 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple and Effective Method to Improve Zero-Shot Cross-Lingual Transfer Learning
Oct 18, 2022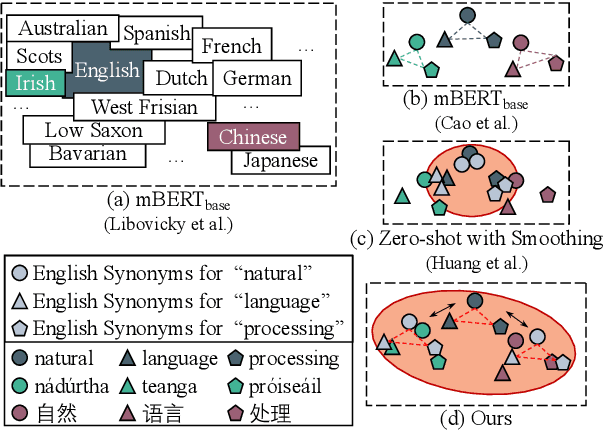
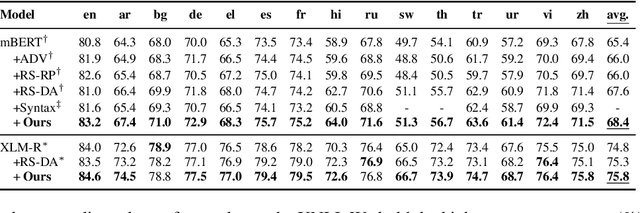
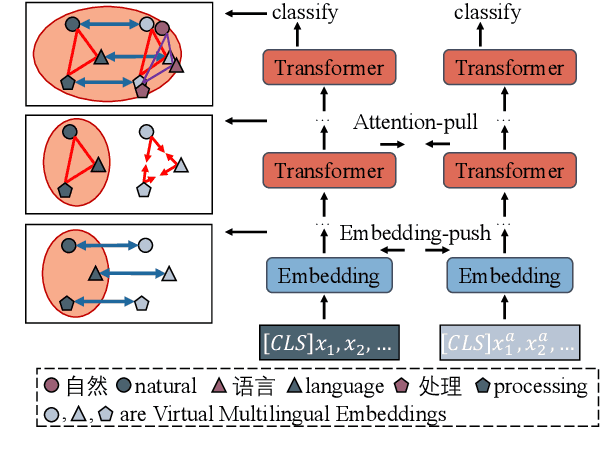
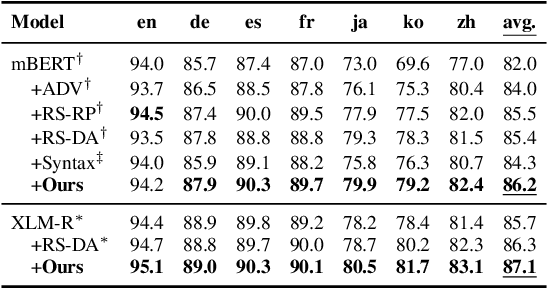
Existing zero-shot cross-lingual transfer methods rely on parallel corpora or bilingual dictionaries, which are expensive and impractical for low-resource languages. To disengage from these dependencies, researchers have explored training multilingual models on English-only resources and transferring them to low-resource languages. However, its effect is limited by the gap between embedding clusters of different languages. To address this issue, we propose Embedding-Push, Attention-Pull, and Robust targets to transfer English embeddings to virtual multilingual embeddings without semantic loss, thereby improving cross-lingual transferability. Experimental results on mBERT and XLM-R demonstrate that our method significantly outperforms previous works on the zero-shot cross-lingual text classification task and can obtain a better multilingual alignment.
SAMP: A Toolkit for Model Inference with Self-Adaptive Mixed-Precision
Sep 19, 2022
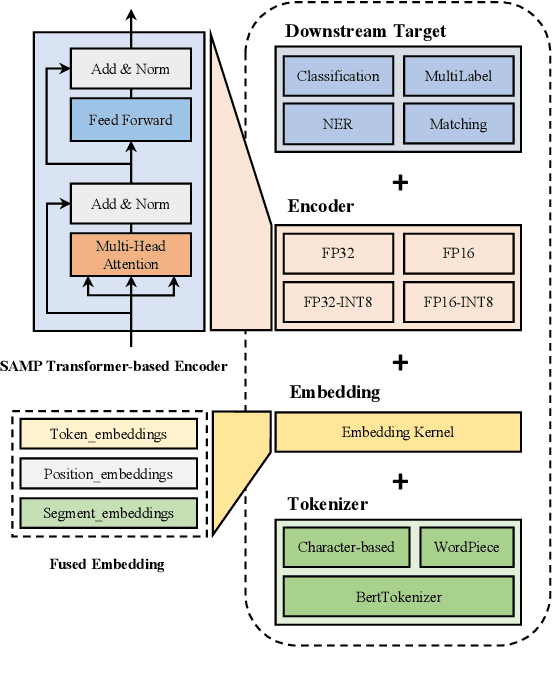
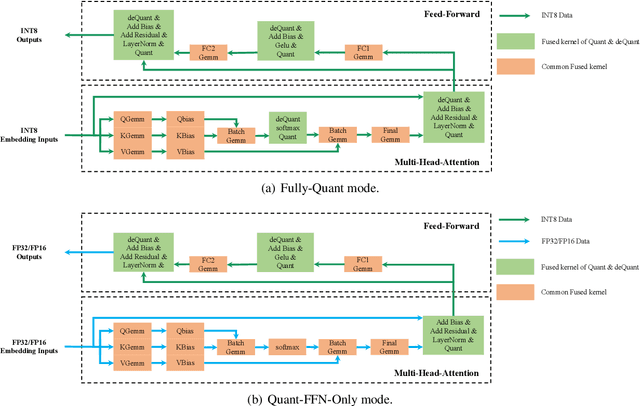
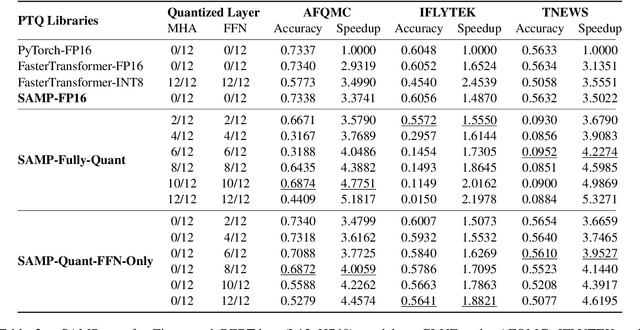
The latest industrial inference engines, such as FasterTransformer1 and TurboTransformers, have verified that half-precision floating point (FP16) and 8-bit integer (INT8) quantization can greatly improve model inference speed. However, the existing FP16 or INT8 quantization methods are too complicated, and improper usage will lead to performance damage greatly. In this paper, we develop a toolkit for users to easily quantize their models for inference, in which a Self-Adaptive Mixed-Precision (SAMP) is proposed to automatically control quantization rate by a mixed-precision architecture to balance efficiency and performance. Experimental results show that our SAMP toolkit has a higher speedup than PyTorch and FasterTransformer while ensuring the required performance. In addition, SAMP is based on a modular design, decoupling the tokenizer, embedding, encoder and target layers, which allows users to handle various downstream tasks and can be seamlessly integrated into PyTorch.
Multi-stage Distillation Framework for Cross-Lingual Semantic Similarity Matching
Sep 13, 2022
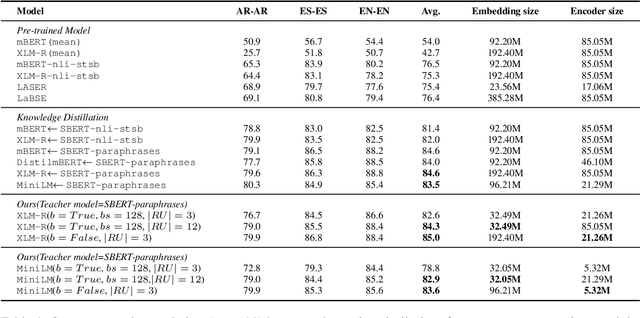
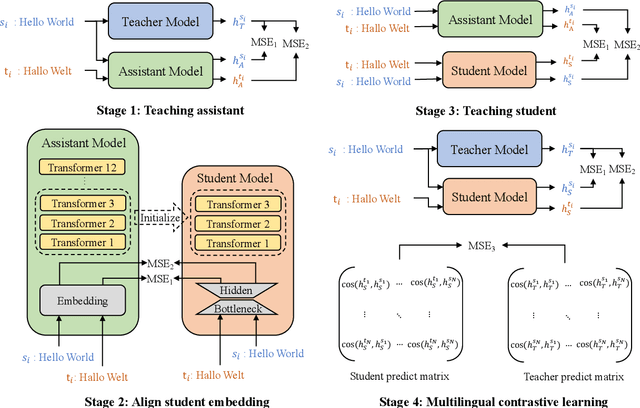
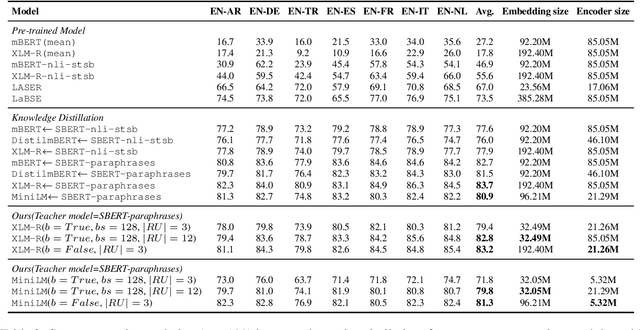
Previous studies have proved that cross-lingual knowledge distillation can significantly improve the performance of pre-trained models for cross-lingual similarity matching tasks. However, the student model needs to be large in this operation. Otherwise, its performance will drop sharply, thus making it impractical to be deployed to memory-limited devices. To address this issue, we delve into cross-lingual knowledge distillation and propose a multi-stage distillation framework for constructing a small-size but high-performance cross-lingual model. In our framework, contrastive learning, bottleneck, and parameter recurrent strategies are combined to prevent performance from being compromised during the compression process. The experimental results demonstrate that our method can compress the size of XLM-R and MiniLM by more than 50\%, while the performance is only reduced by about 1%.
CSL: A Large-scale Chinese Scientific Literature Dataset
Sep 12, 2022
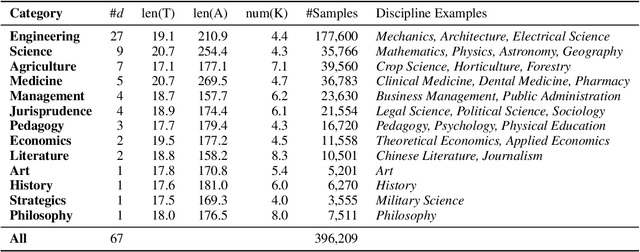
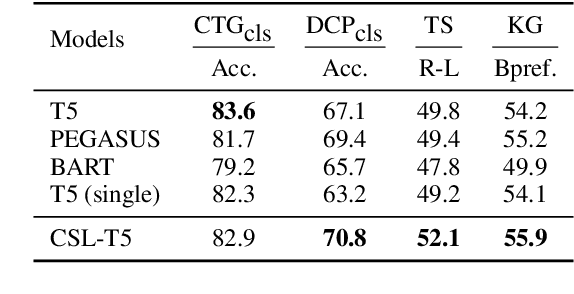
Scientific literature serves as a high-quality corpus, supporting a lot of Natural Language Processing (NLP) research. However, existing datasets are centered around the English language, which restricts the development of Chinese scientific NLP. In this work, we present CSL, a large-scale Chinese Scientific Literature dataset, which contains the titles, abstracts, keywords and academic fields of 396k papers. To our knowledge, CSL is the first scientific document dataset in Chinese. The CSL can serve as a Chinese corpus. Also, this semi-structured data is a natural annotation that can constitute many supervised NLP tasks. Based on CSL, we present a benchmark to evaluate the performance of models across scientific domain tasks, i.e., summarization, keyword generation and text classification. We analyze the behavior of existing text-to-text models on the evaluation tasks and reveal the challenges for Chinese scientific NLP tasks, which provides a valuable reference for future research. Data and code are available at https://github.com/ydli-ai/CSL
Merak: An Efficient Distributed DNN Training Framework with Automated 3D Parallelism for Giant Foundation Models
Jun 21, 2022
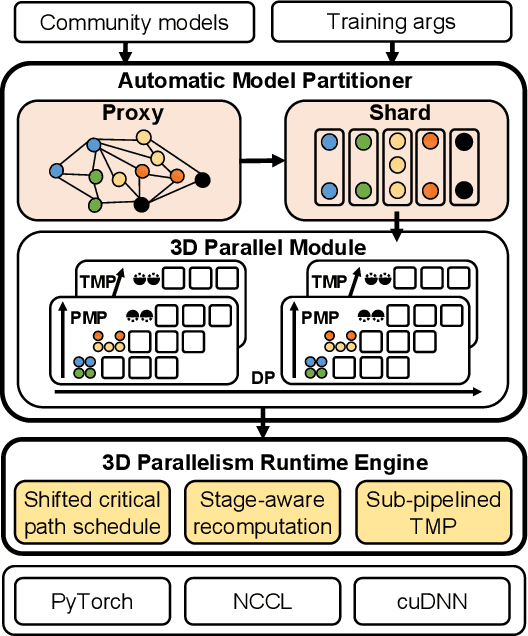

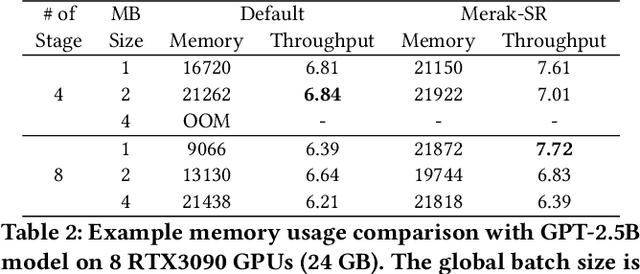
Foundation models are becoming the dominant deep learning technologies. Pretraining a foundation model is always time-consumed due to the large scale of both the model parameter and training dataset. Besides being computing-intensive, the training process is extremely memory-intensive and communication-intensive. These features make it necessary to apply 3D parallelism, which integrates data parallelism, pipeline model parallelism and tensor model parallelism, to achieve high training efficiency. To achieve this goal, some custom software frameworks such as Megatron-LM and DeepSpeed are developed. However, current 3D parallelism frameworks still meet two issues: i) they are not transparent to model developers, which need to manually modify the model to parallelize training. ii) their utilization of computation, GPU memory and network bandwidth are not sufficient. We propose Merak, an automated 3D parallelism deep learning training framework with high resource utilization. Merak automatically deploys with an automatic model partitioner, which uses a graph sharding algorithm on a proxy representation of the model. Merak also presents the non-intrusive API for scaling out foundation model training with minimal code modification. In addition, we design a high-performance 3D parallel runtime engine in Merak. It uses several techniques to exploit available training resources, including shifted critical path pipeline schedule that brings a higher computation utilization, stage-aware recomputation that makes use of idle worker memory, and sub-pipelined tensor model parallelism that overlaps communication and computation. Experiments on 64 GPUs show Merak can speedup the training performance over the state-of-the-art 3D parallelism frameworks of models with 1.5, 2.5, 8.3, and 20 billion parameters by up to 1.42X, 1.39X, 1.43X, and 1.61X, respectively.
Semantic Matching from Different Perspectives
Feb 14, 2022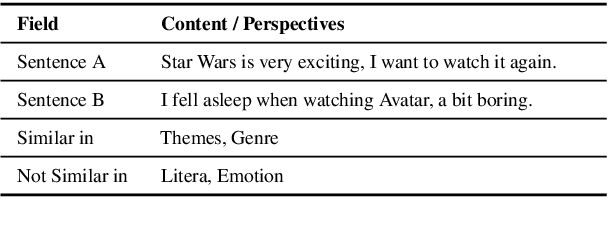
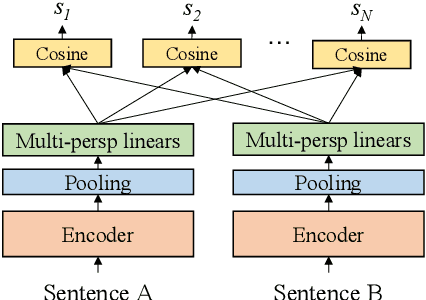
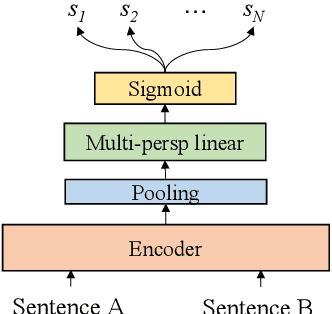

In this paper, we pay attention to the issue which is usually overlooked, i.e., \textit{similarity should be determined from different perspectives}. To explore this issue, we release a Multi-Perspective Text Similarity (MPTS) dataset, in which sentence similarities are labeled from twelve perspectives. Furthermore, we conduct a series of experimental analysis on this task by retrofitting some famous text matching models. Finally, we obtain several conclusions and baseline models, laying the foundation for the following investigation of this issue. The dataset and code are publicly available at Github\footnote{\url{https://github.com/autoliuweijie/MPTS}
SIGMA: A Structural Inconsistency Reducing Graph Matching Algorithm
Feb 06, 2022



Graph matching finds the correspondence of nodes across two correlated graphs and lies at the core of many applications. When graph side information is not available, the node correspondence is estimated on the sole basis of network topologies. In this paper, we propose a novel criterion to measure the graph matching accuracy, structural inconsistency (SI), which is defined based on the network topological structure. Specifically, SI incorporates the heat diffusion wavelet to accommodate the multi-hop structure of the graphs. Based on SI, we propose a Structural Inconsistency reducing Graph Matching Algorithm (SIGMA), which improves the alignment scores of node pairs that have low SI values in each iteration. Under suitable assumptions, SIGMA can reduce SI values of true counterparts. Furthermore, we demonstrate that SIGMA can be derived by using a mirror descent method to solve the Gromov-Wasserstein distance with a novel K-hop-structure-based matching costs. Extensive experiments show that our method outperforms state-of-the-art methods.
Approximating Optimal Transport via Low-rank and Sparse Factorization
Nov 12, 2021Optimal transport (OT) naturally arises in a wide range of machine learning applications but may often become the computational bottleneck. Recently, one line of works propose to solve OT approximately by searching the \emph{transport plan} in a low-rank subspace. However, the optimal transport plan is often not low-rank, which tends to yield large approximation errors. For example, when Monge's \emph{transport map} exists, the transport plan is full rank. This paper concerns the computation of the OT distance with adequate accuracy and efficiency. A novel approximation for OT is proposed, in which the transport plan can be decomposed into the sum of a low-rank matrix and a sparse one. We theoretically analyze the approximation error. An augmented Lagrangian method is then designed to efficiently calculate the transport plan.
Dynamic Relevance Learning for Few-Shot Object Detection
Aug 04, 2021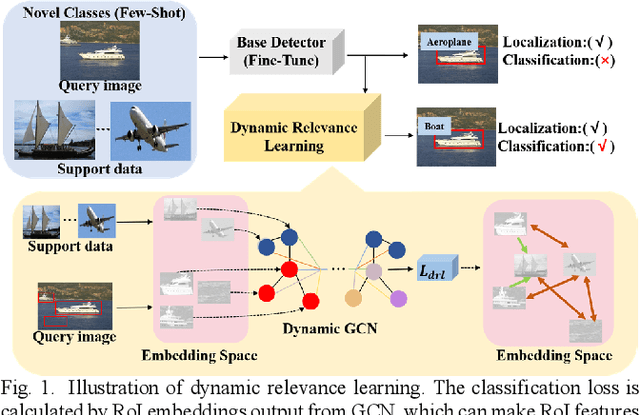
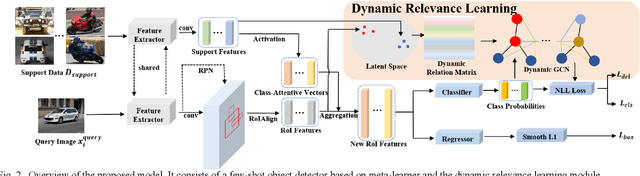
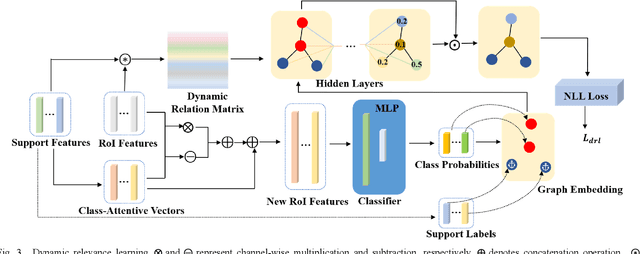
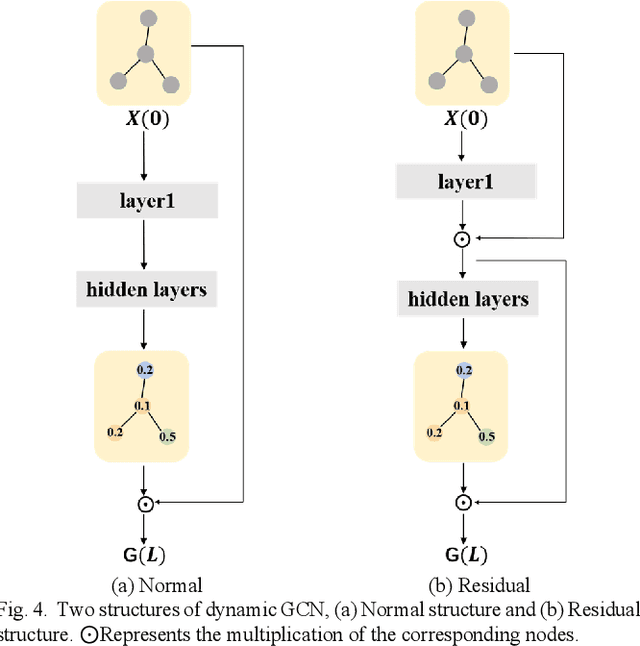
Expensive bounding-box annotations have limited the development of object detection task. Thus, it is necessary to focus on more challenging task of few-shot object detection. It requires the detector to recognize objects of novel classes with only a few training samples. Nowadays, many existing popular methods based on meta-learning have achieved promising performance, such as Meta R-CNN series. However, only a single category of support data is used as the attention to guide the detecting of query images each time. Their relevance to each other remains unexploited. Moreover, a lot of recent works treat the support data and query images as independent branch without considering the relationship between them. To address this issue, we propose a dynamic relevance learning model, which utilizes the relationship between all support images and Region of Interest (RoI) on the query images to construct a dynamic graph convolutional network (GCN). By adjusting the prediction distribution of the base detector using the output of this GCN, the proposed model can guide the detector to improve the class representation implicitly. Comprehensive experiments have been conducted on Pascal VOC and MS-COCO dataset. The proposed model achieves the best overall performance, which shows its effectiveness of learning more generalized features. Our code is available at https://github.com/liuweijie19980216/DRL-for-FSOD.
Whitening Sentence Representations for Better Semantics and Faster Retrieval
Mar 29, 2021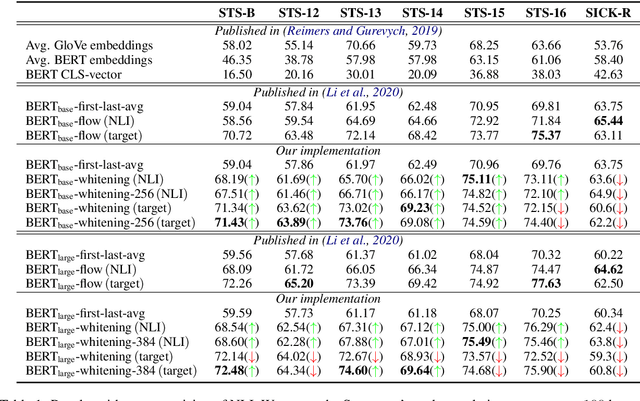
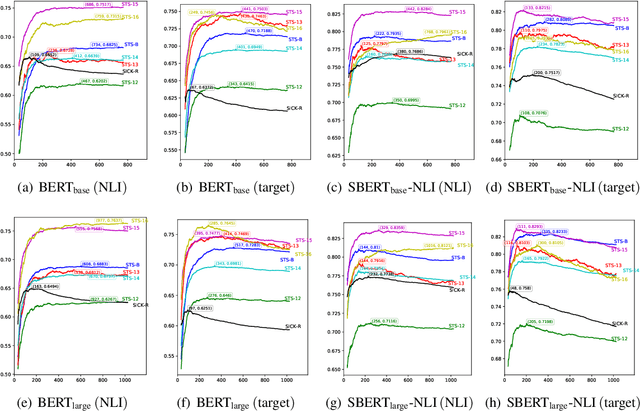
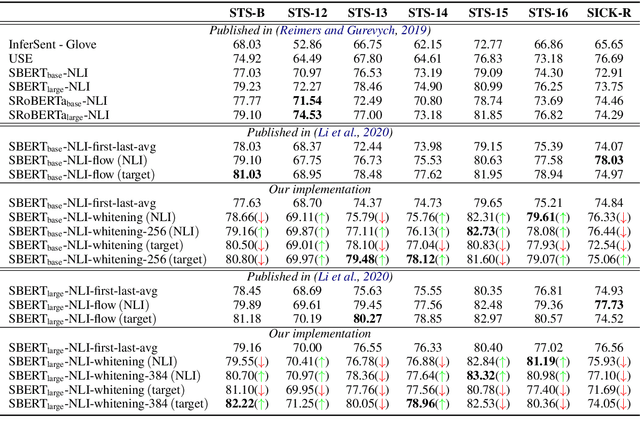
Pre-training models such as BERT have achieved great success in many natural language processing tasks. However, how to obtain better sentence representation through these pre-training models is still worthy to exploit. Previous work has shown that the anisotropy problem is an critical bottleneck for BERT-based sentence representation which hinders the model to fully utilize the underlying semantic features. Therefore, some attempts of boosting the isotropy of sentence distribution, such as flow-based model, have been applied to sentence representations and achieved some improvement. In this paper, we find that the whitening operation in traditional machine learning can similarly enhance the isotropy of sentence representations and achieve competitive results. Furthermore, the whitening technique is also capable of reducing the dimensionality of the sentence representation. Our experimental results show that it can not only achieve promising performance but also significantly reduce the storage cost and accelerate the model retrieval speed.