 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Spatial-Temporal Network for Interpretable Automatic Ultrasonic Assessment of Fetal Head during labor
Mar 20, 2025The intrapartum ultrasound guideline established by ISUOG highlights the Angle of Progression (AoP) and Head Symphysis Distance (HSD) as pivotal metrics for assessing fetal head descent and predicting delivery outcomes. Accurate measurement of the AoP and HSD requires a structured process. This begins with identifying standardized ultrasound planes, followed by the detection of specific anatomical landmarks within the regions of the pubic symphysis and fetal head that correlate with the delivery parameters AoP and HSD. Finally, these measurements are derived based on the identified anatomical landmarks. Addressing the clinical demands and standard operation process outlined in the ISUOG guideline, we introduce the Sequential Spatial-Temporal Network (SSTN), the first interpretable model specifically designed for the video of intrapartum ultrasound analysis. The SSTN operates by first identifying ultrasound planes, then segmenting anatomical structures such as the pubic symphysis and fetal head, and finally detecting key landmarks for precise measurement of HSD and AoP. Furthermore, the cohesive framework leverages task-related information to improve accuracy and reliability. Experimental evaluations on clinical datasets demonstrate that SSTN significantly surpasses existing models, reducing the mean absolute error by 18% for AoP and 22% for HSD.
Through the Magnifying Glass: Adaptive Perception Magnification for Hallucination-Free VLM Decoding
Mar 13, 2025Existing vision-language models (VLMs) often suffer from visual hallucination, where the generated responses contain inaccuracies that are not grounded in the visual input. Efforts to address this issue without model finetuning primarily mitigate hallucination by reducing biases contrastively or amplifying the weights of visual embedding during decoding. However, these approaches improve visual perception at the cost of impairing the language reasoning capability. In this work, we propose the Perception Magnifier (PM), a novel visual decoding method that iteratively isolates relevant visual tokens based on attention and magnifies the corresponding regions, spurring the model to concentrate on fine-grained visual details during decoding. Specifically, by magnifying critical regions while preserving the structural and contextual information at each decoding step, PM allows the VLM to enhance its scrutiny of the visual input, hence producing more accurate and faithful responses. Extensive experimental results demonstrate that PM not only achieves superior hallucination mitigation but also enhances language generation while preserving strong reasoning capabilities.Code is available at https://github.com/ShunqiM/PM .
Stealthy Patch-Wise Backdoor Attack in 3D Point Cloud via Curvature Awareness
Mar 12, 2025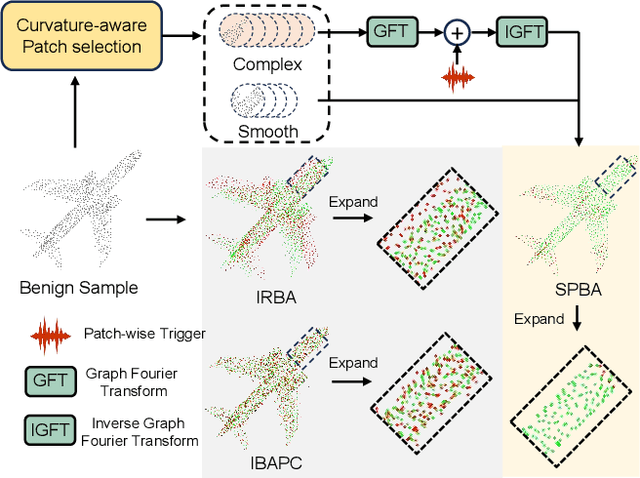
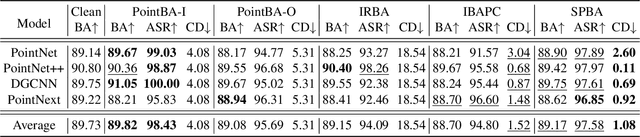
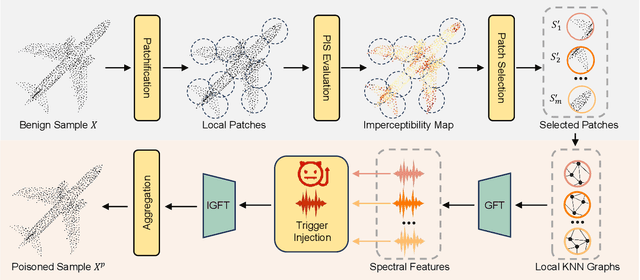
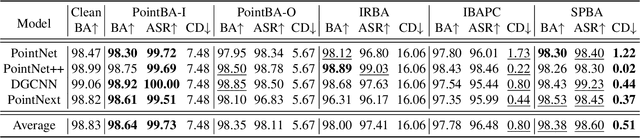
Backdoor attacks pose a severe threat to deep neural networks (DNN) by implanting hidden backdoors that can be activated with predefined triggers to manipulate model behaviors maliciously. Existing 3D point cloud backdoor attacks primarily rely on sample-wise global modifications, resulting in suboptimal stealthiness. To address this limitation, we propose Stealthy Patch-Wise Backdoor Attack (SPBA), which employs the first patch-wise trigger for 3D point clouds and restricts perturbations to local regions, significantly enhancing stealthiness. Specifically, SPBA decomposes point clouds into local patches and evaluates their geometric complexity using a curvature-based patch imperceptibility score, ensuring that the trigger remains less perceptible to the human eye by strategically applying it across multiple geometrically complex patches with lower visual sensitivity. By leveraging the Graph Fourier Transform (GFT), SPBA optimizes a patch-wise spectral trigger that perturbs the spectral features of selected patches, enhancing attack effectiveness while preserving the global geometric structure of the point cloud. Extensive experiments on ModelNet40 and ShapeNetPart demonstrate that SPBA consistently achieves an attack success rate (ASR) exceeding 96.5% across different models while achieving state-of-the-art imperceptibility compared to existing backdoor attack methods.
MultiCo3D: Multi-Label Voxel Contrast for One-Shot Incremental Segmentation of 3D Neuroimages
Mar 09, 20253D neuroimages provide a comprehensive view of brain structure and function, aiding in precise localization and functional connectivity analysis. Segmentation of white matter (WM) tracts using 3D neuroimages is vital for understanding the brain's structural connectivity in both healthy and diseased states. One-shot Class Incremental Semantic Segmentation (OCIS) refers to effectively segmenting new (novel) classes using only a single sample while retaining knowledge of old (base) classes without forgetting. Voxel-contrastive OCIS methods adjust the feature space to alleviate the feature overlap problem between the base and novel classes. However, since WM tract segmentation is a multi-label segmentation task, existing single-label voxel contrastive-based methods may cause inherent contradictions. To address this, we propose a new multi-label voxel contrast framework called MultiCo3D for one-shot class incremental tract segmentation. Our method utilizes uncertainty distillation to preserve base tract segmentation knowledge while adjusting the feature space with multi-label voxel contrast to alleviate feature overlap when learning novel tracts and dynamically weighting multi losses to balance overall loss. We compare our method against several state-of-the-art (SOTA) approaches. The experimental results show that our method significantly enhances one-shot class incremental tract segmentation accuracy across five different experimental setups on HCP and Preto datasets.
CA-W3D: Leveraging Context-Aware Knowledge for Weakly Supervised Monocular 3D Detection
Mar 06, 2025Weakly supervised monocular 3D detection, while less annotation-intensive, often struggles to capture the global context required for reliable 3D reasoning. Conventional label-efficient methods focus on object-centric features, neglecting contextual semantic relationships that are critical in complex scenes. In this work, we propose a Context-Aware Weak Supervision for Monocular 3D object detection, namely CA-W3D, to address this limitation in a two-stage training paradigm. Specifically, we first introduce a pre-training stage employing Region-wise Object Contrastive Matching (ROCM), which aligns regional object embeddings derived from a trainable monocular 3D encoder and a frozen open-vocabulary 2D visual grounding model. This alignment encourages the monocular encoder to discriminate scene-specific attributes and acquire richer contextual knowledge. In the second stage, we incorporate a pseudo-label training process with a Dual-to-One Distillation (D2OD) mechanism, which effectively transfers contextual priors into the monocular encoder while preserving spatial fidelity and maintaining computational efficiency during inference. Extensive experiments conducted on the public KITTI benchmark demonstrate the effectiveness of our approach, surpassing the SoTA method over all metrics, highlighting the importance of contextual-aware knowledge in weakly-supervised monocular 3D detection.
VRM: Knowledge Distillation via Virtual Relation Matching
Feb 28, 2025Knowledge distillation (KD) aims to transfer the knowledge of a more capable yet cumbersome teacher model to a lightweight student model. In recent years, relation-based KD methods have fallen behind, as their instance-matching counterparts dominate in performance. In this paper, we revive relational KD by identifying and tackling several key issues in relation-based methods, including their susceptibility to overfitting and spurious responses. Specifically, we transfer novelly constructed affinity graphs that compactly encapsulate a wealth of beneficial inter-sample, inter-class, and inter-view correlations by exploiting virtual views and relations as a new kind of knowledge. As a result, the student has access to richer guidance signals and stronger regularisation throughout the distillation process. To further mitigate the adverse impact of spurious responses, we prune the affinity graphs by dynamically detaching redundant and unreliable edges. Extensive experiments on CIFAR-100 and ImageNet datasets demonstrate the superior performance of the proposed virtual relation matching (VRM) method over a range of models, architectures, and set-ups. For instance, VRM for the first time hits 74.0% accuracy for ResNet50-to-MobileNetV2 distillation on ImageNet, and improves DeiT-T by 14.44% on CIFAR-100 with a ResNet56 teacher. Thorough analyses are also conducted to gauge the soundness, properties, and complexity of our designs. Code and models will be released.
TractCloud-FOV: Deep Learning-based Robust Tractography Parcellation in Diffusion MRI with Incomplete Field of View
Feb 28, 2025Tractography parcellation classifies streamlines reconstructed from diffusion MRI into anatomically defined fiber tracts for clinical and research applications. However, clinical scans often have incomplete fields of view (FOV) where brain regions are partially imaged, leading to partial or truncated fiber tracts. To address this challenge, we introduce TractCloud-FOV, a deep learning framework that robustly parcellates tractography under conditions of incomplete FOV. We propose a novel training strategy, FOV-Cut Augmentation (FOV-CA), in which we synthetically cut tractograms to simulate a spectrum of real-world inferior FOV cutoff scenarios. This data augmentation approach enriches the training set with realistic truncated streamlines, enabling the model to achieve superior generalization. We evaluate the proposed TractCloud-FOV on both synthetically cut tractography and two real-life datasets with incomplete FOV. TractCloud-FOV significantly outperforms several state-of-the-art methods on all testing datasets in terms of streamline classification accuracy, generalization ability, tract anatomical depiction, and computational efficiency. Overall, TractCloud-FOV achieves efficient and consistent tractography parcellation in diffusion MRI with incomplete FOV.
Efficient 4D fMRI ASD Classification using Spatial-Temporal-Omics-based Learning Framework
Feb 26, 2025


Autism Spectrum Disorder (ASD) is a neurodevelopmental disorder impacting social and behavioral development. Resting-state fMRI, a non-invasive tool for capturing brain connectivity patterns, aids in early ASD diagnosis and differentiation from typical controls (TC). However, previous methods, which rely on either mean time series or full 4D data, are limited by a lack of spatial information or by high computational costs. This underscores the need for an efficient solution that preserves both spatial and temporal information. In this paper, we propose a novel, simple, and efficient spatial-temporal-omics learning framework designed to efficiently extract spatio-temporal features from fMRI for ASD classification. Our approach addresses these limitations by utilizing 3D time-domain derivatives as the spatial-temporal inter-voxel omics, which preserve full spatial resolution while capturing diverse statistical characteristics of the time series at each voxel. Meanwhile, functional connectivity features serve as the spatial-temporal inter-regional omics, capturing correlations across brain regions. Extensive experiments and ablation studies on the ABIDE dataset demonstrate that our framework significantly outperforms previous methods while maintaining computational efficiency. We believe our research offers valuable insights that will inform and advance future ASD studies, particularly in the realm of spatial-temporal-omics-based learning.
RealSyn: An Effective and Scalable Multimodal Interleaved Document Transformation Paradigm
Feb 18, 2025



After pre-training on extensive image-text pairs, Contrastive Language-Image Pre-training (CLIP) demonstrates promising performance on a wide variety of benchmarks. However, a substantial volume of non-paired data, such as multimodal interleaved documents, remains underutilized for vision-language representation learning. To fully leverage these unpaired documents, we initially establish a Real-World Data Extraction pipeline to extract high-quality images and texts. Then we design a hierarchical retrieval method to efficiently associate each image with multiple semantically relevant realistic texts. To further enhance fine-grained visual information, we propose an image semantic augmented generation module for synthetic text production. Furthermore, we employ a semantic balance sampling strategy to improve dataset diversity, enabling better learning of long-tail concepts. Based on these innovations, we construct RealSyn, a dataset combining realistic and synthetic texts, available in three scales: 15M, 30M, and 100M. Extensive experiments demonstrate that RealSyn effectively advances vision-language representation learning and exhibits strong scalability. Models pre-trained on RealSyn achieve state-of-the-art performance on multiple downstream tasks. To facilitate future research, the RealSyn dataset and pre-trained model weights are released at https://github.com/deepglint/RealSyn.
Medical Image Registration Meets Vision Foundation Model: Prototype Learning and Contour Awareness
Feb 17, 2025Medical image registration is a fundamental task in medical image analysis, aiming to establish spatial correspondences between paired images. However, existing unsupervised deformable registration methods rely solely on intensity-based similarity metrics, lacking explicit anatomical knowledge, which limits their accuracy and robustness. Vision foundation models, such as the Segment Anything Model (SAM), can generate high-quality segmentation masks that provide explicit anatomical structure knowledge, addressing the limitations of traditional methods that depend only on intensity similarity. Based on this, we propose a novel SAM-assisted registration framework incorporating prototype learning and contour awareness. The framework includes: (1) Explicit anatomical information injection, where SAM-generated segmentation masks are used as auxiliary inputs throughout training and testing to ensure the consistency of anatomical information; (2) Prototype learning, which leverages segmentation masks to extract prototype features and aligns prototypes to optimize semantic correspondences between images; and (3) Contour-aware loss, a contour-aware loss is designed that leverages the edges of segmentation masks to improve the model's performance in fine-grained deformation fields. Extensive experiments demonstrate that the proposed framework significantly outperforms existing methods across multiple datasets, particularly in challenging scenarios with complex anatomical structures and ambiguous boundaries. Our code is available at https://github.com/HaoXu0507/IPMI25-SAM-Assisted-Registration.