 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Sequence Tagging based Framework for Few-Shot Relation Extraction
Aug 17, 2022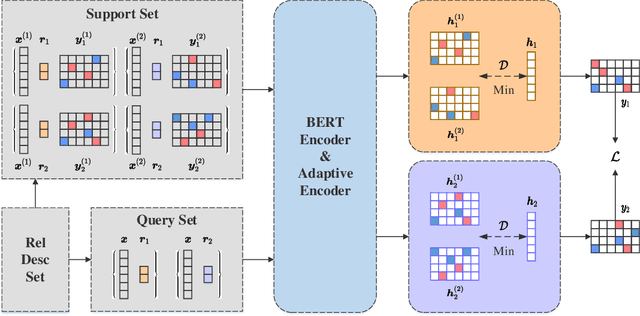
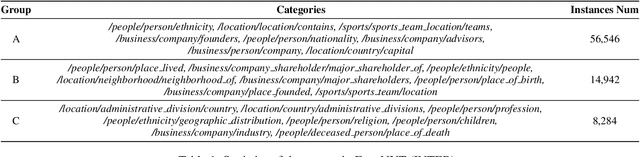
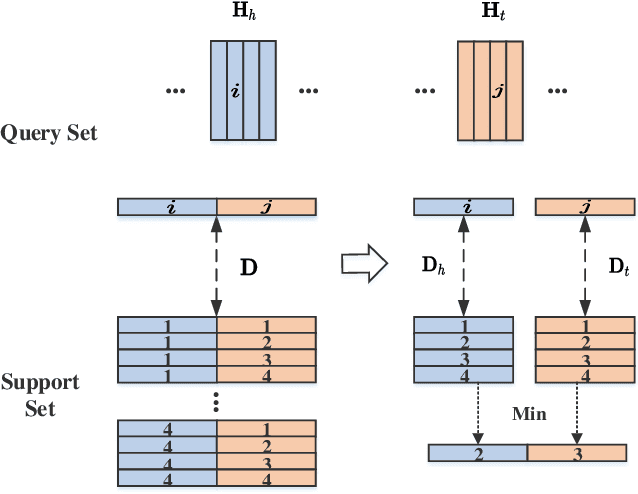
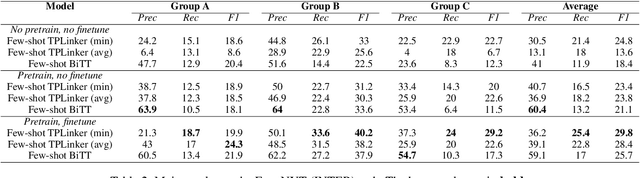
Relation Extraction (RE) refers to extracting the relation triples in the input text. Existing neural work based systems for RE rely heavily on manually labeled training data, but there are still a lot of domains where sufficient labeled data does not exist. Inspired by the distance-based few-shot named entity recognition methods, we put forward the definition of the few-shot RE task based on the sequence tagging joint extraction approaches, and propose a few-shot RE framework for the task. Besides, we apply two actual sequence tagging models to our framework (called Few-shot TPLinker and Few-shot BiTT), and achieves solid results on two few-shot RE tasks constructed from a public dataset.
BiTT: Bidirectional Tree Tagging for Joint Extraction of Overlapping Entities and Relations
Sep 07, 2020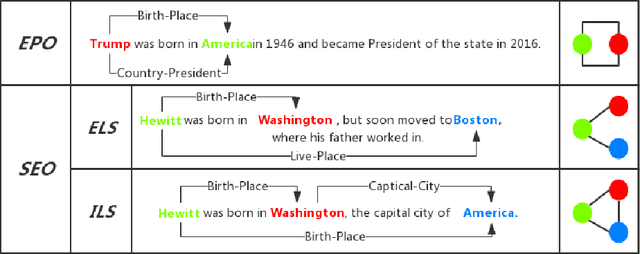
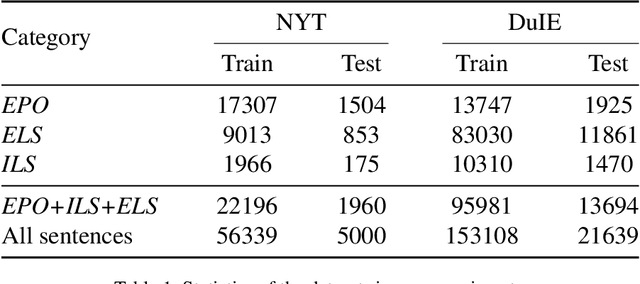
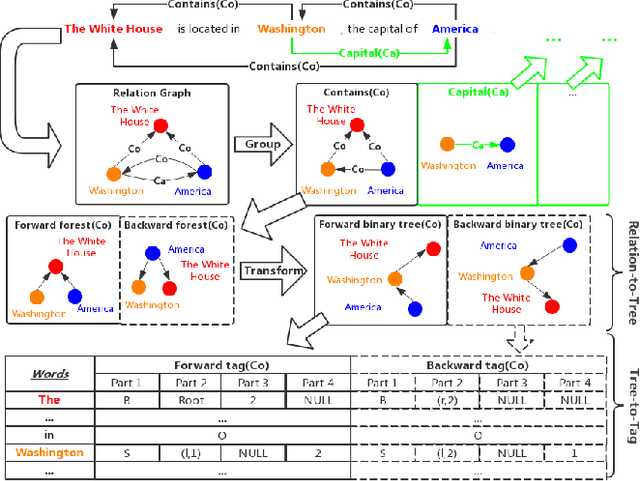
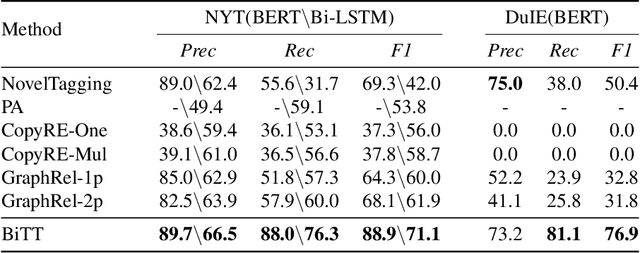
Joint extraction refers to extracting triples, composed of entities and relations, simultaneously from the text with a single model. However, most existing methods fail to extract all triples accurately and efficiently from sentences with overlapping issue, i.e., the same entity is included in multiple triples. In this paper, we propose a novel scheme called Bidirectional Tree Tagging (BiTT) to label overlapping triples in text. In BiTT, the triples with the same relation category in a sentence are especially represented as two binary trees, each of which is converted into a word-level tags sequence to label each word. Based on BiTT scheme, we develop an end-to-end extraction framework to predict the BiTT tags and further extract triples efficiently. We adopt the Bi-LSTM and the BERT as the encoder in our framework respectively, and obtain promising results in public English as well as Chinese datasets.