 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphGDP: Generative Diffusion Processes for Permutation Invariant Graph Generation
Dec 04, 2022



Graph generative models have broad applications in biology, chemistry and social science. However, modelling and understanding the generative process of graphs is challenging due to the discrete and high-dimensional nature of graphs, as well as permutation invariance to node orderings in underlying graph distributions. Current leading autoregressive models fail to capture the permutation invariance nature of graphs for the reliance on generation ordering and have high time complexity. Here, we propose a continuous-time generative diffusion process for permutation invariant graph generation to mitigate these issues. Specifically, we first construct a forward diffusion process defined by a stochastic differential equation (SDE), which smoothly converts graphs within the complex distribution to random graphs that follow a known edge probability. Solving the corresponding reverse-time SDE, graphs can be generated from newly sampled random graphs. To facilitate the reverse-time SDE, we newly design a position-enhanced graph score network, capturing the evolving structure and position information from perturbed graphs for permutation equivariant score estimation. Under the evaluation of comprehensive metrics, our proposed generative diffusion process achieves competitive performance in graph distribution learning. Experimental results also show that GraphGDP can generate high-quality graphs in only 24 function evaluations, much faster than previous autoregressive models.
Continuous-Time and Multi-Level Graph Representation Learning for Origin-Destination Demand Prediction
Jun 30, 2022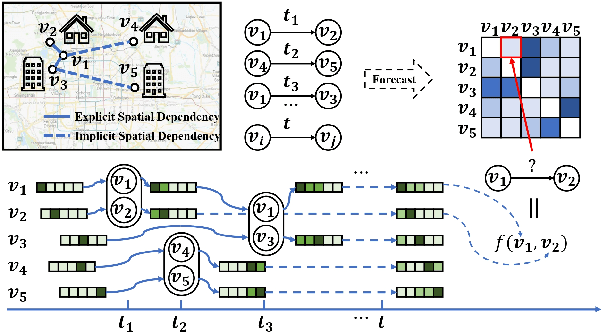
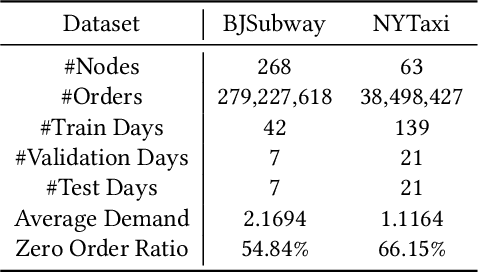
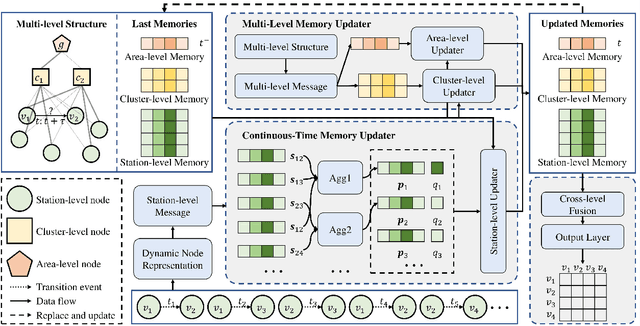
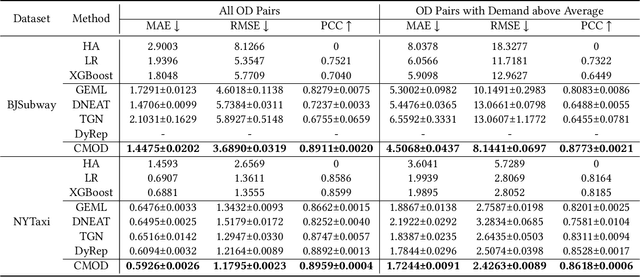
Traffic demand forecasting by deep neural networks has attracted widespread interest in both academia and industry society. Among them, the pairwise Origin-Destination (OD) demand prediction is a valuable but challenging problem due to several factors: (i) the large number of possible OD pairs, (ii) implicitness of spatial dependence, and (iii) complexity of traffic states. To address the above issues, this paper proposes a Continuous-time and Multi-level dynamic graph representation learning method for Origin-Destination demand prediction (CMOD). Firstly, a continuous-time dynamic graph representation learning framework is constructed, which maintains a dynamic state vector for each traffic node (metro stations or taxi zones). The state vectors keep historical transaction information and are continuously updated according to the most recently happened transactions. Secondly, a multi-level structure learning module is proposed to model the spatial dependency of station-level nodes. It can not only exploit relations between nodes adaptively from data, but also share messages and representations via cluster-level and area-level virtual nodes. Lastly, a cross-level fusion module is designed to integrate multi-level memories and generate comprehensive node representations for the final prediction. Extensive experiments are conducted on two real-world datasets from Beijing Subway and New York Taxi, and the results demonstrate the superiority of our model against the state-of-the-art approaches.
Label-Enhanced Graph Neural Network for Semi-supervised Node Classification
May 31, 2022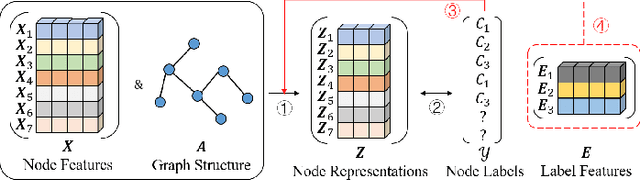

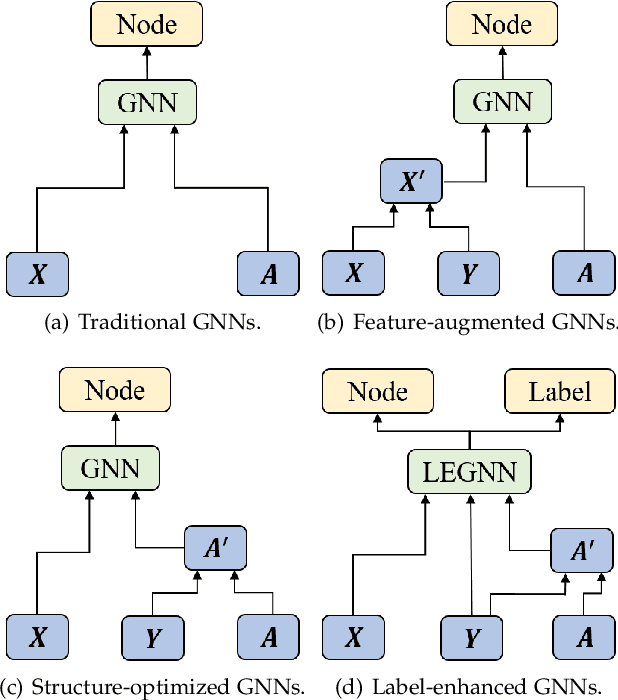
Graph Neural Networks (GNNs) have been widely applied in the semi-supervised node classification task, where a key point lies in how to sufficiently leverage the limited but valuable label information. Most of the classical GNNs solely use the known labels for computing the classification loss at the output. In recent years, several methods have been designed to additionally utilize the labels at the input. One part of the methods augment the node features via concatenating or adding them with the one-hot encodings of labels, while other methods optimize the graph structure by assuming neighboring nodes tend to have the same label. To bring into full play the rich information of labels, in this paper, we present a label-enhanced learning framework for GNNs, which first models each label as a virtual center for intra-class nodes and then jointly learns the representations of both nodes and labels. Our approach could not only smooth the representations of nodes belonging to the same class, but also explicitly encode the label semantics into the learning process of GNNs. Moreover, a training node selection technique is provided to eliminate the potential label leakage issue and guarantee the model generalization ability. Finally, an adaptive self-training strategy is proposed to iteratively enlarge the training set with more reliable pseudo labels and distinguish the importance of each pseudo-labeled node during the model training process. Experimental results on both real-world and synthetic datasets demonstrate our approach can not only consistently outperform the state-of-the-arts, but also effectively smooth the representations of intra-class nodes.
Modelling Evolutionary and Stationary User Preferences for Temporal Sets Prediction
Apr 14, 2022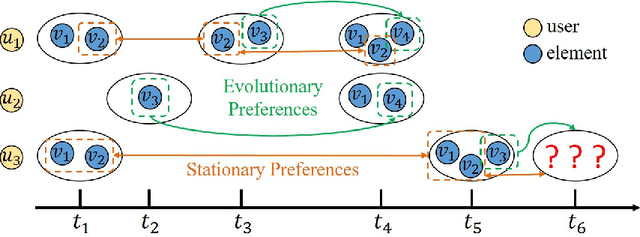

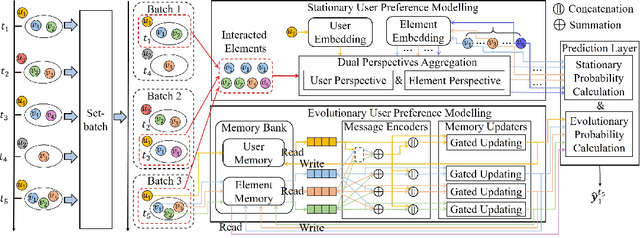

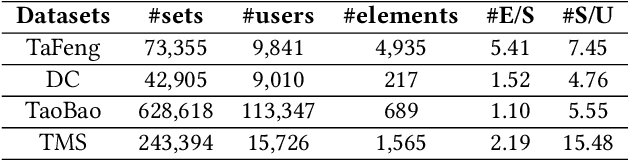
Given a sequence of sets, where each set is associated with a timestamp and contains an arbitrary number of elements, the task of temporal sets prediction aims to predict the elements in the subsequent set. Previous studies for temporal sets prediction mainly capture each user's evolutionary preference by learning from his/her own sequence. Although insightful, we argue that: 1) the collaborative signals latent in different users' sequences are essential but have not been exploited; 2) users also tend to show stationary preferences while existing methods fail to consider. To this end, we propose an integrated learning framework to model both the evolutionary and the stationary preferences of users for temporal sets prediction, which first constructs a universal sequence by chronologically arranging all the user-set interactions, and then learns on each user-set interaction. In particular, for each user-set interaction, we first design an evolutionary user preference modelling component to track the user's time-evolving preference and exploit the latent collaborative signals among different users. This component maintains a memory bank to store memories of the related user and elements, and continuously updates their memories based on the currently encoded messages and the past memories. Then, we devise a stationary user preference modelling module to discover each user's personalized characteristics according to the historical sequence, which adaptively aggregates the previously interacted elements from dual perspectives with the guidance of the user's and elements' embeddings. Finally, we develop a set-batch algorithm to improve the model efficiency, which can create time-consistent batches in advance and achieve 3.5x training speedups on average. Experiments on real-world datasets demonstrate the effectiveness and good interpretability of our approach.
Collaborative Learning in General Graphs with Limited Memorization: Learnability, Complexity and Reliability
Jan 29, 2022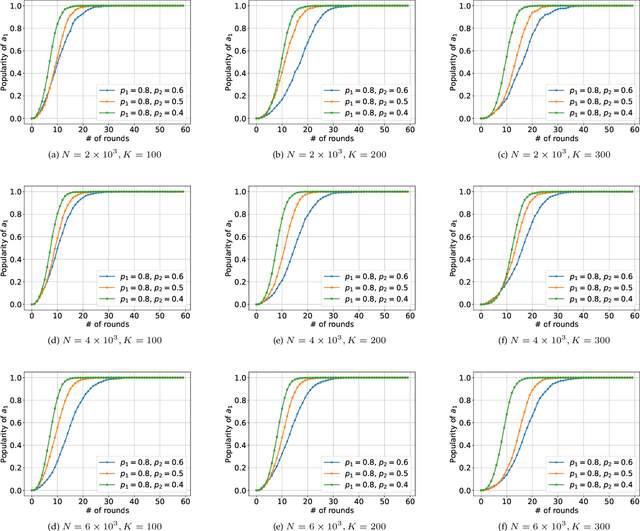
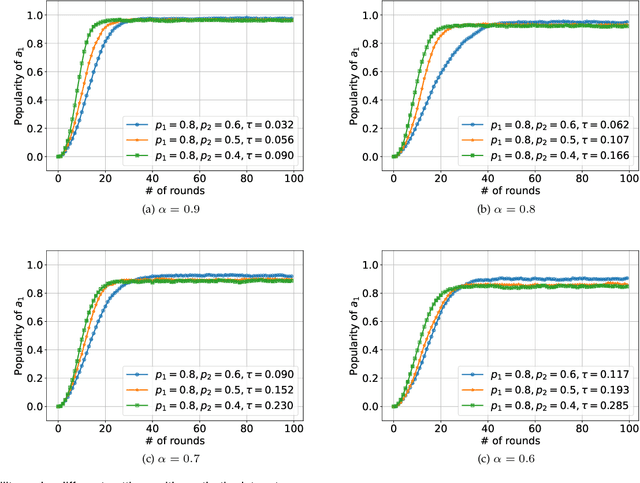
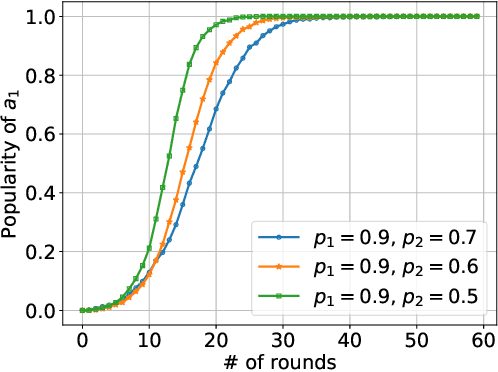
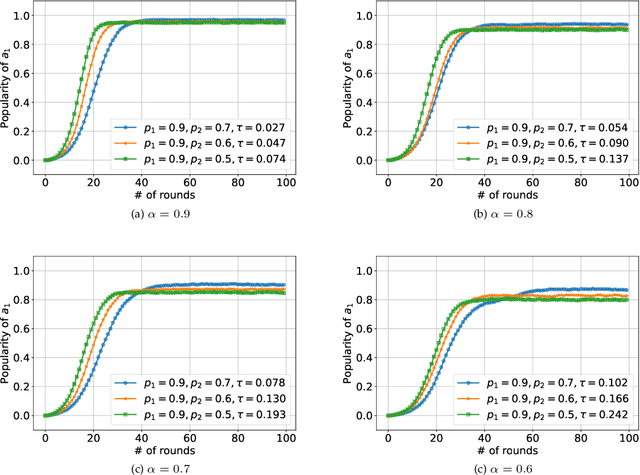
We consider K-armed bandit problem in general graphs where agents are arbitrarily connected and each of them has limited memorization and communication bandwidth. The goal is to let each of the agents learn the best arm. Although recent studies show the power of collaboration among the agents in improving the efficacy of learning, it is assumed in these studies that the communication graphs should be complete or well-structured, whereas such an assumption is not always valid in practice. Furthermore, limited memorization and communication bandwidth also restrict the collaborations of the agents, since very few knowledge can be drawn by each agent from its experiences or the ones shared by its peers in this case. Additionally, the agents may be corrupted to share falsified experience, while the resource limit may considerably restrict the reliability of the learning process. To address the above issues, we propose a three-staged collaborative learning algorithm. In each step, the agents share their experience with each other through light-weight random walks in the general graphs, and then make decisions on which arms to pull according to the randomly memorized suggestions. The agents finally update their adoptions (i.e., preferences to the arms) based on the reward feedback of the arm pulling. Our theoretical analysis shows that, by exploiting the limited memorization and communication resources, all the agents eventually learn the best arm with high probability. We also reveal in our theoretical analysis the upper-bound on the number of corrupted agents our algorithm can tolerate. The efficacy of our proposed three-staged collaborative learning algorithm is finally verified by extensive experiments on both synthetic and real datasets.
Heterogeneous Graph Representation Learning with Relation Awareness
May 24, 2021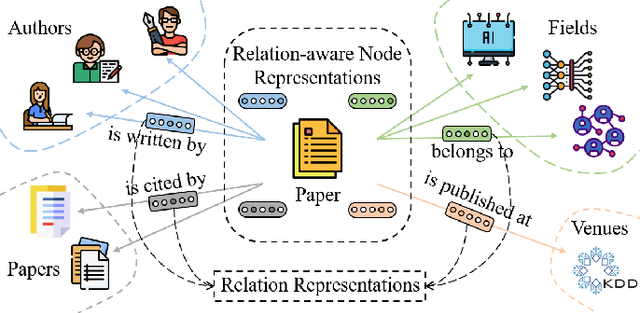
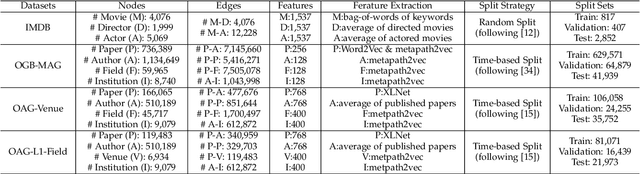
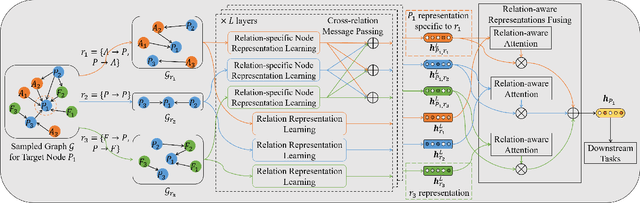

Representation learning on heterogeneous graphs aims to obtain meaningful node representations to facilitate various downstream tasks, such as node classification and link prediction. Existing heterogeneous graph learning methods are primarily developed by following the propagation mechanism of node representations. There are few efforts on studying the role of relations for improving the learning of more fine-grained node representations. Indeed, it is important to collaboratively learn the semantic representations of relations and discern node representations with respect to different relation types. To this end, in this paper, we propose a novel Relation-aware Heterogeneous Graph Neural Network, namely R-HGNN, to learn node representations on heterogeneous graphs at a fine-grained level by considering relation-aware characteristics. Specifically, a dedicated graph convolution component is first designed to learn unique node representations from each relation-specific graph separately. Then, a cross-relation message passing module is developed to improve the interactions of node representations across different relations. Also, the relation representations are learned in a layer-wise manner to capture relation semantics, which are used to guide the node representation learning process. Moreover, a semantic fusing module is presented to aggregate relation-aware node representations into a compact representation with the learned relation representations. Finally, we conduct extensive experiments on a variety of graph learning tasks, and experimental results demonstrate that our approach consistently outperforms existing methods among all the tasks.
Hybrid Micro/Macro Level Convolution for Heterogeneous Graph Learning
Dec 29, 2020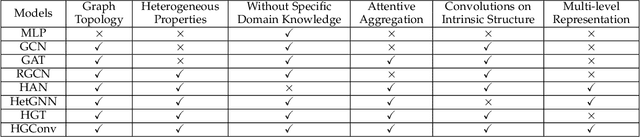
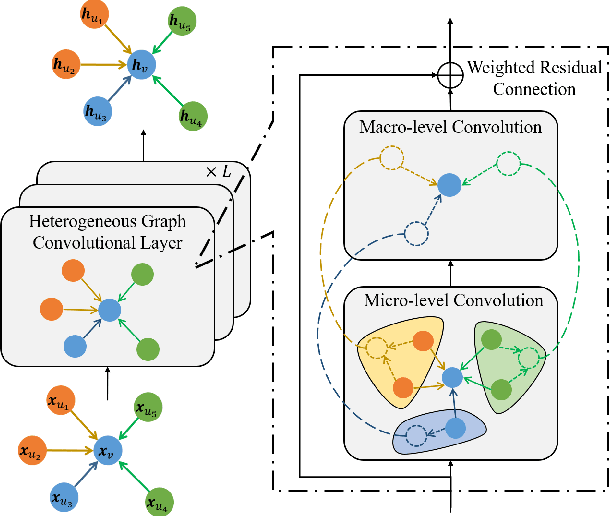
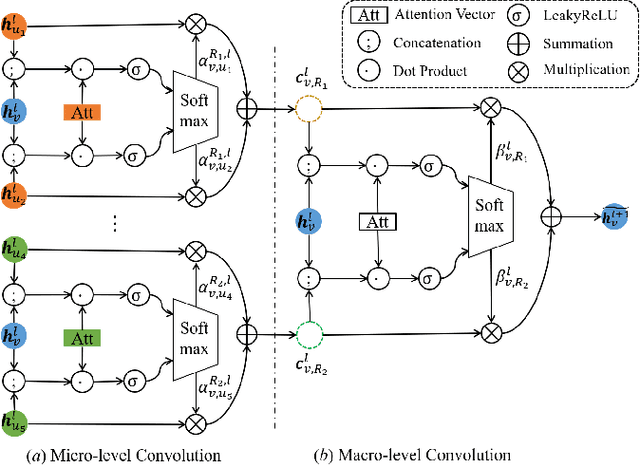
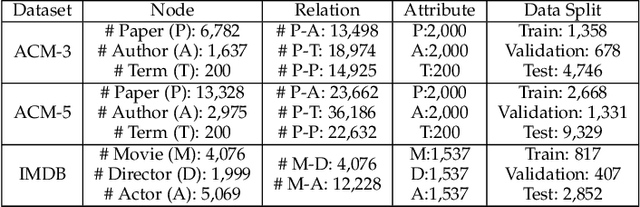
Heterogeneous graphs are pervasive in practical scenarios, where each graph consists of multiple types of nodes and edges. Representation learning on heterogeneous graphs aims to obtain low-dimensional node representations that could preserve both node attributes and relation information. However, most of the existing graph convolution approaches were designed for homogeneous graphs, and therefore cannot handle heterogeneous graphs. Some recent methods designed for heterogeneous graphs are also faced with several issues, including the insufficient utilization of heterogeneous properties, structural information loss, and lack of interpretability. In this paper, we propose HGConv, a novel Heterogeneous Graph Convolution approach, to learn comprehensive node representations on heterogeneous graphs with a hybrid micro/macro level convolutional operation. Different from existing methods, HGConv could perform convolutions on the intrinsic structure of heterogeneous graphs directly at both micro and macro levels: A micro-level convolution to learn the importance of nodes within the same relation, and a macro-level convolution to distinguish the subtle difference across different relations. The hybrid strategy enables HGConv to fully leverage heterogeneous information with proper interpretability. Moreover, a weighted residual connection is designed to aggregate both inherent attributes and neighbor information of the focal node adaptively. Extensive experiments on various tasks demonstrate not only the superiority of HGConv over existing methods, but also the intuitive interpretability of our approach for graph analysis.
Predicting Temporal Sets with Deep Neural Networks
Jul 08, 2020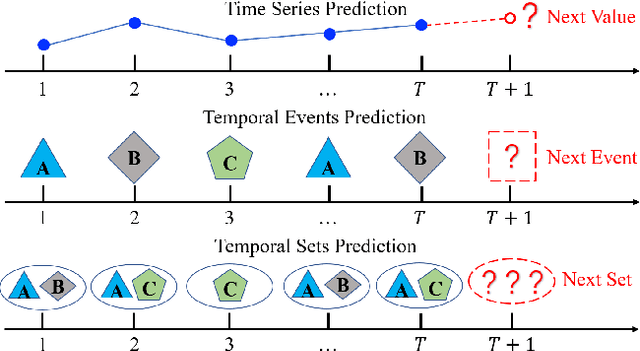
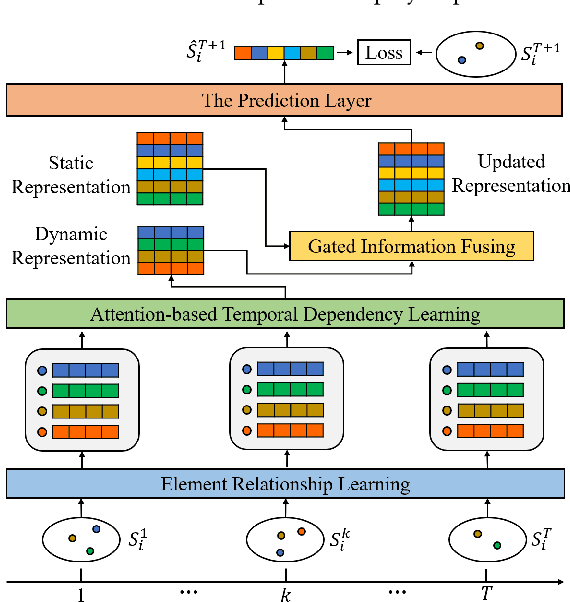

Given a sequence of sets, where each set contains an arbitrary number of elements, the problem of temporal sets prediction aims to predict the elements in the subsequent set. In practice, temporal sets prediction is much more complex than predictive modelling of temporal events and time series, and is still an open problem. Many possible existing methods, if adapted for the problem of temporal sets prediction, usually follow a two-step strategy by first projecting temporal sets into latent representations and then learning a predictive model with the latent representations. The two-step approach often leads to information loss and unsatisfactory prediction performance. In this paper, we propose an integrated solution based on the deep neural networks for temporal sets prediction. A unique perspective of our approach is to learn element relationship by constructing set-level co-occurrence graph and then perform graph convolutions on the dynamic relationship graphs. Moreover, we design an attention-based module to adaptively learn the temporal dependency of elements and sets. Finally, we provide a gated updating mechanism to find the hidden shared patterns in different sequences and fuse both static and dynamic information to improve the prediction performance. Experiments on real-world data sets demonstrate that our approach can achieve competitive performances even with a portion of the training data and can outperform existing methods with a significant margin.
S-Net: From Answer Extraction to Answer Generation for Machine Reading Comprehension
Jan 02, 2018
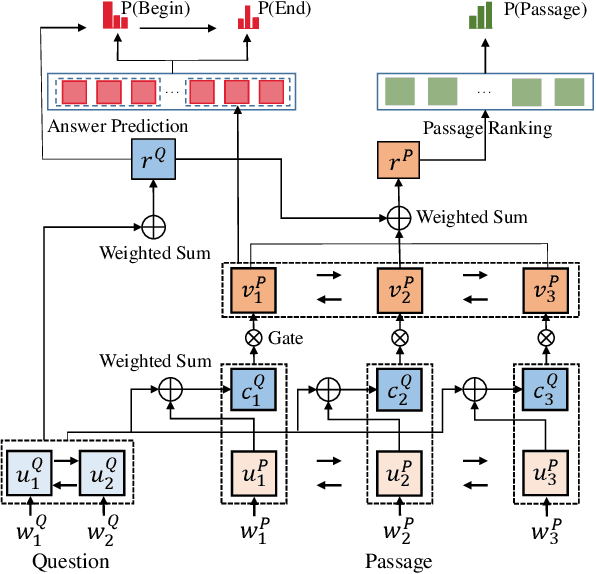
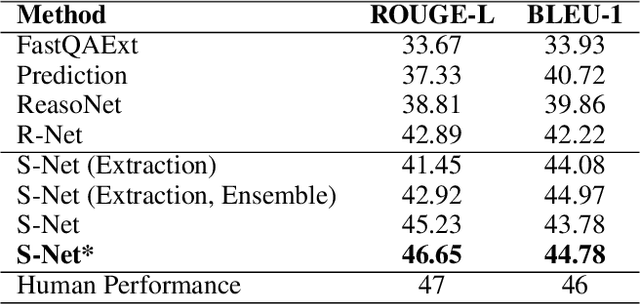
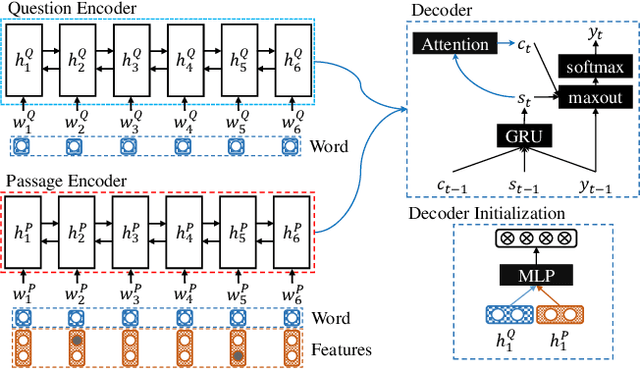
In this paper, we present a novel approach to machine reading comprehension for the MS-MARCO dataset. Unlike the SQuAD dataset that aims to answer a question with exact text spans in a passage, the MS-MARCO dataset defines the task as answering a question from multiple passages and the words in the answer are not necessary in the passages. We therefore develop an extraction-then-synthesis framework to synthesize answers from extraction results. Specifically, the answer extraction model is first employed to predict the most important sub-spans from the passage as evidence, and the answer synthesis model takes the evidence as additional features along with the question and passage to further elaborate the final answers. We build the answer extraction model with state-of-the-art neural networks for single passage reading comprehension, and propose an additional task of passage ranking to help answer extraction in multiple passages. The answer synthesis model is based on the sequence-to-sequence neural networks with extracted evidences as features. Experiments show that our extraction-then-synthesis method outperforms state-of-the-art methods.
Entity Linking for Queries by Searching Wikipedia Sentences
May 18, 2017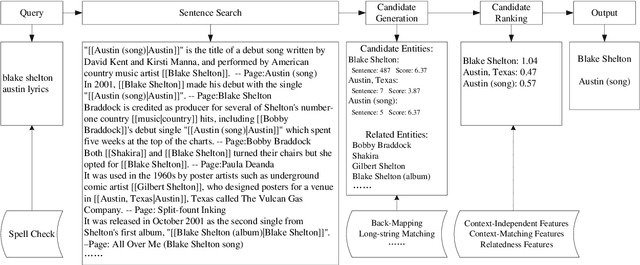

We present a simple yet effective approach for linking entities in queries. The key idea is to search sentences similar to a query from Wikipedia articles and directly use the human-annotated entities in the similar sentences as candidate entities for the query. Then, we employ a rich set of features, such as link-probability, context-matching, word embeddings, and relatedness among candidate entities as well as their related entities, to rank the candidates under a regression based framework. The advantages of our approach lie in two aspects, which contribute to the ranking process and final linking result. First, it can greatly reduce the number of candidate entities by filtering out irrelevant entities with the words in the query. Second, we can obtain the query sensitive prior probability in addition to the static link-probability derived from all Wikipedia articles. We conduct experiments on two benchmark datasets on entity linking for queries, namely the ERD14 dataset and the GERDAQ dataset. Experimental results show that our method outperforms state-of-the-art systems and yields 75.0% in F1 on the ERD14 dataset and 56.9% on the GERDAQ dataset.