 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal Patch Encoding-Based Method for Single Image Super-Resolution
Jul 04, 2018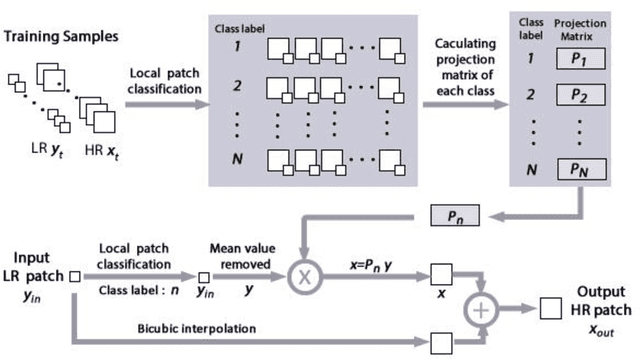
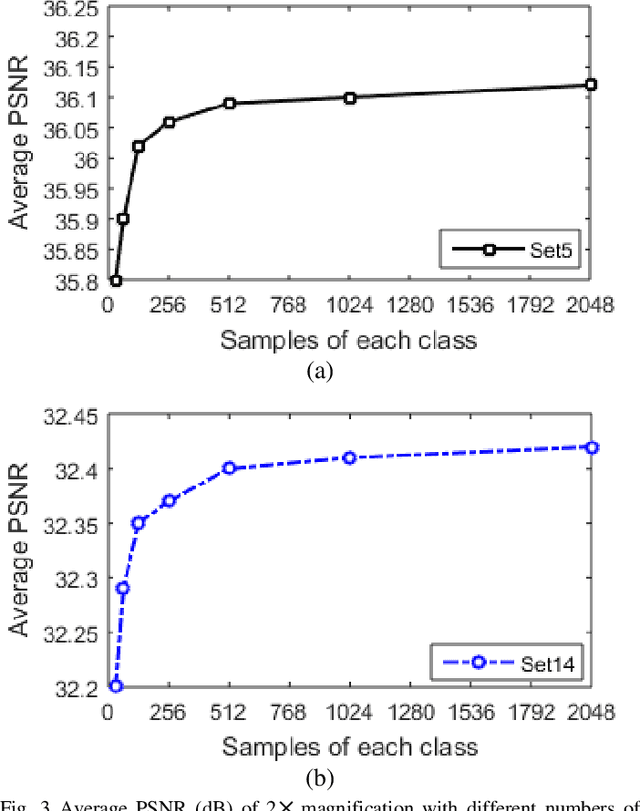


Recent learning-based super-resolution (SR) methods often focus on dictionary learning or network training. In this paper, we discuss in detail a new SR method based on local patch encoding (LPE) instead of traditional dictionary learning. The proposed method consists of a learning stage and a reconstructing stage. In the learning stage, image patches are classified into different classes by means of the proposed LPE, and then a projection matrix is computed for each class by utilizing a simple constraint. In the reconstructing stage, an input LR patch can be simply reconstructed by computing its LPE code and then multiplying the corresponding projection matrix. Furthermore, we discuss the relationship between the proposed method and the anchored neighborhood regression methods; we also analyze the extendibility of the proposed method. The experimental results on several image sets demonstrate the effectiveness of the LPE-based methods.
* 20 pages, 8 figures
Person Transfer GAN to Bridge Domain Gap for Person Re-Identification
Jun 25, 2018

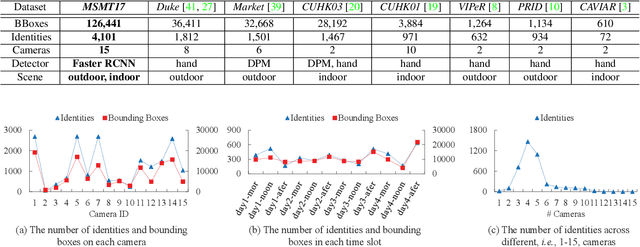
Although the performance of person Re-Identification (ReID) has been significantly boosted, many challenging issues in real scenarios have not been fully investigated, e.g., the complex scenes and lighting variations, viewpoint and pose changes, and the large number of identities in a camera network. To facilitate the research towards conquering those issues, this paper contributes a new dataset called MSMT17 with many important features, e.g., 1) the raw videos are taken by an 15-camera network deployed in both indoor and outdoor scenes, 2) the videos cover a long period of time and present complex lighting variations, and 3) it contains currently the largest number of annotated identities, i.e., 4,101 identities and 126,441 bounding boxes. We also observe that, domain gap commonly exists between datasets, which essentially causes severe performance drop when training and testing on different datasets. This results in that available training data cannot be effectively leveraged for new testing domains. To relieve the expensive costs of annotating new training samples, we propose a Person Transfer Generative Adversarial Network (PTGAN) to bridge the domain gap. Comprehensive experiments show that the domain gap could be substantially narrowed-down by the PTGAN.
RAM: A Region-Aware Deep Model for Vehicle Re-Identification
Jun 25, 2018
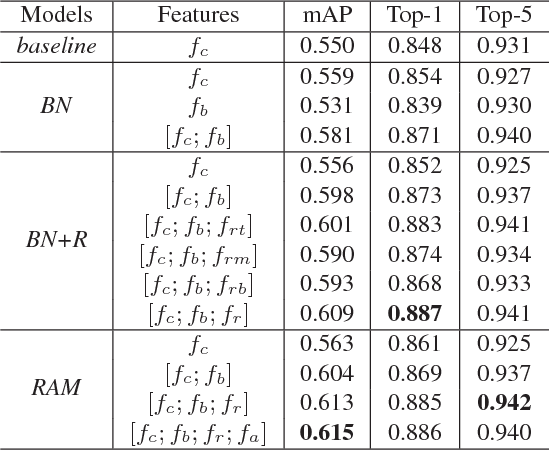
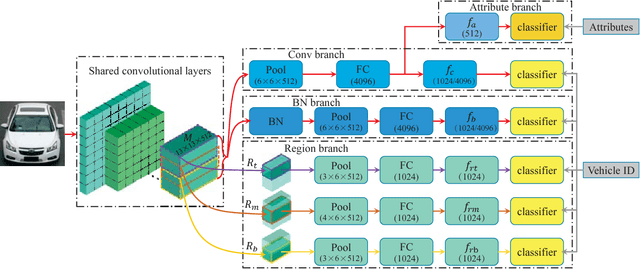
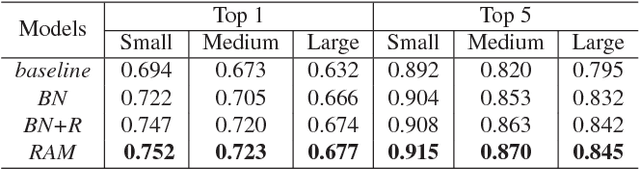
Previous works on vehicle Re-ID mainly focus on extracting global features and learning distance metrics. Because some vehicles commonly share same model and maker, it is hard to distinguish them based on their global appearances. Compared with the global appearance, local regions such as decorations and inspection stickers attached to the windshield, may be more distinctive for vehicle Re-ID. To embed the detailed visual cues in those local regions, we propose a Region-Aware deep Model (RAM). Specifically, in addition to extracting global features, RAM also extracts features from a series of local regions. As each local region conveys more distinctive visual cues, RAM encourages the deep model to learn discriminative features. We also introduce a novel learning algorithm to jointly use vehicle IDs, types/models, and colors to train the RAM. This strategy fuses more cues for training and results in more discriminative global and regional features. We evaluate our methods on two large-scale vehicle Re-ID datasets, i.e., VeRi and VehicleID. Experimental results show our methods achieve promising performance in comparison with recent works.
Globally Variance-Constrained Sparse Representation and Its Application in Image Set Coding
May 03, 2018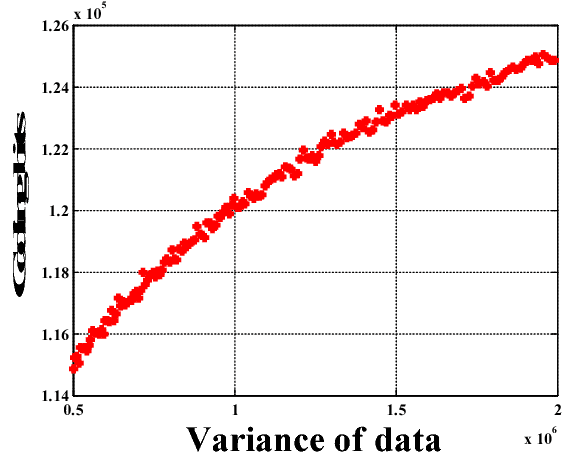

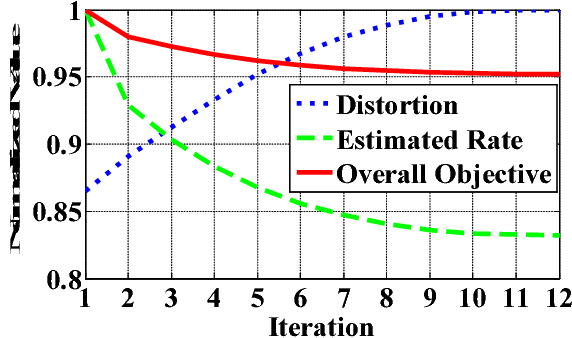
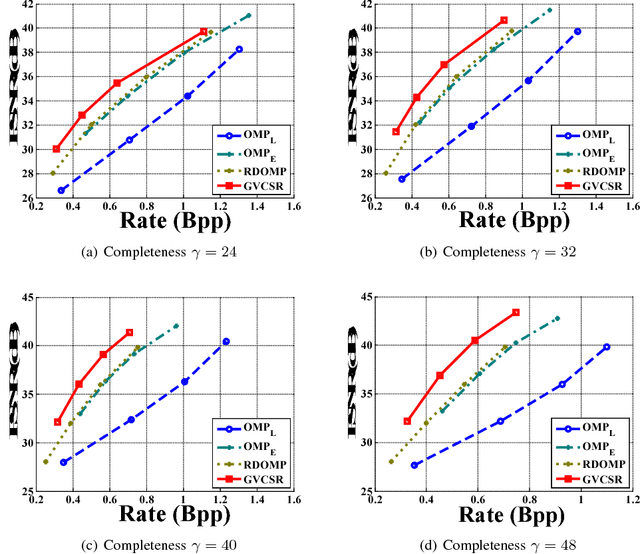
Sparse representation leads to an efficient way to approximately recover a signal by the linear composition of a few bases from a learnt dictionary, based on which various successful applications have been achieved. However, in the scenario of data compression, its efficiency and popularity are hindered. It is because of the fact that encoding sparsely distributed coefficients may consume more bits for representing the index of nonzero coefficients. Therefore, introducing an accurate rate-constraint in sparse coding and dictionary learning becomes meaningful, which has not been fully exploited in the context of sparse representation. According to the Shannon entropy inequality, the variance of a Gaussian distributed data bounds its entropy, indicating the actual bitrate can be well estimated by its variance. Hence, a Globally Variance-Constrained Sparse Representation (GVCSR) model is proposed in this work, where a variance-constrained rate term is introduced to the optimization process. Specifically, we employ the Alternating Direction Method of Multipliers (ADMM) to solve the non-convex optimization problem for sparse coding and dictionary learning, both of them have shown the state-of-the-art rate-distortion performance for image representation. Furthermore, we investigate the potential of applying the GVCSR algorithm in the practical image set compression, where the optimized dictionary is trained to efficiently represent the images captured in similar scenarios by implicitly utilizing inter-image correlations. Experimental results have demonstrated superior rate-distortion performance against the state-of-the-art methods.
Graph-Based Blind Image Deblurring From a Single Photograph
Feb 22, 2018



Blind image deblurring, i.e., deblurring without knowledge of the blur kernel, is a highly ill-posed problem. The problem can be solved in two parts: i) estimate a blur kernel from the blurry image, and ii) given estimated blur kernel, de-convolve blurry input to restore the target image. In this paper, we propose a graph-based blind image deblurring algorithm by interpreting an image patch as a signal on a weighted graph. Specifically, we first argue that a skeleton image---a proxy that retains the strong gradients of the target but smooths out the details---can be used to accurately estimate the blur kernel and has a unique bi-modal edge weight distribution. Then, we design a reweighted graph total variation (RGTV) prior that can efficiently promote a bi-modal edge weight distribution given a blurry patch. Further, to analyze RGTV in the graph frequency domain, we introduce a new weight function to represent RGTV as a graph $l_1$-Laplacian regularizer. This leads to a graph spectral filtering interpretation of the prior with desirable properties, including robustness to noise and blur, strong piecewise smooth (PWS) filtering and sharpness promotion. Minimizing a blind image deblurring objective with RGTV results in a non-convex non-differentiable optimization problem. We leverage the new graph spectral interpretation for RGTV to design an efficient algorithm that solves for the skeleton image and the blur kernel alternately. Specifically for Gaussian blur, we propose a further speedup strategy for blind Gaussian deblurring using accelerated graph spectral filtering. Finally, with the computed blur kernel, recent non-blind image deblurring algorithms can be applied to restore the target image. Experimental results demonstrate that our algorithm successfully restores latent sharp images and outperforms state-of-the-art methods quantitatively and qualitatively.
Blind Image Deblurring via Reweighted Graph Total Variation
Dec 24, 2017
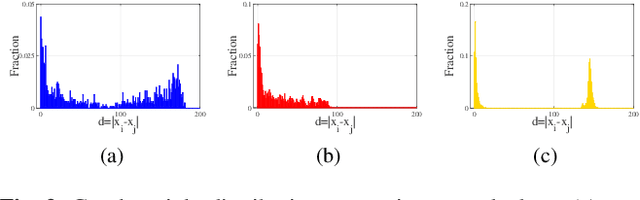
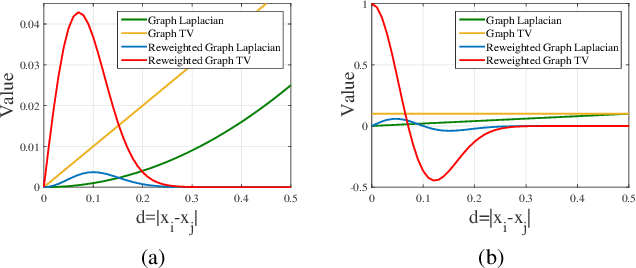

Blind image deblurring, i.e., deblurring without knowledge of the blur kernel, is a highly ill-posed problem. The problem can be solved in two parts: i) estimate a blur kernel from the blurry image, and ii) given estimated blur kernel, de-convolve blurry input to restore the target image. In this paper, by interpreting an image patch as a signal on a weighted graph, we first argue that a skeleton image---a proxy that retains the strong gradients of the target but smooths out the details---can be used to accurately estimate the blur kernel and has a unique bi-modal edge weight distribution. We then design a reweighted graph total variation (RGTV) prior that can efficiently promote bi-modal edge weight distribution given a blurry patch. However, minimizing a blind image deblurring objective with RGTV results in a non-convex non-differentiable optimization problem. We propose a fast algorithm that solves for the skeleton image and the blur kernel alternately. Finally with the computed blur kernel, recent non-blind image deblurring algorithms can be applied to restore the target image. Experimental results show that our algorithm can robustly estimate the blur kernel with large kernel size, and the reconstructed sharp image is competitive against the state-of-the-art methods.
AI Oriented Large-Scale Video Management for Smart City: Technologies, Standards and Beyond
Dec 05, 2017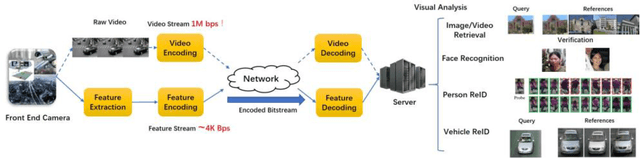
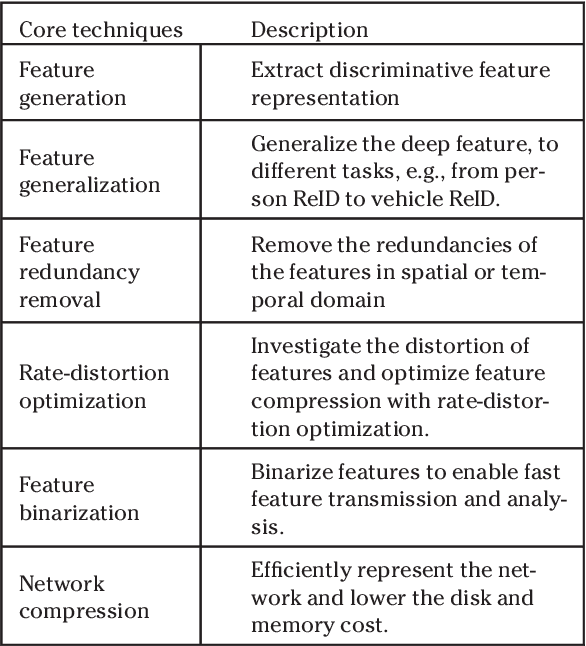
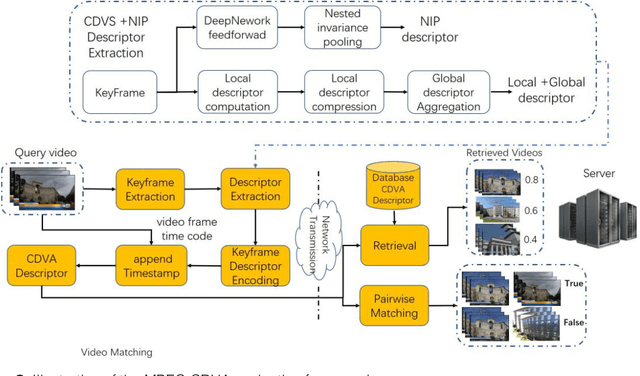
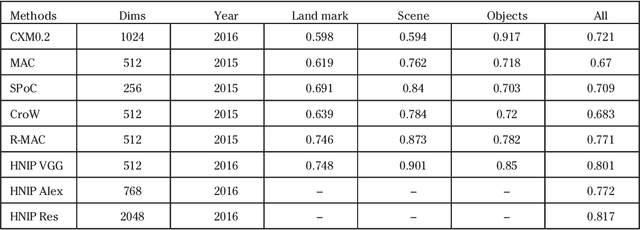
Deep learning has achieved substantial success in a series of tasks in computer vision. Intelligent video analysis, which can be broadly applied to video surveillance in various smart city applications, can also be driven by such powerful deep learning engines. To practically facilitate deep neural network models in the large-scale video analysis, there are still unprecedented challenges for the large-scale video data management. Deep feature coding, instead of video coding, provides a practical solution for handling the large-scale video surveillance data. To enable interoperability in the context of deep feature coding, standardization is urgent and important. However, due to the explosion of deep learning algorithms and the particularity of feature coding, there are numerous remaining problems in the standardization process. This paper envisions the future deep feature coding standard for the AI oriented large-scale video management, and discusses existing techniques, standards and possible solutions for these open problems.
A Bio-Inspired Multi-Exposure Fusion Framework for Low-light Image Enhancement
Nov 02, 2017
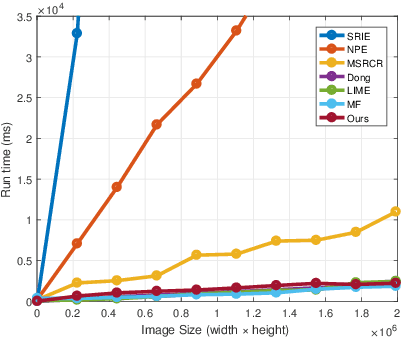

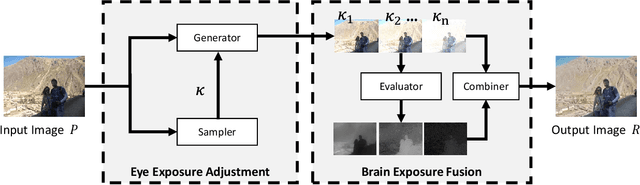
Low-light images are not conducive to human observation and computer vision algorithms due to their low visibility. Although many image enhancement techniques have been proposed to solve this problem, existing methods inevitably introduce contrast under- and over-enhancement. Inspired by human visual system, we design a multi-exposure fusion framework for low-light image enhancement. Based on the framework, we propose a dual-exposure fusion algorithm to provide an accurate contrast and lightness enhancement. Specifically, we first design the weight matrix for image fusion using illumination estimation techniques. Then we introduce our camera response model to synthesize multi-exposure images. Next, we find the best exposure ratio so that the synthetic image is well-exposed in the regions where the original image is under-exposed. Finally, the enhanced result is obtained by fusing the input image and the synthetic image according to the weight matrix. Experiments show that our method can obtain results with less contrast and lightness distortion compared to that of several state-of-the-art methods.
Pose-driven Deep Convolutional Model for Person Re-identification
Sep 25, 2017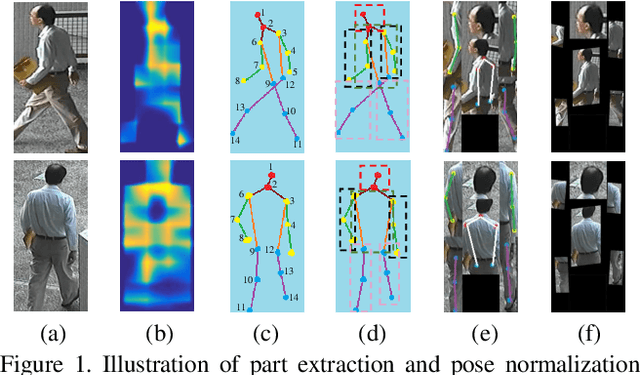
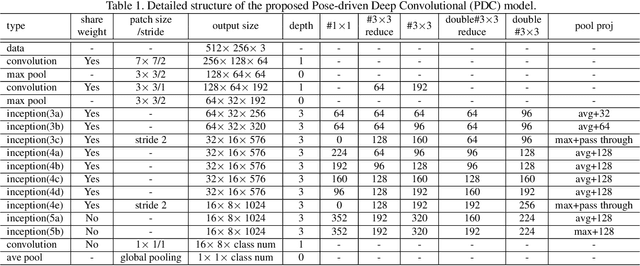
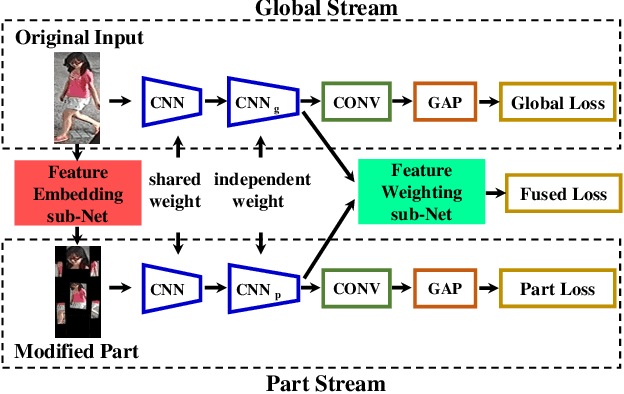
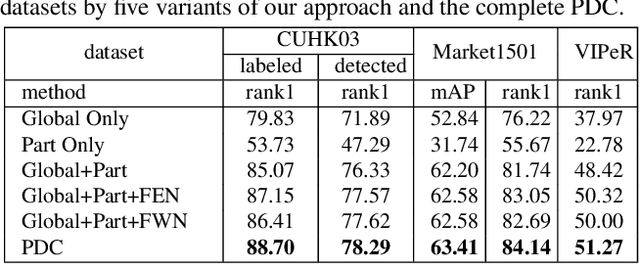
Feature extraction and matching are two crucial components in person Re-Identification (ReID). The large pose deformations and the complex view variations exhibited by the captured person images significantly increase the difficulty of learning and matching of the features from person images. To overcome these difficulties, in this work we propose a Pose-driven Deep Convolutional (PDC) model to learn improved feature extraction and matching models from end to end. Our deep architecture explicitly leverages the human part cues to alleviate the pose variations and learn robust feature representations from both the global image and different local parts. To match the features from global human body and local body parts, a pose driven feature weighting sub-network is further designed to learn adaptive feature fusions. Extensive experimental analyses and results on three popular datasets demonstrate significant performance improvements of our model over all published state-of-the-art methods.
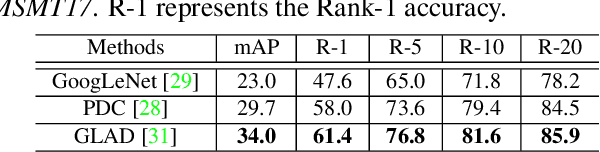
GLAD: Global-Local-Alignment Descriptor for Pedestrian Retrieval
Sep 13, 2017
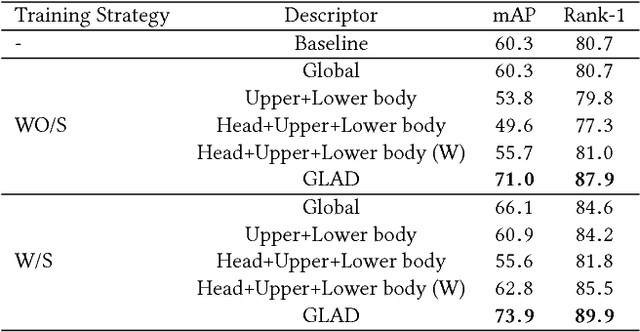
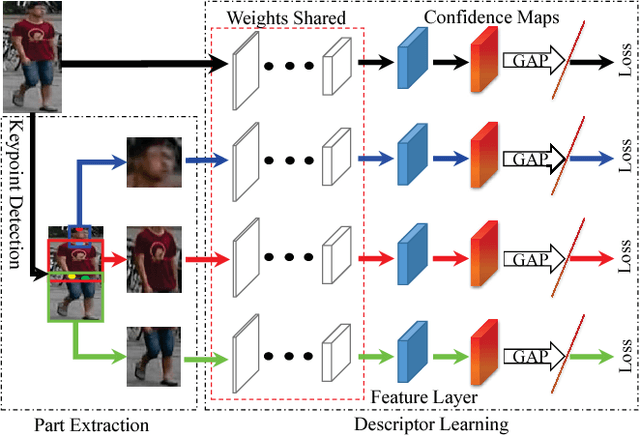

The huge variance of human pose and the misalignment of detected human images significantly increase the difficulty of person Re-Identification (Re-ID). Moreover, efficient Re-ID systems are required to cope with the massive visual data being produced by video surveillance systems. Targeting to solve these problems, this work proposes a Global-Local-Alignment Descriptor (GLAD) and an efficient indexing and retrieval framework, respectively. GLAD explicitly leverages the local and global cues in human body to generate a discriminative and robust representation. It consists of part extraction and descriptor learning modules, where several part regions are first detected and then deep neural networks are designed for representation learning on both the local and global regions. A hierarchical indexing and retrieval framework is designed to eliminate the huge redundancy in the gallery set, and accelerate the online Re-ID procedure. Extensive experimental results show GLAD achieves competitive accuracy compared to the state-of-the-art methods. Our retrieval framework significantly accelerates the online Re-ID procedure without loss of accuracy. Therefore, this work has potential to work better on person Re-ID tasks in real scenarios.