 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Learning for On-Device Speech Recognition using Disentangled Conformers
Dec 13, 2022



Automatic speech recognition research focuses on training and evaluating on static datasets. Yet, as speech models are increasingly deployed on personal devices, such models encounter user-specific distributional shifts. To simulate this real-world scenario, we introduce LibriContinual, a continual learning benchmark for speaker-specific domain adaptation derived from LibriVox audiobooks, with data corresponding to 118 individual speakers and 6 train splits per speaker of different sizes. Additionally, current speech recognition models and continual learning algorithms are not optimized to be compute-efficient. We adapt a general-purpose training algorithm NetAug for ASR and create a novel Conformer variant called the DisConformer (Disentangled Conformer). This algorithm produces ASR models consisting of a frozen 'core' network for general-purpose use and several tunable 'augment' networks for speaker-specific tuning. Using such models, we propose a novel compute-efficient continual learning algorithm called DisentangledCL. Our experiments show that the DisConformer models significantly outperform baselines on general ASR i.e. LibriSpeech (15.58% rel. WER on test-other). On speaker-specific LibriContinual they significantly outperform trainable-parameter-matched baselines (by 20.65% rel. WER on test) and even match fully finetuned baselines in some settings.
Speech-to-Speech Translation For A Real-world Unwritten Language
Nov 11, 2022



We study speech-to-speech translation (S2ST) that translates speech from one language into another language and focuses on building systems to support languages without standard text writing systems. We use English-Taiwanese Hokkien as a case study, and present an end-to-end solution from training data collection, modeling choices to benchmark dataset release. First, we present efforts on creating human annotated data, automatically mining data from large unlabeled speech datasets, and adopting pseudo-labeling to produce weakly supervised data. On the modeling, we take advantage of recent advances in applying self-supervised discrete representations as target for prediction in S2ST and show the effectiveness of leveraging additional text supervision from Mandarin, a language similar to Hokkien, in model training. Finally, we release an S2ST benchmark set to facilitate future research in this field. The demo can be found at https://huggingface.co/spaces/facebook/Hokkien_Translation .
Simple and Effective Unsupervised Speech Translation
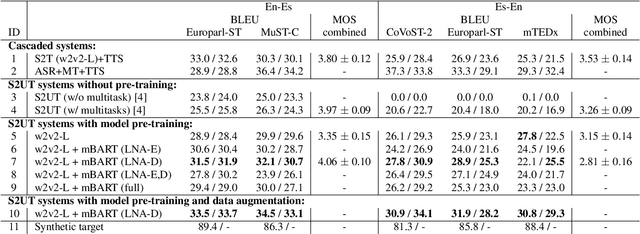
Oct 18, 2022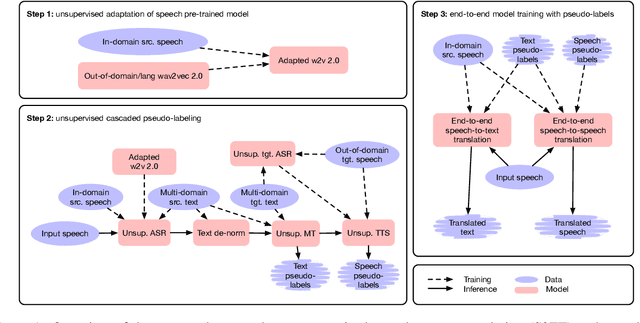
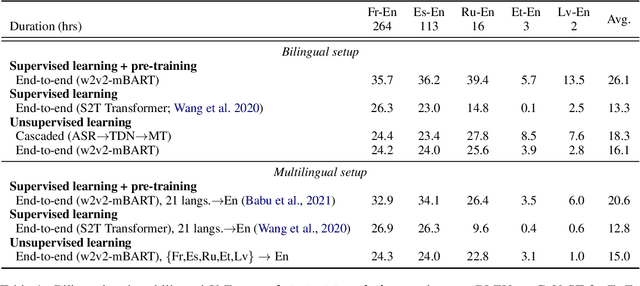
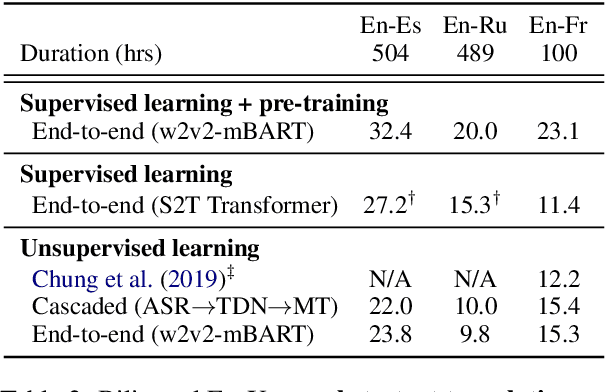
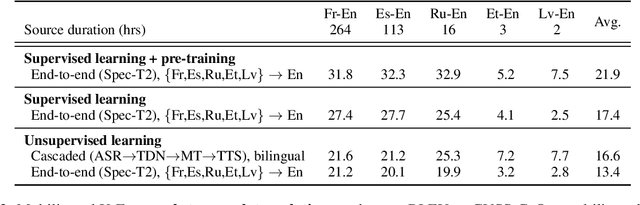
The amount of labeled data to train models for speech tasks is limited for most languages, however, the data scarcity is exacerbated for speech translation which requires labeled data covering two different languages. To address this issue, we study a simple and effective approach to build speech translation systems without labeled data by leveraging recent advances in unsupervised speech recognition, machine translation and speech synthesis, either in a pipeline approach, or to generate pseudo-labels for training end-to-end speech translation models. Furthermore, we present an unsupervised domain adaptation technique for pre-trained speech models which improves the performance of downstream unsupervised speech recognition, especially for low-resource settings. Experiments show that unsupervised speech-to-text translation outperforms the previous unsupervised state of the art by 3.2 BLEU on the Libri-Trans benchmark, on CoVoST 2, our best systems outperform the best supervised end-to-end models (without pre-training) from only two years ago by an average of 5.0 BLEU over five X-En directions. We also report competitive results on MuST-C and CVSS benchmarks.
A Single Self-Supervised Model for Many Speech Modalities Enables Zero-Shot Modality Transfer
Jul 14, 2022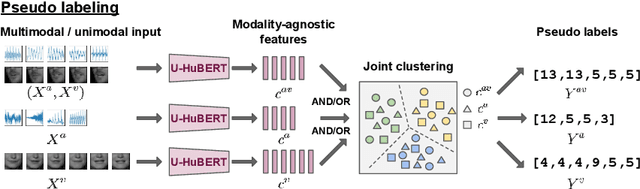
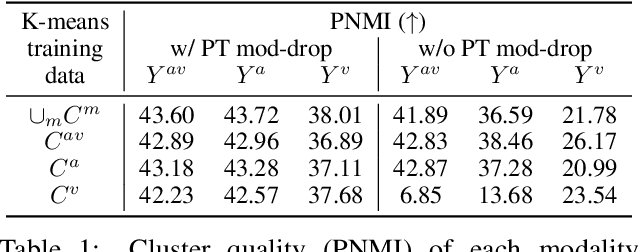
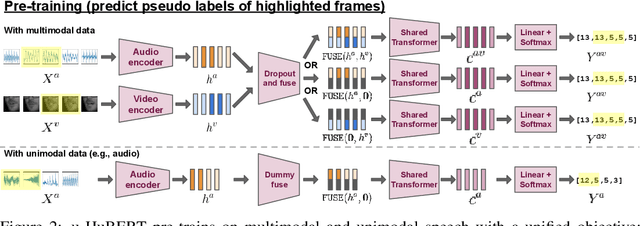
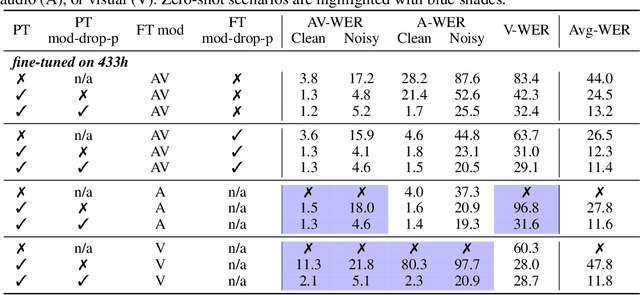
While audio-visual speech models can yield superior performance and robustness compared to audio-only models, their development and adoption are hindered by the lack of labeled and unlabeled audio-visual data and the cost to deploy one model per modality. In this paper, we present u-HuBERT, a self-supervised pre-training framework that can leverage both multimodal and unimodal speech with a unified masked cluster prediction objective. By utilizing modality dropout during pre-training, we demonstrate that a single fine-tuned model can achieve performance on par or better than the state-of-the-art modality-specific models. Moreover, our model fine-tuned only on audio can perform well with audio-visual and visual speech input, achieving zero-shot modality generalization for speech recognition and speaker verification. In particular, our single model yields 1.2%/1.4%/27.2% speech recognition word error rate on LRS3 with audio-visual/audio/visual input.
Learning Lip-Based Audio-Visual Speaker Embeddings with AV-HuBERT
May 15, 2022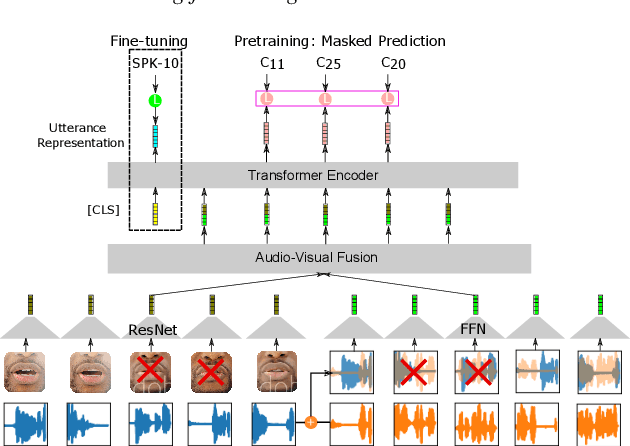
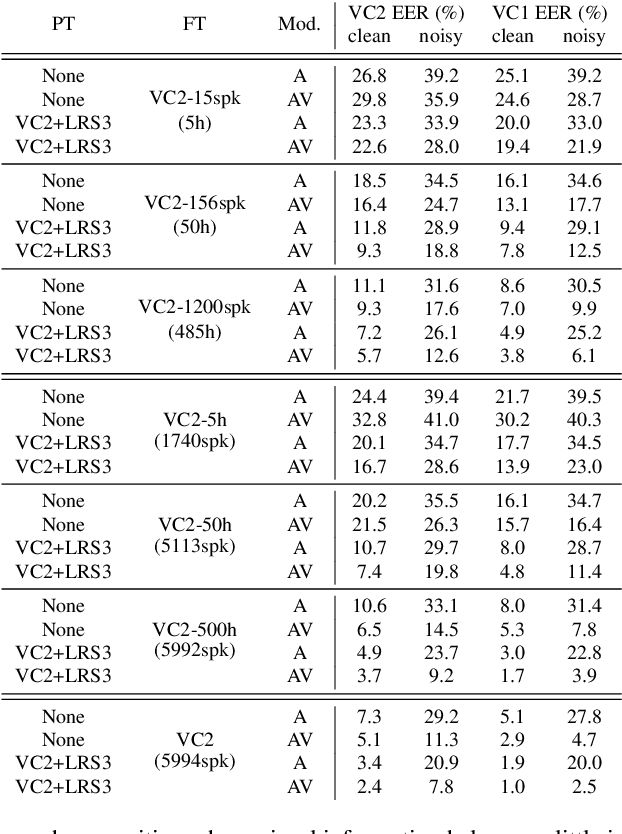
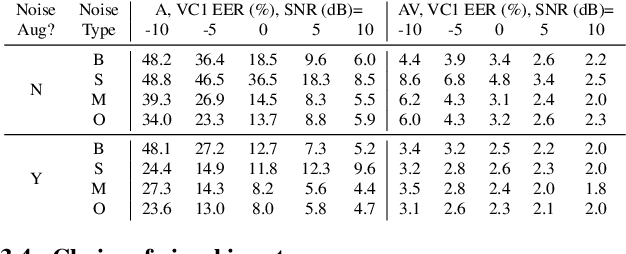
This paper investigates self-supervised pre-training for audio-visual speaker representation learning where a visual stream showing the speaker's mouth area is used alongside speech as inputs. Our study focuses on the Audio-Visual Hidden Unit BERT (AV-HuBERT) approach, a recently developed general-purpose audio-visual speech pre-training framework. We conducted extensive experiments probing the effectiveness of pre-training and visual modality. Experimental results suggest that AV-HuBERT generalizes decently to speaker related downstream tasks, improving label efficiency by roughly ten fold for both audio-only and audio-visual speaker verification. We also show that incorporating visual information, even just the lip area, greatly improves the performance and noise robustness, reducing EER by 38% in the clean condition and 75% in noisy conditions. Our code and models will be publicly available.
On-demand compute reduction with stochastic wav2vec 2.0
Apr 25, 2022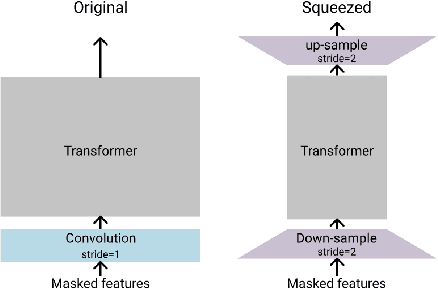
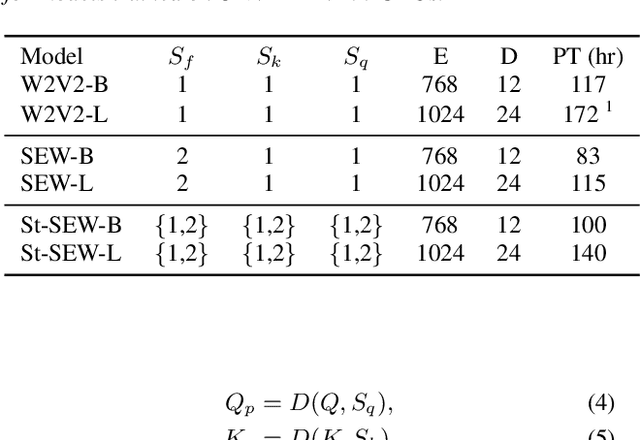
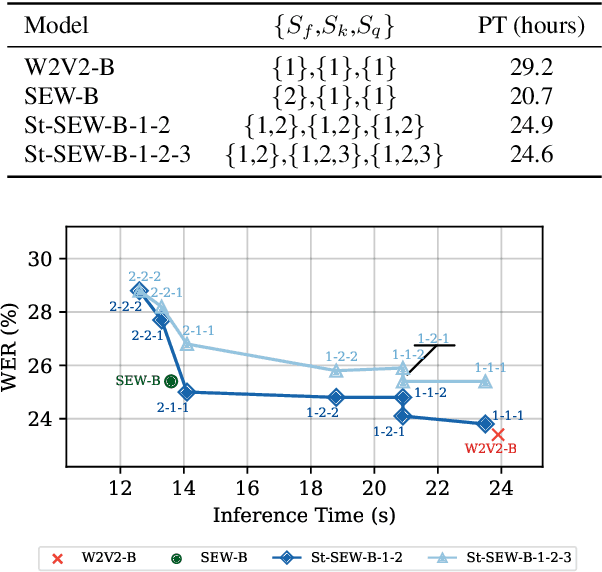
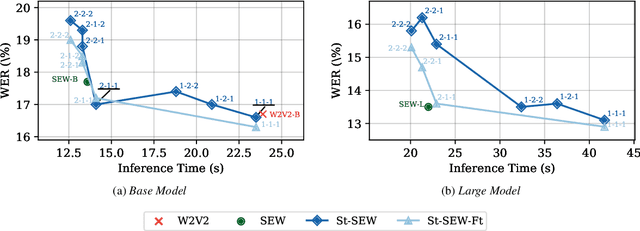
Squeeze and Efficient Wav2vec (SEW) is a recently proposed architecture that squeezes the input to the transformer encoder for compute efficient pre-training and inference with wav2vec 2.0 (W2V2) models. In this work, we propose stochastic compression for on-demand compute reduction for W2V2 models. As opposed to using a fixed squeeze factor, we sample it uniformly during training. We further introduce query and key-value pooling mechanisms that can be applied to each transformer layer for further compression. Our results for models pre-trained on 960h Librispeech dataset and fine-tuned on 10h of transcribed data show that using the same stochastic model, we get a smooth trade-off between word error rate (WER) and inference time with only marginal WER degradation compared to the W2V2 and SEW models trained for a specific setting. We further show that we can fine-tune the same stochastically pre-trained model to a specific configuration to recover the WER difference resulting in significant computational savings on pre-training models from scratch.
Simple and Effective Unsupervised Speech Synthesis
Apr 20, 2022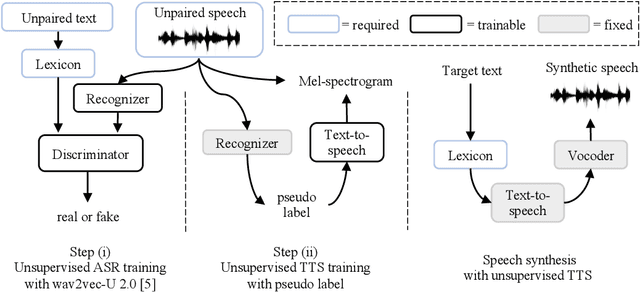
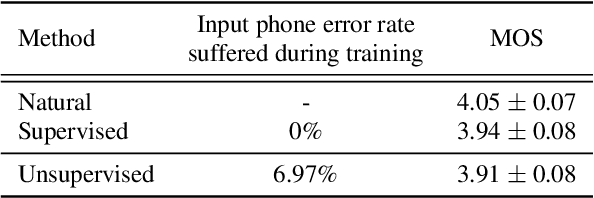
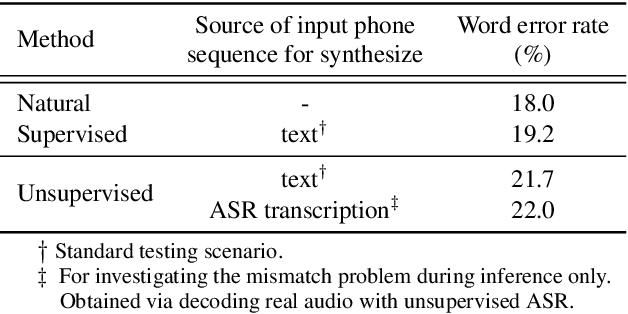

We introduce the first unsupervised speech synthesis system based on a simple, yet effective recipe. The framework leverages recent work in unsupervised speech recognition as well as existing neural-based speech synthesis. Using only unlabeled speech audio and unlabeled text as well as a lexicon, our method enables speech synthesis without the need for a human-labeled corpus. Experiments demonstrate the unsupervised system can synthesize speech similar to a supervised counterpart in terms of naturalness and intelligibility measured by human evaluation.
Unified Speech-Text Pre-training for Speech Translation and Recognition
Apr 11, 2022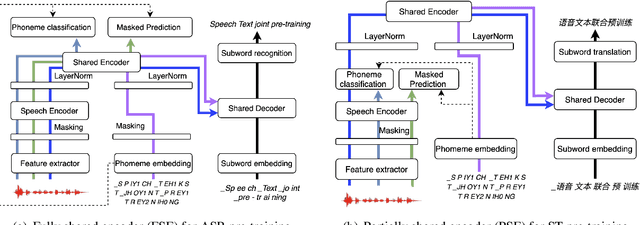

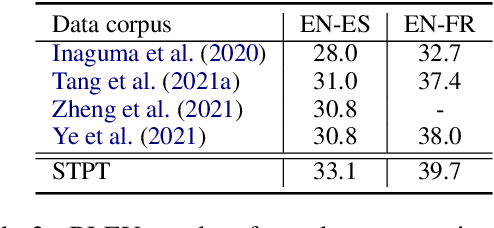
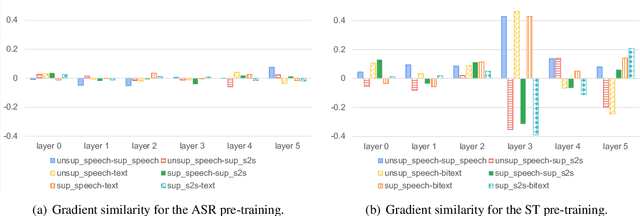
We describe a method to jointly pre-train speech and text in an encoder-decoder modeling framework for speech translation and recognition. The proposed method incorporates four self-supervised and supervised subtasks for cross modality learning. A self-supervised speech subtask leverages unlabelled speech data, and a (self-)supervised text to text subtask makes use of abundant text training data. Two auxiliary supervised speech tasks are included to unify speech and text modeling space. Our contribution lies in integrating linguistic information from the text corpus into the speech pre-training. Detailed analysis reveals learning interference among subtasks. Two pre-training configurations for speech translation and recognition, respectively, are presented to alleviate subtask interference. Our experiments show the proposed method can effectively fuse speech and text information into one model. It achieves between 1.7 and 2.3 BLEU improvement above the state of the art on the MuST-C speech translation dataset and comparable WERs to wav2vec 2.0 on the Librispeech speech recognition task.
Enhanced Direct Speech-to-Speech Translation Using Self-supervised Pre-training and Data Augmentation
Apr 06, 2022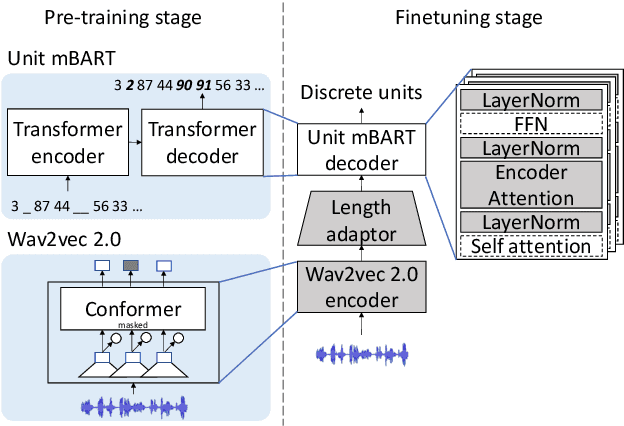

Direct speech-to-speech translation (S2ST) models suffer from data scarcity issues as there exists little parallel S2ST data, compared to the amount of data available for conventional cascaded systems that consist of automatic speech recognition (ASR), machine translation (MT), and text-to-speech (TTS) synthesis. In this work, we explore self-supervised pre-training with unlabeled speech data and data augmentation to tackle this issue. We take advantage of a recently proposed speech-to-unit translation (S2UT) framework that encodes target speech into discrete representations, and transfer pre-training and efficient partial finetuning techniques that work well for speech-to-text translation (S2T) to the S2UT domain by studying both speech encoder and discrete unit decoder pre-training. Our experiments show that self-supervised pre-training consistently improves model performance compared with multitask learning with a BLEU gain of 4.3-12.0 under various data setups, and it can be further combined with data augmentation techniques that apply MT to create weakly supervised training data. Audio samples are available at: https://facebookresearch.github.io/speech_translation/enhanced_direct_s2st_units/index.html .
Towards End-to-end Unsupervised Speech Recognition
Apr 05, 2022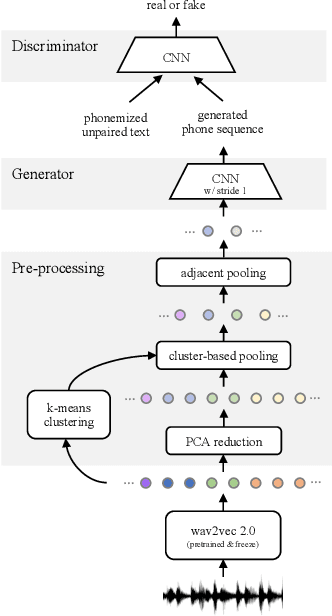

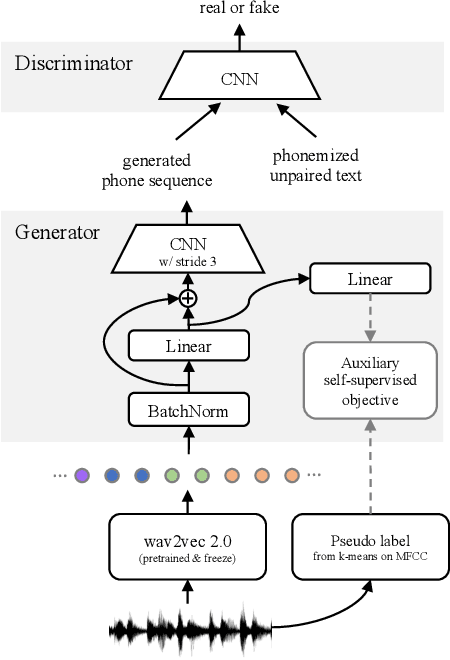
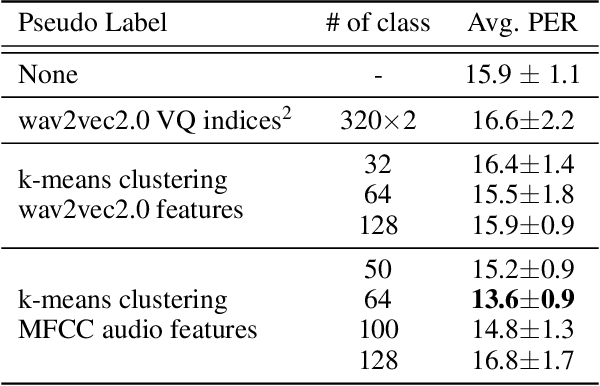
Unsupervised speech recognition has shown great potential to make Automatic Speech Recognition (ASR) systems accessible to every language. However, existing methods still heavily rely on hand-crafted pre-processing. Similar to the trend of making supervised speech recognition end-to-end, we introduce \wvu~which does away with all audio-side pre-processing and improves accuracy through better architecture. In addition, we introduce an auxiliary self-supervised objective that ties model predictions back to the input. Experiments show that \wvu~improves unsupervised recognition results across different languages while being conceptually simpler.