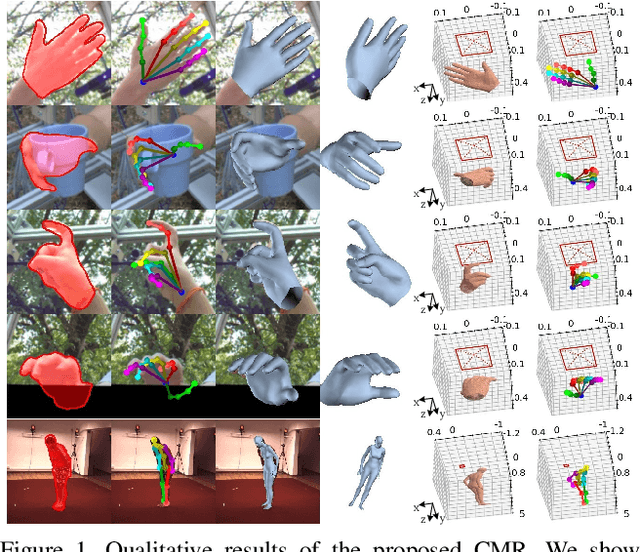
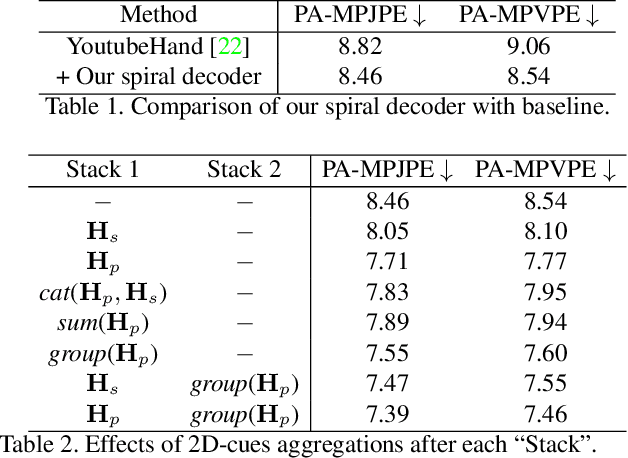
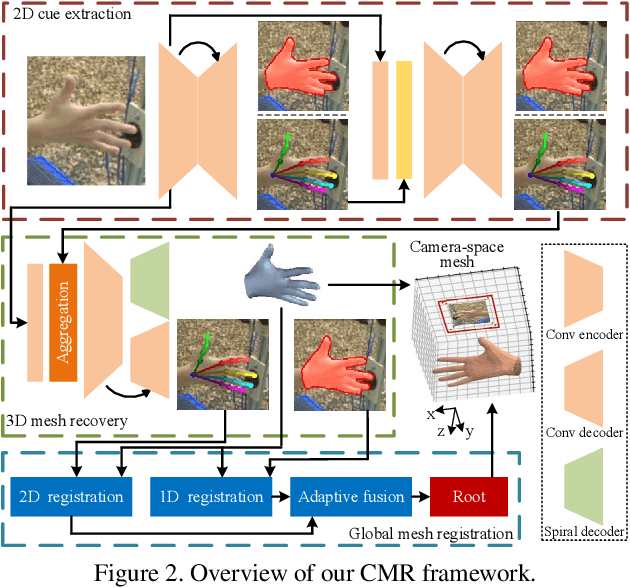
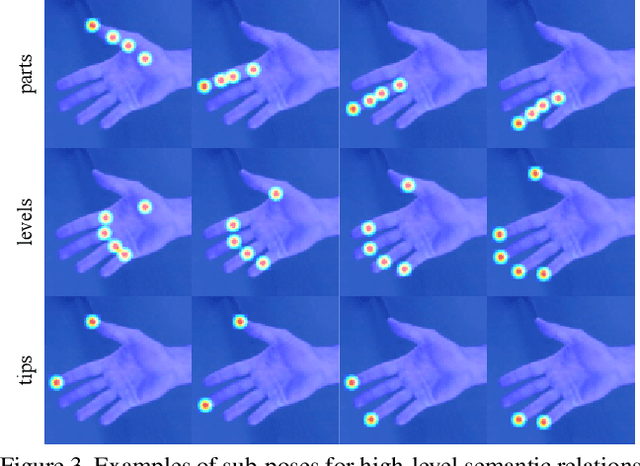
Recent years have witnessed significant progress in 3D hand mesh recovery. Nevertheless, because of the intrinsic 2D-to-3D ambiguity, recovering camera-space 3D information from a single RGB image remains challenging. To tackle this problem, we divide camera-space mesh recovery into two sub-tasks, i.e., root-relative mesh recovery and root recovery. First, joint landmarks and silhouette are extracted from a single input image to provide 2D cues for the 3D tasks. In the root-relative mesh recovery task, we exploit semantic relations among joints to generate a 3D mesh from the extracted 2D cues. Such generated 3D mesh coordinates are expressed relative to a root position, i.e., wrist of the hand. In the root recovery task, the root position is registered to the camera space by aligning the generated 3D mesh back to 2D cues, thereby completing cameraspace 3D mesh recovery. Our pipeline is novel in that (1) it explicitly makes use of known semantic relations among joints and (2) it exploits 1D projections of the silhouette and mesh to achieve robust registration. Extensive experiments on popular datasets such as FreiHAND, RHD, and Human3.6M demonstrate that our approach achieves stateof-the-art performance on both root-relative mesh recovery and root recovery. Our code is publicly available at https://github.com/SeanChenxy/HandMesh.
Cycle4Completion: Unpaired Point Cloud Completion using Cycle Transformation with Missing Region Coding
Mar 14, 2021
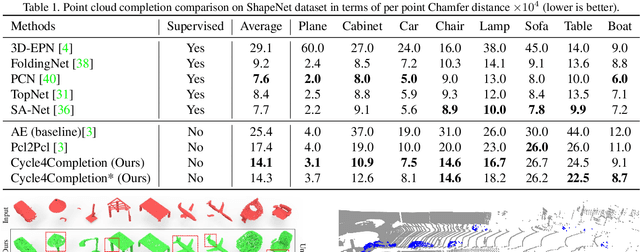
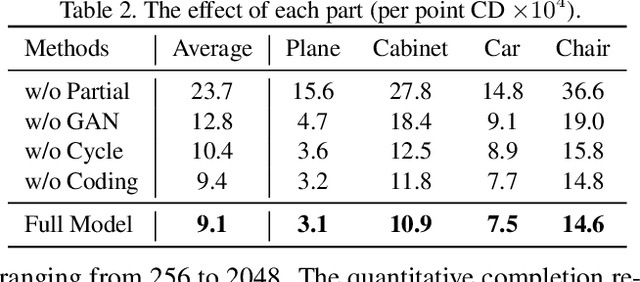
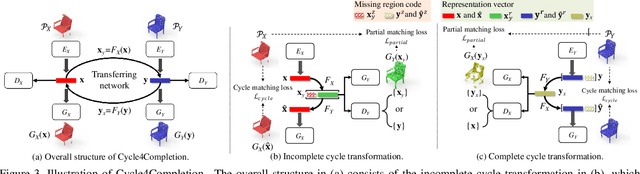
In this paper, we present a novel unpaired point cloud completion network, named Cycle4Completion, to infer the complete geometries from a partial 3D object. Previous unpaired completion methods merely focus on the learning of geometric correspondence from incomplete shapes to complete shapes, and ignore the learning in the reverse direction, which makes them suffer from low completion accuracy due to the limited 3D shape understanding ability. To address this problem, we propose two simultaneous cycle transformations between the latent spaces of complete shapes and incomplete ones. The insight of cycle transformation is to promote networks to understand 3D shapes by learning to generate complete or incomplete shapes from their complementary ones. Specifically, the first cycle transforms shapes from incomplete domain to complete domain, and then projects them back to the incomplete domain. This process learns the geometric characteristic of complete shapes, and maintains the shape consistency between the complete prediction and the incomplete input. Similarly, the inverse cycle transformation starts from complete domain to incomplete domain, and goes back to complete domain to learn the characteristic of incomplete shapes. We provide a comprehensive evaluation in experiments, which shows that our model with the learned bidirectional geometry correspondence outperforms state-of-the-art unpaired completion methods.
PMP-Net: Point Cloud Completion by Learning Multi-step Point Moving Paths
Dec 07, 2020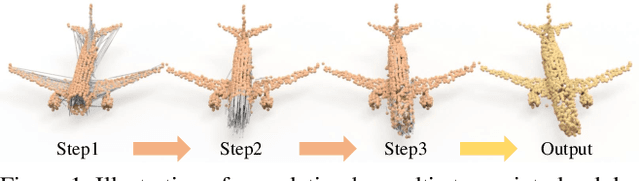
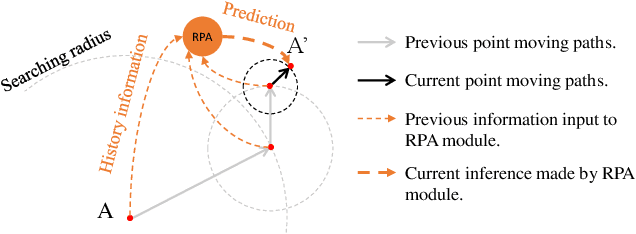
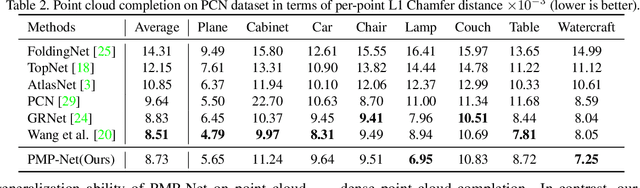
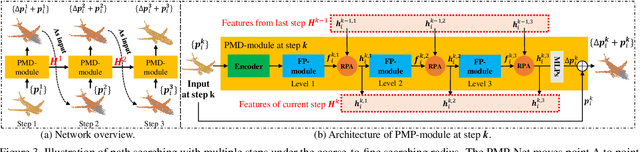
The task of point cloud completion aims to predict the missing part for an incomplete 3D shape. A widely used strategy is to generate a complete point cloud from the incomplete one. However, the unordered nature of point clouds will degrade the generation of high-quality 3D shapes, as the detailed topology and structure of discrete points are hard to be captured by the generative process only using a latent code. In this paper, we address the above problem by reconsidering the completion task from a new perspective, where we formulate the prediction as a point cloud deformation process. Specifically, we design a novel neural network, named PMP-Net, to mimic the behavior of an earth mover. It moves move each point of the incomplete input to complete the point cloud, where the total distance of point moving paths (PMP) should be shortest. Therefore, PMP-Net predicts a unique point moving path for each point according to the constraint of total point moving distances. As a result, the network learns a strict and unique correspondence on point-level, which can capture the detailed topology and structure relationships between the incomplete shape and the complete target, and thus improves the quality of the predicted complete shape. We conduct comprehensive experiments on Completion3D and PCN datasets, which demonstrate our advantages over the state-of-the-art point cloud completion methods.
Improving Monocular Depth Estimation by Leveraging Structural Awareness and Complementary Datasets
Jul 22, 2020
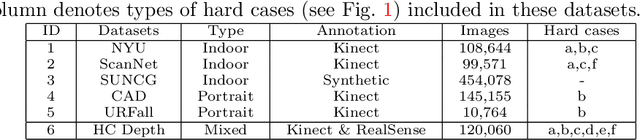
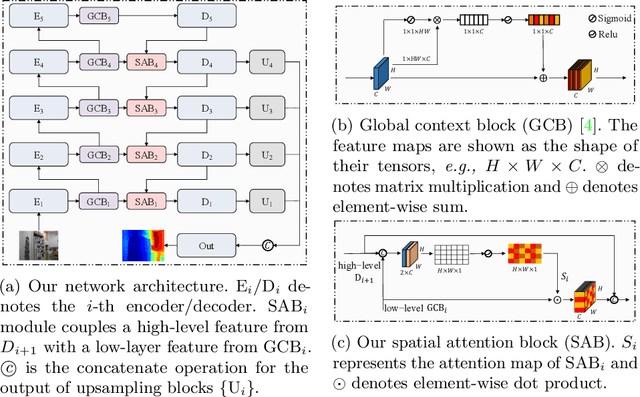
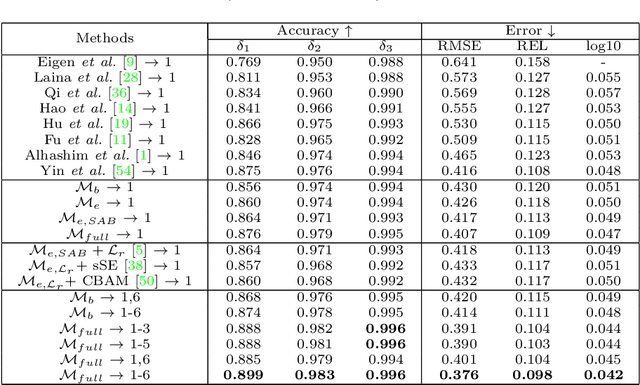
Monocular depth estimation plays a crucial role in 3D recognition and understanding. One key limitation of existing approaches lies in their lack of structural information exploitation, which leads to inaccurate spatial layout, discontinuous surface, and ambiguous boundaries. In this paper, we tackle this problem in three aspects. First, to exploit the spatial relationship of visual features, we propose a structure-aware neural network with spatial attention blocks. These blocks guide the network attention to global structures or local details across different feature layers. Second, we introduce a global focal relative loss for uniform point pairs to enhance spatial constraint in the prediction, and explicitly increase the penalty on errors in depth-wise discontinuous regions, which helps preserve the sharpness of estimation results. Finally, based on analysis of failure cases for prior methods, we collect a new Hard Case (HC) Depth dataset of challenging scenes, such as special lighting conditions, dynamic objects, and tilted camera angles. The new dataset is leveraged by an informed learning curriculum that mixes training examples incrementally to handle diverse data distributions. Experimental results show that our method outperforms state-of-the-art approaches by a large margin in terms of both prediction accuracy on NYUDv2 dataset and generalization performance on unseen datasets.
Siamese Keypoint Prediction Network for Visual Object Tracking
Jun 07, 2020
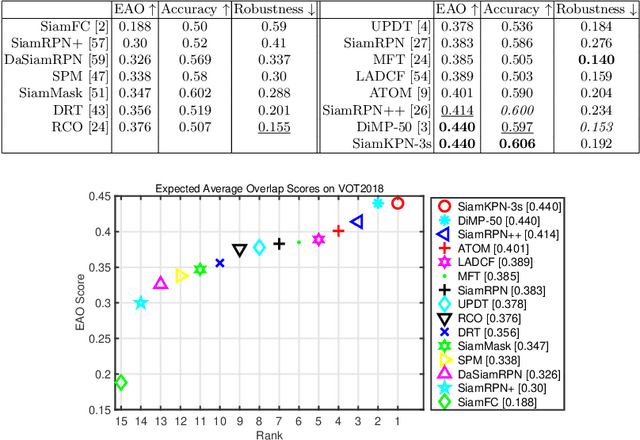
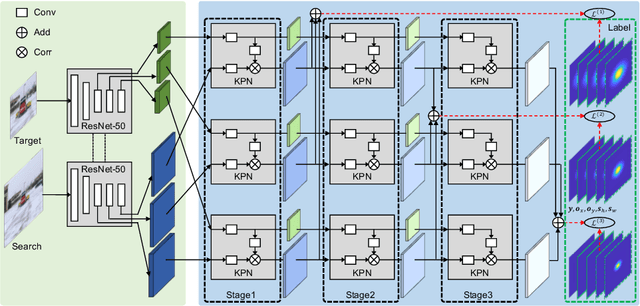
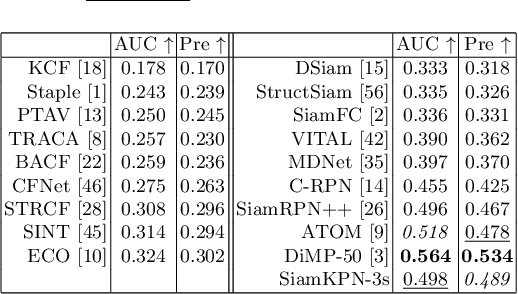
Visual object tracking aims to estimate the location of an arbitrary target in a video sequence given its initial bounding box. By utilizing offline feature learning, the siamese paradigm has recently been the leading framework for high performance tracking. However, current existing siamese trackers either heavily rely on complicated anchor-based detection networks or lack the ability to resist to distractors. In this paper, we propose the Siamese keypoint prediction network (SiamKPN) to address these challenges. Upon a Siamese backbone for feature embedding, SiamKPN benefits from a cascade heatmap strategy for coarse-to-fine prediction modeling. In particular, the strategy is implemented by sequentially shrinking the coverage of the label heatmap along the cascade to apply loose-to-strict intermediate supervisions. During inference, we find the predicted heatmaps of successive stages to be gradually concentrated to the target and reduced to the distractors. SiamKPN performs well against state-of-the-art trackers for visual object tracking on four benchmark datasets including OTB-100, VOT2018, LaSOT and GOT-10k, while running at real-time speed.
Adaptive Wasserstein Hourglass for Weakly Supervised Hand Pose Estimation from Monocular RGB
Sep 11, 2019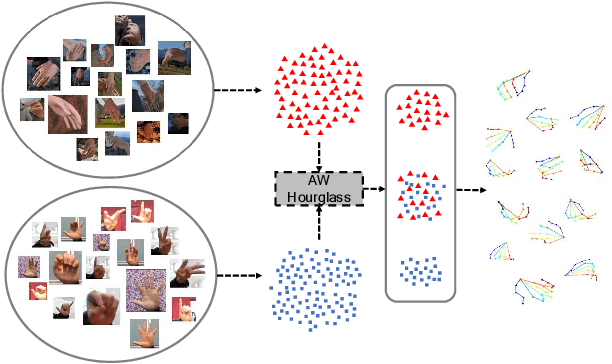
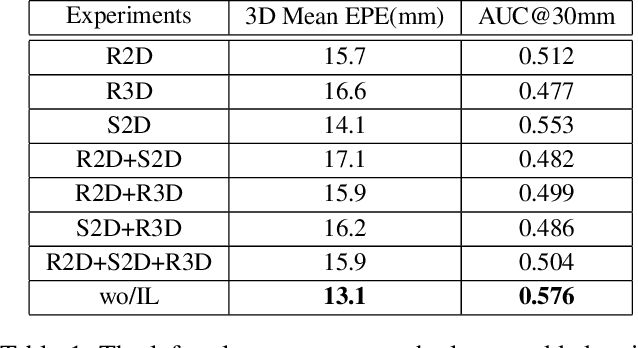
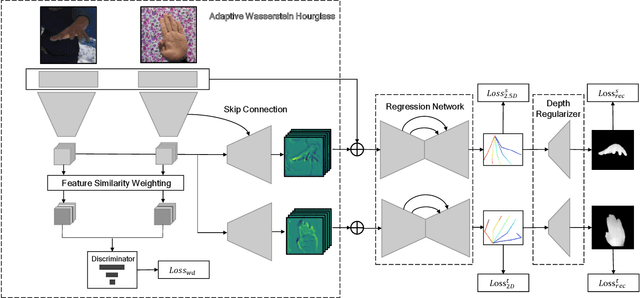
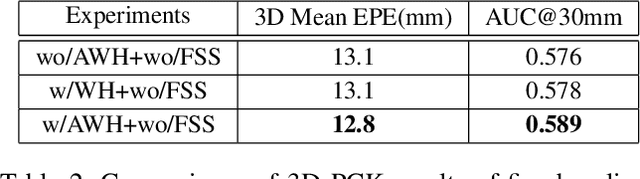
Insufficient labeled training datasets is one of the bottlenecks of 3D hand pose estimation from monocular RGB images. Synthetic datasets have a large number of images with precise annotations, but the obvious difference with real-world datasets impacts the generalization. Little work has been done to bridge the gap between two domains over their wide difference. In this paper, we propose a domain adaptation method called Adaptive Wasserstein Hourglass (AW Hourglass) for weakly-supervised 3D hand pose estimation, which aims to distinguish the difference and explore the common characteristics (e.g. hand structure) of synthetic and real-world datasets. Learning the common characteristics helps the network focus on pose-related information. The similarity of the characteristics makes it easier to enforce domain-invariant constraints. During training, based on the relation between these common characteristics and 3D pose learned from fully-annotated synthetic datasets, it is beneficial for the network to restore the 3D pose of weakly labeled real-world datasets with the aid of 2D annotations and depth images. While in testing, the network predicts the 3D pose with the input of RGB.
StyleRemix: An Interpretable Representation for Neural Image Style Transfer
Mar 25, 2019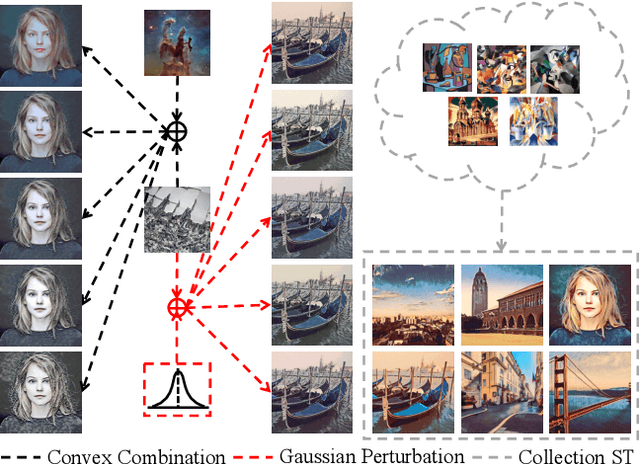

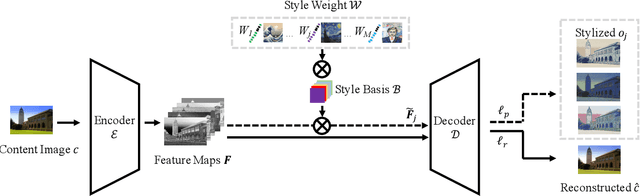
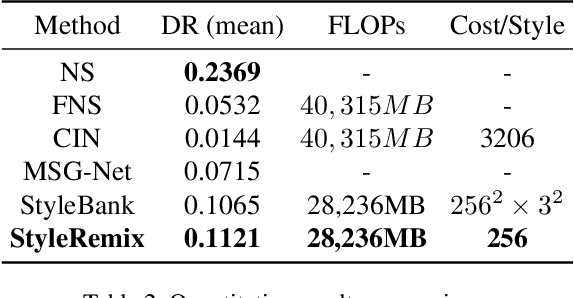
Multi-Style Transfer (MST) intents to capture the high-level visual vocabulary of different styles and expresses these vocabularies in a joint model to transfer each specific style. Recently, Style Embedding Learning (SEL) based methods represent each style with an explicit set of parameters to perform MST task. However, most existing SEL methods either learn explicit style representation with numerous independent parameters or learn a relatively black-box style representation, which makes them difficult to control the stylized results. In this paper, we outline a novel MST model, StyleRemix, to compactly and explicitly integrate multiple styles into one network. By decomposing diverse styles into the same basis, StyleRemix represents a specific style in a continuous vector space with 1-dimensional coefficients. With the interpretable style representation, StyleRemix not only enables the style visualization task but also allows several ways of remixing styles in the smooth style embedding space.~Extensive experiments demonstrate the effectiveness of StyleRemix on various MST tasks compared to state-of-the-art SEL approaches.
End-to-end Hand Mesh Recovery from a Monocular RGB Image
Mar 09, 2019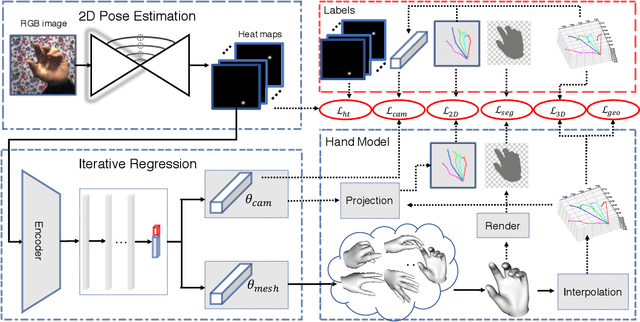
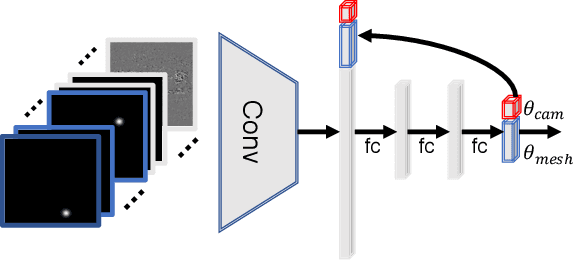
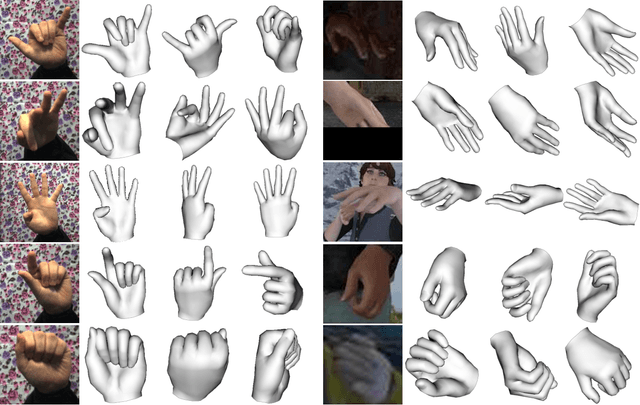

In this paper, we present a HAnd Mesh Recovery (HAMR) framework to tackle the problem of reconstructing the full 3D mesh of a human hand from a single RGB image. In contrast to existing research on 2D or 3D hand pose estimation from RGB or/and depth image data, HAMR can provide a more expressive and useful mesh representation for monocular hand image understanding. In particular, the mesh representation is achieved by parameterizing a generic 3D hand model with shape and relative 3D joint angles. By utilizing this mesh representation, we can easily compute the 3D joint locations via linear interpolations between the vertexes of the mesh, while obtain the 2D joint locations with a projection of the 3D joints.To this end, a differentiable re-projection loss can be defined in terms of the derived representations and the ground-truth labels, thus making our framework end-to-end trainable.Qualitative experiments show that our framework is capable of recovering appealing 3D hand mesh even in the presence of severe occlusions.Quantitatively, our approach also outperforms the state-of-the-art methods for both 2D and 3D hand pose estimation from a monocular RGB image on several benchmark datasets.