 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Action Priors for Cross-embodiment Robot Manipulation
Jun 24, 2026Most Vision-Language-Action (VLA) models build on a Vision-Language Model (VLM) backbone by attaching an action module and optimizing the full policy jointly. This design inherits strong visual and linguistic priors from the VLM, but leaves the action module to learn physical motion almost from scratch. As a result, the policy lacks an explicit motion prior, forcing early optimization to simultaneously discover temporal action dynamics and cross-modal alignment, a challenge further amplified in cross-embodiment settings. In this work, we propose to pretrain the action module with motion priors before cross-modal VLA alignment. Specifically, we introduce a two-stage training framework that equips the action module with cross-embodiment temporal motion structure before VLA training begins. In Stage~1, a lightweight flow-matching-based encoder-decoder action module efficiently learns temporal motion structure solely from unconditioned action trajectories, without processing visual or language tokens. In Stage~2, this learned prior is transferred to VLA training through decoder reuse and early-stage latent distillation, aligning visual-language features with the action embedding space while still allowing end-to-end policy refinement. In addition, the trained encoder serves as a compact history compressor, summarizing state-action histories into a single temporal context token for history-aware modeling at negligible cost. Extensive experiments across 13 diverse cross-embodiment tasks on both simulated and real-world platforms validate the effectiveness of our approach. Compared with VLA training without action priors, our model achieves faster convergence, higher success rates, and substantially stronger performance on data-scarce real-world tasks. Moreover, scaling up the action data in Stage~1 yields a more generalizable action prior that directly improves downstream VLA performance.
TempoVLA: Learning Speed-Controllable Vision-Language-Action Policies
Jun 04, 2026Robot manipulation alternates between low-risk transit phases that call for fast execution and high-risk contact stages that demand slow, precise motion. Yet existing Vision-Language-Action models (VLAs) only inherit a single fixed speed from training demonstrations. Prior efforts to accelerate VLAs through model compression, KV-cache reuse, or reinforcement learning only shift the policy from one fixed speed to another, and leave deceleration almost unexplored. We observe that the magnitude of each predicted action already governs how fast the robot moves, opening a direct route to controllable execution speed. We turn this observation into TempoVLA, a single VLA whose execution speed is controlled by an explicit condition. TempoVLA combines two coupled components. (1) A data-side Variable-Speed Trajectory Augmentation (VSTA) that re-times demonstration to any target speed by merging or splitting actions while preserving its motion semantics. (2) A model-side conditioning mechanism that feeds the speed to the policy. Statistics show that VSTA reaches the requested speed with negligible motion error. Experiments in simulation and on real-world tasks demonstrate that TempoVLA achieves flexible speed control in both directions, while VSTA additionally boosts the default $1\times$ performance via better data utilization. Furthermore, by cooperating with a large multimodal model, TempoVLA realizes dynamic speed control, accelerating through low-risk phases and decelerating for high-risk ones.
When Vision Overrides Language: Evaluating and Mitigating Counterfactual Failures in VLAs
Feb 19, 2026Vision-Language-Action models (VLAs) promise to ground language instructions in robot control, yet in practice often fail to faithfully follow language. When presented with instructions that lack strong scene-specific supervision, VLAs suffer from counterfactual failures: they act based on vision shortcuts induced by dataset biases, repeatedly executing well-learned behaviors and selecting objects frequently seen during training regardless of language intent. To systematically study it, we introduce LIBERO-CF, the first counterfactual benchmark for VLAs that evaluates language following capability by assigning alternative instructions under visually plausible LIBERO layouts. Our evaluation reveals that counterfactual failures are prevalent yet underexplored across state-of-the-art VLAs. We propose Counterfactual Action Guidance (CAG), a simple yet effective dual-branch inference scheme that explicitly regularizes language conditioning in VLAs. CAG combines a standard VLA policy with a language-unconditioned Vision-Action (VA) module, enabling counterfactual comparison during action selection. This design reduces reliance on visual shortcuts, improves robustness on under-observed tasks, and requires neither additional demonstrations nor modifications to existing architectures or pretrained models. Extensive experiments demonstrate its plug-and-play integration across diverse VLAs and consistent improvements. For example, on LIBERO-CF, CAG improves $π_{0.5}$ by 9.7% in language following accuracy and 3.6% in task success on under-observed tasks using a training-free strategy, with further gains of 15.5% and 8.5%, respectively, when paired with a VA model. In real-world evaluations, CAG reduces counterfactual failures of 9.4% and improves task success by 17.2% on average.
Say Cheese! Detail-Preserving Portrait Collection Generation via Natural Language Edits
Jan 28, 2026As social media platforms proliferate, users increasingly demand intuitive ways to create diverse, high-quality portrait collections. In this work, we introduce Portrait Collection Generation (PCG), a novel task that generates coherent portrait collections by editing a reference portrait image through natural language instructions. This task poses two unique challenges to existing methods: (1) complex multi-attribute modifications such as pose, spatial layout, and camera viewpoint; and (2) high-fidelity detail preservation including identity, clothing, and accessories. To address these challenges, we propose CHEESE, the first large-scale PCG dataset containing 24K portrait collections and 573K samples with high-quality modification text annotations, constructed through an Large Vison-Language Model-based pipeline with inversion-based verification. We further propose SCheese, a framework that combines text-guided generation with hierarchical identity and detail preservation. SCheese employs adaptive feature fusion mechanism to maintain identity consistency, and ConsistencyNet to inject fine-grained features for detail consistency. Comprehensive experiments validate the effectiveness of CHEESE in advancing PCG, with SCheese achieving state-of-the-art performance.
Incentivizing Multimodal Reasoning in Large Models for Direct Robot Manipulation
May 19, 2025Recent Large Multimodal Models have demonstrated remarkable reasoning capabilities, especially in solving complex mathematical problems and realizing accurate spatial perception. Our key insight is that these emerging abilities can naturally extend to robotic manipulation by enabling LMMs to directly infer the next goal in language via reasoning, rather than relying on a separate action head. However, this paradigm meets two main challenges: i) How to make LMMs understand the spatial action space, and ii) How to fully exploit the reasoning capacity of LMMs in solving these tasks. To tackle the former challenge, we propose a novel task formulation, which inputs the current states of object parts and the gripper, and reformulates rotation by a new axis representation instead of traditional Euler angles. This representation is more compatible with spatial reasoning and easier to interpret within a unified language space. For the latter challenge, we design a pipeline to utilize cutting-edge LMMs to generate a small but high-quality reasoning dataset of multi-round dialogues that successfully solve manipulation tasks for supervised fine-tuning. Then, we perform reinforcement learning by trial-and-error interactions in simulation to further enhance the model's reasoning abilities for robotic manipulation. Our resulting reasoning model built upon a 7B backbone, named ReasonManip, demonstrates three notable advantages driven by its system-2 level reasoning capabilities: i) exceptional generalizability to out-of-distribution environments, objects, and tasks; ii) inherent sim-to-real transfer ability enabled by the unified language representation shared across domains; iii) transparent interpretability connecting high-level reasoning and low-level control. Extensive experiments demonstrate the effectiveness of the proposed paradigm and its potential to advance LMM-driven robotic manipulation.
CoTMR: Chain-of-Thought Multi-Scale Reasoning for Training-Free Zero-Shot Composed Image Retrieval
Feb 28, 2025Zero-Shot Composed Image Retrieval (ZS-CIR) aims to retrieve target images by integrating information from a composed query (reference image and modification text) without training samples. Existing methods primarily combine caption models and large language models (LLMs) to generate target captions based on composed queries but face various issues such as incompatibility, visual information loss, and insufficient reasoning. In this work, we propose CoTMR, a training-free framework crafted for ZS-CIR with novel Chain-of-thought (CoT) and Multi-scale Reasoning. Instead of relying on caption models for modality transformation, CoTMR employs the Large Vision-Language Model (LVLM) to achieve unified understanding and reasoning for composed queries. To enhance the reasoning reliability, we devise CIRCoT, which guides the LVLM through a step-by-step inference process using predefined subtasks. Considering that existing approaches focus solely on global-level reasoning, our CoTMR incorporates multi-scale reasoning to achieve more comprehensive inference via fine-grained predictions about the presence or absence of key elements at the object scale. Further, we design a Multi-Grained Scoring (MGS) mechanism, which integrates CLIP similarity scores of the above reasoning outputs with candidate images to realize precise retrieval. Extensive experiments demonstrate that our CoTMR not only drastically outperforms previous methods across four prominent benchmarks but also offers appealing interpretability.
Leveraging Large Vision-Language Model as User Intent-aware Encoder for Composed Image Retrieval
Dec 15, 2024Composed Image Retrieval (CIR) aims to retrieve target images from candidate set using a hybrid-modality query consisting of a reference image and a relative caption that describes the user intent. Recent studies attempt to utilize Vision-Language Pre-training Models (VLPMs) with various fusion strategies for addressing the task.However, these methods typically fail to simultaneously meet two key requirements of CIR: comprehensively extracting visual information and faithfully following the user intent. In this work, we propose CIR-LVLM, a novel framework that leverages the large vision-language model (LVLM) as the powerful user intent-aware encoder to better meet these requirements. Our motivation is to explore the advanced reasoning and instruction-following capabilities of LVLM for accurately understanding and responding the user intent. Furthermore, we design a novel hybrid intent instruction module to provide explicit intent guidance at two levels: (1) The task prompt clarifies the task requirement and assists the model in discerning user intent at the task level. (2) The instance-specific soft prompt, which is adaptively selected from the learnable prompt pool, enables the model to better comprehend the user intent at the instance level compared to a universal prompt for all instances. CIR-LVLM achieves state-of-the-art performance across three prominent benchmarks with acceptable inference efficiency. We believe this study provides fundamental insights into CIR-related fields.
CoTBal: Comprehensive Task Balancing for Multi-Task Visual Instruction Tuning
Mar 07, 2024



Visual instruction tuning is a key training stage of large multimodal models (LMMs). Nevertheless, the common practice of indiscriminately mixing instruction-following data from various tasks may result in suboptimal overall performance due to different instruction formats and knowledge domains across tasks. To mitigate this issue, we propose a novel Comprehensive Task Balancing (CoTBal) algorithm for multi-task visual instruction tuning of LMMs. To our knowledge, this is the first work that explores multi-task optimization in visual instruction tuning. Specifically, we consider two key dimensions for task balancing: (1) Inter-Task Contribution, the phenomenon where learning one task potentially enhances the performance in other tasks, attributable to the overlapping knowledge domains, and (2) Intra-Task Difficulty, which refers to the learning difficulty within a single task. By quantifying these two dimensions with performance-based metrics, task balancing is thus enabled by assigning more weights to tasks that offer substantial contributions to others, receive minimal contributions from others, and also have great intra-task difficulties. Experiments show that our CoTBal leads to superior overall performance in multi-task visual instruction tuning.
Light Field Raindrop Removal via 4D Re-sampling
May 26, 2022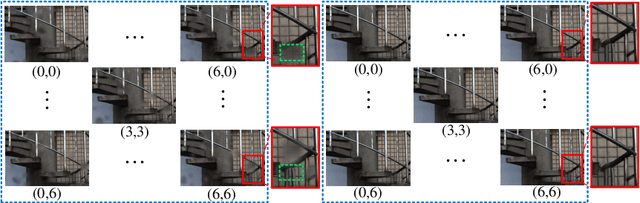


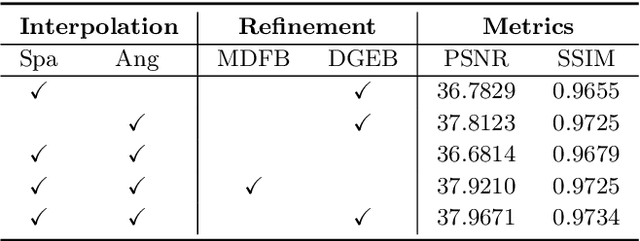
The Light Field Raindrop Removal (LFRR) aims to restore the background areas obscured by raindrops in the Light Field (LF). Compared with single image, the LF provides more abundant information by regularly and densely sampling the scene. Since raindrops have larger disparities than the background in the LF, the majority of texture details occluded by raindrops are visible in other views. In this paper, we propose a novel LFRR network by directly utilizing the complementary pixel information of raindrop-free areas in the input raindrop LF, which consists of the re-sampling module and the refinement module. Specifically, the re-sampling module generates a new LF which is less polluted by raindrops through re-sampling position predictions and the proposed 4D interpolation. The refinement module improves the restoration of the completely occluded background areas and corrects the pixel error caused by 4D interpolation. Furthermore, we carefully build the first real scene LFRR dataset for model training and validation. Experiments demonstrate that the proposed method can effectively remove raindrops and achieves state-of-the-art performance in both background restoration and view consistency maintenance.