 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint Cloud Registration for Fusion between SPECT MPI and CTA Images
Apr 27, 2026Clinical fusion of Single Photon Emission Computed Tomography Myocardial Perfusion Imaging (SPECT MPI) and Computed Tomography Angiography (CTA) remains limited by cross-modality misregistration and reliance on manual landmarks, which can hinder accurate ischemia localization and lesion-level functional assessment. To address this issue, we propose a registration and fusion framework for SPECT MPI and CTA that integrates functional and structural information for comprehensive cardiac evaluation. The proposed pipeline performs U-Net-based segmentation on both modalities. On SPECT MPI, only the left ventricle (LV) is extracted, and anatomical landmarks are automatically derived from characteristic LV structures. On CTA, both ventricles are segmented, and their spatial relationship is used to automatically define landmarks at the interventricular septal junction. Scale-space consistency preprocessing and landmark-driven coarse registration are applied to mitigate initial misalignment. Based on this initialization, multiple fine registration methods are evaluated on LV epicardial surface point clouds, including ICP, SICP, CPD, CluReg, FFD, and BCPD-plus-plus. The resulting transformations are then propagated to voxel-level resampling for high-precision SPECT-CTA fusion. In a retrospective cohort of 60 patients, the proposed framework preserved sub-millimeter coronary detail from CTA while accurately overlaying quantitative SPECT perfusion. Among the evaluated methods, BCPD-plus-plus achieved the highest accuracy with a mean point cloud distance of 1.7 mm. By combining robust initialization, comparative fine registration, and voxel-level fusion, the proposed approach provides a practical solution for myocardial ischemia localization and functional evaluation of coronary lesions, while remaining independent of any specific fine registration algorithm.
UPMAD-Net: A Brain Tumor Segmentation Network with Uncertainty Guidance and Adaptive Multimodal Feature Fusion
May 06, 2025
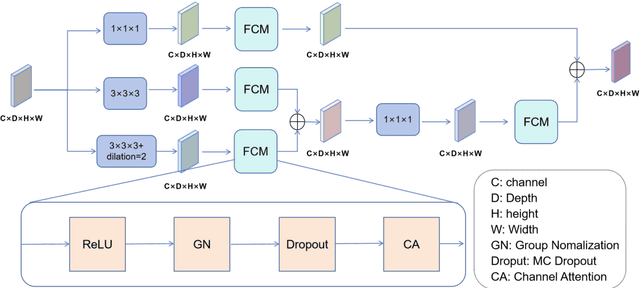


Background: Brain tumor segmentation has a significant impact on the diagnosis and treatment of brain tumors. Accurate brain tumor segmentation remains challenging due to their irregular shapes, vague boundaries, and high variability. Objective: We propose a brain tumor segmentation method that combines deep learning with prior knowledge derived from a region-growing algorithm. Methods: The proposed method utilizes a multi-scale feature fusion (MSFF) module and adaptive attention mechanisms (AAM) to extract multi-scale features and capture global contextual information. To enhance the model's robustness in low-confidence regions, the Monte Carlo Dropout (MC Dropout) strategy is employed for uncertainty estimation. Results: Extensive experiments demonstrate that the proposed method achieves superior performance on Brain Tumor Segmentation (BraTS) datasets, significantly outperforming various state-of-the-art methods. On the BraTS2021 dataset, the test Dice scores are 89.18% for Enhancing Tumor (ET) segmentation, 93.67% for Whole Tumor (WT) segmentation, and 91.23% for Tumor Core (TC) segmentation. On the BraTS2019 validation set, the validation Dice scores are 87.43%, 90.92%, and 90.40% for ET, WT, and TC segmentation, respectively. Ablation studies further confirmed the contribution of each module to segmentation accuracy, indicating that each component played a vital role in overall performance improvement. Conclusion: This study proposed a novel 3D brain tumor segmentation network based on the U-Net architecture. By incorporating the prior knowledge and employing the uncertainty estimation method, the robustness and performance were improved. The code for the proposed method is available at https://github.com/chenzhao2023/UPMAD_Net_BrainSeg.
Myocardial Region-guided Feature Aggregation Net for Automatic Coronary artery Segmentation and Stenosis Assessment using Coronary Computed Tomography Angiography
Apr 27, 2025



Coronary artery disease (CAD) remains a leading cause of mortality worldwide, requiring accurate segmentation and stenosis detection using Coronary Computed Tomography angiography (CCTA). Existing methods struggle with challenges such as low contrast, morphological variability and small vessel segmentation. To address these limitations, we propose the Myocardial Region-guided Feature Aggregation Net, a novel U-shaped dual-encoder architecture that integrates anatomical prior knowledge to enhance robustness in coronary artery segmentation. Our framework incorporates three key innovations: (1) a Myocardial Region-guided Module that directs attention to coronary regions via myocardial contour expansion and multi-scale feature fusion, (2) a Residual Feature Extraction Encoding Module that combines parallel spatial channel attention with residual blocks to enhance local-global feature discrimination, and (3) a Multi-scale Feature Fusion Module for adaptive aggregation of hierarchical vascular features. Additionally, Monte Carlo dropout f quantifies prediction uncertainty, supporting clinical interpretability. For stenosis detection, a morphology-based centerline extraction algorithm separates the vascular tree into anatomical branches, enabling cross-sectional area quantification and stenosis grading. The superiority of MGFA-Net was demonstrated by achieving an Dice score of 85.04%, an accuracy of 84.24%, an HD95 of 6.1294 mm, and an improvement of 5.46% in true positive rate for stenosis detection compared to3D U-Net. The integrated segmentation-to-stenosis pipeline provides automated, clinically interpretable CAD assessment, bridging deep learning with anatomical prior knowledge for precision medicine. Our code is publicly available at http://github.com/chenzhao2023/MGFA_CCTA
Learning to Write Stylized Chinese Characters by Reading a Handful of Examples
Jun 18, 2018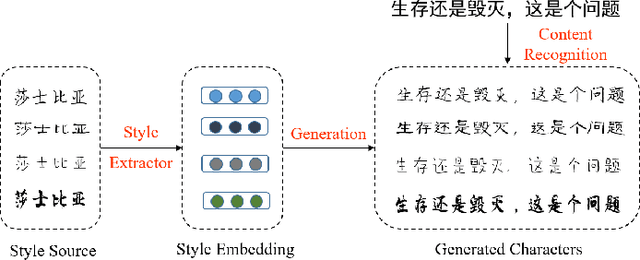
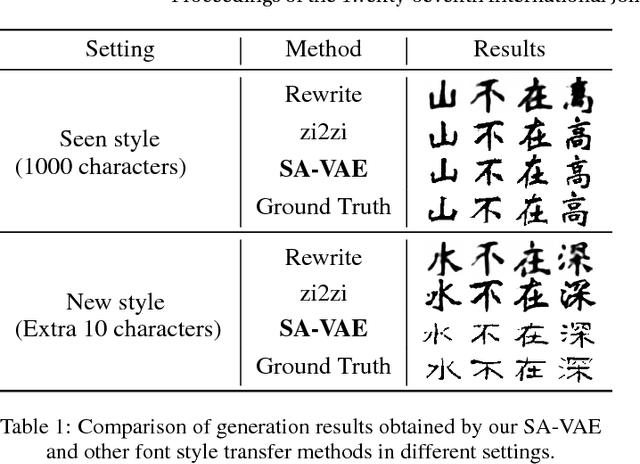
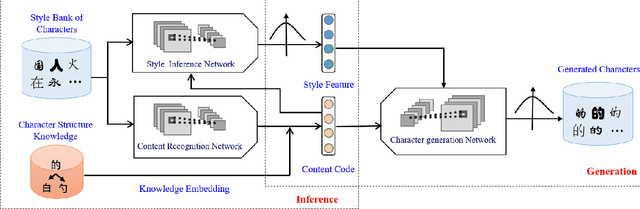

Automatically writing stylized Chinese characters is an attractive yet challenging task due to its wide applicabilities. In this paper, we propose a novel framework named Style-Aware Variational Auto-Encoder (SA-VAE) to flexibly generate Chinese characters. Specifically, we propose to capture the different characteristics of a Chinese character by disentangling the latent features into content-related and style-related components. Considering of the complex shapes and structures, we incorporate the structure information as prior knowledge into our framework to guide the generation. Our framework shows a powerful one-shot/low-shot generalization ability by inferring the style component given a character with unseen style. To the best of our knowledge, this is the first attempt to learn to write new-style Chinese characters by observing only one or a few examples. Extensive experiments demonstrate its effectiveness in generating different stylized Chinese characters by fusing the feature vectors corresponding to different contents and styles, which is of significant importance in real-world applications.