 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICON: Incremental CONfidence for Joint Pose and Radiance Field Optimization
Jan 17, 2024Neural Radiance Fields (NeRF) exhibit remarkable performance for Novel View Synthesis (NVS) given a set of 2D images. However, NeRF training requires accurate camera pose for each input view, typically obtained by Structure-from-Motion (SfM) pipelines. Recent works have attempted to relax this constraint, but they still often rely on decent initial poses which they can refine. Here we aim at removing the requirement for pose initialization. We present Incremental CONfidence (ICON), an optimization procedure for training NeRFs from 2D video frames. ICON only assumes smooth camera motion to estimate initial guess for poses. Further, ICON introduces ``confidence": an adaptive measure of model quality used to dynamically reweight gradients. ICON relies on high-confidence poses to learn NeRF, and high-confidence 3D structure (as encoded by NeRF) to learn poses. We show that ICON, without prior pose initialization, achieves superior performance in both CO3D and HO3D versus methods which use SfM pose.
SiLK -- Simple Learned Keypoints
Apr 12, 2023



Keypoint detection & descriptors are foundational tech-nologies for computer vision tasks like image matching, 3D reconstruction and visual odometry. Hand-engineered methods like Harris corners, SIFT, and HOG descriptors have been used for decades; more recently, there has been a trend to introduce learning in an attempt to improve keypoint detectors. On inspection however, the results are difficult to interpret; recent learning-based methods employ a vast diversity of experimental setups and design choices: empirical results are often reported using different backbones, protocols, datasets, types of supervisions or tasks. Since these differences are often coupled together, it raises a natural question on what makes a good learned keypoint detector. In this work, we revisit the design of existing keypoint detectors by deconstructing their methodologies and identifying the key components. We re-design each component from first-principle and propose Simple Learned Keypoints (SiLK) that is fully-differentiable, lightweight, and flexible. Despite its simplicity, SiLK advances new state-of-the-art on Detection Repeatability and Homography Estimation tasks on HPatches and 3D Point-Cloud Registration task on ScanNet, and achieves competitive performance to state-of-the-art on camera pose estimation in 2022 Image Matching Challenge and ScanNet.
Open-world Instance Segmentation: Top-down Learning with Bottom-up Supervision
Mar 09, 2023



Many top-down architectures for instance segmentation achieve significant success when trained and tested on pre-defined closed-world taxonomy. However, when deployed in the open world, they exhibit notable bias towards seen classes and suffer from significant performance drop. In this work, we propose a novel approach for open world instance segmentation called bottom-Up and top-Down Open-world Segmentation (UDOS) that combines classical bottom-up segmentation algorithms within a top-down learning framework. UDOS first predicts parts of objects using a top-down network trained with weak supervision from bottom-up segmentations. The bottom-up segmentations are class-agnostic and do not overfit to specific taxonomies. The part-masks are then fed into affinity-based grouping and refinement modules to predict robust instance-level segmentations. UDOS enjoys both the speed and efficiency from the top-down architectures and the generalization ability to unseen categories from bottom-up supervision. We validate the strengths of UDOS on multiple cross-category as well as cross-dataset transfer tasks from 5 challenging datasets including MS-COCO, LVIS, ADE20k, UVO and OpenImages, achieving significant improvements over state-of-the-art across the board. Our code and models are available on our project page.
EgoTracks: A Long-term Egocentric Visual Object Tracking Dataset
Jan 11, 2023



Visual object tracking is a key component to many egocentric vision problems. However, the full spectrum of challenges of egocentric tracking faced by an embodied AI is underrepresented in many existing datasets; these tend to focus on relatively short, third-person videos. Egocentric video has several distinguishing characteristics from those commonly found in past datasets: frequent large camera motions and hand interactions with objects commonly lead to occlusions or objects exiting the frame, and object appearance can change rapidly due to widely different points of view, scale, or object states. Embodied tracking is also naturally long-term, and being able to consistently (re-)associate objects to their appearances and disappearances over as long as a lifetime is critical. Previous datasets under-emphasize this re-detection problem, and their "framed" nature has led to adoption of various spatiotemporal priors that we find do not necessarily generalize to egocentric video. We thus introduce EgoTracks, a new dataset for long-term egocentric visual object tracking. Sourced from the Ego4D dataset, this new dataset presents a significant challenge to recent state-of-the-art single-object tracking models, which we find score poorly on traditional tracking metrics for our new dataset, compared to popular benchmarks. We further show improvements that can be made to a STARK tracker to significantly increase its performance on egocentric data, resulting in a baseline model we call EgoSTARK. We publicly release our annotations and benchmark, hoping our dataset leads to further advancements in tracking.
RegCLR: A Self-Supervised Framework for Tabular Representation Learning in the Wild
Nov 02, 2022Recent advances in self-supervised learning (SSL) using large models to learn visual representations from natural images are rapidly closing the gap between the results produced by fully supervised learning and those produced by SSL on downstream vision tasks. Inspired by this advancement and primarily motivated by the emergence of tabular and structured document image applications, we investigate which self-supervised pretraining objectives, architectures, and fine-tuning strategies are most effective. To address these questions, we introduce RegCLR, a new self-supervised framework that combines contrastive and regularized methods and is compatible with the standard Vision Transformer architecture. Then, RegCLR is instantiated by integrating masked autoencoders as a representative example of a contrastive method and enhanced Barlow Twins as a representative example of a regularized method with configurable input image augmentations in both branches. Several real-world table recognition scenarios (e.g., extracting tables from document images), ranging from standard Word and Latex documents to even more challenging electronic health records (EHR) computer screen images, have been shown to benefit greatly from the representations learned from this new framework, with detection average-precision (AP) improving relatively by 4.8% for Table, 11.8% for Column, and 11.1% for GUI objects over a previous fully supervised baseline on real-world EHR screen images.
Open-World Instance Segmentation: Exploiting Pseudo Ground Truth From Learned Pairwise Affinity
Apr 12, 2022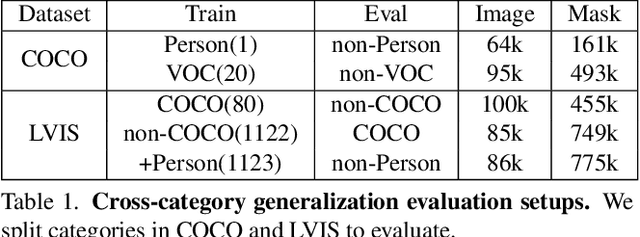
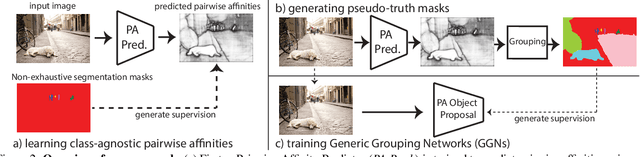


Open-world instance segmentation is the task of grouping pixels into object instances without any pre-determined taxonomy. This is challenging, as state-of-the-art methods rely on explicit class semantics obtained from large labeled datasets, and out-of-domain evaluation performance drops significantly. Here we propose a novel approach for mask proposals, Generic Grouping Networks (GGNs), constructed without semantic supervision. Our approach combines a local measure of pixel affinity with instance-level mask supervision, producing a training regimen designed to make the model as generic as the data diversity allows. We introduce a method for predicting Pairwise Affinities (PA), a learned local relationship between pairs of pixels. PA generalizes very well to unseen categories. From PA we construct a large set of pseudo-ground-truth instance masks; combined with human-annotated instance masks we train GGNs and significantly outperform the SOTA on open-world instance segmentation on various benchmarks including COCO, LVIS, ADE20K, and UVO. Code is available on project website: https://sites.google.com/view/generic-grouping/.
Pediatric Otoscopy Video Screening with Shift Contrastive Anomaly Detection
Oct 25, 2021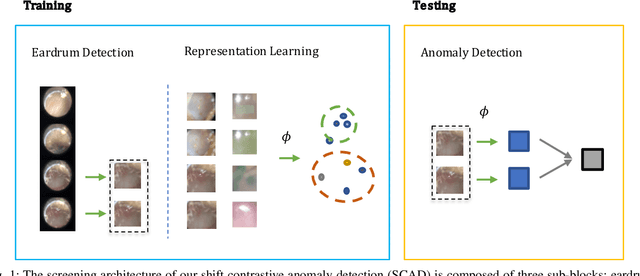
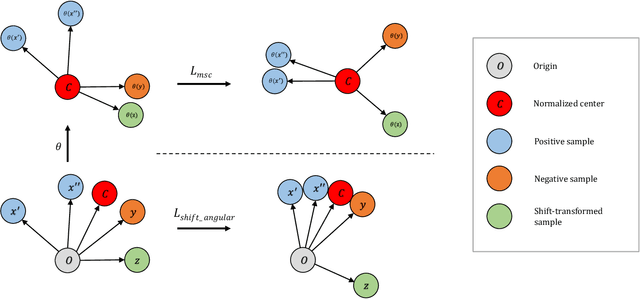

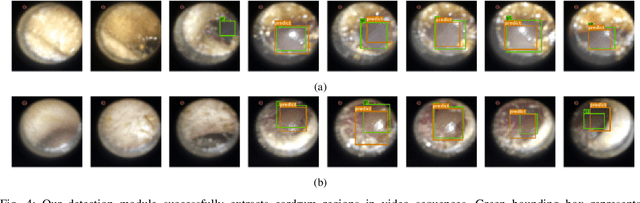
Ear related concerns and symptoms represents the leading indication for seeking pediatric healthcare attention. Despite the high incidence of such encounters, the diagnostic process of commonly encountered disease of the middle and external presents significant challenge. Much of this challenge stems from the lack of cost effective diagnostic testing, which necessitating the presence or absence of ear pathology to be determined clinically. Research has however demonstrated considerable variation among clinicians in their ability to accurately diagnose and consequently manage ear pathology. With recent advances in computer vision and machine learning, there is an increasing interest in helping clinicians to accurately diagnose middle and external ear pathology with computer-aided systems. It has been shown that AI has the capacity to analyse a single clinical image captured during examination of the ear canal and eardrum from which it can determine the likelihood of a pathognomonic pattern for a specific diagnosis being present. The capture of such an image can however be challenging especially to inexperienced clinicians. To help mitigate this technical challenge we have developed and tested a method using video sequences. We present a two stage method that first, identifies valid frames by detecting and extracting ear drum patches from the video sequence, and second, performs the proposed shift contrastive anomaly detection to flag the otoscopy video sequences as normal or abnormal. Our method achieves an AUROC of 88.0% on the patient-level and also outperforms the average of a group of 25 clinicians in a comparative study, which is the largest of such published to date. We conclude that the presented method achieves a promising first step towards automated analysis of otoscopy video.
Learn Proportional Derivative Controllable Latent Space from Pixels
Oct 15, 2021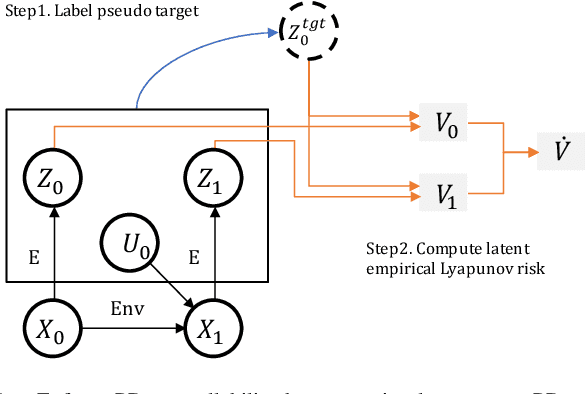
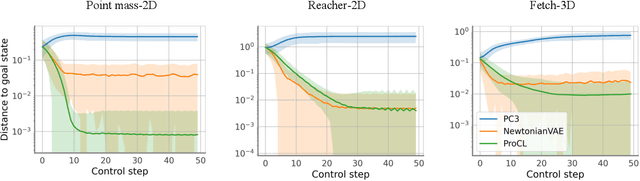
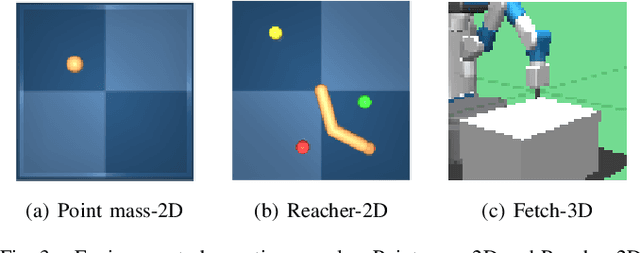
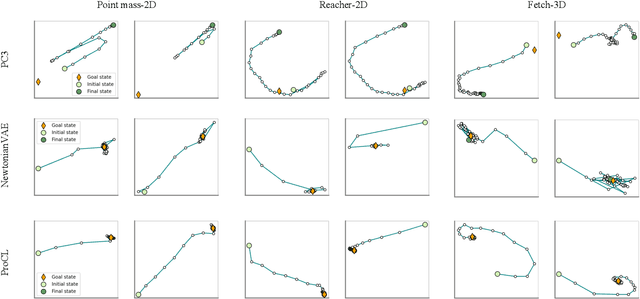
Recent advances in latent space dynamics model from pixels show promising progress in vision-based model predictive control (MPC). However, executing MPC in real time can be challenging due to its intensive computational cost in each timestep. We propose to introduce additional learning objectives to enforce that the learned latent space is proportional derivative controllable. In execution time, the simple PD-controller can be applied directly to the latent space encoded from pixels, to produce simple and effective control to systems with visual observations. We show that our method outperforms baseline methods to produce robust goal reaching and trajectory tracking in various environments.
Unidentified Video Objects: A Benchmark for Dense, Open-World Segmentation
Apr 10, 2021
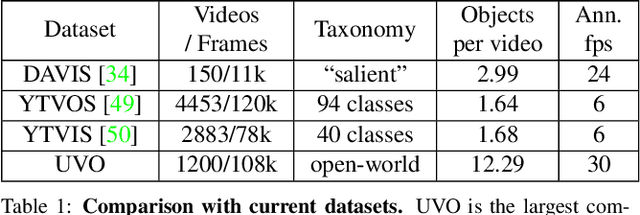
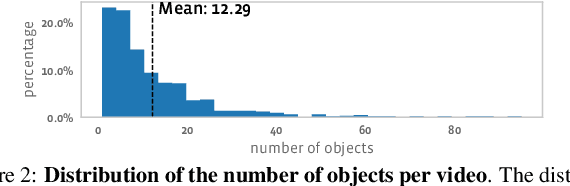

Current state-of-the-art object detection and segmentation methods work well under the closed-world assumption. This closed-world setting assumes that the list of object categories is available during training and deployment. However, many real-world applications require detecting or segmenting novel objects, i.e., object categories never seen during training. In this paper, we present, UVO (Unidentified Video Objects), a new benchmark for open-world class-agnostic object segmentation in videos. Besides shifting the problem focus to the open-world setup, UVO is significantly larger, providing approximately 8 times more videos compared with DAVIS, and 7 times more mask (instance) annotations per video compared with YouTube-VOS and YouTube-VIS. UVO is also more challenging as it includes many videos with crowded scenes and complex background motions. We demonstrated that UVO can be used for other applications, such as object tracking and super-voxel segmentation, besides open-world object segmentation. We believe that UVo is a versatile testbed for researchers to develop novel approaches for open-world class-agnostic object segmentation, and inspires new research directions towards a more comprehensive video understanding beyond classification and detection.
Generic Event Boundary Detection: A Benchmark for Event Segmentation
Jan 26, 2021
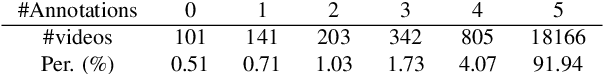
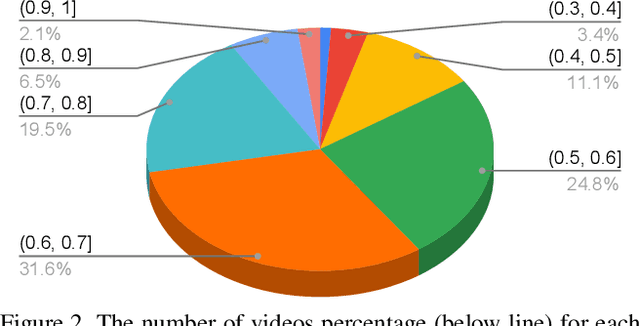
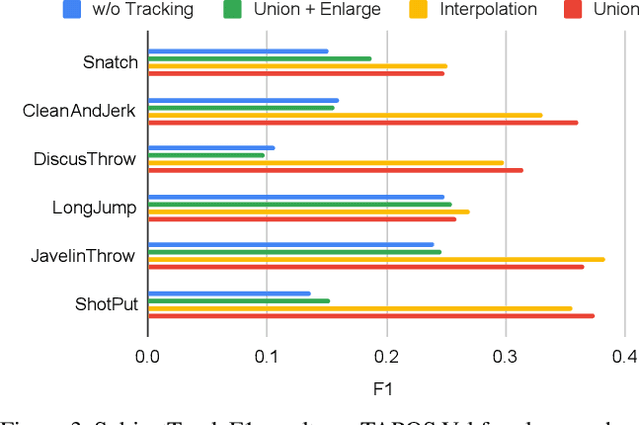
This paper presents a novel task together with a new benchmark for detecting generic, taxonomy-free event boundaries that segment a whole video into chunks. Conventional work in temporal video segmentation and action detection focuses on localizing pre-defined action categories and thus does not scale to generic videos. Cognitive Science has known since last century that humans consistently segment videos into meaningful temporal chunks. This segmentation happens naturally, with no pre-defined event categories and without being explicitly asked to do so. Here, we repeat these cognitive experiments on mainstream CV datasets; with our novel annotation guideline which addresses the complexities of taxonomy-free event boundary annotation, we introduce the task of Generic Event Boundary Detection (GEBD) and the new benchmark Kinetics-GEBD. Through experiment and human study we demonstrate the value of the annotations. We view this as an important stepping stone towards understanding the video as a whole, and believe it has been previously neglected due to a lack of proper task definition and annotations. Further, inspired by the cognitive finding that humans mark boundaries at points where they are unable to predict the future accurately, we explore un-supervised approaches based on temporal predictability. We identify and extensively explore important design factors for GEBD models on the TAPOS dataset and our Kinetics-GEBD while achieving competitive performance and suggesting future work. We will release our annotations and code at CVPR'21 LOVEU Challenge: https://sites.google.com/view/loveucvpr21